基于動作模板匹配的弱監督動作定位
2019-10-23 12:23:56石祥濱周金成劉翠微
計算機應用 2019年8期
關鍵詞:視頻
石祥濱 周金成 劉翠微


摘 要:為解決視頻中的動作定位問題,提出一種基于模板匹配的弱監督動作定位方法。首先在視頻的每一幀上給出若干個動作主體位置的候選框,按時間順序連接這些候選框形成動作提名;然后利用訓練集視頻的部分幀得到動作模板;最后利用動作提名與動作模板訓練模型,找到最優的模型參數。在UCF-sports數據集上進行實驗,結果顯示,與TLSVM方法相比,所提方法的動作分類準確率提升了0.3個百分點;當重疊度閾值取0.2時,與CRANE方法相比,所提方法的動作定位準確率提升了28.21個百分點。實驗結果表明,所提方法不但能夠減少數據集標注的工作量,而且動作分類和動作定位的準確率均得到提升。
關鍵詞:動作定位;動作模板;弱監督;動作提名;視頻
中圖分類號:?TP391.4
文獻標志碼:A
Weakly supervised action localization based on action template matching
SHI Xiangbin1,2, ZHOU Jincheng1*, LIU Cuiwei2
1.College of Information, Liaoning University, Shenyang Liaoning 110136, China ;
2.College of Computer Science, Shenyang Aerospace University, Shenyang Liaoning 110136, China
Abstract:?In order to solve the problem of action localization in video, a weakly supervised method based on template matching was proposed. Firstly, several candidate bounding boxes of the action subject position were given on each frame of the video, and then these candidate bounding boxes were connected in chronological order to form action proposals. Secondly, action templates were obtained from some frames of the training set video. Finally, the optimal model parameters were obtained after model training by using action proposals and action templates. In the experiments on UCF-sports dataset, the method has the accuracy of the action classification increased by 0.3 percentage points compared with TLSVM (Transfer Latent Support Vector Machine) method; when the overlapping threshold is 0.2, the method has the accuracy of action localization increased by 28.21 percentage points compared with CRANE method. Experimental results show that the proposed method can not only reduce the workload of dataset annotation, but also improve the accuracy of action classification and action localization.
