基于性能測試的信息系統監測與調優方法研究
2019-09-19 11:08:02李天翼楊佳愉
鐵路計算機應用 2019年9期
于 澎,李 琪,李天翼,楊佳愉
(1.中國鐵道科學研究院集團有限公司 電子計算技術研究所,北京 100081;2.北京經緯信息技術有限公司,北京 100081)
信息系統軟件作為交付給用戶使用的產品,其質量的好壞直接關系到用戶對產品的體驗度。測試是保證軟件高質量的必要手段,其中,軟件性能測試是整個測試過程中不可缺少的一部分。對于鐵路12306互聯網售票系統,其邏輯結構復雜,系統層次劃分較多,應用服務、中間件和數據庫大多分布在Unix或Linux服務器上,或以集群的方式提供服務,其性能的好壞直接影響到交易量[1]。因此執行性能測試的主要目的是通過監測服務器的性能指標,發現網站的性能瓶頸,并通過調整服務器參數使系統運行達到最優。
本文旨在從信息系統的服務器瓶頸分析出發,基于性能測試過程中系統每秒處理事務數(TPS,Transaction Per Second)、響應時間和吞吐量等指標,建立一套對系統性能監測與調優的方法,為系統平穩運行提供保障。
1 系統性能測試研究
1.1 性能測試指標分析
性能測試通過使用多種測試工具來模擬大量用戶發起某個業務請求的情景,從而對系統運行產生壓力。在此過程中,系統監測是檢查系統運行指標和發現系統瓶頸的過程;系統調優則是消滅系統瓶頸的過程。系統的吞吐量是指在給定的時間段內系統所完成的交易數,其中,互聯網系統的吞吐量與用戶發送的請求對服務器CPU、內存、外部接口、I/O資源等的消耗緊密關聯[2]。單個用戶請求對CPU消耗越高,外部系統接口和I/O響應速度越慢,系統吞吐能力越低,反之吞吐能力越高。并發數、TPS和響應時間是衡量系統吞吐量的主要參數,并發數為系統同時處理的事務數,TPS為每秒鐘系統處理的事務數,響應時間為系統處理完成事務的平均時間,對于互聯網系統的事務,響應時間是指系統接到請求、進行處理并返回回應的整個過程的時間。三者之間的關系為:TPS=并發數/響應時間,三者關系如圖1所示。系統的吞吐量主要由TPS和并發數兩個因素決定,每個系統的TPS和并發數都有極限值,在模擬大量用戶請求壓力下,若其中某一項達到系統最高值,系統的吞吐量就無法繼續升高,如果壓力持續增大,系統的吞吐量反而會下降。其主要原因是系統已超負荷工作,服務器的CPU、內存和接口資源等的消耗導致系統的性能下降[3]。
