醫學影像人工智能輔助診斷的樣本增廣方法
2019-10-31 09:21:33魏小娜李英豪王振宇李皓尊汪紅志
計算機應用 2019年9期
關鍵詞:人工智能
魏小娜 李英豪 王振宇 李皓尊 汪紅志


摘 要:針對不同領域人工智能(AI)應用研究所面臨的采用常規手段獲取大量樣本時耗時耗力耗財的問題,許多AI研究領域提出了各種各樣的樣本增廣方法。首先,對樣本增廣的研究背景與意義進行介紹;其次,歸納了幾種公知領域(包括自然圖像識別、字符識別、語義分析)的樣本增廣方法,并在此基礎上詳細論述了醫學影像輔助診斷方面的樣本獲取或增廣方法,包括X光片、計算機斷層成像(CT)圖像、磁共振成像(MRI)圖像的樣本增廣方法;最后,對AI應用領域數據增廣方法存在的關鍵問題進行總結,并對未來的發展趨勢進行展望。經歸納總結可知,獲取足夠數量且具有廣泛代表性的訓練樣本是所有領域AI研發的關鍵環節。無論是公知領域還是專業領域都進行樣本增廣,且不同領域甚至同一領域的不同研究方向,其樣本獲取或增廣方法均不相同。此外,樣本增廣并不是簡單地增加樣本數量,而是盡可能再現小樣本量無法完全覆蓋的真實樣本存在,進而提高樣本多樣性,增強AI系統性能。
關鍵詞:人工智能;醫學影像;輔助診斷;樣本增廣
中圖分類號:TP391.41
文獻標志碼:A
Methods of training data augmentation for medical image artificial intelligence aided diagnosis
WEI Xiaona1, LI Yinghao2, WANG Zhenyu1, LI Haozun2, WANG Hongzhi1,2*
1.Shanghai Key Laboratory of Magnetic Resonance (East China Normal University), Shanghai 200062, China;
2.School of Physics and Material Science, East China Normal University, Shanghai 200062, China
Abstract:
For the problem of time, effort and money consuming to obtain a large number of samples by conventional means faced by Artificial Intelligence (AI) application research in different fields, a variety of sample augmentation methods have been proposed in many AI research fields. Firstly, the research background and significance of data augmentation were introduced. Then, the methods of data augmentation in several common fields (including natural image recognition, character recognition and discourse parsing) were summarized, and on this basis, a detailed overview of sample acquisition or augmentation methods in the field of medical image assisted diagnosis was provided, including X-ray, Computed Tomography (CT), Magnetic Resonance Imaging (MRI) images. Finally, the key issues of data augmentation methods in AI application fields were summarized and the future development trends were prospected. It can be concluded that obtaining a sufficient number of broadly representative training samples is the key to the research and development of all AI fields. Both the common fields and the professional fields have conducted sample augmentation, and different fields or even different research directions in the same field have different sample acquisition or augmentation methods. In addition, sample augmentation is not simply to increase the number of samples, but to reproduce the existence of real samples that cannot be completely covered by small sample size as far as possible, so as to improve sample diversity and enhance AI system performance.
Key words:
Artificial Intelligence (AI); medical image; aided diagnosis; sample augmentation
0 引言
人工智能(Artificial Intelligence, AI)作為當今最為熱門的話題之一,是研究、開發用于模擬、延伸和擴展人的智能的理論、方法、技術及應用系統的一門新技術科學。AI是計算機科學的一個分支,它企圖了解智能的實質,并生產出一種新的能以人類智能相似的方式作出反應的智能機器,該領域的研究包括機器人、語言識別、圖像識別、自然語言處理等。
