流形學習研究現狀分析
2019-09-18 03:58:30張韜
中國科技縱橫 2019年14期
張韜
摘 要:流形學習的目的就是對高維樣本點集進行非線性降維,從中挖掘出樣本點集的有效特征。本文主要對流形學習算法的研究現狀進行分析,從中指出其存在的潛在問題,以及對未來的研究方向進行分析探討。
關鍵詞: 流形學習;樣本點集;降維;算法
中圖分類號:TP181 文獻標識碼:A 文章編號:1671-2064(2019)14-0203-03
0 引言
隨著社會的發展, 目前已經進入到數據時代, 大數據這個概念被很多的人所認識。數據時代我們面臨的數據量越來越大, 且數據的復雜度越來越高。這樣存在一個很突出的問題, 當我們對大數據進行處理時, 會造成處理的時間及成本代價很高。另外, 通常在對數據進行學習之前, 需要對數據進行預處理, 即對數據進行清洗。所謂清洗, 就是將無用的信息剔除掉, 將有用的信息保留。常用的方法就是對數據集進行特征提取, 根據學習的需求, 從中提取有用信息。
通常情況下, 數據點集的維度很高, 每個維度都表示數據的一個特征, 從多個特征中提取少量特征, 其實質就是對樣本點集進行降維。常見的降維方法有線性降維算法, 其主要目的是通過學習一個線性降維映射, 將高維樣本點集投影到低維空間。常見的線性降維算法有P C A [ 9 ] 、MDS[8]、LDA[10]。主成分分析法(PCA)是最著名的線性降維算法, 其采用統計學的思想, 通過構造樣本點集之間的協方差矩陣來分析樣本點的分布特點。通過對協方差矩陣進行特征值分解, 按照特征值的大小對特征向量進行排列。最大的特征值所對應的特征向量表示第一主成分, 它表明,樣本點集沿著此方向分布最多。依次可以構造第二主成分, 第三主成分等。通過這樣的方式, 可以達到對樣本點集進行降維的目的。多維尺度分析( M D S ) 是另一類比較經典的線性降維算法, 其采用幾何學的知識, 希望在降維過程中保持高維樣本點之間的歐氏距離, 也就是說降維后, 低維樣本點之間的歐氏距離與對應的高維樣本點之間的距離保持一致。因此M D S 算法的關鍵是求解樣本點之間的距離矩陣。第三個比較經典的線性降維算法是線性判別分析法( L D A ) , 這個算法主要用在分類學習中。對于帶有標簽信息的樣本點集, L D A 算法的目的是讓同一類的樣本點映射后距離較近, 而不同類樣本點映射后距離盡可能的遠。這三類樣本點在處理樣本點呈現出線性分布結構時, 它們的降維效果非常的好。然而現實生活中, 由于通常處理的數據量非常的大, 而且數據的維數非常的高, 因此樣本點集在高維空間中呈現出高度非線性分布結構。而針對這種分布特點的樣本點集, 常見的線性降維算法已經無法精確的來提取其有效特征。因此, 基于此目的, 研究者提出一類非線性降維方法。
首先針對非線性分布的樣本點集, S c h o l k o p f等人引入核函數的思想, 提出核化主成分分析法( K P C A ) [ 1 1 ] , 這個方法的主要思想是將核函數加入到樣本點集上, 首先利用核函數, 將初始樣本點集映射到更高維空間中, 使得樣本點集在更高維空間中呈現出線性分布特征, 然后再利用P C A算法對更高維的樣本點集進行線性特征提取。這個方法存在的問題是, 如何選擇非線性核函數是算法的難點。因此,為了避免這個方法的局限性, 在2 0 0 0 年《科學》雜志上提出了流形學習的思想, 也就是假設一組非線性分布的高維樣本點集分布在一個低維子流形上, 然后利用流形的性質對樣本點集進行特征提取。從直觀上理解, 流形是局部具有歐氏空間性質的幾何空間, 也就是流形上每一點的局部鄰域與歐氏空間的某個子集之間存在同胚映射關系, 因此從局部上借助于歐氏空間的性質對高維樣本點集進行降維。流形學習首次引入了局部化的思想。
1 流形學習