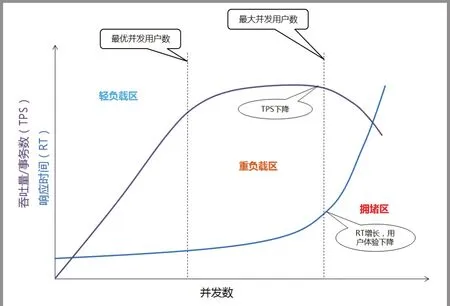
圖1 并發數、TPS和響應時間關系圖
1.2 服務器瓶頸分析
信息系統一般由多臺服務器或集群搭建而成。一臺服務器的性能瓶頸主要發生在CPU、內存、I/O和網絡4個部分。系統調優是通過配置參數來平衡這4部分的運行狀態,解決服務器瓶頸,使系統整體達到最優。這4個部分并非孤立運行,而是相互關聯的,某個部分過高的利用率會導致其他部分出現問題,使整個系統無法達到最優。例如,I/O系統中大量的整頁讀取會導致數據占滿內存隊列,網絡流量過大會導致網絡控制器消耗CPU資源,從內存中向存儲空間進行大批量的寫操作會導致消耗CPU和IO通道資源等等。系統調優是一個診斷與解決瓶頸的過程,其難點在于看似是某個部分的問題表象,但真正產生問題的原因是其他部分過載所引起的[4]。
2 系統性能監測與調優
進行信息系統性能檢測和調優需先通過業務分析來確定該系統各服務器的類型。通常電子商務類網站的后臺服務器可以分為兩類:重I/O型和重CPU型。重I/O型的服務器會消耗大量的內存和存儲資源,原因是應用程序會使用大量的數據,而數據信息會在內存和存儲系統之間傳輸。這種應用一般不需要大量的CPU資源,系統執行完I/O請求,CPU即轉為睡眠狀態,利用率較低,存儲系統與服務器之間大多都配有高速專有網絡,因此網絡消耗也較低。通常數據庫服務器屬于重I/O型。重CPU型又可以稱為重計算型,應用程序會使用服務器中大量的CPU資源進行批量處理和數值計算,通常應用服務器和中間件服務器屬于重CPU型[5]。
2.1 系統性能檢測工具
大多數Unix和Linux操作系統都裝有一系列的監測工具,不同版本的操作系統中工具用法會稍有不同。部分版本的Linux甚至將監測工具作為系統安裝的一部分,或者作為安裝附件,管理員可以自行安裝使用。系統性能監測的主要工具如表1所示。
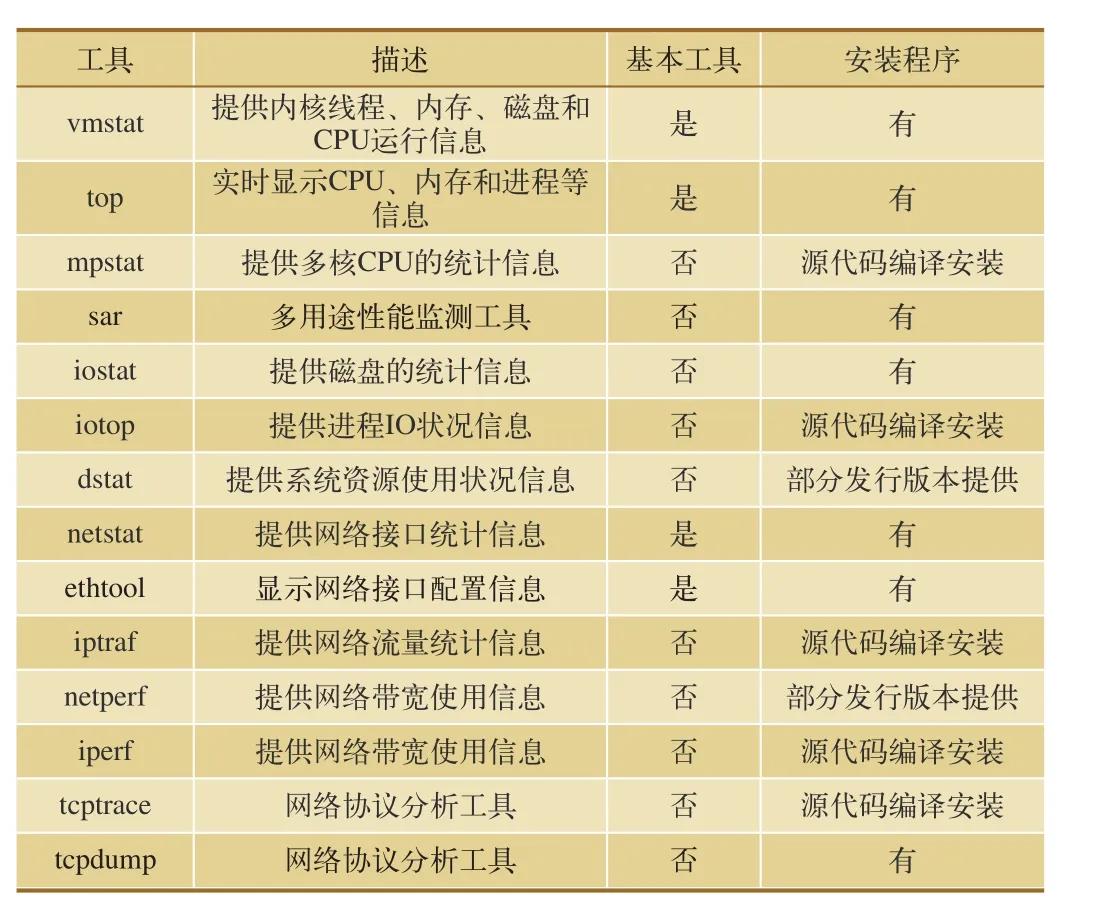
表1 系統性能監測主要工具
2.2 CPU監測與調優
2.2.1 CPU利用率
