校內綜合信息服務平臺關鍵技術研究與實現
2019-09-12 10:41:42龔丹石蘊金
智能計算機與應用 2019年4期
關鍵詞:云平臺
龔丹 石蘊金


摘 要:當前在大學校園中已經建設的各種信息系統互相獨立、分散性很大,已不能滿足移動互聯網發展過程中,人們對信息獲取便捷性、快速性的需求。本文首先簡述了網絡爬蟲和OCR驗證碼識別技術;然后結合統一文件存儲、外部數據庫代理、Docker虛擬化容器等云平臺、跨平臺技術,給出接入已有校內系統獲取信息,進而建設一站式校園信息綜合服務平臺的解決方案;最后給出方案實施后在功能、性能和實用性等角度的測試結果。結果表明本方案可以打破傳統校內系統的壁壘,向用戶提供更便捷、移動端友好的信息服務。
關鍵詞:校園信息系統;網絡爬蟲;OCR;云平臺
文章編號:2095-2163(2019)04-0112-05 中圖分類號:TP311 文獻標志碼:A
0 引 言
當前大學校園通常都配備有教務系統、圖書館系統、校園卡系統、門禁系統、就業系統等等。這些系統覆蓋了高校內的各種核心業務,但是通常是各自為政[1-3]。信息化管理的普及給工作帶來高效的同時,也積累了越來越多的應用系統;尤其是移動互聯網發展,移動端APP瘋狂上市,近期央視新聞報道在一些高校信息化手段出現的過度傾向[4],打水、連網、記學分都要APP。可見,當前信息化手段的應用不再局限于管理工作,更多地是提供服務,以方便師生在校學習、工作時,方便快捷地獲得所需要的信息。這種信息獲取的需求,內容是基礎,但更重要的是體驗——隨時隨地、快速便捷、清晰美觀地呈現給用戶。因此,作者以工作和學習的校園實際情況為背景,提出打破已有獨立系統壁壘、提供一站式綜合信息服務系統的方案,并利用云平臺技術,去除用戶安裝和使用本系統的計算資源負擔,享受高品質的信息服務。
1 相關技術
1.1 網絡爬蟲
網絡爬蟲是一個自動地從互聯網上抽取網絡信息的程序,通常作為網絡數據收集的工具。通過編寫爬蟲程序,完成特定的過程和算法,從目標地址中獲取所需要的信息,并使用特定算法完整數據結構分析和整理[5]。一般爬蟲分為增量型爬蟲、批量型爬蟲和垂直型爬蟲。增量型爬蟲無固定范圍目標,持續不斷的抓取互聯網中的各種類型的信息,根據目前互聯網的變化而不斷變化抓取的內容。批量型爬蟲有固定范圍目標,設定一定的目標達到設定的目標就自動停止抓取信息。而垂直型爬蟲不像通用爬蟲那樣需要全面地從互聯網抓取網絡數據,而只編寫成為完成特定目的,為指定系統和目標使用特定算法抓取目標信息的爬蟲[6]。本文僅研究垂直型爬蟲以實現獲取系統所需的信息和功能。
1.2 OCR驗證碼識別
1.2.1 OCR技術介紹
OCR技術是光學字符識別的縮寫(Optical Character Recognition),通過掃描等光學輸入方式將各種票據、報刊、書籍、文稿及其印刷品的文字轉化為圖像信息,再利用文字識別技術將圖像信息轉化為可使用的計算機輸入技術。可應用于銀行票據、大量文字資料、檔案卷宗、文案的錄入和處理領域。適合于銀行、稅務等行業大量票據表格的自動掃描識別及長期存儲。相對一般文本,通常以最終識別率、識別速度、版面理解正確率及版面還原滿意度4個方面作為OCR技術的評測依據;而相對于表格及票據, 通常以識別率或整張通過率及識別速度為測定OCR技術的實用標準[7]。
1.2.2 驗證碼識別的概念
驗證碼的英文CAPTCHA,即全自動區分計算機和人類的圖靈測試,是為區別對方到底是人類還是計算機程序而設置的一種驗證措施,主要用來防止網絡機器人的一些惡意行為[8]。