Key words:?action localization; action template; weakly supervised; action proposal; video
0 引言
計算機視覺中的動作定位任務[1-19] 不僅需要在空間上和時序上定位動作,而且需要確定動作類別。即不僅需要確定動作在視頻每一幀上的位置,而且需要確定動作從什么時間開始到什么時間結束,以及視頻中動作是什么類別的動作。動作定位有著廣泛的應用前景,比如警方需要確定犯罪分子的逃跑路線或是街頭斗毆的經過以及球迷希望集中觀看足球場上精彩射門瞬間等。
近些年對視頻動作定位的研究方興未艾。文獻[1-6]雖然能夠做到在時序上對動作進行定位,但是無法在空間上對動作進行定位。現有的能夠實現動作時空定位的方法可以概括為兩類,一種是強監督方法,另一種是弱監督方法。文獻[8-16]利用強監督方法定位動作,這些方法的缺點在于必須對數據集中視頻的每幀圖像逐一標注,使得研究人員將大部分時間花在標注數據集這樣簡單重復的工作上,犧牲了真正研究算法的時間。文獻[17-18]采用弱監督方法,利用從網絡上下載的圖像來幫助定位人的動作,減少了標注數據集所花費的精力,但是獲取合適的網絡圖像、處理網絡圖像同樣不容易。為解決動作定位任務中數據集標注工作量大且容易標錯的問題,本文提出一種基于模板匹配的動作定位模型,只需要對視頻作類別標注和極少的幀級別標注,是一種弱監督方法,減少了處理數據集的時間,同時也不用借助網絡圖像。
1 動作定位問題的起源與難點
隨著互聯網、社交媒體的發展,生活中需要處理的視頻激增,借助計算機視覺技術,可以在一定程度上解決有限的人員精力和海量視頻數據之間的矛盾。計算機視覺中動作識別任務能夠確定視頻中動作的類別,但是有時不但需要知道動作類別還需要知道動作發生的時空位置,由此產生了動作定位。
動作識別本身就是一項困難的工作,對于未經處理的視頻,相機的抖動和復雜的背景加大了識別的難度,但是近些年來計算機視覺領域的發展使得這項任務取得了很大進展,處理動作識別數據集時只需要確定每個視頻的類別標簽,這相對來說不是一件繁重的事情。在動作定位中,不但要標注動作的類別,還要標注動作在每一幀上發生的具體位置,對于大型的數據集,靠人工來完成是一項艱巨的工作,不僅量大、耗時長,而且容易出錯。如果在只知道數據集中視頻類別的情況下就可以實現動作定位,就可以大大減少研究人員在數據集處理上所花費的時間。
2 模型主要思想
為定位視頻中動作的位置并確定視頻中動作的類別,需要先在視頻的每一幀上給出若干個動作主體(人)的矩形候選框;然后按照時間順序連接候選框形成多個候選的動作軌跡,即動作提名;最后從這些動作提名中選擇一個最合適的提名作為動作的位置,同時判定動作的類別。由于本文方法是弱監督的,訓練視頻只做了動作類別標注和極少部分幀級別標注,動作的實際位置并未標注出來,所以模型訓練時需要利用動作模板從動作提名中選擇一個最合適的提名作為視頻中動作的真實位置。每類動作的動作模板從訓練視頻中極少部分幀級別標注的矩形框得到。訓練視頻中動作的真實位置未被告知,看作模型的隱變量,模型訓練時從動作提名中取值。
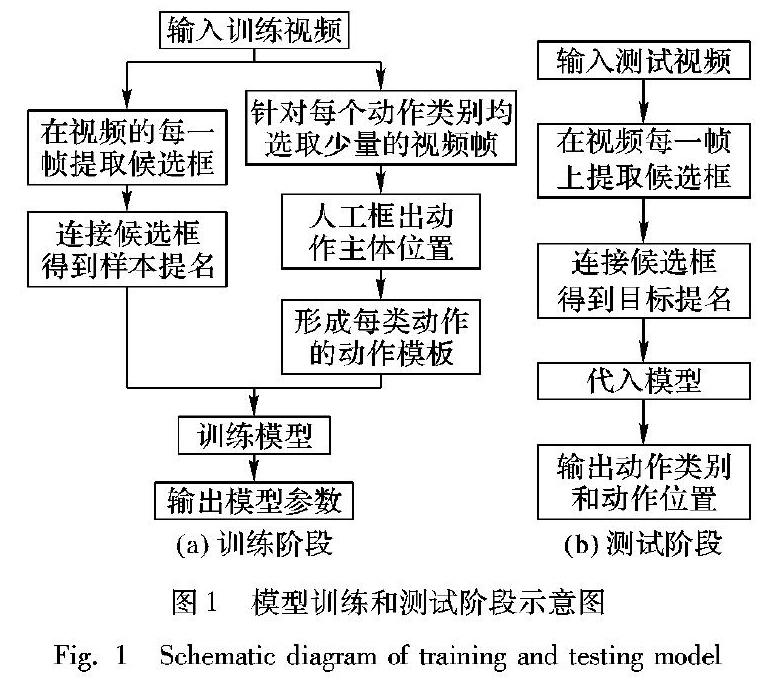
模型訓練階段,首先在訓練視頻每一幀上給出動作主體(人)的若干個候選框,然后按照時間順序連接候選框形成多個候選動作軌跡,即動作提名。從訓練視頻中提取的動作提名稱作樣本提名,分別提取整個視頻的C3D(Convolutional 3-Dimension)特征[19]和樣本提名的C3D特征。同時從訓練集中選擇少量視頻幀,人工標注出動作主體的位置,形成每類動作的動作模板。模型訓練時,訓練視頻中動作的實際位置未人工標注,通過動作模板與樣本提名匹配,促使模型選擇最合適的樣本提名作為視頻中動作的位置。利用整個視頻的C3D特征、樣本提名的C3D特征和動作模板訓練模型。圖1(a)是訓練階段示意圖。
測試階段,同樣在每個測試視頻幀中給出動作主體(人)的候選框,連接候選框形成動作提名,從測試視頻中提取的動作提名稱作目標提名,然后將整個視頻的C3D特征[19]和目標提名的C3D特征代入訓練好的模型,確定動作類別和動作位置。圖1(b)是測試階段的示意圖。
模型訓練需要解決以下幾個問題:1)獲得每個測試視頻的樣本提名;2)得到動作模板,以及樣本提名與動作模板匹配;3)求解模型參數。
3 獲取動作提名
