此人不存在
2019-10-30 03:44:24技術宅
電腦愛好者 2019年7期
技術宅
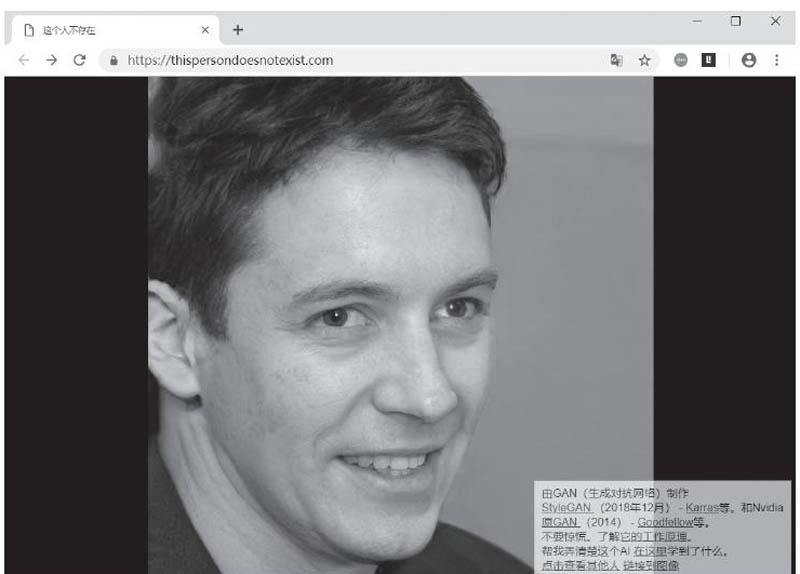
AI畫像——“真實”的不存在
我們只要打開瀏覽器登錄https://thispersondoesnotexist.com,成功加載網頁后就會看到一幅人物畫像,可以看到這些人像非常的真實,而且每刷新一次會出現新的畫像,他們就像是我們生活中的各個普通人物(圖1)。
AI畫像背后——認識StyleGAN算法
那么這些人像是怎么生成的呢?該網站明確表示,是基于GAN的StyleGAN算法生成的。GAN是Generative AdversarialNetworks(生成式對抗網絡)的簡稱,它是一種深度學習模型,這種模型一般包括兩個模塊:生成模型G(Generative Model)和判別模型D(Discriminative Model),通過兩個模型的互相博弈學習產生完美的輸出。博弈的結果是讓G可以生成足以“以假亂真”的圖片G(z)。
因為博弈訓練需要大量的運算,隨著GPU運算能力的提升,2018年英偉達開發了基于GAN的人工智能算法——StyleGAN,它可以合成足以騙過人類的各種假人臉。StyleGAN的算法生成器和普通的GAN不一樣,它是借助風格遷移的思路重新發明的。在實際訓練中,科學家們向AI輸入兩張圖,比如圖A決定人物的年齡、性別、頭發長度和姿勢;圖B決定一切其他因素,如膚色、發色、衣服顏色等等。這樣通過博弈訓練后,圖B的畫風就自然遷移給A,從而生成一個A、B融合的新圖片(圖2)。

顯然StyleGAN的核心是融合,將多張不同風格的目標任務融合在一個輸出目標上。為了讓生成的人像更為逼真、多變和自然。StyleGAN先通過學習在低分辨率下出現的基本特征來創建基礎圖像,然后通過更高分辨率的圖片訓練來識別更多的細節,這樣通過漸進式訓練,最終融合輸出的照片就顯得非常自然、逼真(圖3)。

StyleGAN通過從粗糙、中等、精細三種R度上調節圖像的生成。其中粗糙是指規模最大的調整,它的分辨率在42-82之間,比如人臉的朝向、臉型和發型,都在這里調整。通過粗糙調整,讓AI畫出幾乎風格、外形完全不同的人物畫像(圖4)。中等則是只調整部分特征,比如對臉部特征、發色發量、鼻子大小等局部的特征進行調整,這樣生成的圖像看上去似曾相識,但是仔細觀察卻可以看到臉部特征是不同的。精細改變的是圖像的配色,幾乎不會給人物變臉。
當然這三種調整不是獨立的,而是相輔相成的,StyleGAN通過特定的算法將它們組合在一起,最終實現完美的輸出,即通過簡單的輸入,如選擇一種自己喜歡的臉型、發型或膚色,StyleGAN在后臺就可以通過預置的算法生成你需要的人像(圖5)。



回到文章前面介紹的網站,這是一位來自Uber的軟件工程師Philip Wang創建的,他利用的正是英偉達創建的StyleGAN算法,創作了源源不斷的假人像。當訪問者每次刷新這個網站,網站后臺服務器就會使用StyleGAN算法結合上述介紹的三種調整來重新生成一張以假亂真的人物圖像(圖6)。
AI造假——讓人歡喜讓人憂
通過上面的介紹我們見識到了基于StyleGAN算法的AI畫像的超能力。AI畫像的模仿能力可以讓我們有意想不到的驚喜,比如去年的“天價”AI畫作事件,佳士得拍賣行以43.25萬美元(約為300萬人民幣)的高價拍出一件人工智能藝術品(圖7)。

雖然目前模型是被訓練用來生成人臉圖像的,但理論上來說它可以模仿任何來源的圖像。比如我們可以利用這個模型來生成新的字體,這樣設計師們再也不用苦思冥想,利用現成的海報字體就可以“模仿”出各種漂亮的字體了(圖8)。
當然隱憂也是顯而易見的,比如可能有不懷好意的人利用它來生成一個不存在的人,然后利用臆想的文字編造假新聞,這種有圖有真相的假新聞可能會造成各種不良的影響。類似的,用GAN模仿字跡寫欠條、換臉開門禁,這類看似不可能完成的任務,在以后的生活中可能一一出現。任何一項新技術的出現,其好壞兩面的評估都值得科學家認真、審慎地去對待!
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
無線電工程(2020年11期)2020-10-29 01:25:46
現代出版(2020年3期)2020-06-20 07:10:34
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