CPU的利用率主要是由它所訪問的資源決定的,CPU調度器負責調度內核線程、用戶線程和中斷請求,并給資源分配不同的預先權。其中,優先權由高到低,分別是中斷請求、內核線程和用戶線程,與其相對應的指標是上下文切換量、運行隊列長度和CPU使用率。
現代多核架構的CPU對于操作系統來說,每個內核都是獨立的,每個線程都會被分配到固定的時間片在處理器內核上運行。如果線程在指定的時間片內沒有完成或是具有更高優先級的中斷需要處理,內核則會通過上下文切換將線程調度到隊列中排隊等候運行。每個CPU都有一個線程的運行隊列,保存著正在運行的和等待運行的線程。CPU的利用率是直觀查看使用情況的指標,可分為以下3個部分:(1)用戶利用率,CPU執行用戶線程的時間比例;(2)系統利用率,CPU執行系統內核線程和中斷的時間比例;(3)I/O等待占用率,CPU由于等待I/O請求所消耗的時間比例[6]。
2.2.2 CPU性能監測
測試人員可以使用vmstat工具監測CPU運行情況。vmstat工具提供了整個操作系統全局的運行信息,并且自身運行對操作系統的影響較小,運行狀況界面如圖2所示,相關指標含義如表2所示。

圖2 vmstat工具運行狀況界面
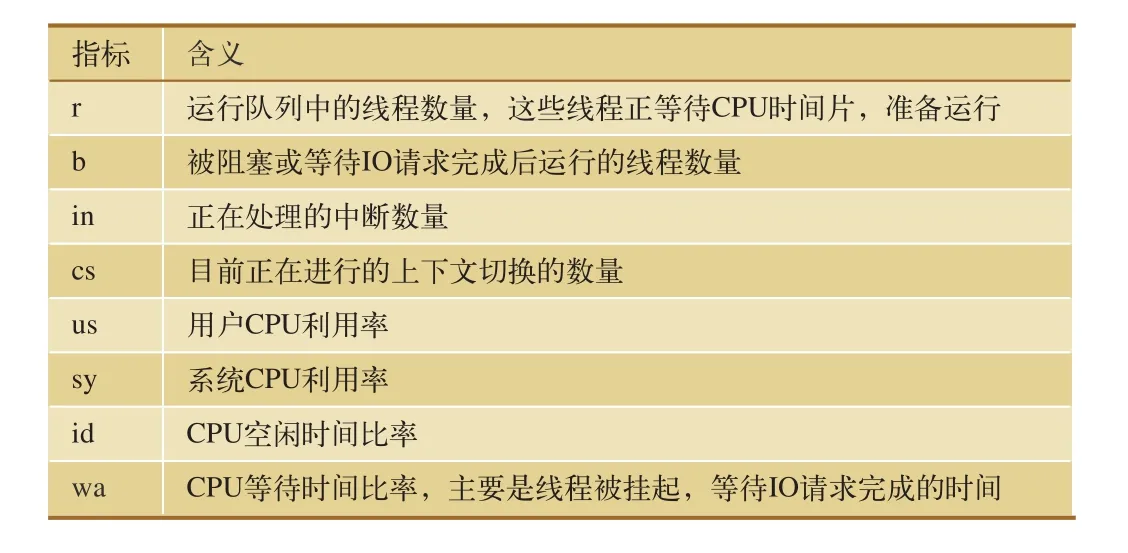
表2 vmstat工具監測CPU的主要指標
測試人員也可以使用top工具監測CPU運行情況。top工具主要用來統計并顯示CPU負載,活躍進程使用CPU情況等動態信息,其中,系統負載可以分1 min、5 min和15 min進行統計顯示[7],其運行狀況界面如圖3所示。
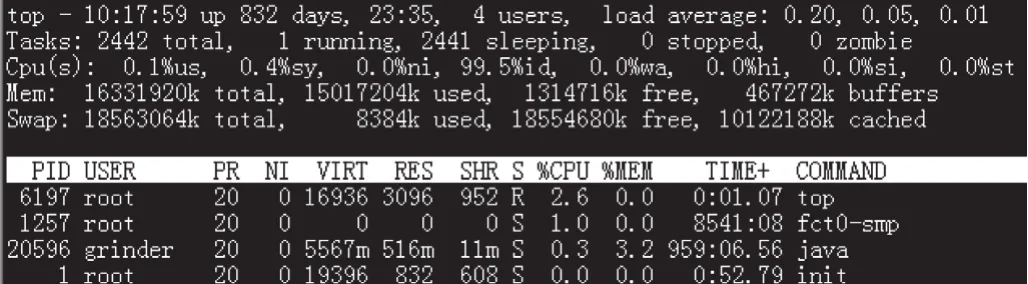
圖3 top工具運行狀況界面
2.2.3 CPU性能調優
(1)測試經驗表明,為控制系統不超負荷運行,CPU監測過程中需進行運行隊列檢查,并確保每個處理器的隊列不超過3個線程在排隊,CPU的用戶利用率和系統利用率的比例接近7:3。
(2)若CPU消耗大量時間在系統時間上,則很有可能是過載導致CPU重新調度線程的優先權。對于重CPU計算的進程和對I/O請求大的進程,兩者盡可能分不同服務器處理,以免在同一服務器中產生競爭。