訓練階段和最后的識別都需要先獲取動作提名。首先在每一個視頻幀上獲得候選框,由于動作的主體是人,所以主要提取人的候選框;然后, 按照時間順序連接這些候選框形成動作提名,并利用穩定光流去除動作提名中不包括動作的部分。
3.1 生成候選框
獲取動作提名的前提是在視頻幀上生成精度高的候選框,由于目前還沒有一種在精度、速度、召回率這三方面均表現良好的解決方案,所以為了得到高質量的候選框,采用多種方法,取長補短。這里采用三種方法來獲得幀上的候選框,分別是YOLOv3(You Only Look Once in version 3)[20]、EdgeBoxes[21]和Objectness[22]。Objectness根據目標框之間的NG(Normed Gradients)[22]特征具有顯著的共性,以及目標框和背景框的NG特征明顯不同,確定哪些候選框框住的是目標。雖然這種方法計算速度快、召回率高,但是結果不夠精確。EdgeBoxes利用邊緣信息確定框內的輪廓個數和與框邊緣重疊的輪廓個數,然后給出候選框,這種方法的缺陷在于評分較高的框近乎是整幅圖像的大小,雖然召回率高但是不夠精確。相比前兩種方法,YOLOv3的優點是給出的候選框精確度高,同時可以判定類別,缺點是召回率較低。
提取候選框時,YOLOv3能夠提取高質量的人的候選框,但是由于人的姿態豐富多變,會出現在某些幀上丟失檢測的情況。EdgeBoxes和Objectness得到的候選框比較豐富,召回率較高,但是大多數都不精確且不知道框住的物體是什么。三種方法各有利弊,為提升候選框的數量和質量,對YOLOv3設定一個較高閾值獲得高質量的人的候選框,并利用EdgeBoxes和Objectness繼續在每一幀上提取物體候選框,最后每一個視頻幀上得到的候選框包括所有的YOLOv3候選框,以及得分排名靠前的EdgeBoxes和Objectness候選框各500個。連接過程中優先連接YOLOv3候選框,在出現丟失檢測的幀上用另外兩種候選框替代。
3.2 連接候選框
獲取幀級別的候選框后,需要在幀與幀之間無間斷地連接候選框,所形成的候選框序列就是動作提名。動作提名最大的特性就是平滑性和相似性,幀與幀之間的連接要平滑,前一個框和后一個框要具有很強的相似性。
框與框的連接是一個沿著時間順序按照連接得分大小決定是否進行連接的過程。后一個框與前一個框的連接得分由下式計算得到:
score=α1·IOU+α2·A+α3·S
(1)
IOU= box1∩box2 box1∪box2
(2)
A=1- ?| area1-area2 | ?area1+area2
(3)
α1+α2+α3=1
(4)
其中:IOU表示兩個框的重疊度,A表示兩個框面積的相似性,area1和area2是框的面積,S表示顏色直方圖的相似性。IOU和A約束動作提名的平滑性,S約束動作提名上框與框之間的相似性。連接時先連接得分較高的YOLOv3框,在沒有滿足條件的YOLOv3框的情況下嘗試連接滿足條件的EdgeBoxes或Objectness候選框。動作主體是人,而YOLOv3提取人的候選框,所以每個動作提名的第一個矩形框總是YOLOv3框,由于YOLOv3框數量較少,減少了無效連接的數量。經過實驗發現,候選框重疊度和候選框大小相似性兩個因素對獲得動作提名一樣重要,候選框顏色直方圖相似性要比其他兩個因素影響更大,所以實驗中候選框連接得分公式中的參數α1、α2和α3分別設置成0.3、0.3和0.4。每個動作提名連接時,如果與下一幀上候選框連接的最高得分score<0.2,則結束該提名的后續連接。
3.3 確定時間位置
為便于標記時間位置,使從視頻中提取的每個動作提名的長度與該視頻的長度相等,把動作提名沒有覆蓋到的視頻幀上的位置標記成(0,0,0,0),四個數分別是矩形框左上角坐標和右下角坐標。每個動作提名的有效長度不包括標記成(0,0,0,0)的部分,本文其他地方提到的動作提名都是指有效長度部分。對動作提名使用穩定光流[23]來確定動作的開始位置和結束位置。計算每一幀的平均光流幅值和相應的動作提名上矩形框的平均光流幅值來舍棄動作提名的頭部和尾部中不是動作的部分。
γ>f/F
(5)
其中:f是矩形框內的平均光流幅值,F是整個視頻幀的平均光流幅值。當f/F小于閾值γ時,將動作提名當前的矩形框標記成(0,0,0,0);當f/F大于于閾值γ時停止。γ取值1.5。
4 動作模板