下面我們對幾類經典的流形學習算法進行分析, 從中來分析其存在的一些優點及局限性。流形學習首次將局部化的思想引入到機器學習中。其基本思想是從樣本點集的局部鄰域出發來獲取其潛在的有效特征。因此流形學習的首要任務是對高維樣本點集進行鄰域劃分, 常見的鄰域劃分的方法有兩種, 一種是K - 近鄰法, 一種是ε- 球鄰域法。( 1 ) K -近鄰法[ 7 ]的基本思想如下: 首先任意選取一個樣本點, 其次計算其與其余樣本點之間的歐氏距離, 然后對這組歐氏距離進行排序, 選擇距離最近的K 個樣本點作為其最近鄰點。
( 2 )ε-球鄰域法的基本思想如下: 首先仍然是任意選取一個樣本點, 然后以這個樣本點為中心, ε為球半徑做一個球面, 球面內部的樣本點就稱為此樣本點的球鄰域點。為了分析的方便, 在此假設高維樣本點集表示為{ x 1 ,x 2 , …, x N} , x i∈R D ,其中N表示樣本點集的個數, D 表示樣本點集的維度。降維后對應的低維空間的樣本點集表示為{ y 1,y 2,…,y N} ,y i∈Rd,d表示低維空間的維度。
1.1 等度量映射(ISOMAP)
ISOMAP[2 ]是在20 00年提出的流形學習算法,它引入了流形學習的概念。其基本思想是以線性降維M D S 算法為基礎, 通過獲取高維樣本點集之間真實的測地線距離來代替兩點之間的歐氏距離。在流形上, 任意兩點之間的真實距離通過測地線距離來表示。因此I S O M A P 算法的主要思想是獲取任意兩個樣本點之間的測地線距離, 然后利用M D S算法, 在低維空間重構一組樣本點集, 使得在低維空間任意兩點之間的歐氏距離等于高維樣本點之間的測地線距離。算法的具體步驟表示如下:
第一步: 利用鄰域劃分算法對高維樣本點集{ x 1 ,x 2 ,…, x N} 進行鄰域劃分。
第二步: 在樣本點集上構造局部鄰接圖, 利用D i j k s t r a算法[ 6 ] 計算任意兩點之間的最短路徑, 鄰域點之間的最短路徑表示為兩點之間的歐氏距離。
第三步: 利用M D S 算法以及第二步求得的樣本點之間的距離矩陣,在低維空間重構一組樣本點集{ y 1 ,y 2 ,…,y N}。
1.2 局部線性嵌入(LLE)
LLE[2]算法與ISOMAP算法同年發表在《科學》雜志上的另一篇流形學習算法。它與I S OM A P算法的出發點不同, 它的主要目的是在降維過程中保持樣本點集之間的局部幾何結構。因此它屬于保局部結構的算法。L L E 算法的基本思想是假設流形的局部鄰域為線性空間, 鄰域內的中心點可以由它的鄰域點集進行線性表示, 其對應的線性相關系數表示鄰域點之間的局部幾何結構。L L E 降維的目的是在低維空間重構一組樣本點集, 使得樣本點集對應的局部鄰域樣本點之間仍然滿足這個線性相關系數。下面給出算法的具體步驟:
第一步: 仍然是利用鄰域劃分方法對高維樣本點集進行劃分。
第二步: 以樣本點x i 的鄰域為例來說明, 計算鄰域中心點與其鄰域點之間的線性相關表示系數。
第三步: 在低維空間重構一組樣本點集, 使得對應的鄰域點之間滿足高維樣本點之間的線性相關性。
1.3 拉普拉斯特征映射(LEM)
L E M [ 3 ]是另一類經典的流形學習算法, 它也屬于保局部特征的降維學習算法。其基本思想是希望降維后距離較近的點仍然距離很近, 因此在鄰域點之間賦予權值, 利用權值來表示兩點之間的相似度, 權值越大表示兩點之間的相似度越高。算法的基本步驟表示如下:
第一步: 利用鄰域劃分方法對高維樣本點集進行鄰域劃分。
第二步: 構造鄰域點之間的權值, 在此利用高斯函數來計算鄰域點權值。對于非鄰域點之間的權值賦予零。第三步: 利用第二步求得的鄰域點之間的權值, 在低維空間重構樣本點集, 使得距離越近的點, 在低維空間中仍然距離越近。
2 流形學習現存問題分析