(3)針對目前流行的多核CPU均采用非統一內存訪問(NUMA,Non Uniform Memory Access Architecture)技術,多個處理器不用共享一個集中的存儲器和I/O總線,而是將處理器劃分成多個節點,每個節點有相對應的本地存儲空間,在Linux中對NUMA調優命令是numactl,命令代碼如下。
numactl --menbind 1 --cpunodebind 1 --localalloc jboss
2.3 內存監測與調優
2.3.1 虛擬內存與系統瓶頸
目前服務器一般都配置較大的內存以滿足應用程序的需求,一旦內存占滿,系統會使用磁盤的部分空間充當虛擬內存使用,將目前不使用的數據寫入到虛擬內存中,再次使用到虛擬內存中的數據時,則將數據讀入到內存中。虛擬內存會被分成頁進行管理,在x86架構服務器上虛擬內存頁是4KB大小。系統以頁為最小單元在內存和磁盤之間進行讀寫,磁盤上被劃分出來做虛擬內存的部分通常被稱做交換空間[8]。
虛擬內存的引入對于應用程序來說,擴大了內存容量。程序并不關心數據是在內存中,還是虛擬內存中。但由于系統讀寫虛擬內存的速度要遠慢于內存,所以程序訪問虛擬內存會使運行速度變慢。
2.3.2 內存性能監測
vmstat工具不僅可以監測CPU的運行情況,還可以統計內存狀況,圖2中和內存相關的指標如表3所示。
2.3.3 內存性能調優
服務器內存調優常調用malloc/realloc函數進行動態內存分配,但這樣較為耗時,內存也容易出現碎片。因此程序應少進行動態內存分配,而采用內存池技術進行調優,目的是減少鏈接建立和線程創建的開銷,從而提高性能,對于HTTP服務這樣的短業務較為有效。

表3 vmstat監測內存主要指標
2.4 I/O監測與調優
2.4.1 I/O性能瓶頸
數據讀寫是整個服務器中最慢的部分,因其到CPU的物理距離較遠,并且磁盤需要有物理轉動和磁頭移動的時間以完成數據的讀寫操作。系統訪問磁盤的時間和訪問內存的時間好比分鐘級別和秒級別的差距,因此應盡可能減少由訪問磁盤上的數據而產生的I/O次數。