每類動作的動作模板是該類動作各種動作姿態的集合,從訓練集得到。數據集中有c類動作,就會形成c種動作模板。由于訓練視頻中動作位置未被人工標注,動作模板的作用在于使模型訓練時選擇最合適的樣本提名作為訓練視頻中動作的位置。
分別從每個動作類別的訓練視頻中隨機選擇200幀圖像,在這些視頻幀上人工標注出動作的位置,然后提取標注框的VGG(Visual Geometry Group)特征[24],特征的維度用dim表示。將標注框的特征按列合并成矩陣 M ,將 M 看作動作模板,若每個動作模板包含n個標注框,則 M 是一個dim×n維矩陣。為使得到的動作模板更具代表性和可靠性,能夠很好地表征一類動作,并且 M 的維數不至于過大,將標注框集合隨機且有重合地形成3組,也就是每類動作形成3個動作模板。為解決動作模板中同一姿態出現次數過多、動作姿態不夠多樣的問題,對矩陣 M 的列向量組求極大線性無關組,組中不符合條件的動作姿態從標注框集合中隨機選擇一個替換,直至最終確定合適的動作模板。
同時,對每個樣本提名關鍵幀上的候選框提取VGG特征,關鍵幀選取的步長是ρ,按列合并這些特征形成矩陣 P , P 的行數是特征的維數,列數是框的個數。
樣本提名與動作模板的匹配等價于矩陣 P 中所有列向量能否被矩陣 M 近似地表示。將模板匹配轉化成優化問題,如式(6)所示:
min u (‖ P - M · u ‖2F+λ1‖ u - u ?‖2F+λ2‖ u ‖1)
(6)
用文獻[7]中方法求解出此優化問題的參數矩陣 u ,其中 u ?是 u 行向量均值在列上的級聯。式(6)中‖ P - M · u ‖2F是匹配誤差,與動作實際位置重疊度越高的樣本提名和動作模板之間匹配誤差越小。由于一個連續動作軌跡上的矩形框具有時序性,框與框的特征之間具有相似性,因此參數矩陣 u 中列向量之間應具有相似性。式(6)中‖ u - u ?‖2F約束參數矩陣 u 中列向量的相似性。
比如,對于跳水動作,利用訓練集中跳水視頻的部分幀可以得到跳水動作的動作模板。將跳水動作模板與某個跳水視頻的眾多動作提名逐一匹配,匹配誤差最小的動作提名就是最優提名,在模型訓練階段將找到的最優提名看作視頻中動作的位置。
5 基于模板匹配的動作定位模型
獲得訓練視頻的樣本提名和每類動作的動作模板后,下一步建立基于模板匹配的動作定位模型,通過模型確定視頻中動作的類別和時空位置。下面介紹模型訓練過程,以及模型訓練好后如何判定視頻中動作的類別和位置。
5.1 模型訓練
令V={(xi,yi)i=1:N}表示訓練集,其中:xi表示第i個視頻;Y是動作類別集合;yi是視頻xi的動作類別標簽,yi∈Y;N是視頻的數量。Hi是從視頻xi提取的樣本提名集合。視頻xi中動作的實際位置在訓練之前未被人工標注,模型訓練時選擇一個最合適的樣本提名h*i作為視頻xi中動作的位置,h*i∈Hi,h*i視作模型的隱變量。
定義判別函數F(x,h):
F(x,h)=max y,h? f w y(x,h)
(7)
f w y(x,h)= w y Φ (x,h)
(8)
分區
圖2 聯合特征的提取過程 和聯合特征的結構
Fig. 2 Extraction of joint features ??and structure of joint features
其中:y表示動作類別,y∈Y;令H表示從視頻x中提取的樣本提名集合,h∈H; Φ (x,h)是由整個視頻x的C3D特征和視頻x中樣本提名h的C3D特征組成的聯合特征,如圖2所示; w y表示與動作類別y相關的模型參數向量,f w y(x,h)是視頻x和其樣本提名h的聯合特征與 w y的乘積。整個模型的參數 w 由全部的 w y組成。
為學習判別函數F(x,h)的參數,引入隱變量支持向量機,與普通支持向量機相比,唯一不同點在于模型訓練時視頻xi中動作位置h*i沒有顯式地告知,需要在參數學習過程中確定,將h*i看作隱變量。隱變量支持向量機參數優化問題定義為:
min ?w ,ξi,ξsi?? 1 2 ‖ w ‖2+c1∑ N i=1 ξi+c2∑ N i=1 ξsi
(9)
s.t.
fwyi(xi,h*i)-f w y′(xi,h′i)≥Δ(yi,y′)-ξi;? y′,h′i,i
(10)
min j:yi=yj? 1 zxi ?Θ(h*i,tj)≤ξsi;? i
(11)
