基于哈夫曼編碼的多線程無損壓縮庫的設計與實現
2019-10-16 09:07:12彭海峰劉永紅趙衛東成都大學信息科學與工程學院四川成都6006成都大學模式識別與智能信息處理四川省高校重點實驗室四川成都6006
成都大學學報(自然科學版) 2019年3期
關鍵詞:研究
鄢 濤, 彭海峰, 李 浩, 陳 超, 劉永紅, 趙衛東(.成都大學 信息科學與工程學院, 四川 成都 6006;2.成都大學 模式識別與智能信息處理四川省高校重點實驗室, 四川 成都 6006)
0 引 言
程序開發中,文件操作是比較常用的操作.除了創建、刪除及讀寫操作外,壓縮或解壓也很重要.目前,開發具有壓縮功能的程序比較常用的函數庫有7z、LZ4、QuickLZ及snappy等,但是這些庫普遍存在不開源、嵌入到自己的項目中不夠便捷等問題.對此,本研究介紹了一種基于哈夫曼樹的多線程壓縮C++庫.該庫以哈夫曼編碼為基礎,實現了基本的無損壓縮,同時保證了良好的壓縮率,并且使用C++的多線程實現了高效的壓縮速度,能夠滿足實際開發中高效敏捷的開發需求.文件壓縮通常分為無損壓縮與有損壓縮.壓縮軟件通常用的都是無損壓縮,無損壓縮又分為2種:一種是將數據替換成數據加重復次數,另一種是用較短的數來替換較長的數[1].本研究使用第2種方法,由此能有效地求出所有數據的帶權編碼最小的前綴編碼方式,同時,將采用C++的多線程來處理壓縮數據過大的情況,在保證壓縮率時提高壓縮的速度.
1 無損壓縮與哈夫曼樹
1.1 無損壓縮的原理
1.1.1 無損壓縮.
無損壓縮是指利用數據的統計冗余進行壓縮,可完全恢復原始數據而不引起任何失真,但壓縮率是受到數據統計冗余度的理論限制,一般為2∶1到5∶1.這類方法廣泛用于文本數據、程序和特殊應用場合的圖像數據,如指紋圖像、醫學圖像等,的壓縮[2].現在常用的壓縮軟件都是無損壓縮.
1.1.2 無損壓縮方式.
方式1:將數據替換成數據+重復次數.例如,某個文件的內容是AAAABBBCCCCC,就可以替換為4A3B5C,將12個字符壓縮為6個字符,大大減少了存儲空間,但是這種壓縮比較適用于重復性大且連續重復的情況.
方式2:用更短的數來替換較長的數.在計算機中所有的數據都會以二進制進行存放,文件里所有的字符、數字,在計算機里都表現為數.將每次出現的字符根據出現的權重用二進制的1位或幾位進行替換,這樣1個字節就能存儲多個字符,減少了普通編碼文件所占的空間大小.
1.2 哈夫曼樹建立
1.2.1 統計每個字符出現的頻率.
若要建立哈夫曼樹,首先要計算出該文檔中每個字符出現的頻率,然后根據出現的頻率給每個字符賦予權值.假設該文檔中有A、B、C與D 4個字符,出現的次數依次是10、8、5與4次,然后可以給A、B、C與D根據出現的次數賦予編碼.偽代碼如下:
void analyse(char * fileName)
{
while ((fread(&temp,1,1,fp))==1)//fp為該文件的指針
{
int flagExist=0;
//判斷該字符之前出現過沒有?
check(flagExist);
//沒有出現過
if (!flagExist)
save(temp);//存儲該字符
}
fclose(fp);
}
1.2.2 根據字符出現的頻率建立哈夫曼樹.
先簡單介紹一下前綴編碼,前綴編碼是指任一字符的編碼都不是另一個字符編碼的前綴,這種編碼翻譯時不會出現歧義.哈夫曼編碼是一種帶權路徑最小的前綴編碼[3],非常適用于文件壓縮.獲取哈夫曼編碼的偽代碼如下:
void createCoding(FileState * pfileState)
{
//建立根節點
node * root=createHuffman(pfileState);
//創建哈夫曼樹
fillHuffmanCode(root,pfileState);
//獲取哈夫曼編碼
int i,j;
for(i=0;i
{
printf(″%c″,pfileState->symbolArray[i].character);
for(j=0;j<20;j++)
printf(″%d ″,pfileState->symbolArray[i].huffCode[j]);
}
}
其中,FileState為文件字符總結構體,有文件中總字符數及每個出現的字符數字2個屬性.