對所有領域AI產品的研發而言,訓練樣本的獲取都是關鍵問題之一。訓練樣本好比AI的糧食,沒有糧食,再好的AI算法也無法實現其價值[1];AI產品的質量是由其所擁有的訓練樣本數量決定的[2],訓練樣本越多,AI就越智能。那么質量達到多少才算足夠呢?99.99%的準確率表示萬無一失,但如果是自動駕駛,萬無一失意味著無人駕駛技術的失敗,準確率要訓練到至少百萬無一失可能才算合格。所以Google的自動駕駛[3]項目每天都有數百輛數據采集車行駛在路上采集數據。每輛車每天采集數據量達24TB,一年可采集一萬英里的路況數據。盡管如此,300萬英里的實際路況數據,外加10億英里的模擬軟件駕駛數據,才能達到每1000英里的脫離率為0.2(平均而言人類需要每5000英里干預一次行使)。AlphaGo熟讀16萬局網絡棋譜后,戰勝了圍棋冠軍柯潔。AlphaZero[4-5]通過基本圍棋規則自弈300萬盤,無需搜集網絡棋譜,性能超越AlphaGo,本質上是自我進行的樣本增廣。
目前AI的技術開發有個誤區,即認為AI主要做神經網絡構建和編程工作。事實上,AI從業者2/3以上的工作量都在獲取或標注訓練樣本。Google等大公司不斷向世界分享他們在算法和神經網絡結構上的最新成果,但對其訓練數據集卻很少公開,即使公開也只是其中很少一部分[6]。由此可見,神經網絡構建和算法對于AI固然重要,但如何獲取更多的訓練樣本可能更重要。目前AI領域對于算法和網絡構建關注極高,而關注訓練樣本的人卻很少。對于公知領域樣本的勾畫和標注,普通勞務人員即可完成,因而出現了一批專門為AI服務的數據公司,甚至是產業園。對于需要專業知識的樣本獲取和標注,依靠通用數據公司是無法完成的。AI應用如果按訓練樣本獲取或標注是否需要專業性可分為公知領域和專業領域。按獲取樣本量的大小可分為大樣本和小樣本領域。目前較為成熟的AI研究和應用主要集中在公知大樣本領域,其原因與樣本獲取和加工處理標注相對較為容易不無關系。但即使是公知大樣本領域(如基于人臉識別的安防、基于語音識別的同譯、基于場景識別的自動駕駛等),仍然采用了各種樣本增廣方法來提高訓練準確率。
當前AI在醫療領域的發展可謂是風生水起,而影像已然成為AI在醫療領域落地的主要突破口[7]。鑒于影像種類的多樣性和復雜性,收集醫療數據是一個耗時耗力且會耗費大量資金的過程,而且需要研究人員與專業醫生合作才能完成[8]。AI影像的一個重要特征是需要大量標準圖像和異常標注樣本圖像的輸入[9],輸入學習的樣本種類越多,AI的適應性和準確性就越高,對具體圖像的分析判斷能力就越強,所得結果越準確。但在AI醫學影像研究領域,樣本獲取存在著諸多限制[10]:1)醫療數據合法使用的法規政策尚不明確。現有醫療數據的安全規定,過于籠統缺少細則,缺乏針對性和可操作性。2)醫院和醫生提供醫療數據的動力不足。有些醫院和醫生對于提供少量標注樣本與公司進行合作科研是歡迎的,但對于需要花費大量時間和精力提供大量標注樣本進行產品開發存在嚴重的動力不足現象。3)現有醫療數據標準化沒有形成,質量參差不齊。就磁共振成像(Magnetic Resonance Imaging, MRI)圖像而言,盡管每家醫院都有海量的MRI影像,但這些影像主要是針對某個型號設備的,其種類受制于設備提供的序列和默認序列參數。且不同廠家設備的檢查序列也有差異,沒有標準化,技師也有序列或圖像表現偏好。因此采用某家公司的某種設備產出的MRI樣本進行訓練,會出現樣本種類不足、對其他廠商設備或其他種類MRI圖像診斷效果不佳的現象。另外,人體疾病有2000多種,目前AI還只能對單一疾病進行訓練,因此總會存在一些疾病種類樣本不足的問題。若AI學習的圖像樣本不足,其適應性和準確性就難以提高,這也是AI+MRI較少出產品的原因之一。
本文首先介紹了幾種公知領域(包括自然圖像識別、字符識別、語義分析)的樣本增廣方法;然后介紹了醫學影像輔助診斷方面的樣本獲取或增廣方法,包括X光片、X線計算機斷層成像(Computed Tomography, CT)圖像、MRI圖像的樣本增廣方法;最后對不同領域樣本增廣方法存在的問題進行了總結,并對未來發展趨勢進行了展望。
1 公知領域的樣本增廣方法
1.1 自然圖像識別
目前,圖像識別大多是借助計算機技術進行的,圖像識別是AI的一個重要領域,而深度學習又是近十年來人工智能領域取得的最重要突破之一[11]。與傳統的機器學習方法相比,深度學習極其依賴大規模訓練數據,它需要大量數據去理解潛在的數據模式。
深度學習在計算機視覺領域最具影響力的突破發生在2012年, Krizhevsky小組采用深度學習贏得了ImageNet[12-13]圖像分類比賽[14]。他們對原始圖像采用裁剪、水平翻轉及顏色調整的方法來增廣訓練樣本,有效減輕了過擬合現象,使top-5誤差率由26.172%降到15.315%,分類準確率超出第二名10%以上。2014年Chatfield等[15]在基于卷積神經網絡的圖像分類任務中,也使用了水平翻轉及裁剪與水平翻轉相結合的增廣方法;但他們的裁剪操作不同于Krizhevsky小組,他們從整幅圖像中進行裁剪然后水平翻轉,此操作比從一幅256×256圖像中心裁剪所獲得的性能更好。受Krizhevsky小組啟發,Raitoharju等[16]在AI識別無脊椎動物的訓練樣本時,采用旋轉和鏡像的增廣方法,該方法類似多角度拍攝樣本照片來實現樣本增廣;雖然訓練精確度提升了3%~6%,但增廣后的樣本量依然很少,可否采用其他方法,如添加噪聲[17]、抖動或裁剪某些身體部位(如頭部或尾部)等來進行數據增廣,仍需繼續探究。由此可見,Krizhevsky小組的數據增廣方法已然成為了數據增廣領域最基本、最普遍的方法,而后的一些方法大多是在此基礎上,取長補短,進一步優化改進,當然也出現了一些新的方法。
如文獻[18-20]中將自然圖像與眾多著名藝術品相結合,產生了新風格高質量的新圖像,該方法類似于選擇照相機不同色調模式采集圖像實現數據增廣;文獻[21]通過隨機化原圖像顏色、紋理和對比度,同時保留其幾何形狀和語義內容,將原圖像風格進行轉移來增加樣本量。與傳統的旋轉、隨機裁剪等增廣技術相比,該方法可生成更多語義一致且多樣化的訓練數據。但該方法受傳統神經類型風格轉移能力的限制,無法實現復雜的變換,如晝夜或季節轉換等。