系統中某些特定情況的發生會引起I/O瓶頸,可以使用系統提供的工具進行原因的辨別,主要工具有iotop、vmstat、iostat和sar等。每個工具會對I/O的某個方面提供特定的信息。IOPS(Input/Output Operations Per Second)是評價I/O調度狀況的主要指標,其與多方面因素有關,如磁盤轉速、磁頭移動速度和讀取數據速度等因素,而每次I/O讀寫數據的大小與系統的工作方式有關,主要分為2種工作模式:順序模式和隨機模式。其中,順序模式需要一次讀寫大量的數據信息,其性能與單次最大讀取數據量相關。例如,數據庫系統執行大量數據的查詢操作,或是流媒體服務讀取大量的數據。隨機模式的I/O請求數據量一般都比較小,因此效率不由數據大小決定,而主要由磁盤能支持的IOPS決定[9]。如果系統沒有足夠的內存空間,程序啟動運行需要內存時將使用交換空間,對交換空間的讀寫操作都會消耗時間。由于交換空間是磁盤設備的一部分,一旦系統對與交換空間相同的文件系統進行訪問,產生讀寫磁盤相同盤面的競爭,繼而數據會堵塞I/O通道,導致系統運行速度變得更慢。
2.4.2 I/O性能監測
測試人員可以使用iostat工具監測文件系統每個分區的詳細運行信息,運行狀況界面如圖4所示。

圖4 iostat工具運行狀況界面
使用iotop工具可以顯示進程使用I/O資源的狀況,輸出信息與top工具類似,與iostat工具結合使用可以監測系統的I/O瓶頸,運行狀況界面如圖5所示。
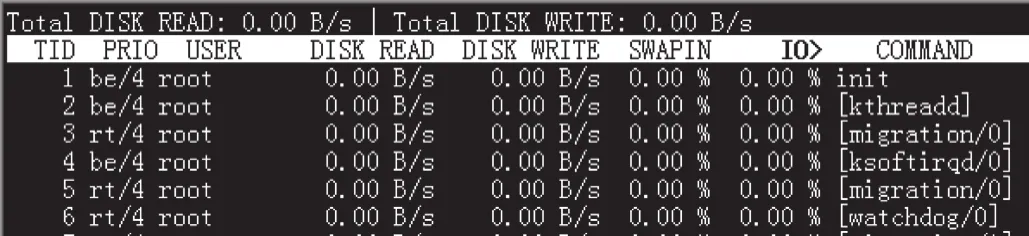
圖5 iotop工具運行狀況界面
2.4.3 I/O性能調優
I/O監測顯示,當磁盤過載時,CPU需等待I/O請求完成,導致系統變慢。I/O性能調優的方式主要有以下3種。
(1)通過分析應用進程類型,來決定系統訪問磁盤的方式,對于讀寫慢的磁盤需要分析和對比訪問的等待時間和服務時間,以確定I/O瓶頸的具體位置。
(2)通過監測系統交換空間和文件系統,確保系統虛擬內存與文件系統I/O不會產生競爭。
(3)把內核和外設的I/O次數盡可能減少,對于讀來說,讀內存cache里的數據比外設快很多;對于寫來說,cache寫的速度也很快,但數據的實時性就會降低。因此應盡可能實現寫的次數與實效性之間的平衡。
2.5 網絡監測與調優
在服務器瓶頸的4個部分中,網絡是最難監測的,因為網絡是相對抽象的實體。對網絡的監測和調優已經超越了系統的內部因素,其主要的原因有網絡線路上的延遲、沖突、擁塞和包錯誤[10]。