本研究需要先建立哈夫曼樹,每次依次尋找節點數組中最小的2個數,然后將其組建成一個二叉樹,直到讓所有的節點都組建到這棵二叉樹上為止,然后根據哈夫曼樹對左右兩邊的節點賦予編碼,即得到哈夫曼編碼.注意,用1、2進行編碼而不是0、1,因為0可能會與一個字節初始的0產生混淆,所以用2來代替,在壓縮和解壓時需要把2替換成0,以便進行位的操作[4].
2 文件的壓縮與解壓
2.1 文件的壓縮
根據獲取的哈夫曼編碼來讀文件,將讀到的數據按編碼進行替換,再用C++的位操作將每個字符的0、1編碼合成1個字節,再存到文件中,這樣1個字節就可以存儲多個字符,從而達到壓縮效果.偽代碼如下:
void compressor(char * fileName,char * newFileName)
{
//打開文件
ostream outFile;
if (outFile.open(fileName,ios::out)==0)
{
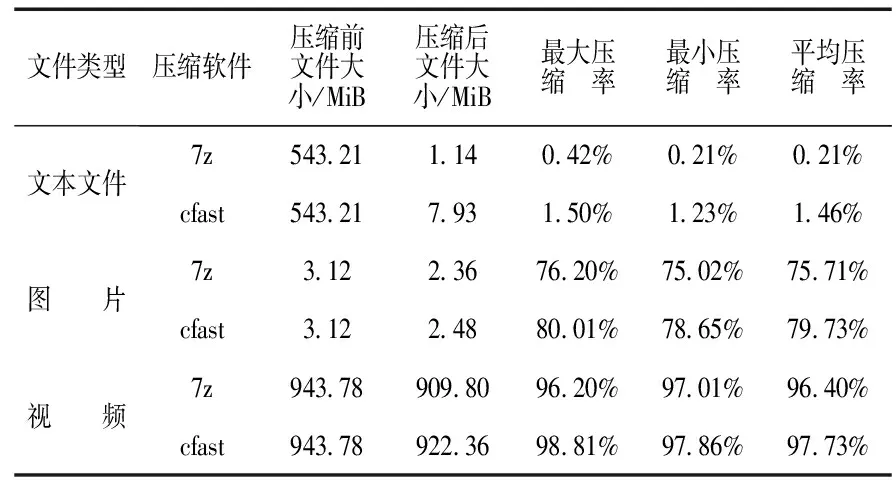
cout<<″打開失敗″< return; } ostream inFile; if (inFile.open(newFileName,ios::in)==0) { cout<<″打開失敗″< return; } //將字典結構體先寫到文件里面,方便解壓時讀取 writeHeader(fp2,pfileState); //根據字典對文件重新編碼實現壓縮效果 writeCode(fp1,fp2,pfileState); outFile.close(); inFile.close(); } 本研究修改文件的后綴為ycf,即Linux下的壓縮文件格式,然后對照著編碼表,將每個字符翻譯成二進制中的位,再用C++中的位操作將這些位合成字節實現壓縮. 解壓過程正好與壓縮過程相反.解壓過程是,依次讀取文件中每個字符,然后根據字符的二進制對照哈夫曼編碼進行翻譯,將翻譯的結果存儲到指定的文件中,這樣就完成了解壓[4].解壓偽代碼[5-6]如下: void deCompress(char * fileName,char * newFileName) { memset(&fileState,0,sizeof(fileState)); //讀取文件獲得相關信息存儲到fileState中 readHeader(fileNmae, & fileState); //創建哈夫曼樹 node * root=NULL; root=createHuffman(&fileState); //翻譯哈夫曼編碼得到新的解壓文件 writeDeCompressfile(fp,fileName,root,newFileName); } 解壓時,先讀取文件,然后依次翻譯當中的每個字節,將字節中的位翻譯成字符,因為哈夫曼編碼是一種前置編碼,在翻譯過程中不會產生歧義,這樣讀完整個文件即可完成解壓過程. 如果處理的文件較大,則單線程的設計模式效率就會很低.壓縮一個文件可能需要幾分鐘甚至更久,由于這么長的壓縮時間不能滿足實際開發需要,所以必須要引入多線程的設計模式[7-8].本研究使用C++11的多線程開發加快壓縮速率.壓縮過程的偽代碼如下: void compress(char * fileName,char * newFileName) { //用2個線程讓分析文件與創建哈夫曼編碼同時進行 std::thread th1(analyse,fileName); std::thread th2(createCoding, & fileState); //阻塞主線程 th1.join(); th2.join(); writeFile(fileName, & fileState,newFileName); } 本研究使用C++11庫中的thread類來進行并發操作,同時使用2個線程讓分析文件與創建哈夫曼樹同時進行,這樣能大大加快壓縮速度. 