為了解決上述問題,文獻[22-23]中使用生成式對抗網絡(Generative Adversarial Network, GAN)[24-26],實現了夏日風光的場景與冬季風景的相互轉換,呈現了同一景象在不同季節下的情形。其中文獻[23]采用的對抗網絡,還能實現視覺上相似的兩個目標之間的轉移,圖像風格的轉移以及由繪畫圖像得到照片圖的轉換。但此處的轉移不同于文獻[18],這里是學習模仿一整套藝術作品的風格,而非一件選定的藝術作品的風格。該方法在涉及顏色和紋理變換的任務中所得效果較好,但對于需要幾何變換的任務卻收效甚微,仍需進一步完善。
事實上,在獲取自然狀態下的樣本時,有時樣本會被遮擋,為了使模型更好地應對這一影響因素,Zhong等[27]提出了一種簡單且實用的無參數數據增強方法——隨機擦除,即隨機擦除隨機選擇的圖像矩形區域,并以隨機值擦除其像素值,進而產生具有不同遮擋程度的圖像。該方法使CIFAR10的top-1誤差率從3.72%降到了3.08%,CIFAR100的誤差率從18.68%降到了17.65%。隨機擦除與隨機裁剪、隨機水平翻轉具有一定的互補性,綜合應用這幾種方法,可取得更好的模型表現。在將來的研究中,可以考慮將該方法用于目標檢索和人臉識別任務。2018年Google科學家Cubuk等[28]提出了一種新的數據增廣方法:AutoAugment,這是一種自動化的增廣工具,其獨特之處在于它一改以往手動設計增強策略,只用強化學習就能從數據本身找出最佳圖像增強策略。既可提高訓練效果,又可消除研究人員尋找、制作數據集的煩惱。
除以上方法外,遷移學習[29-30]可極大緩解深度學習中數據不足引起的問題。其基本思想[31]是:先從其他數據源訓練得到模型,然后利用少量的目標數據對模型進行微調。對于自然圖像,可以利用文獻[32]中基于網絡的深度遷移方法,先對訓練好的模型(如VGGNet[33]、ResNet[34]、Inception V3[35]等)進行預訓練,然后用目標圖像進行微調。文獻[36]在基于卷積神經網絡對無脊椎動物分類的任務中,就是先用ImageNet圖像進行預訓練,然后用無脊椎動物的較小數據集進行微調,并獲得了很好的分類結果。該方法可大大減少訓練樣本量,并縮短訓練時間。但也存在一些困難,如需要一個相對大規模的預訓練數據;如何選擇合適的預訓練模型;如何判斷需要多少額外數據來訓練模型,等等。雖然存在許多困難,但隨著深度神經網絡的發展,遷移學習將被廣泛用于解決許多具有挑戰性的問題。
1.2 字符識別
字符識別是模式識別的一個重要應用領域,為了解決訓練樣本匱乏問題,采用數據增廣技術生產數據是目前增加樣本數量及多樣性的有效途徑[37]。
對于字符識別,也可采用平移、旋轉、尺寸縮放、水平及垂直拉伸變形的方法[38],及Simard等[39]采用的仿射變換(如平移、旋轉和傾斜)和彈性變形。事實上,1996年Yaeger等[40]就已提出與Simard等相似的筆畫扭曲增廣技術,通過傾斜、旋轉和縮放等對字符進行微小改變。后來,Bastien等[41]提出了包括局部彈性變形、對比度變化、灰度變換、添加各種噪聲及改變字符厚度[42]等19種手寫偽樣本生成方法,針對NIST-19手寫數據集,生成了超過8.19億的巨大樣本,有效解決了訓練樣本不足的問題。但該方法最大的缺點是,操作較復雜、工作量較大。此外,文獻[43]對原有Google字體庫中的樣本采用字符間距調整、添加下劃線和投影畸變的數據生產方法,并使用擴展后的數據集研究自然場景下的文本識別,達到了90.8%的識別率。鑒于上述幾何變形方法,文獻[44]在研究滿文字符識別時,除采用與文獻[41]相似的彈性變形、仿射變換、模糊變換及添加噪聲等方法外,還采用光照不均、褪色變換、背景融合及形態學處理的方法。這幾種方法不僅能增加訓練樣本量,也能很好反映真實存在的情形,如褪色變換,類似于文檔長期放置產生的褪色現象;背景融合,通過為單一字符圖像添加不同類型的背景,以此模擬字符實際使用的環境;利用形態學處理中的膨脹和腐蝕操作,則可以再現出不同粗細筆畫書寫的字符圖像。顯然,這些增廣方法對于其他字符的樣本增廣也同樣適用,同時也說明,樣本增廣并不是只關注樣本數量,所增廣的樣本還應符合真實存在的情形。
由于手寫體漢字存在結構復雜、詞匯量大、相互相似度高、不同書寫風格差異大等問題,文獻[45]利用三角函數構成非線性函數,通過選擇合適的變形參數,將給定的手寫漢字變形為24種不同的書寫風格,并通過實驗證明了該方法的有效性。該方法是否適用于其他領域,如形狀匹配、目標識別等,值得進一步研究。文獻[46]使用余弦函數對漢字圖像進行變換,使用不同的余弦函數對原始圖像處理,所得漢字的書寫風格也就不同。該方法不僅增加了樣本數量,一定程度上與提高了樣本質量。但該方法的缺陷在于,無法保證變換后的圖像都足夠好,在使用新生成的樣本前,需選出并丟棄不好的樣本。后續工作中,需繼續探究如何同時提升生成樣本的規模和質量。
此外,文獻[47]在研究合成樣本對訓練字符分類器進行數據增廣帶來的益處時,對比了在數據空間采用數據扭曲[48](對字符圖像應用仿射變換和彈性變形創建扭曲數據)和在特征空間合成過采樣技術[49-50]兩種創造額外訓練數據的方法。對于手寫體字符的識別,在數據空間采用彈性變形進行數據增廣效果較好。對于某些機器學習問題,有時無法確定原始數據樣本的轉換確實保留了標簽信息,此時可在特征空間進行數據增廣,但模型性能在訓練集與測試集上存在一定的差距,而且通過合成數據對分類器進行擴增訓練,得到的性能很可能受實際數據等效量訓練的約束。相比而言,GAN所受約束較少,并能生成大量的訓練樣本。文獻[51]提出了一種基于GAN網絡的DeLiGAN模型,將該模型在MNIST數據集中進行實驗,結果證明該模型能夠在數據量有限的條件下,生產一系列多樣化的圖片。與普通GAN模型[24]相比,該模型具有很好的穩定性,可避免變形偽跡的發生,產生的樣本具有更好的多樣性。但該模型的建立包含一些簡化的假設,限制了模型對復雜分布的估測能力,為提高模型的泛化能力,仍需對所涉及的參數繼續優化調整。以上方法可有效增廣手寫字符的樣本量,但對于離線字符[52],由于缺少書寫時的動態信息,通常很難生成一組包含足夠變化筆跡的字符。為了提高離線字符分類器的識別性能,文獻[53]提出了一種基于人工增廣實例的支持向量機離線字符識別訓練方法,文獻[54]結合扭曲模型使用映射函數從現有訓練樣本中生成大量偽樣本。文獻[53]的基本思想是:1)對真實字符的每一個筆畫作仿射變換;2)對人造字符的每一個筆畫作仿射變換,且這些變換都是在主成分分析(Principal Component Analysis, PCA)[55]的基礎上合成的。該方法可以生成一組包含足夠變化筆跡的人造字符,有效解決收集大量數據時耗時費資的問題。但該方法的數據增廣操作要在PCA基礎上才能取得很好的效果,若不使用PCA,識別率將會下降,分類時間也將變長,造成此現象的具體原因仍需進一步探討。