驗證碼是一種區分用戶是計算機和人類的全自動程序。該程序生產一個問題,可以由計算機生成并評判,必須只有人類才能解答該問題。由于計算機無法解答驗證碼的問題,所以回答出這個問題的用戶就能被認定為是人類。由于這個測試是由計算機來考人類,而不是標準的圖靈測試中那樣由人類來考計算機,被稱為反向圖靈測試。
2 網絡爬蟲的詳細設計
2.1 正方教務系統爬蟲
正方現代教學管理系統是目前廣泛用于高校學院各部門以及各層次用戶的多模塊綜合信息管理系統,包括教務公共信息維護、學生管理、師資管理、教學計劃管理、智能排課、考試管理、選課管理、成績管理、教材管理、實踐管理、收費管理、教學質量評價、畢業生管理、體育管理、實驗室管理以及學生綜合信息查詢、教師網上成績錄入等模塊。正方教務系統爬蟲是針對正方教務系統自動獲取系統中的學生數據、成績數據、課表數據等數據并通過特定算法完成整理數據結構返回其數據信息的垂直型爬蟲。具體結構如圖1所示。正方教務爬蟲的基礎流程如下:
(1)建立抓取指定信息的任務;
(2)判斷緩存數據庫是否含有任務緩存信息;
(3)嘗試進行模擬登入;
(4)將網頁信息和驗證碼交給統一文件存儲服務;
(5)通過OCR驗證碼識別服務識別驗證碼;
(6)指定信息網頁下載;
(7)根據數據格式要求調用指定算法進行數據結構整理;
(8)格式化數據并進行編碼;
(9)更新存儲數據到緩存數據庫。
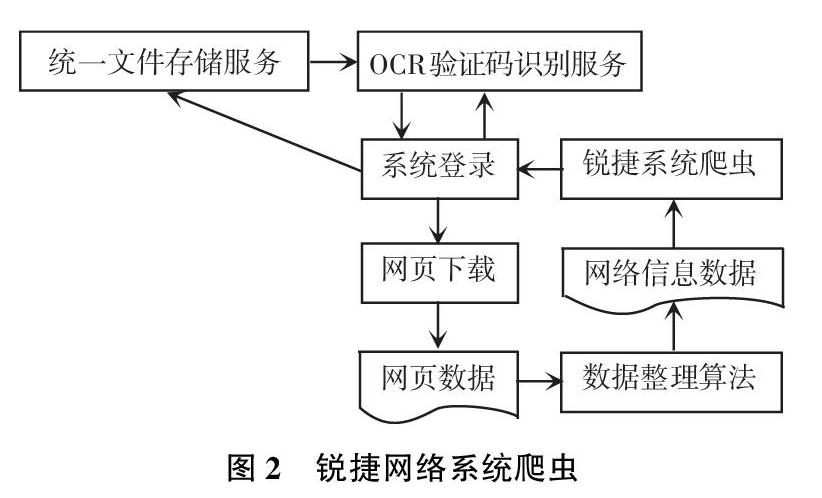
2.2 銳捷網絡管理系統爬蟲
銳捷RG-SAM認證計費網絡管理系統是目前廣泛用于高校學院中的一種認證計費網絡管理軟件。銳捷網絡管理系統爬蟲是針對銳捷RG-SAM認證計費網絡管理系統會根據用戶的信息數據自動獲取用戶網絡數據的用戶余額、上網周期、綁定IP、網絡參數等信息的垂直型網絡爬蟲。具體結構如圖2所示。銳捷網絡管理系統爬蟲的基礎流程如下:
(1)建立指定信息抓取任務;
(2)系統登錄;
(3)將信息存入統一文件存儲服務;
(4)使用OCR驗證碼識別服務識別驗證碼;
(5)指定信息網頁下載;
(6)使用數據整理算法;
(7)返回數據信息。
3 OCR驗證碼識別服務的詳細設計
驗證碼識別服務主要有以下幾個主要功能,實現圖像的采集功能、去噪、二值化、字符切割、樣本的訓練和識別。在本文中,作者對系統的總體功能結構、技術框架和總體類進行了分析和實現,在此基礎上,本章將對驗證碼識別服務的主要功能進行詳細設計。
3.1 圖像采集功能
通過特定方式請求,從Internet上獲取需要識別的驗證碼并存儲在統一文件存儲服務中,并將存儲信息告知識別程序。程序流程:
(1)由服務端傳輸所需要的請求信息,如:請求id值、請求類型、請求地址、COOKIE、HEADER等信息。由圖像采集功能模塊建立socket鏈接從Internet上讀取圖片文件;
(2)將讀取到的圖片文件流通過請求id命名、PUT提交給統一文件存儲服務進行存儲;
(3)告知服務端圖片獲取是否成功,由服務端繼續執行圖片識別服務。
3.2 圖像的去噪
驗證碼在生成中為了防止識別添加了許多噪點或傳輸壓縮的過程中產生了很多噪聲,去噪聲是圖像處理中常用的技術手段。通常需要對識別目標的噪聲進行分析,根據不同噪聲的特性進行去噪,也稱噪聲去除。
根據采集到的大量樣本表明字體顏色采用了純藍色RGB(0,0,153),使用該特征可以很方便地去噪。將圖片轉換為矩陣,進行循環掃描濾波,去除其顏色信息后,獲得只包含字符信息的圖片矩陣。
3.3 圖像的二值化
為了讓程序更好更快地識別其中的信息,需要對彩色圖像信息進行處理,圖像的二值化就是把圖像中的像素根據一定的標準分化成2種顏色。區分圖像中的前景信息與背景信息,簡單定義前景信息為黑色,背景信息為白色。