封裝成靜態庫的過程很簡單,只需要調節項目的相關屬性,再生成項目即可.庫封裝好之后,調用庫中函數的步驟如下: 1)更改項目的相關屬性,導入庫; 2)引入頭文件,應用相關函數進行壓縮或者解壓,代碼如下: //引入頭文件 #include #include #include int main(int argc, char ** argv) { ycl::compressor t;//定義庫中的壓縮類 std::string op,tar; //被壓縮的文件絕對路徑名及壓縮后的文件名 std::cin >> op >> tar; t.compress(op,tar);//壓縮 t.deCompress(op,tar);//解壓縮 return 0; } 本研究以7z的庫為例介紹如何用7z庫函數進行壓縮與解壓縮.由于7z的庫中沒有現成的壓縮函數,而且開源社區也只有7z的源代碼,程序員需要自己編譯成靜態庫,然后導入到自己的項目中,具體步驟如下: 1)從網絡下載源代碼,用VS對其編譯成靜態庫; 2)新建自己的項目導入編譯好的靜態庫; 3)編寫壓縮與解壓函數.這個過程非常麻煩,因為需要弄懂庫中所有函數,才能將其應用到自己的函數中,這將大大降低開發的效率,增加不必要的開發難度與時間消耗[9]. 封裝好庫后,在Windows平臺下分別對圖片、文本文檔及視頻等常用文件進行大量的數據測試,因為實際開發中所要壓縮的文件大小都是以MiB為單位,所以本研究的測試文件都為1 MiB到1 GiB之間的文件.為了保證數據的可靠性,每種文件的樣本數量為100,由于手動壓縮文件較麻煩,本研究先把文件存在文件夾中,然后用C語言循環遍歷此文件夾進行壓縮. 測試壓縮率如表1所示. 表1 測試壓縮率 表1中的文件大小都為樣本容量中的平均文件大小.從表1可知,本研究設計的庫的壓縮率與現有的庫還有一定的差距.但是,在CSDN、掘金、博客園等論壇上尋找的近100份問答中,一般情況下,本研究所探討的壓縮率已經能完全符合實際開發的需求,同時使用起來簡單便捷,然而使用7z的平均學習時間是8 h左右,但使用本研究的庫最多需要2 h的學習時間,且不需要繁瑣的導入過程,開發效率高. 本研究討論了利用哈夫曼編碼的多線程壓縮程序.實驗表明,哈夫曼編碼的壓縮方法具有良好的壓縮率,缺點在于需要耗費大量時間,所以在庫中加入了C++11中的多線程,這樣大大縮短了壓縮時間.簡潔的庫也保證了程序員使用過程中的便捷,相對于目前常用的庫較大地提高了開發效率,同時對研究文件壓縮過程和壓縮算法的改進具有一定的參考意義.2.2 文件的解壓
3 優化、封裝與性能測試
3.1 多線程優化
3.2 封裝成庫
3.3 性能測試分析
4 結 語
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54天津外國語大學學報(2021年3期)2021-08-13 08:32:18遼金歷史與考古(2021年0期)2021-07-29 01:06:54科技傳播(2019年22期)2020-01-14 03:06:54遼金歷史與考古(2019年0期)2020-01-06 07:45:20民用飛機設計與研究(2019年4期)2019-05-21 07:21:24電子制作(2018年11期)2018-08-04 03:26:04汽車工程學報(2017年2期)2017-07-05 08:13:02國際商務財會(2017年8期)2017-06-21 06:14:14電子制作(2017年23期)2017-02-02 07:17:19