1.3 語義分析
語義分析的目標是通過建立有效的模型和系統,實現在各個語言單位的自動語義分析,從而實現理解整個文本表達的真實語義[56]。顯而易見,建立有效的模型是至關重要的,而數據增廣是提高模型性能的有效方法,在計算機視覺領域已得到了廣泛探討。諸如翻轉、旋轉和改變RGB強度等是視覺系統常見的做法[14],除此之外,添加噪聲、隨機插值一對圖像等方法[17]在前面的工作中也提到過。然而,這些方法并不能直接用于語義增廣,因為語言中的單詞順序可能會形成嚴格的句法語法意義,因此,其相應的增廣方法也就有所不同。
2016年斯坦福大學計算機科學系Robin和PercyJia等[57]在神經語義分析的研究中,提出了數據重組的增廣思想,即從給定的原始訓練集中,歸納出一種高精度的同步上下文無關文法,用以捕獲語義分析中常見的重要條件獨立屬性。與經典的數據增廣方法(如圖像轉換和添加噪聲等只改變輸入不改變輸出)不同,該方法在對輸入語言進行變換操作的同時也改變輸出,使新的輸入與新的輸出相匹配,進而生成更多的訓練樣例,有效提升模型精確度。此增廣思想是否具有更廣泛的適用性值得進一步探討。同年,Xu等[58]在利用深度遞歸神經網絡對兩個實體間關系進行分類的工作中,提出了一種利用句子關系的方向性進行數據增廣的技術,該技術可以在不使用外部數據資源的情況下提供額外的數據樣本,有效緩解數據稀疏問題并保持較深的網絡,提高了模型性能,對分類任務作出了一定貢獻。Jiang等[59]也于同年提出了一種為罕見語義關系訓練增廣數據的方法。其主要思想是:利用Co-training,在每次循環中,用有標注的數據對兩個語義分析器進行初步訓練,然后用這兩個分析器對未標注文檔進行分類,并產生對應的語義樹,最后經過篩選,把置信度最高的數據加入到最初有標注的數據中,進行繼續循環。該方法對罕見語義關系可達到很高的識別性能,但對常見的語義關系則是無效的。因此,對該方法的研究仍需進一步完善,以提高其對常見語義關系的識別性能。
2017年Fadaee等[60]為提高低資源語言對的翻譯質量,提出了翻譯數據增強方法,即通過改變平行語料庫中已有的句子來增廣訓練數據。他們利用在大量單語數據上訓練的語言模型,生成包含罕見單詞的新句子對,并在翻譯過程中生成更多生詞,從而提高翻譯質量。該方法對增廣低頻單詞是有效的,但是否適用于一般的翻譯任務仍無法確定。與Fadaee等的工作類似,2018年Kobayashi[61]提出了一種被稱為contextual augmentation的數據增廣方法。該方法通過使用雙向語言模型,在給定要擴展的原始單詞上下文的情況下,用對某個單詞進行預測的單詞來替換該單詞。與基于同義詞的增廣方法相比,該方法生成了與原始文本標簽兼容的各種單詞,并改進了神經分類器,且該方法不受特定任務知識的限制,可用于不同領域的分類任務。同年,哈爾濱工業大學社會計算與信息檢索研究中心,提出了面向任務的對話系統中語言理解模塊的數據增廣問題[62]。他們利用訓練數據中與一個語句具有相同語義的其他句子,提出了基于序列到序列生成的數據增廣框架,并創新性地將多樣性等級結合到話語表示中以使模型產生多樣化的語句數據,而且這些多樣化的新語句有助于改善語言理解模塊;但該方法是否存在一定的限制性,是否具有廣泛的適用性,仍需進一步探討。
以上方法單獨作用在各自的研究任務中都取得了很好的效果,若將其與別的方法相結合,是否可以取得更好的效果仍需進一步探究。近年來,GAN[24]引起了大量的研究關注。它產生對抗性例子的能力對數據增廣很具吸引力,但由于語義分析具有一定的特殊性,如何將GAN用于語義分析仍是一個有待解決的問題。
以上介紹了公知大樣本領域的數據增廣方法,可以看出,該領域的樣本增廣方法相對較為廣泛,涉及面也較廣。雖然該領域AI的應用和研究相對已經較為成熟,但依然沒有一套通用的增廣方法,對于不同的任務,需根據實際情況選擇合適的方法。因此,在今后的研究中仍需研究者提出更多有創新性、實用性的增廣方法。
2 AI+醫學影像診斷研究中的樣本增廣
2.1 AI+X光片病理判定的樣本獲取方法
為了給研究界提供足夠的訓練數據,美國國家醫學圖書館提供了兩組公開的Postero-anterior(PA)胸片數據集[63]:MC(Montgomery County chest X-ray)集和深圳集,以促進計算機輔助診斷肺部疾病的研究。兩組數據集中的影像資料分別來自美國馬里蘭州蒙哥馬利縣衛生署及中國深圳第三人民醫院,這兩組數據集都包含有結核表現的正常和異常胸部X光片。并且已有出版物[64-65]將這兩組數據集用于結核自動篩選和肺分割。其中在結核自動篩選實驗中,這兩組數據集的準確率分別達到了曲線下面積87%和90%,雖然檢測效能仍低于人類水平,但與放射科醫生的表現已相當接近[64]。雖然這兩組數據集對于結核自動篩選可取得很好的效果,但對于檢測異常胸部X光片,僅依靠這兩組數據集是不夠的,深度學習領域依然存在數據稀缺,及對標記數據的依賴性。
為了解決這一問題,文獻[66]介紹了一個更大的胸部X光片公開數據集Open I[67],它包含來自印第安納患者護理網絡的3955份放射學報告和來自醫院圖片存檔和通信系統的7470份相關的胸部X光片。該數據集免費開放,研究人員可將該數據集用于訓練計算機學習如何檢測和診斷疾病,輔助醫生作出更好的診斷決策。但該數據集所包含的胸透圖像報告沒有定量的疾病檢測結果,若將該數據集用于相關模型的訓練,是否會有影響還需進一步探討。
考慮到Open I數據集存在的問題,Wang等[68]在關于胸部X光片的診斷和病理位置定位一文中,通過自然語言處理方法從醫院圖像存檔和通信系統中,提取報告內容獲取標簽,構建了一套醫院規模的弱監督醫學圖像數據集ChestX-ray14,該數據集包含112120個單獨標注的14種不同胸部疾病的正面胸部X光片。后來,Wang等對這個數據集中的8種疾病圖像進行研究,構建了ChestX-ray8數據集。同時,斯坦福大學吳恩達教授團隊,使用ChestX-ray14數據集訓練Chex Net模型[69]進行肺炎診斷,并用隨機水平翻轉來增加訓練數據量。經充分訓練的模型,能通過胸部X光片判斷病人是否患有肺炎,且在敏感性和特異性肺炎的檢測任務上,其表現能力已超過了專業放射科醫師。但該數據集的缺點在于,胸部X線放射學報告可能不被公開分享;數據集中的圖片都是正面胸片,而背部掃描的胸片有時對診斷來說也是至關重要的;此外,該數據集中的標簽不是由放射科醫生直接提供,而是由放射科醫生的文本報告自動生成的,因此難免會出現一些錯誤的標簽。