2.5.1.3 網絡數據包監測
與提供統計信息的網絡工具不同,tcpdump工具主要用于網絡抓包,可監視指定網口的網絡數據包的傳遞方向,并輸出數據包的報文頭信息,為網絡中的數據包分析提供強大的支持,與網絡封包分析軟件配合使用可以對網絡數據包進行篩選和分析,tcpdump工具網絡抓包界面如圖11所示。
2.5.1 網絡性能監測
2.5.1.1 網口速度和工作模式監測
因為在網絡上存在多種不同速度和工作模式的網絡設備,服務器上的以太網接口大多自動探測網絡速度并設置其工作模式。使用ethtool工具可以顯示并設定網口的速度和工作模式,運行狀況界面如圖6所示。
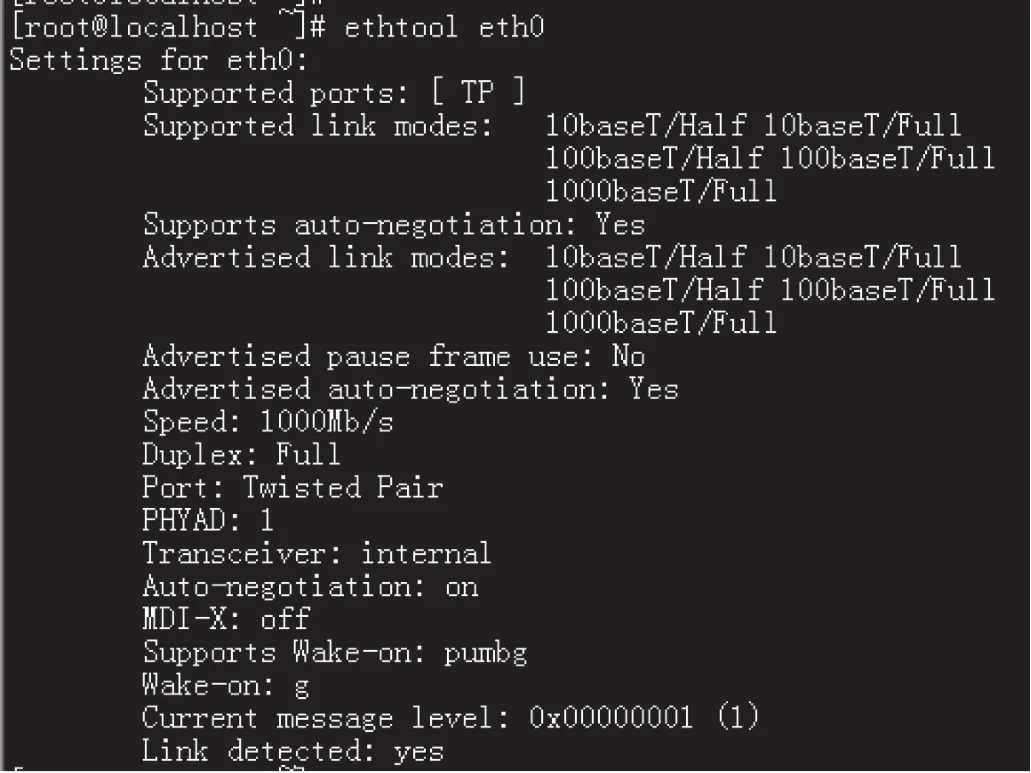
圖6 ethtool工具顯示網卡的狀況界面
2.5.1.2 網絡流量監測
由于網絡上用戶和服務器之間的數據會經過交換機、路由器和網絡連線等設備,所以網絡存在帶寬問題。因此監測網絡流量最好的方法是在網絡中發送和接收數據,同時收集和分析網絡速度和延時。
通過iptraf工具可以監測系統網卡上的流量,但其提供的可分析信息較少。netperf工具可以分析網絡上點到點之間的流量,對于客戶端到服務器之間網絡流量分析有很大幫助。該工具有客戶端和服務器2種運行模式。在服務器上以服務器模式運行netperf,在想要測試的網絡上以客戶端模式運行netperf,兩者之間會通過網絡發送和接收TCP協議包,運行結束后,netperf會統計發送和接收的數據包,并計算出網絡帶寬。netperf不僅對有線局域網可用,而且對無線網絡監測也有效。netperf服務器模式運行界面如圖7所示,運行及結果顯示界面如圖8所示。

圖7 netperf工具服務器模式運行界面
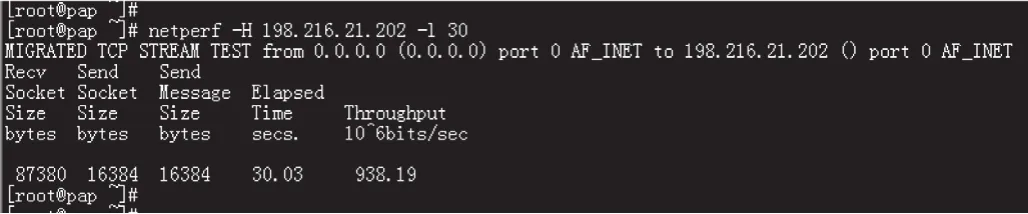
圖8 netperf工具運行及結果顯示界面
與netperf工具類似,iperf工具可以監測網絡上任意兩結點之間流量的動態信息,提供TCP和UDP協議包的窗口大小和服務質量信息,對于TCP/IP配置調整具有指導作用。iperf工具可以在服務器和客戶端模式下運行,其中,服務器端默認開啟5001端口,在客戶端運行可實時監測到服務器網絡帶寬,服務器模式運行界面如圖9所示,運行及實時輸出結果如圖10所示。

