基于DSP28335的慣導解算設計與優化*
2019-09-27 01:47:46杜偉偉許江寧何泓洋
艦船電子工程 2019年9期
杜偉偉 許江寧 何泓洋
(海軍工程大學電氣工程學院 武漢 430033)
1 引言
慣性導航系統(Inertial Navigation System,INS)是以牛頓經典力學為依據的自主式導航系統,只需要對慣性測量單元(Inertial Measurement Unit,IMU)輸出結果進行積分就能得到導航信息。目前慣性導航系統常見做法是采用嵌入式DSP(Digital Signal Processing,DSP)或者FPGA(Field-Programmable Gate Array,FPGA)實現積分以及導航解算。DSP在嵌入式領域具有體積小,功耗低,計算能力強等特點多用于復雜計算系統中處理數字信號燈問題。DSP是TI(Texas Instruments,TI)公司于20世紀80年代設計制作的專用于數字信號處理的專用芯片。得益于其對數字信號處理能力強于其他CPU或微處理器,因此在通訊系統,信號處理系統,自動控制系統,航天、航空、軍事等領域得到廣泛應用。本文介紹了基于DSP 28335平臺多種優化方法,本文提出程序設計優化技巧以及DSP特有優化方式。通過多種優化方式提升系統整體性能。
文獻[1~6]重點介紹了DSP環境下C語言編程優化方式,從數據類型,數據操作以及變量定義方向進行優化,在語言優化其他方面稍有不足不能完全發揮DSP性能優勢;文獻[7~9]提出基于高性能DSP平臺和FPGA平臺共同完成捷聯慣性導航系統的設計,利用FPGA對硬件時序控制優勢采集信號,將數字信號通過特定接口輸出至DSP芯片,由DSP芯片完成算法,實現高頻、高速的慣導解算。由于文獻中系統采用FPGA以及高性能DSP芯片導致系統硬件成本較高,在對成本有一定要求的系統中使用會受到限制。