其中:c1、c2是懲罰系數;ξi、ξsi是松弛變量;N是視頻的數量;y′從所有的動作類別中取值,y′∈Y;yi表示視頻xi的真實動作類別;Hi是視頻xi所對應的樣本提名集合;h*i表示視頻xi的動作位置,h*i∈Hi;對Δ(yi,y′),當yi≠y′時,Δ=1,否則Δ=0。
約束(10)是含有隱變量的支持向量機中最大間隔約束,確保模型能夠對視頻進行正確的類別判定。
tj是動作類別yj的動作模板;Θ(h*i,tj)表示h*i與tj的匹配誤差,由式(6)計算,用來評估樣本提名與動作模板的相似性,誤差值越小說明相似性越大;
zxi=max h′i min j:yi=yj Θ(h′i,tj),h′i是視頻xi中的樣本提名,h′i∈Hi,zxi的值是確定的,用來歸一化Θ(h′i,tj),使得ξsi的值始終在[0,1]范圍內。由于視頻xi中動作位置h*i未被人工標注,在訓練階段未知,看作是隱變量,約束(11)利用動作模板促使模型傾向于選擇與動作實際位置一致的樣本提名,提高動作定位的準確性。
利用文獻[18,25]中的方法求解優化問題(9),得到模型的參數 w 。
5.2 識別和定位
利用學習到的參數 w ,將視頻x的C3D特征和目標提名h的C3D特征代入式(12),可以知道任意視頻x的動作類別y*和動作位置h*。h∈H,H是從視頻x中提取的目標提名集合;y∈Y,Y是所有動作類別集合。算法1是判定動作類別和定位動作的偽代碼。
(y*,h*)=max y,h? f w y(x,h)
(12)
算法1? 判定動作類別和定位動作。
輸入? 待處理視頻x;
輸出? 動作類別y*和動作位置h*。
程序前
從視頻x中提取動作主體(人)的候選框
按照算法2得到目標提名集合H
將視頻x的C3D特征和目標提名的C3D特征代入訓練好的F(x,h),h∈H
程序后
算法2? 按照時間順序連接候選框得到目標提名。
輸入? 用YOLOv2,EdgeBoxes,Objectness方法在視頻x每幀上獲取的候選框;
輸出? 動作提名集合H。
程序前
fo r t=0 to frames
//從第t幀開始搜索直到最后一幀
if? numPath>500
//如果找到的提名數大于500
break
end if
wh ile pbs[t].size() != 0
//當第t幀上的候選框數不為0
if? numPath>500
break
end if
+ +numPath
將動作提名的第一個框從第t幀上候選框集合移除
fo r j=t+1 to frames
if? 在第j幀上找到滿足連接條件的候選框
將j幀上連接的候選框從候選框集合中移除
el se
轉至第一個for循環判定條件處
end if
end for
end while
end for
程序后
6 實驗結果與分析
實驗所使用的數據集是UCF-sports,該數據集包含多個運動視頻,一共10類動作150個視頻。其中:跳水動作(Diving-Side, DS)有14個視頻,打高爾夫(Golf-Swing, GS)有18個視頻,踢(Kicking, K)有20個視頻,舉重(Lifting, L)有6個視頻,騎馬(Riding-Horse, RH)有12個視頻,跑步(Run-Side)有13個視頻,玩滑板(Skateboarding, S)有12個視頻,鞍馬(Swing-Bench, SB)有20個視頻,單杠(Swing-Sideangle, SS)有13個視頻,走(Walk-Front, WF)有22個視頻。UCF-sports數據集中視頻的時間長度不一,視頻幀的分辨率不一,背景復雜,對于動作定位來說十分具有挑戰性。
遵循UCF-sports數據集官網對動作定位任務中數據集分類的建議,數據集中的103個視頻作為訓練數據,47個視頻作為測試數據,訓練集和測試集的比例大概是2∶ 1。實驗中判定動作起止時間位置參數γ設置成1.5,動作提名中關鍵幀步長ρ是6,每個動作模板中包含20個人工標注的候選框。候選框連接階段會舍棄長度過短的提名,提名中候選框少于10個認為不可靠。實驗中用C3D網絡[19]提取4096維的視頻特征和動作提名特征,用VGG網絡[20]提取4096維矩形框內的圖像特征。