3.4 圖像的字符切割
一般圖像信息中含有多個字符,識別時需要根據每個字符的特征進行比對識別,所以對圖像進行字符切割是不可或缺的。這一步的主要工作就是把圖像中的字符獨立出來以方便識別和進行處理。
對圖像信息分析發現,字符使用的字號相對固定,每個字符不會出現重疊現象僅可能出現粘連,文字旋轉方向相對不固定但小于等于45°。規則字符的粘連很容易分割開,如果字符本身有縮放、變形就很難處理。經分析,可以發現,上面的字符粘連屬于很簡單的方式,只是規則字符的粘連,處理這種情況,可使用很簡單的處理方式。當完成分割操作后,不能馬上確定分割的部分是否為一個字符,要進行驗證。驗證的關鍵因素就是,切割下來的字符的寬是否大于閾值,這個閾值的取舍標準是,一個字符無論怎么旋轉變形都不會大于這個閾值。如果切割的塊大于這個閾值,就認為這是一個粘連字符;如果大于2個閾值之和,就認為是三個字符粘連,以此類推。了解這個規則后,切割粘連字符也就很簡單了。如發現是粘連字符塊,直接平分這個塊為2個或者多個新的塊就可以。當然為了更好地還原字符,本文采用平分+1、-1對字符塊的部分進行適當的補充。具體算法如下:
(1)掃描整個圖像信息,取得真實字符串圖像所在位置和大小,進行記錄;
(2)按照字符串數量進行等分,并判斷字符是否存在粘連并進行處理,取得每個字符串所在的大概位置;
(3)將圖像進行分割,取得每個字符圖像。
3.5 圖像的訓練和識別
首先,采取大量訓練樣本來進行處理分析,取得每個字符大量樣本后進行標注,將得到的信息以文件形式保存為權值矩陣。本程序中采用的訓練樣本以圖片形式展現。經過處理后的訓練樣本僅保留了字符的特征信息,將大量樣本用來擴充樣本庫。識別服務啟動后首先載入全部樣本庫,識別樣本時創建一個權重數組,按照相似度比對進行權重累加。最后輸出權重值最高的字符作為識別結果進行返回。經過挑選采用了800個含有字符數據信息的圖像作為訓練樣本。圖像中包含了0到8的9個數字、不包括O的從A到Y的24個英文小寫字母,總共33個字符處理后的圖像。
經過測試,這些訓練樣本訓練后的識別服務對于其驗證碼可以達到約90%以上的識別率。當然如果進行圖像傾斜度矯正,那無疑可以進一步提高識別率,但是圖片處理的時間和復雜度會達到非常大的級別,同樣如果再增加訓練樣本也可以提高識別率,所以實際意義不大。
4 方案實施與應用
除上述關鍵技術,本文系統的總體設計方案中將系統按模塊劃分為控制節點模塊、交付模塊、自動發布模塊和 Web 管理頁面模塊。采用Docker虛擬化容器架構,提高了跨平臺的部署性、擴展性和安全性。系統分為以下子容器系統:Web平臺服務、服務注冊系統、自動發布服務、容器管理服務、OCR驗證碼識別服務、統一文件儲存服務、外部數據庫代理服務、數據庫服務。最后,將系統部署到學校的服務器集群上,提供云平臺計算,應用前端通過微信小程序發布(微信搜索小程序“華德校園”,試用賬號請與作者聯系),供用戶使用。本部分給出對關鍵技術的測試和系統應用情況的展示。
4.1 信息抓取與格式化——以課程表信息為例
在校內各項信息中,課程表是學生最為關注的信息之一。因此,本部分以展示前面所設計的正方教務系統爬蟲的實施效果為例,以說明本系統的信息服務功能。如圖3所示,(a)為算法直接抓取到的數據,顯然,需要經過格式化,才能成為課表服務中的輸入,并以直觀易懂的形式顯示給用戶。(b)為從抓取數據中提取出關鍵信息的中間表示形式。鑒于大學課程在不同教學周的安排變化較大,本平臺最終輸出給用戶的課程表,以周為單位進行展示,如圖4所示。