因此,本文針對DSP 28335平臺針對有限的系統資源進行優化問題,開展了程序設計以及優化方面的研究,對捷聯慣導解算程序進行了優化。從而提升了程序運行效率。可以通過較低的硬件成本,實現慣導高速、高頻解算。
2 捷聯慣導系統基本理論
2.1 坐標系定義
對文中實際提到的坐標系統定義如下:
1)地心慣性坐標系統(i系):坐標系原點位于地球中心O,xi軸指向地球春分放向,zi軸為地球自轉軸,yi、xi、zi軸構成右手坐標系。
2)地球坐標系(e系):與地球固定。原點位于地心,xe軸穿過地球赤道和本初子午線交點,ye穿過地球東經90°子午線與赤道交點,ze軸川渝地球北極點。
3)導航坐標系(n系):坐標原點O位于載體質心,xn、yn、zn分別指向載體所在地的東、北、天。
2.2 慣性導航力學編排
捷聯慣導系統是一種將加速度計和陀螺儀直接固定在載體上的一種慣性導航系統,計算機根據載體固定的加速度計測量線性運動信息和陀螺儀測量的角運動信息解算出載體的速度、姿態、運動方向、以及載體位置信息。圖1為捷聯式慣性導航系統工作原理圖。
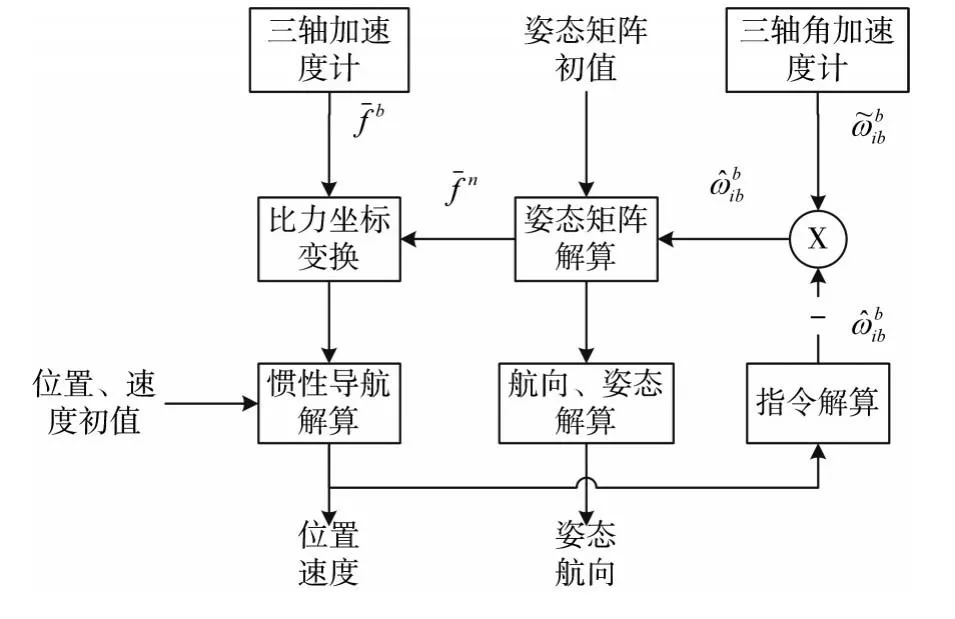
圖1 捷聯式慣性導航系統工作原理圖
導航計算原理根據固定在載體的陀螺和加速度計所輸出的角運動信息和線運動信息進行計算,角運動信息計算得出姿態轉移矩陣,線運動信息輸出的比力減去誤差速度得到載體運動速度,經過姿態轉移矩陣,將速度轉為導航坐標系下,進行導航解算就能得到速度、姿態以及位置坐標信息。
慣性導航系統基本解算方程有速度更新、位置更新、姿態更新。姿態更新解算方法目前主流的有四元數姿態更新法、歐拉角法、等效旋轉矢量法[10]。由于四元數姿態更新法相比其他算法計算量小,避免萬向節死鎖和奇異點的問題出現[11]。