除此之外,吳恩達教授團隊在檢測異常肌肉骨骼時,開源了MURA數據集[70],并用該數據集訓練卷積神經網絡,用以尋找并定位X光片的異常部位。MURA是目前最大的X光片數據集之一,它包含源自14982項病例的40895張肌肉骨骼X光片。基于該數據集,該團隊開發了一個有效預測異常肌肉骨骼的模型,流程如圖1所示。
經充分訓練后,將模型的表現能力與專業放射科醫生進行對比。結果發現,該模型在診斷手指和手腕X光片異常情況時,其表現比放射科醫生好,但對其他部位(如肩膀、肱部、肘部、前臂、手掌)的診斷則比放射科醫生差。值得注意的是,MURA數據集中的四萬張圖像來自近15000篇論文,其中9067篇為正常上肢肌肉骨骼X光片的研究,5915篇是異常研究。即該團隊不是直接從醫院獲取數據,而是從公開渠道獲取樣本。該方法的最大優點是所受限制較少,不足之處是需要搜集和閱讀大量的資料,且獲得的樣本質量參差不齊。表1列出了一些公開可用的醫療放射圖像數據集。
綜上可知,在深度學習領域,X光片樣本的獲取主要是從一些公開的醫療圖像數據集中得到,然后結合一些簡單的變換操作來增加訓練樣本量。在今后的研究中,仍需研究者開源出更大的數據集,以滿足AI對于臨床疾病的相關研究。
2.2 AI+CT圖像樣本增廣方法
由于CT圖像屬于單參數成像,主要反映組織密度差異,所有圖像均屬于一類圖像,即標準圖像只有一種,因此,對于CT圖像可以采用經典的數據增廣方法[14]。文獻[71]公開了一種基于3D全連接卷積神經網絡的CT圖像肺結節檢測系統,該項發明在構建訓練集時,對區域訓練集的圖像以標簽的方式分為負樣本(無結節)和正樣本(有結節),同時對有限數量的正樣本采用平移、旋轉、縮放、鏡像等幾何變換作數據多樣性增廣,類似于醫生通過不同的視角、不同的上下文去分析結節區域。采用該發明技術方案可實現結節自動檢測,無需任何人工干預,并能有效提高結節檢測的召回率,大幅降低假陽性病灶,獲得肺結節病灶區域的像素級定位、定量、定性結果。這項發明對于臨床CT圖像肺結節的檢測具有極大的幫助,但文中所用的數據增廣方法只有一些基本的幾何變換,僅使用這些簡單的變換方法,還不足以提升模型的泛化能力。
為解決上述問題,上海交通大學人工智能實驗室[72]利用深度學習搭建的肺結節自動定位篩查系統,能有效檢測CT影像中包含的微小結節、磨玻璃等各類結節,并降低假陽性誤診的發生。他們在數據處理上,除了對圖像采用旋轉、平移等幾何變換外,還利用GAN[24]對數據預處理,從隨機噪聲中產生新的結節正樣本,學習生成新形態的結節樣本,深度增廣數據多樣性,有效提升了模型泛化能力,使模型更好地處理不同形態的結節特征,達到很好的檢測效果。此為該團隊在數據處理方面與文獻[71]的最大區別之處,同時也是其成功之處所在。
此外,Frid-Adar等[73]利用GAN自動生成合成醫學圖像,并用于肝臟病變的分類任務。圖2[73]顯示了三種腫瘤病變圖像,(a)真實病變圖像,(b)合成病變圖像,其中頂行為囊腫病變圖像,中間行為轉移腫瘤病變圖像,底行為血管瘤病變圖像。
具體訓練過程為:1)先用傳統增廣方法(如平移、旋轉、翻轉和縮放)創建更大的數據集,然后將其用于訓練GAN;2)用GAN生成合成圖像作為數據增廣的額外資源;3)將傳統增廣方法得到的圖像與GAN生成的合成圖像相結合,用于訓練病灶分類器。
圖3[73]顯示了肝臟病變分類精確度隨訓練集的變化情況。由圖可知,使用合成圖像增加訓練集,比僅用傳統方法增加訓練集在性能上提高了7%,這也進一步證明了用GAN生成合成圖像來增加訓練集的有效性和可行性。
GAN最初是由Goodfellow等[24]提出的一種生成式模型,首次將其應用于合成醫學圖像生成領域的是Nie等[74],為了從給定MRI圖像中生成更真實的CT圖像,他們使用了GAN進行訓練。GAN可以生成視覺上真實的圖像,從圖2可以看
出合成的病變圖像與真實病變圖像在視覺上沒有很大差別,且該方法對于數據的增廣可以達到很好的效果。
2.3 MRI圖像的樣本增廣方法
MRI圖像的特點決定了其具有不同于其他醫學圖像的特殊性,MRI圖像的多樣性,決定了AI+醫學影像在核磁影像方面的結合較為罕見。相對而言,研究MRI圖像樣本增廣方法的人較少,但依然有研究者提出了一些可行的數據增廣方法,如文獻[75]在利用卷積神經網絡對阿爾茲海默癥進行識別的研究中,采用了Krizhevsky小組[14]所用的圖像變換的增廣方法。其具體操作是:在預處理后的一個MRI圖像中選擇多個中心點提取多幅2.5D圖像,這樣一張圖就可以增益為多幅圖片,然后使用卷積神經網絡對增益后的圖像進行訓練和識別,進而共同判決該MRI的分類。該方法不僅能從MRI中提取足夠的信息,并能有效抑制卷積神經網絡的過擬合問題。但操作過程中多個中心點的位置選擇是一個難點,而且該方法是否適用于其他病癥MRI圖像的數據增廣依然未知。此外,Thyreau等[76]在對海馬體進行分割時,開發了一種數據增強系統,該系統通過改變輸入影像的幾何形狀、邊界對比度和一般強度來增加訓練樣本量,生成每個圖像和相應目標的多種變化。他們使用這種數據增強方案,能夠從一個樣本圖生成4個合成樣本圖,有效增加訓練樣本量。但數據增廣過程中對目標掩碼圖只進行了幾何變換操作,且該系統是作用于高精度輸入圖像上的,對于低精度輸入圖像是否可以取得同樣的效果仍需進一步探索。
近年來,在醫學圖像分割中U-net網絡備受關注,為了提高模型的準確度和精度,Dong等[77]在利用該網絡進行腦腫瘤檢測和分割時,考慮到腫瘤沒有明確的形狀,簡單的變換方法,如翻轉、旋轉、平移和縮放,僅能改變圖像的位移場,并不能創建形狀不同的訓練樣本,而剪切操作雖然可以在水平方向上輕微扭曲腫瘤的整體形狀,但仍不足以獲取足夠的可變訓練數據。因此他們采用了與Ronneberger等[78]分割細胞時使用的相似的數據增廣方法——彈性變形[17],來生成更多任意形狀且與實際情形相吻合的訓練數據,有效提高了網絡的性能,并取得了很好的分割效果。值得注意的是,他們用于訓練模型的數據來自公開數據集(BRATS 2015[79]),將文中的增廣方法用于具有各向異性分辨率的臨床數據,是未來的研究方向之一。