第二節, 我們只對流形學習的三個經典的算法進行了詳細的介紹, 由于流形學習屬于無監督學習的范疇, 因此在這十幾年當中, 流形學習得到了迅速的發展, 除了這三類經典的算法以外, 流形學習又發展了一系列經典的算法,例如HLLE[1 4]、LTSA[1 2]、LPP[1 3]算法等。下面我們來分析一下這些算法所存在的一些問題。
通過對這些算法進行分析可以看出, 流形學習算法的一個共有的前提假設是所處理的高維樣本點集分布在某個低維子流形上, 這個子流形是嵌入在高維空間中的。除此之外, 針對每個算法又有各自特有的假設條件。例如I S O M A P 算法假設所處理的流形為一個無洞的凸子集, 并且流形是與歐氏空間之間等距同胚的。另外L L E 以及H L L E 、L T S A 等算法假設樣本點的局部鄰域是線性空間。這些假設存在如下一系列問題。
( 1 ) 針對分布呈現出非線性結構的流形, 例如球面, 假設局部鄰域為線性空間就會存在問題。
( 2 ) 在進行鄰域劃分的時候, 是在每個點都進行鄰域劃分, 這樣就導致鄰域集的個數與樣本點的個數保持一樣。對于大數據級別的數據量, 會導致構造的鄰域的個數過大, 使得算法的復雜度非常的高。
( 3 ) 在對子流形的低維維度進行估計時, 由于假設局部鄰域為線性空間, 這樣會導致估計存在偏差。
針對以上存在的這些問題, 近些年來, 已經有一些改進的算法,例如MLLE算法[5]是對LLE算法進行改進,使得所選取的鄰域點更合理。TCIE算法[4 ]是對ISOMAP算法進行改進, 這個算法消除了I S OM A P算法對流形凸假設的條件。盡管又發展了一系列改進的算法, 但是這些算法本身仍然存在一些未被解決的問題。例如, 已有的流形學習算法仍然未考慮流形局部的彎曲程度, 即曲率信息。在對鄰域進行劃分時并未考慮樣本點的分布特點。因此, 在接下來的工作中, 可以將流形本身的拓撲結構加入到流形學習算法中, 從本身的結構出發來設計算法。
3 實驗分析
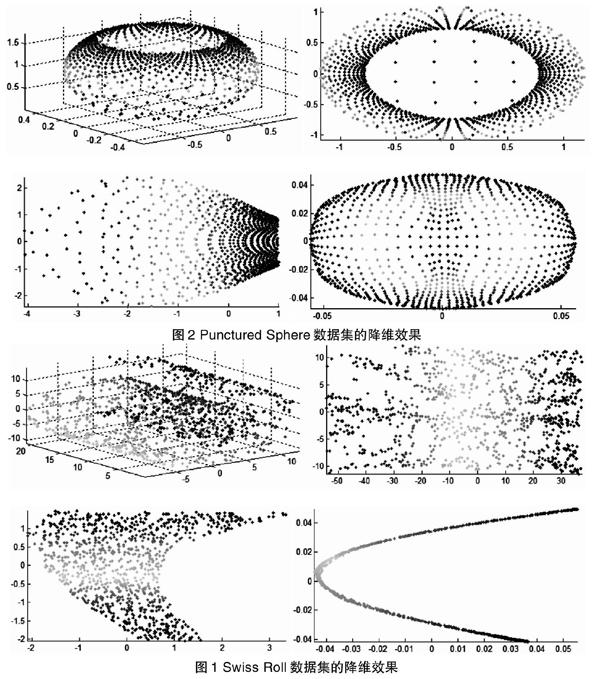
在本實驗中, 我們主要采用一組三維合成數據集來進行實驗, 從中分析已有的流形學習算法所存在的一些問題。在此, 我們主要選取了兩組數據集來進行實驗, 一組是分布呈現出瑞士卷結構的三維數據集(Swis s Roll),一組是球面數據集(Punctured Sphere)。
在實驗設計中,我們主要采用I S OMAP、L LE以及L EM三個流形學習算法對這兩組數據集進行降維, 從中分析算法的降維效果。具體的可視化結果表示如圖1 , 圖2 所示。每個圖有四個子圖, 從左到右分別表示初始數據集, I S O M A P算法降維效果, L L E 算法降維效果, L E M 算法降維效果。從這兩個圖可以看出, 它們的降維效果并沒有達到最好, 例如,針對Swis s Roll數據集,LLE算法以及LEM算法的降維效果就不好, 究其原因是因為在降維過程中并未考慮樣本集分布的彎曲程度。
4 結語
本文主要對流形學習的幾類算法進行解釋, 從中分析不同算法所存在的主要問題。在實驗方面, 選取了兩組數據集在不同的流形學習算法上進行實驗, 實驗結果也印證了我們所分析的當前流形學習所存在的問題。
參考文獻
[1] S. Roweis and L. Saul, Nonlinear dimensionality reductionby locally linear embedding. Science, vol.290,2000.
[2] J. B. Tenenbaum, V. de Silva and J. C. Langford, Aglobal geometric framework for nonlinear dimensionalityreduction. Science, vol.290,2000.