慣導解算包括位置解算、速度解算與姿態解算。如下所示。
位置解算方程:
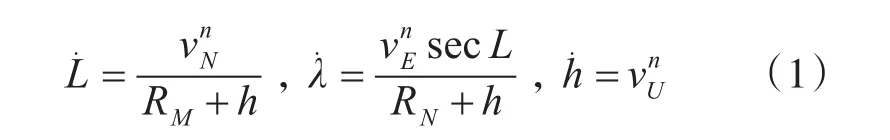
其中L、λ、h分別為載體所在位置的地理坐標系的緯度、經度、高度,vn為載體所在導航坐標系速度,為向東速度為向北速度為向天速度。
速度解算方程:
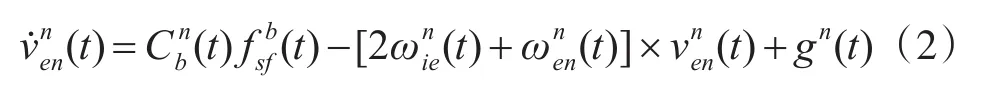
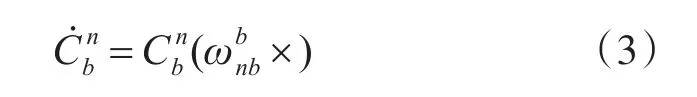
2.3 四元數姿態更新方法
四元數旋轉可以避免歐拉角中萬向節鎖現象,而且只需要一個四維的四元數即可實現任意繞過原點的向量旋轉,在某些情況下比旋轉矩陣效率更高。四元數相比歐拉旋轉可以實現球面平滑插值[12]。
2.3.1 四元數定義
四元數表示姿態,就是用四個元構成的數,可以表示為
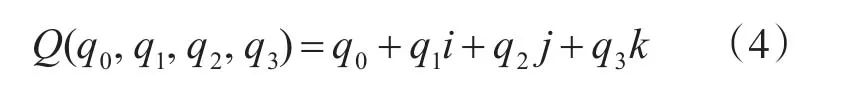
其中q0、q1、q2、q3為實數,q0為四元數的實部,qv=q1i+q2j+q3k為四元數的虛部。i、j、k是具有互相正交關系的單位向量同時又是虛單位四元數可以看做是復數的擴充,有的地方稱為超復數。四元數之間運算規則滿足加法交換律和加法結合律,但不滿足乘法交換律也不滿足乘法結合律。
2.3.2 歐拉角與四元數
分別定義俯仰角、偏航角、橫滾角為繞X軸、Y軸、Z軸的夾角分別為α、β、γ,旋轉軸的方向可以表示完成一個單位矢量
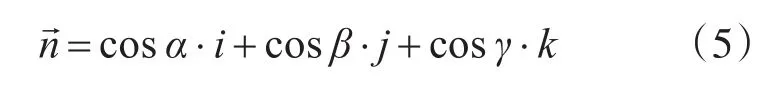
則有固定點剛體通過繞該點的某個軸旋轉角度θ到達新姿態,則描述該旋轉角度的四元數Q表示為
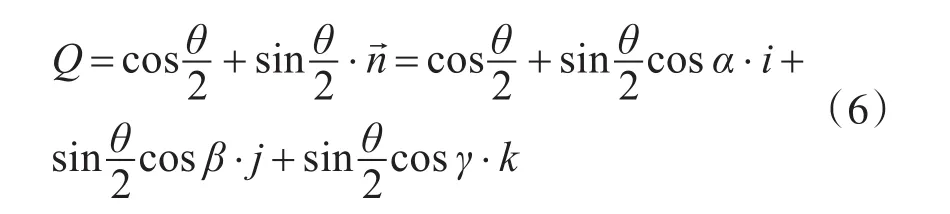