鑒于醫學影像數據集的不平衡性,文獻[80]利用GAN來合成異常MRI圖像的方法進行數據增廣。其基本思想是:利用兩個公開的MRI數據集(ADNI和BRATS),訓練生成GAN網絡,進而合成具有腦腫瘤的異常MRI圖像。他們用合成的圖像作為數據增廣的一種形式,演示了其對改進腫瘤分割性能的有效性,并證明了當對合成數據和真實受試者數據進行訓練時,可以獲得類似的腫瘤分割效果。該方法為深度學習在醫學影像領域面臨的兩個最大挑戰(病理學發現的發生率較低及共享患者數據受到限制),提供了一個潛在的解決方案。
以上方法雖然能有效解決樣本數量問題,但在解決樣本多樣性方面,所取得的效果并不是很理想。文獻[10]介紹了一種MRI圖像樣本的自動增廣和批量標注軟件平臺(DMRIAtlas),既可以解決樣本數量問題,也能增加樣本多樣性,其工作原理是:通過定量MRI成像技術獲取正常志愿者和少量陽性病例重點病灶區的物理信息,然后利用虛擬MRI成像技術對正常或病灶區信息進行虛擬數據采集和成像,基于不同的成像序列和參數,輸出不同種類、不同表現的大量MRI圖像。借助該軟件生成的圖像可以是不同分辨率、不同信噪比、不同權重、不同b值的MRI圖像,可極大增廣訓練樣本的種類和數量。
圖4為使用該軟件對正常腦部組織同一層面采用不同序列經虛擬掃描得到的T1WI、T2WI、T1-FLAIR、T2-FLAIR和STIR的圖像[10]。
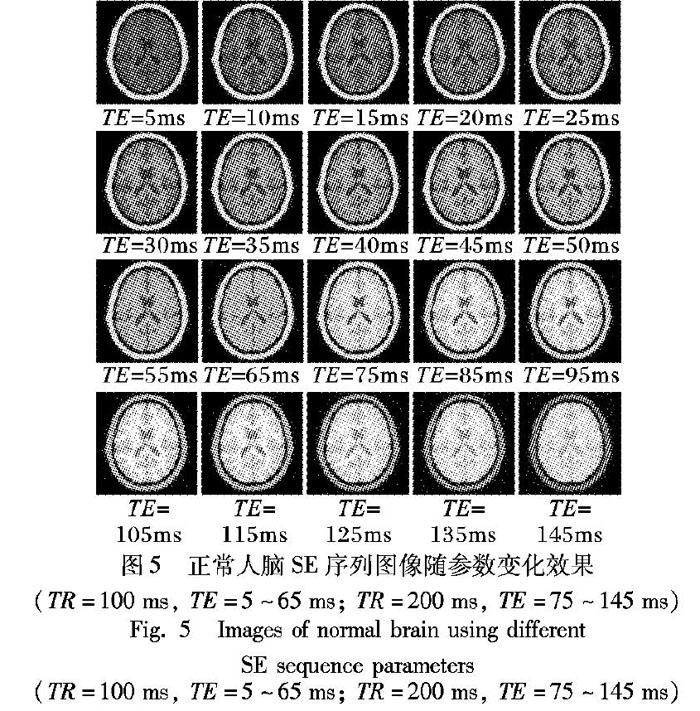
為了彌補設備差異或技師水平差異等帶來的實際圖像差異,對同種序列選取不同的序列參數,可以得到對比度和信噪比逐漸變化的圖像效果。圖5為正常人腦SE序列圖像隨參數變化(TR=100ms和200ms, TE=5~145ms)的效果圖[10]。
顯而易見,通過類似上述的簡單操作,即可得到龐大的樣本數據。在醫學影像診斷這一專業小樣本領域,該軟件作為一種通用型MRI圖像樣本增廣工具,只需采集一定數量的某種疾病不同程度陽性病例的物理信息數據,然后借助專業影像醫生的勾畫標注,或通過一些簡單的操作(如調節不同的參數、選取不同的斷面等),即可得到大量的樣本,極大降低了成本,解決了樣本數量與種類不足的問題,具有很好的應用前景。
上述內容總結梳理了醫學影像中X光片、CT圖像和MRI圖像的樣本獲取或增廣方法。當然,AI在醫學影像診斷中的應用并非只針對這三類圖像,其他醫學圖像,如醫學光學圖像,同樣也涉及到AI的應用,并且已有學者提出了AI應用于該類圖像時相應的數據增廣方法。比如,Vasconcelos等[81]在皮膚病變分析黑色素瘤的檢測任務中,采用了幾何變換增廣、顏色變換增廣以及基于專家知識的數據增廣方法,進行人工創建樣本;Ciresan等[82]在2012年的乳腺癌組織影像有絲分裂檢測挑戰賽中,應用了任意旋轉和鏡像方法來創建額外的訓練實例;等等。然而,僅從本文所述醫學圖像的數據增廣方法中就可看出,不同醫學圖像的樣本獲取或增廣方法是各不
相同的。由于醫學影像本身的復雜性,目前的方法多是針對某一具體任務而言的。因此,對于不同圖像、不同研究方向,需根據具體知識采用針對性的增廣方法。
3 結語
本文對AI在三類公知大樣本領域及專業小樣本領域(醫學影像識別和輔助診斷)的樣本增廣方法進行了全面分析。通過分析總結可知,絕大多數AI應用領域都要進行樣本增廣,且不同領域甚至同一領域的不同研究對象,其樣本獲取或增廣方法也是截然不同的。
此外,樣本增廣不是為了簡單地增加樣本數量,而是盡可能再現小樣本量無法完全覆蓋的真實樣本存在,進而提高樣本多樣性,增強AI系統性能,因此,需根據具體領域知識采用針對性的增廣方法,使增廣的數據盡可能呈現出真實情況下所出現的情形,不能一味為了增廣數據而增廣,必須從實際出發,與實際情形相吻合。
目前AI領域對于算法和網絡構建的提升及改進關注度特別高,相對而言,關注訓練樣本的人卻很少。實際上,充足的訓練數據對AI研發起著至關重要的作用,運用合適的方法進行樣本增廣就起到了舉足輕重的作用。但由于人們對樣本增廣的關注度還不夠高,現在仍處于發展階段,依然有一些問題值得進一步深入研究:
1)對于公知大樣本領域,雖然該領域獲取樣本的方法相對較多、較為成熟,但對于不同的任務,依然沒有一套統一的增廣方法。對于不同的任務,需根據具體情況選取合適的增廣方法,不可盲目增廣,要從實際出發,使增廣的數據盡可能再現出真實樣本的存在。在未來的研究中,是否可以探索出一些有效且通用的樣本增廣方法或開發出一種通用的樣本增廣工具值得進一步探究。
2)對于醫療影像領域而言,由于數據規模比較小,獲取樣本的途徑也較少且存在各種困難,因此,對樣本增廣方法多樣性和有效性的研究,將成為該領域研究的熱點,同時也是急需進一步完善的難點所在;在今后的研究中,需倡導研究者開發出更多針對某一類醫學圖像通用的樣本增廣工具(諸如DMRIAtlas軟件)。此外,醫學領域往往不僅僅依靠圖像來診斷,結合臨床信息、檢驗報告等非圖像數據的多模態學習也是值得關注的方向。
3)現有數據增廣方法中,同時適用于公知大樣本領域和醫療影像領域的方法少之又少。對于醫療影像這一小樣本領域,由于其有效的數據增廣技術相對較少、較不成熟,因此,可對公知大樣本領域中較為成熟的增廣方法進一步探究,以驗證其能否用于某些醫學圖像的增廣。
盡管對樣本增廣方法的研究還存在許多問題,但它對AI產品的研發產生的影響不容小覷。更加多樣、更有效且適用范圍更廣的增廣方法,能夠帶來更多有效的樣本,并能對AI系統的性能起到很大的提升作用。尤其對于醫療影像這一小樣本領域,如何利用有效的增廣技術獲取足夠豐富且高質量的影像數據,對提升診斷準確度起到了至關重要的作用。總之,對樣本增廣方法的研究是一個值得進一步探索的領域,在未來的研究中一定會更加成熟。
參考文獻
[1]HACKER NOON. Big challenge in deep learning: training data. Artificial intelligence for real problems: deep systems.ai.[EB/OL].[2019-05-04]. https://www.jianshu.com/p/2a3388d8c9c3
HACKER NOON. Big challenge in deep learning [EB/OL]. [2018-11-04]. https://hackernoon.com/%EF%B8%8F-big-challenge-in-deep-learning-training-data-31a88b97b282.
[2]ELIZEBETH G. AI firms lure academics [J]. Nature, 2016, 532(4): 422-423.