[3] M. Belkin and P. Niyogi, Laplacian eigenmaps and spectraltechniques for embedding and clustering. In proc.Int. Conf. Advances in Neural Information ProcessingSystems,2001.
[4] G. Rosman, M.M Bronstein, A.M. Bronstein, and R. Kimmel.Nonlinear dimensionality reduction by topologically constrainedisometric embedding. Int. J. Comput. Vis.89:56-68,2010.
[5] Z. Zhang, J. Wang. Mlle: modified locally linear embeddingusing multiple weights. NIPS 19:1593-1600,2006.
[6] E.W. Dijkstra. A note on two problems in connectionwith graphs. Numerische Mathematic, 1:269-271. Doi:10.1007/BF01386390.
[7] T.M. Cover and P. E. Hart. Nearest neighbor patternclassification. IEEE Transactions on Information Theory,13(1):21-27,1967.
[8] M.A.A. Cox, T.F. Cox, Multidimensional scaling. In: Handbookof Data Visulization,315-347,2008.
[9] Lindsay T Smith. A tutorial on principal componentsanalysis. February 26,2002.
[10] R. A. Fisher. The use of multiple measurements intaxonomic problems. Annales of Eugenics,7(2):179-188,1936.
[11] J. Yang, A.F. Frangi, J.-Y. Yang, D. Zhang, and Z. Jin.KPCA plus LDA: a complete kernel Fisher discriminantframework for feature extraction and recognition. IEEETrans Pattern Analysis and Machine Intelligence, vol. 27,no.2,pp. 230-244,2005.
[12] Z. Zhang, H. Zha. Principal manifolds and nonlineardimension reduction via local tangent space alignment.SIAM J. Sci. Comput.26:313-338,2004.
[13] Xiaofei He and Partha Niyogi. Locality preservingprojection. Int. Conf Advances in Neural Information ProcessingSystems,2003.
[14] D.L. Donoho, C.E. Crimes. Hessian eigenmaps: locallylinear embedding techniques for high-dimensional data.Proc. Nati. Acad. Sci. USA 100:5591-5596,2003.