由式(6)得出歐拉角到四元數的轉換公式:
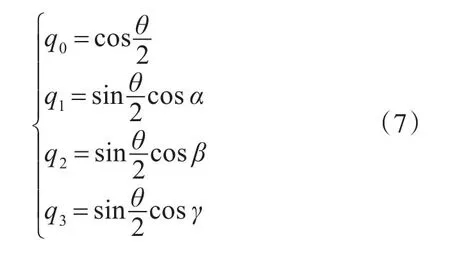
2.3.3 四元數姿態更新方程
慣導數據是定時采樣,固定時間間隔輸出。為了減少噪聲在積分中的影響。系統直接將角增量來確定四元數[10]。
四元數姿態更新方程
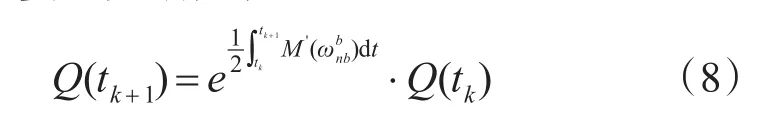
為了降低計算復雜度對式(5)進行展開得到三階近似算法:
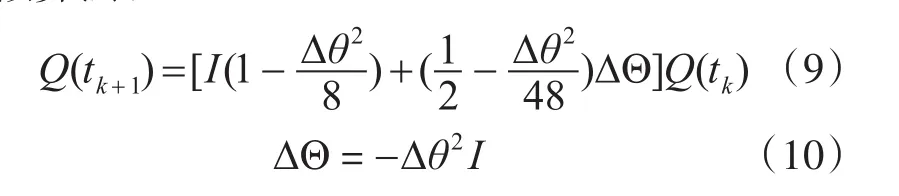
其中I為單位矩陣。
3 基于DSP 28335的慣導解算設計與優化
3.1 基于DSP 28335的程序設計
DSP28335芯片有兩個帶數據緩沖功能的高速輸入輸出串口,和一個不帶數據緩沖功能的普通串口。本文程序設計只使用其中兩個帶數據緩沖功能的高速串口:第一個串口用于接收陀螺和加速度計數據;第二個串口用于接收上位機命令數據并且發送慣導解算數據。串口中斷程序負責接收串口數據,主程序負責解析串口協議以及執行相應串口命令和解算慣導數據,并控制串口發送數據。
DSP 28335主程序如圖2所示,系統啟動后首先初始化芯片資源設置看門狗,設置芯片主頻,初始化全局變量,初始化GPIO口,初始化串口,初始化系統中斷,進入程序循環,判斷串口緩存區是否存儲串口數據,如果串口緩存區存在數據就進行串口協議解析,當串口數據滿足協議時進行相應分析,如果是上位機設置命令則進行相應參數設置,參數設置完畢后發送參數設置應答;如果是來自慣導數據則進行相應串口解算,將解算結果通過串口發送上位機。
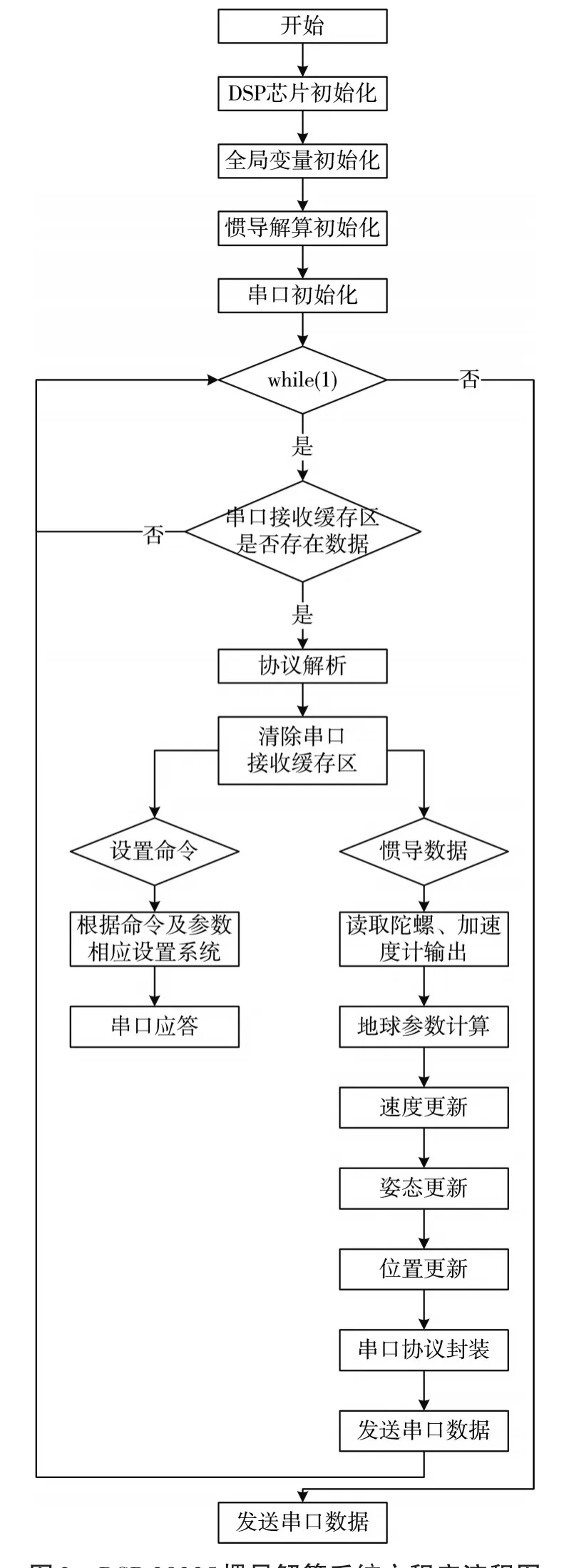
圖2 DSP 28335慣導解算系統主程序流程圖