在UCF-sports數據集上,分類效果如表1和2所示。表1中的大寫字符是每類動作的英文首字母縮寫,表中數字是模型對測試集視頻的分類結果,可以計算出總體的識別準確率是87.2%。從表3中可以看出本文方法在動作定位任務中識別精度優于其他方法,比TLSVM(Transfer Latent Support Vector Machine)[18]方法識別準確率提高了0.3個百分點。
實驗定位效果如圖3所示,圖中虛線框是測試集中人工標注的位置,實線框由本文方法定位產生,定位效果的衡量標準按照式(13):
τ= 1 n ∑ n i=1 IOUi(b1,b2)
(13)
其中:τ是定位結果和動作真實位置之間的重疊度,表示定位的效果;n是動作持續的幀數;IOUi(b1,b2)是第i幀上定位框b1與實際框b2之間的交并比。在閾值τ取0.2的情況下,即定位結果如果與動作真實位置重疊度大于0.2時認為定位結果正確,將定位的精度與CRANE(Concept Ranking According to Negative Exemplars)[28]、Siva等[29]提出的方法和Sultani等[17]進行對比,結果如表4所示。
CRANE[28]、Siva等[29]提出的方法和Sultani等[17]都是弱監督方法,其中效果最好的Sultani等[17]先給出動作提名,然后利用網絡圖像來對動作提名排序,選出得分最高的動作提名作為定位結果。而本文方法動作的定位和識別同時進行,兩者之間相互促進,知道動作類別可以幫助定位,知道動作位置也可以幫助判定類別,提高了各自的精度。另外,本文方法利用視頻幀幫助定位動作比Sultani等[17]利用網絡圖像更加合適,因為視頻幀中動作姿態來自一個完整連續的動作視頻,比靜止孤立的網絡圖像能夠更好地表現動作的特點。從表4定位效果來看,本文方法要明顯好于其他幾種方法。
在UCF-sports數據集上的實驗,如果使用強監督方法需要人工標注6605張訓練集視頻幀,而使用本文方法只需要分別從每個動作類別的訓練視頻中隨機選擇200幀圖像人工標注即可,其余視頻幀不用標注。由于UCF-sports數據集包含10個動作類別,所以人工標注2000張訓練集視頻幀,數據集標注的工作量將減少69.7%。
7 結語
本文提出一種只需對數據集中視頻做動作類別和極少幀級別標注就可以定位動作的弱監督方法,訓練時將動作真實位置看成是隱變量[30],利用動作模板在短時間內完成模型參數的學習。本文方法受相機抖動影響較小,并且可以處理任意長度視頻,方法應用范圍廣。在數據集UCF-sports上的實驗結果顯示,相比CRANE[28]、Siva等[29]提出的方法和Sultani等[17]提出的方法,本文方法的定位效果分別提升了28.21個百分點、30.61個百分點和0.9個百分點。本文方法能處理包含單個主要動作的視頻,但是當視頻中出現兩個及以上不同類型動作同時發生的情況,則不能很好地將這些動作都定位出來,這是未來需要繼續研究的方向。
參考文獻
[1]?YUAN Z, STROUD J C, LU T, et al. Temporal action localization by structured maximal sums [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 3215-3223.
[2]?LIN T, ZHAO X, SHOU Z. Single shot temporal action detection [C]// Proceedings of the 25th ACM International Conference on Multimedia. New York: ACM, 2017: 988-996.
[3]?SHOU Z, WANG D, CHANG S. Action temporal localization in untrimmed videos via multi-stage CNNs [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 1049-1058.
[4]?SHOU Z, CHAN J, ZAREIAN A. CDC:convolutional-de-convolutional networks for precise temporal action localization in untrimmed videos [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 1417-1426.