[3]ALEXIS C. MADRIGAL. Inside Waymos secret world for training self-driving cars [EB/OL]. [2019-01-04]. The Atlantic Daily. AUG 23,2017. https://www.yahoo.com/news/inside-waymo-apos-secret-world-152456397.html.
[4]SILVER D, SCHRITTWIESER J, SIMONYAN K, et al. Mastering the game of Go without human knowledge [J]. Nature, 2017, 550(7676): 354-359.
[5]SILVER D, HUBERT T, SCHRITTWIESER J, et al. A general reinforcement learning algorithm that masters chess, shogi and Go through self-play [J]. Science, 2018, 362(6419): 1140-1144.
[6]TING D S W, LIU Y, BURLINA P, et al. AI for medical imaging goes deep [J]. Nature Medicine, 2018,24(5): 539-540.
[7]李綱,徐鼎梁.AI+醫療:如何做好一只被風吹上天的豬[EB/OL].[2019-05-04] 財經,2018(3)(LI G, XU D L.AI+ medicine: how to make a pig that is blown to the sky [EB/OL].[2019-05-04] finance and economics,2018(3))www.sohu.com/a/222070262_487521
李綱,徐鼎梁.AI+醫療:如何做好一只被風吹上天的豬[EB/OL]. [2019-01-04]. www.sohu.com/a/222070262_487521.(LI G, XU D L. AI+ medicine: how to be a pig that is blown to the sky [EB/OL]. [2019-01-04]. www.sohu.com/a/222070262_487521.)
[8]GREENSPAN H, van GINNEKEN B, SUMMERS R M. Guest editorial deep learning in medical imaging: overview and future promise of an exciting new technique [J]. IEEE Transactions on Medical Imaging, 2016, 35(5): 1153-1159.
[9]MAXMEN A. AI researchers embrace bitcoin technology to share medical data [J]. Nature, 2018,555(7696): 293-294.
[10]汪紅志,趙地,楊麗琴,等.基于AI+MRI的影像診斷的樣本增廣與批量標注方法[J].波譜學雜志,2018,35(4):447-456.(WANG H Z, ZHAO D, YANG L Q, et al. An approach for training data enrichment and batch labeling in AI+MRI aided diagnosis [J]. Chinese Journal of Magnetic Resonance, 2018, 35(4): 447-456.)
[11]王曉剛.深度學習在圖像識別中的研究進展與展望[J].中國計算機學會通訊,2015,10(WANG X G,Research progress and prospect of deep learning in image recognition[J],Communication of the Chinese computer Federation Oct,2015)
王曉剛.深度學習在圖像識別中的研究進展與展望 [EB/OL]. [2019-01-10]. http://www.360doc.com/content/15/0604/11/20625606_475573792.shtml.(WANG X G. Research progress and prospect of deep learning in image recognition [EB/OL]. [2019-01-10]. http://www.360doc.com/content/15/0604/11/20625606_475573792.shtml.)
[12]DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// Proceedings of the 2009 Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2009: 248-255.
[13]RUSSAKOVSKY O, DENG J, SU H, et al. ImageNet largescale visual recognition challenge [J]. International Journal of Computer Vision, 2015, 115(3): 211-252.
[14]KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// Proceedings of the 2012 International Conference on Neural Information Processing Systems. North Miami Beach, FL, USA: Curran Associates, 2012: 1097-1105.
[15]CHATFIELD K, SIMONYAN K, VEDALDI A, et al. Return of the devil in the details: delving deep into convolutional nets [J]. Computer Science, 2014:1-12
CHATFIELD K, SIMONYAN K, VEDALDI A, et al. Return of the devil in the details: delving deep into convolutional nets [EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1405.3531.pdf.
[16]RAITOHARJU J, RIABCHENKO E, MEISSNER K, et al. Data enrichment in fine-grained classification of aquatic macroinvertebrates [C]// Proceedings of the ICPR 2nd Workshop on Computer Vision for Analysis of Underwater Imagery. Washington, DC: IEEE Computer Society, 2016: 43-48.
[17]ZHANG H Y, CISSSE M, DAUPHIN Y N, et al. Mixup: beyond empirical risk minimization [EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1710.09412.pdf.
[18]GATYS L A, ECKER A S, BETHGE M. Image style transfer using convolutional neural networks [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 2414-2423.
[19]JOHNSON J, ALAHI A, LI F. Perceptual losses for real-time style transfer and super-resolution [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9906. Berlin: Springer, 2016: 694-711.
[20]GATYS L A, ECKER A S, BETHGE M. A neural algorithm of artistic style [EB/OL]. [2019-01-04]. https://arxiv.org/pdf/1508.06576.pdf.
[21]JACKSON P T, TAPOUR-ABARGHOUEI A, BONNER S, et al. Style augmentation: data augmentation via style randomization [EB/OL]. [2019-01-04]. https://arxiv.org/pdf/1809.05375v1.pdf.
[22]RAJ B. Data augmentation: how to use deep learning when you have limited data [EB/OL]. [2019-01-04]. https://www.kdnuggets.com/2018/05/data-augmentation-deep-learning-limited-data.html.
[23]ZHU J, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision.? Washington, DC: IEEE Computer Society, 2017: 2242-2251.
[24]GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014: 2672-2680.
[25]林懿倫,戴星原,李力,等.人工智能研究的新前線:生成式對抗網絡[J].自動化學報,2018,44(5):775-792.(LIN Y L, DAI X Y, LI L, et al. The new frontier of AI research: generative adversarial networks [J]. Acta Automatica Sinica, 2018, 44(5): 775-792.)
[26]ANTONIOU A, STORKEY A, EDWARDS H. Data augmentation generative adversarial networks [EB/OL]. [2019-01-04]. https://arxiv.org/pdf/1711.04340.pdf.
[27]ZHONG Z, ZHENG L, KANG G, et al. Random erasing data augmentation [EB/OL]. [2019-01-04]. https://arxiv.org/pdf/1708.04896.pdf.
[28]CUBUK E D, ZOPH B, MANE D, et al. AutoAugment: learning augmentation policies from data [EB/OL]. [2019-01-04]. https://arxiv.org/pdf/1805.09501.pdf.
[29]Sebastian Ruder. Transfer learning—machine learnings next frontier [EB/OL]. [2019-01-04]. http://ruder.io/transfer-learning/.
[30]PAN S J, YANG Q. A survey on transfer learning [J]. IEEE Transaction on Knowledge and Data Engineering, 2010, 22(10): 1345-1359.
[31]YOSINSKI J, CLUNE J, BENGIO Y, et al. How transferable are features in deep neural networks? [J] In Advances in Neural Information Processing Systems 27 (NIPS 14),NIPS Foundation,2014.
YOSINSKI J, CLUNE J, BENGIO Y, et al. How transferable are features in deep neural networks? [EB/OL]. [2019-01-04]. https://arxiv.org/pdf/1411.1792.pdf.