當有串口收到數據后DSP芯片會產生中斷信號,調用相應中斷函數。中斷函數流程如圖3所示,首先讀串口數據,然后將串口數據添加緩存區中,最后清除中斷標志,表示串口中斷處理完成。
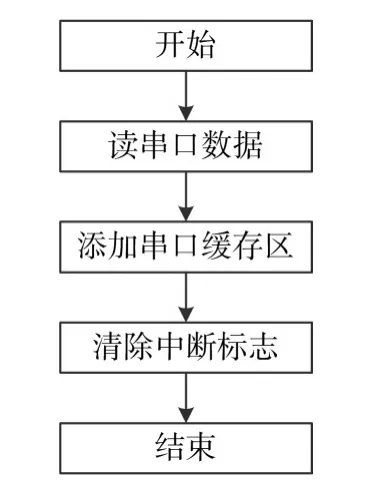
圖3 DSP 28335慣導解算系統串口中斷函數流程圖
3.2 算法優化
通過算法計算原理進行優化,這一步可以極大減少計算量也是最重要的優化手段。先分析計算原理和過程,有目的性減少計算量。例如慣導解算公式(10)
通常做法:
第一步計算Δθ2=Δθ×Δθ;
第二步計算 -Δθ2=-1×Δθ2;
第三步創建單位矩陣I;
第四步將單位矩陣每一個元素和-Δθ2相乘。
優化后:
第一步計算Δθ2=Δθ×Δθ;
第二步計算 -Δθ2=0-Δθ2;
第三步程序初始化定義值為0的矩陣I0緯度和矩陣I一致;
第四步將-Δθ2直接賦值于I0對角線元素。
通常做法計算原理過于呆板導致計算量過大,本文利用DSP系統加減法速度優于乘除法的優勢,用 -Δθ2=0-Δθ2代替 -Δθ2=-1×Δθ2降低系統運算時間,并且利用單位矩陣只有對角線元素為1,其余為0的特性以及1乘任何數等于其本身,0乘任何數等于0,直接將-Δθ2賦值于I0矩陣對角線元素免除乘計算。再次降低系統計算量,提升系統性能。
3.3 循環優化
C語言優化過程中最主要的手段是從循環語句著手重點優化,采用高效循環方式,或者減少循環次數,亦可不用循環語句。例如C語言中for循環:
for(表達式1;表達式2;表達式3)
{
語句;
}
進入循環前先執行表達式1,在判斷表達式2,如果表達式2位真執行for循環中的語句,如果為假則調出循環。當循環語句執行完后則執行表達式3。
可以看出每執行一次循環語句都要判斷一次表達式2和執行一次表達式3。則優化方法就是減小循環語句,如果循環次數較少則不使用循環語句。