圖9 iperf工具服務器模式運行界面
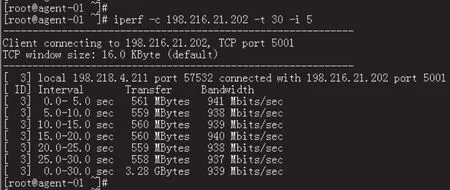
圖10 iperf工具運行及實時輸出結果界面

圖11 tcpdump工具網絡抓包界面
2.5.2 網絡性能調優
對系統網絡的調優主要針對以下幾點。
(1)檢查以太網接口是否運行在合適的速度和工作模式上,通過對網卡輸入和輸出流量的監測和統計確保系統運行在合適的網速上。
(2)通過對網絡數據包的分析確定網絡數據類型,設定系統對相應數據處理的優先級,以達到系統網絡運行最優模式。
(3)針對基于HTTP協議應用的網絡調優主要關注TCP鏈接開銷,服務器可以支持的TCP鏈接數量是有限的,TCP鏈接配置中,KeepAlive參數定義了發送包后沒有收到回應自動斷開鏈接并回收資源的等待時長,對于HTTP短鏈接,一般設置KeepAlive的值為1~2 min。
3 結束語
性能測試過程中對系統的監測和調優是一個復雜的過程,這個過程一般是由表及里、由外到內的,是發現問題、定位原因、調整參數、反復執行的過程。基于本文所述的系統性能監測與調優方法,對鐵路12306互聯網售票系統進行多輪次、多場景的性能測試,通過監控服務器運行狀態和分析系統性能指標,消除系統瓶頸,最終提升了用戶體驗。本文對系統普遍適用的工具和方法做了研究和總結,通過對系統各類性能瓶頸的監測和運行參數的調優,使系統運行在最佳狀態,用戶體驗滿意度得到提升。

猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
當代陜西(2020年13期)2020-08-24 08:22:02
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
制造技術與機床(2017年5期)2018-01-19 02:49:17
家庭影院技術(2017年9期)2017-09-26 03:41:45
金秋(2017年4期)2017-06-07 08:22:16
中國材料進展(2016年10期)2016-12-26 06:50:20