4.2 驗證碼識別服務
如圖5(a)所示,帶陰影的圖文區域是舊系統登錄時隨機生成的驗證碼,其左側黑色字符為本文方法識別得到的結果。圖5(b)是對本方法進行330次測試得到的統計結果,該驗證碼系統中33種字符,識別準確率在90%以上的字符24種,占73%;準確率在80%以上的字符則為28種,占85%;識別效果最差的為字符l,準確率為62%。本服務設置了自動嘗試3次,因此驗證通過率完全符合實際需要。
4.3 應用與推廣
為進一步說明本文所述的解決方案及相應系統的實用性,通過微信小程序數據服務獲得了2018年9月至12月,APP用戶和訪問數統計詳情,如圖6所示。可見,本系統用戶數穩定上升,訪問次數以7天為單位呈周期地波動,完全符合高校教學周的活動特征。
5 結束語
舊的校園網內管理系統互相獨立、使用便捷性不高。因此,從提升校園內信息服務品質的角度,本文基于云平臺的架構,設計了一個綜合信息服務平臺。其中涉及網絡爬蟲和驗證碼識別技術,為打破舊有系統各自的壁壘、完成信息的綜合集成奠定了基礎;同時,本系統將信息獲取與格式處理、統一文件存儲、數據庫等計算服務建構在云平臺之上,通過發布的微信小程序作為用戶入口,極大地提升了用戶體驗、降低了應用負擔。對近半年的應用數據進行觀察可見,用戶規模不斷增加,應用粘度非常高,技術方案合理、系統具有較好的實用價值。
參考文獻
[1] 邢長明,楊林,劉一良. “互聯網+”時代地方高校繼續教育信息化建設的問題與對策[J]. 中國成人教育,2018(21):123-126.
[2]牛文. 基于云技術的高校信息服務平臺設計[J]. 電子設計工程,2018,26(16):116-119,124.
[3]李竹村. 高校信息化發展規劃現狀與規劃建議[J]. 電腦知識與技術,2018,14(21):175-177.
[4]央視新聞. 打水也要APP!. [EB/OL]. [2018-11-13]. https://mp.weixin.qq.com/s/HE15owRLW4s-KGTWisKboQ.
[5]孫立偉,何國輝,吳禮發. 網絡爬蟲技術的研究[J]. 電腦知識與技術,2010,6(15):4112-4115.
[6]姜美英. 垂直搜索引擎在校園網中的研究與應用[D]. 西安:西安科技大學,2012.
[7]百度百科. OCR技術. [EB/OL]. [2018-11-29]. https://baike.baidu.com/item/OCR%E6%8A%80%E6%9C%AF/15695472?fr=aladdin.
[8]汪中.驗證碼識別技術及應用[J]. 計算機光盤軟件與應用,2014,17(5):167-168.
猜你喜歡
東方教育(2016年13期)2017-01-12 23:14:14
電子技術與軟件工程(2016年22期)2016-12-26 11:14:53
軟件導刊(2016年11期)2016-12-22 21:53:04
電子技術與軟件工程(2016年20期)2016-12-21 11:19:58
電腦知識與技術(2016年26期)2016-11-24 17:30:56
科技視界(2016年23期)2016-11-04 23:13:16
中國市場(2016年36期)2016-10-19 04:43:09
中國新通信(2016年16期)2016-10-18 10:45:11
科技視界(2016年17期)2016-07-15 10:15:56
企業導報(2016年11期)2016-06-16 15:36:34