例如C語言程序中Bk矩陣為4×4,該矩陣很小可以不使用for循環語句,而是直接執行表達式:
以上語句雖然代碼量比雖然較長,但是在進行優化前計算次數為278次,改為優化后的代碼計算次數為16次,大大減少計算時間。
3.4 變量優化
C語言編程時在函數中往往會定義比較多的局部變量,每定義一個局部變量CPU調用該函數時就會執行壓棧出棧操作。算法中的變量比較多,而在普通PC機的CPU性能十分強大可忽略壓棧出棧執行語句的耗時。但DSP芯片主頻有限就需要盡可能優化減少不必要的指令。因此將函數中的中間變量全部定義為全局變量,這樣又能提升系統性能。
3.5 DSP系統優化
DSP系統對Flash儲存區訪問速度遠遠慢于對系統內部RAM(Random Access Memory,RAM)的訪問,因此要大大提升DSP運行速度就要在系統啟動時將程序從flash區搬移至RAM區運行,這樣可以大大減少解算時間,對系統性能提升具有非常重要意義。DSP系統還可以通過編譯器編譯選項優化,TI公司自帶DSP開發環境CCS(Code Composer Studio,CCS)編譯器提供編譯選項-O3最高等級編譯優化,此時編譯效率已經接近純匯編模式,因此沒有必要對代碼進行匯編語言的優化。
4 試驗驗證
通過示波器波形分析對比優化前后的程序執行時間,圖4未優化Flash運行解算時間,圖5優化后Flash運行解算時間,圖6優化后RAM運行解算時間。
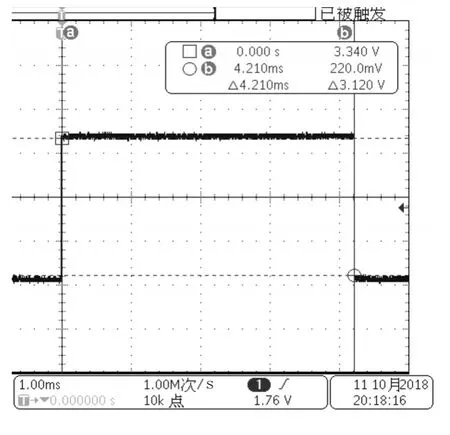
圖4 源碼未優化Flash運行解算時間
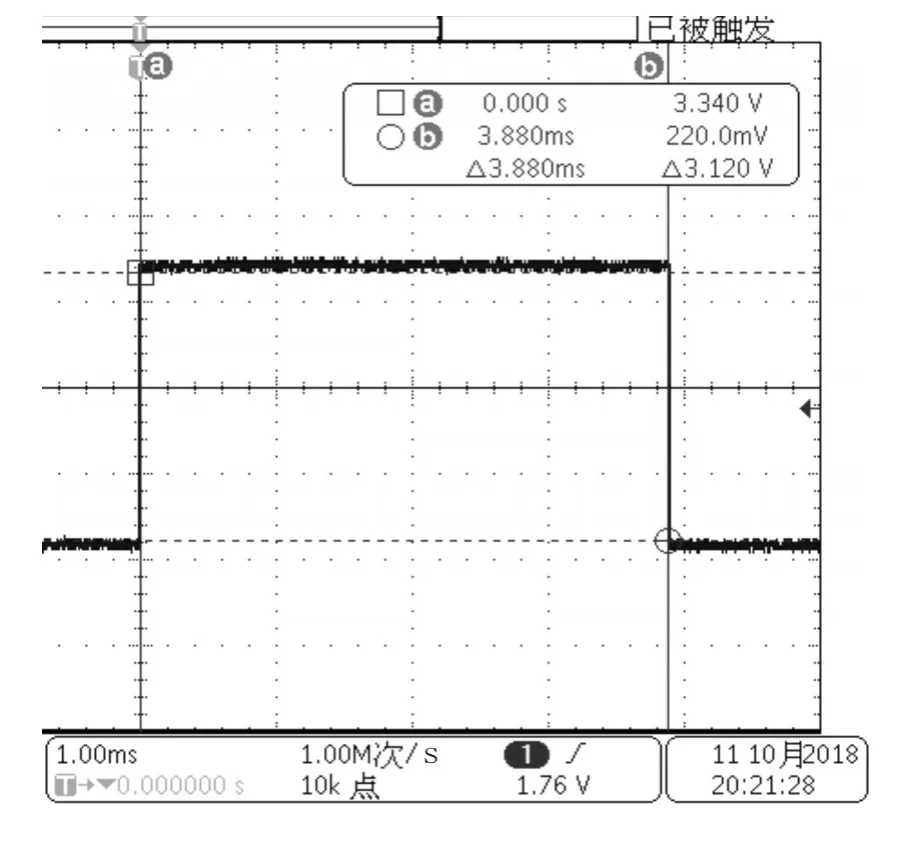
圖5 源碼優化后Flash運行解算時間
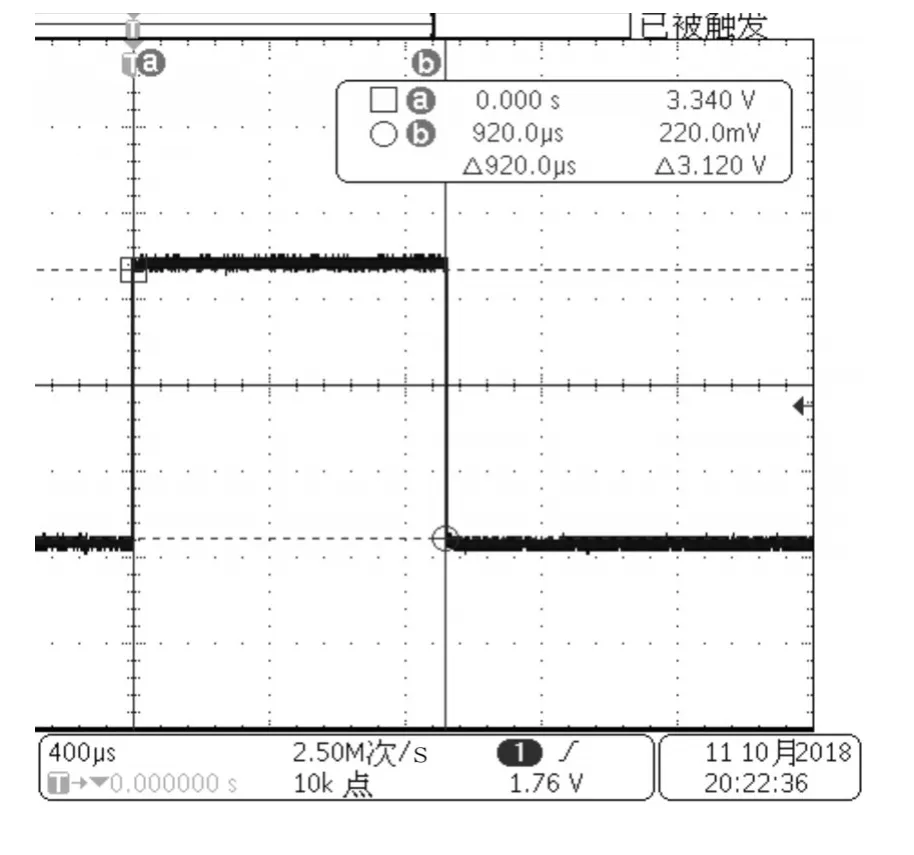