[5]?XU H, DAS A, SAENKO K. R-C3D: region convolutional 3D network for temporal activity detection [C]// Proceedings of the 2016 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2017: 5794-5803.
[6]??ZHAO Y, XIONG Y, WANG L, et al. Temporal action detection with structured segment networks [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2017: 2933-2942.
[7]?SCHMIDT M. Graphical model structure learning with l1-regularization [D]. Berkeley: University of British Columbia, 2010: 27-32.
[8]?SAHA S, SINGH G, SAPIENZA M, et al. Deep learning for detecting multiple space-time action tubes in videos [C]// Proceedings of the 2016 British Machine Vision Conference. Guildford, UK: BMVA Press, 2016: No.58.
http://www.bmva.org/bmvc/2016/papers/paper058/abstract058.pdf
https://arxiv.org/abs/1608.01529?context=cs
[9]?ZOLFAGHARI M, OLIVEIRA G L, SEDAGHAT N, et al. Chained multi-stream networks exploiting pose, motion, and appearance for action classification and detection [C]// Proceedings of the 2017 IEEE Conference on International Conference on Computer Vision. Piscataway, NJ: IEEE, 2017: 2923-2932.
[10]?SINGH K K, LEE Y J. Hide-and-Seek: forcing a network to be meticulous for weakly-supervised object and action localization [C]// Proceedings of the 2017 IEEE Conference on International Conference on Computer Vision. Piscataway, NJ: IEEE, 2017: 3544-3553.
[11]?BAGAUTDINOV T, ALAHI A, FLEURET F, et al. Social scene understanding: end-to-end multi-person action localization and collective activity recognition [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 3425-3434.
[12]?CHEN L, ZHAI M, MORI G. Attending to distinctive moments: weakly-supervised attention models for action localization in video [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops. Piscataway, NJ: IEEE, 2017: 328-336.