圖6 源碼優化后RAM允許解算時間
源碼未經過優化程序在Flash上運行時慣導解算時間為4.13ms,源碼經過優化程序在Flash上運行時慣導解算時間為3.940ms,對比程序優化解算時間減少0.19ms。源碼優化后讓程序在DSP系統內部RAM上運行解算時間為0.928ms,對比解算時間減少3.012ms。通過整體優化共節約時間3.202ms。
5 結語
本文通過慣導解算程序進行設計優化,針對DSP 28335平臺的優化進行詳細分析介紹,并通過試驗及實測數據驗證了優化的有效性。通過程序優化可以使系統運行效率有小幅度提升。試驗驗證慣導解算時間節約3.940ms,性能提升7.8%。通過對DSP 28335系統優化,將程序搬移至DSP內部RAM區運行慣性導航導解算時間節約2.952ms,性能提升76%,使系統性能滿足高頻、高速的慣導解算要求,并得出以下結論:通過程序優化對DSP系統性能提升有限;通過對DSP系統優化能夠獲得較大幅度性能提升。因此DSP系統優化是慣導解算中一種重要的優化方式,程序優化雖然對系統性能提升有限,依然是DSP系統優化中重要方式之一。遇到對系統要求更加嚴苛的項目,還可以通過其他優化方式提升系統性能。
TI公司DSP芯片種類繁多,但無論系統設計采用哪種芯片想要最大化獲得性能輸出,就必須對系統進行整體優化,最大可能性地利用芯片提供資源。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
人大建設(2019年12期)2019-05-21 02:55:44
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
家庭影院技術(2017年9期)2017-09-26 03:41:45