[13]?HOU R, CHEN C, SHAH M. Tube Convolutional Neural Network (T-CNN) for action detection in videos [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2017: 5823-5832.
[14]?WANG L M, XIONG Y J, LIN D H, et al. UntrimmedNets for weakly supervised action recognition and detection [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 6402-6411.
[15]?KLSER A, MARSZAEK M, SCHMID C, et al. Human focused action localization in video [C]// Proceedings of the 2010 European Conference on Computer Vision, LNCS 6553. Berlin: Springer, 2010: 219-233.
[16]??WEINZAEPFEL P, HARCHAOUI Z, SCHMID C. Learning to? track for spatio-temporal action localization [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2015: 3164-3172.
[17]?SULTANI W, SHAH M. What if we do not have multiple videos of the same action? — video action localization using Web images [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 1077-1085.
[18]??LIU C W, WU X, JIA Y. Weakly supervised action recognition? and localization using Web images [C]// Proceedings of the 2014 Asian Conference on Computer Vision, LNCS 9007. Berlin: Springer, 2014: 642-657.
[19]?TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2015: 4489-4497.
[20]??REDMON J, FARHADI A. YOLOv3: An incremental improvement [J]. arXiv E-print, 2018: arXiv:1804.02767.?[EB/OL]. [2018-09-23]. https://arxiv.org/pdf/1804.02767.pdf.
[21]??ZITNICK L, DOLLR P. Edge boxes: locating object proposals? from edges [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8693. Berlin: Springer, 2014: 391-405.
[22]?CHENG M, ZHANG Z, LIN W, et al. BING: binarized normed gradients for objectness estimation at 300fps [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2014: 3286-3293.
[23]?WANG H, SCHMID C. Action recognition with improved trajectories [C]// Proceedings of the 2013 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2013: 3551-3558.
[24]?SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [J]. arXiv E-print, 2015: arXiv:1409.1556.?[EB/OL]. [2018-09-23]. https://arxiv.org/pdf/1409.1556.pdf.
[25]?DO T, ARTIRES T. Regularized bundle methods for convex and non-convex risks [J]. The Journal of Machine Learning Research, 2012, 13(1): 3539-3583.
[26]?LAN T, WANG Y, MORI G. Discriminative figure-centric models for joint action localization and recognition [C]// Proceedings of the 2011 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2011: 2003-2010.
[27]??MOSABBEB E A, CABRAL R, TORRE F de la, et al. Multi-label discriminative weakly-supervised human activity recognition and localization [C]// Proceedings of the 2014 Asian Conference on Computer Vision, LNCS 9007. Berlin: Springer, 2014: 241-258.
[28]??TANG K, SUKTHANKAR R, YAGNIK J, et al. Discriminative? segment annotation in weakly labeled video [C]// Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2013: 2483-2490.
[29]?SIVA P, RUSSELL C, XIANG T. In defence of negative mining for annotating weakly labelled data [C]// Proceedings of the 2012 European Conference on Computer Vision, LNCS 7574. Berlin: Springer, 2012: 594-608.
[30]?劉翠微.視頻中人的動作分析與理解[D].北京:北京理工大學,2015:77-78. (LIU C W. Analysis and understanding of human action in video [D]. Beijing: Beijing Institute of Technology, 2015: 77-78.)
猜你喜歡
藝術與設計·理論(2016年4期)2017-01-16 02:06:32
中國新通信(2016年22期)2017-01-13 09:47:47
亞太教育(2016年33期)2016-12-19 04:44:01
考試周刊(2016年94期)2016-12-12 13:10:56
中國記者(2016年9期)2016-12-05 02:24:38
科技視界(2016年25期)2016-11-25 08:45:10
新媒體研究(2016年19期)2016-11-18 20:01:10
電腦知識與技術(2016年25期)2016-11-16 13:03:34
讀寫算·素質教育論壇(2016年22期)2016-11-14 07:35:17
電子技術與軟件工程(2016年18期)2016-11-14 00:01:37