[32]TAN C, SUN F, KONG T, et al. A survey on deep transfer learning [C]// Proceedings of the 2018 International Conference on Artificial Neural Networks, LNCS 11141. Berlin: Springer: 270-279.
[33]SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL].[2019-01-04]. https://arxiv.org/pdf/1409.1556.pdf.
[34]HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016:770-778.
[35]SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision [EB/OL]. [2019-01-04]. https://arxiv.org/pdf/1512.00567.pdf.
[36]RIABCHENKO E, MEISSNER K, AHMAD I, et al. Learned vs. engineered features for fine-grained classification of aquatic macroinvertebrates [C]// Proceedings of the 23rd International Conference on Pattern Recognition. Piscataway, NJ: IEEE, 2016: 2276-2281.
[37]金連文,鐘卓耀,楊釗,等.深度學習在手寫漢字識別中的應用綜述[J].自動化學報,2016,42(8):1125-1141.(JIN L W, ZHONG Z Y, YANG Z, et al. Applications of deep learning for handwritten Chinese character recognition: a review [J]. Acta Automatica Sinica, 2016, 42(8): 1125-1141.)
[38]LeCUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition [J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[39]SIMARD P Y, STEINKRAUS D, PLATT J C. Best practices for convolutional neural networks applied to visual document analysis [C]// Proceedings of the 7th International Conference on Document Analysis and Recognition. Washington, DC: IEEE Computer Society, 2003: 958-962.
[40]YAEGER L, LYON R, WEBB B. Effective training of a neural network character classifier for word recognition [C]// Advances in Neural Information Processing Systems, 1997: 807-816.
YAEGER L, LYON R, WEBB B. Effective training of a neural network character classifier for word recognition [C]// Proceedings of the 9th International Conference on Neural Information Processing Systems. Denver, Colorado: [s.n.], 1997:807-816.
[41]BASTIEN F, BENGIO Y, BERGERON A, et al. Deep self-taught learning for handwritten character recognition [EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1009.3589v1.pdf.
[42]VARGA T, BUNKE H. Generation of synthetic training data for an HMM-based handwriting recognition system [C]// Proceedings of the 7th International Conference on Document Analysis and Recognition. Piscataway, NJ: IEEE, 2003: 618-622.
[43]JADERBERG M, SIMONYAN K, VEDALDI A, et al. Synthetic data and artificial neural networks for natural scene text recognition [EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1406.2227.pdf.
[44]畢佳晶,李敏,鄭蕊蕊,等. 面向滿文字符識別的訓練數據增廣方法研究[J].大連民族大學學報,2018,20(1):73-78.(BI J J,LI M, ZHENG R R, et al. Research on training data augmentation methods for Manchu character recognition [J] . Journal of Dalian Minzu University, 2018, 20(1): 73-78.)
[45]JIN L, HUANG J, YIN J, et al. Deformation transformation for handwritten Chinese character shape correction[C]// Proceedings of the 3rd International Conference on Multimodal Interfaces, LNCS 1948. Berlin: Springer, 2000: 450-457.
[46]CHEN G, ZHANG H, GUO J. Learning pattern generation for handwritten Chinese character using pattern transform method with cosine function [C]// Proceedings of the 2006 International Conference on Machine Learning and Cybernetics. Piscataway, NJ: IEEE, 2006: 3329-3333.
[47]WONG S C, GATT A, STAMATESCU V, et al. Understanding data augmentation for classification: when to warp? [EB/OL]. [2019-01-04]. https://arxiv.org/pdf/1609.08764.pdf.
[48]BAIRD H S. Document image defect models [M]// BAIRD H S, BUNKE H, YAMAMOTO K. Structured Document Image Analysis. Berlin: Springer, 1992: 546-556.
[49]CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over-sampling technique [J]. Journal of Artificial Intelligence Research, 2002, 16(1): 321-356.
[50]DEVRIES T, TAYLOR G W. Dateset augmentation in feature space [EB/OL]. [2019-01-04]. https://arxiv.org/pdf/1702.05538.pdf.
[51]GURUMURTHY S, SARVADEVABHATLA R K, BABU R V. DeLiGAN: generative adversarial networks for diverse and limited data [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 4941-4949.
[52]楊明,劉強,尹忠科,等.基于輪廓追蹤的字符識別特征提取[J].計算機工程與應用 2007,43(20):207-209.(YANG M, LIU Q, YIN Z K, et al. Feature extraction in character recognition based on contour pursuit [J]. Computer Engineering and Applications, 2007, 43(20): 207-209.)
[53]MIYAO H, MARUYAMA M. Virtual example synthesis based on PCA for off-line handwritten character recognition [C]// Proceedings of the 7th International Workshop on Document Analysis Systems, LNCS 3872. Berlin: Springer, 2006: 96-105.
[54]LEUNG K C, LEUNG C H. Recognition of handwritten Chinese characters by combining regularization, Fishers discriminant and distorted sample generation [C]// Proceedings of the 10th International Conference on Document Analysis and Recognition. Piscataway, NJ: IEEE, 2009: 1026-1030.
[55]趙元慶,吳華.多尺度特征和神經網絡相融合的手寫體數字識別[J].計算機科學,2013,40(8):316-318.(ZHAO Y Q, WU H. Hand written numeral recognition based on multi-scale features and neural network [J]. Computer Science, 2013, 40(8): 316-318.)
[56]張敏,韓先培,張家俊,等.中文信息處理發展報告(2016)[R].北京:中國中文信息學會,2016.(ZHANG M, HAN X P, ZHANG J J, et al. Chinese information processing development report (2016)[R]. Beijing: Chinese Information Society, 2016.)
[57]JIA R, LIANG P. Data recombination for neural semantic parsing [C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2016: 12-22.
[58]XU Y, JIA R, MOU L, et al. Improved relation classification by deep recurrent neural networks with data augmentation [EB/OL].[2019-01-04]. https:arxiv.org/pdf/1601.03651.pdf.
[59]JIANG K, CARENINI G, NG R T. Training data enrichment for infrequent discourse relations [EB/OL]. [2019-01-04]. https://www.aclweb.org/anthology/C16-1245.
[60]FADAEE M, BISAZZA A, MONZ C. Data augmentation for low-resource neural machine translation [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2017: 567-573.
[61]KOBAYASHI S. Contextual augmentation: data augmentation by words with paradigmatic relations [C]. //Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2018), New Orleans, Louisiana, June 1-6, 2018:452-457.
KOBAYASHI S. Contextual augmentation: data augmentation by words with paradigmatic relations [EB/OL]. [2019-01-04]. https://arxiv.org/pdf/1805.06201.pdf.
[62]HOU Y, LIU Y, CHE W, et al. Sequence-to-sequence data augmentation for dialogue language understanding [C] // The 27th International Conference on Computational Linguistics. Santa Fe, New Mexico August 20-26, 2018: 1234-1245
HOU Y, LIU Y, CHE W, et al. Sequence-to-sequence data augmentation for dialogue language understanding [EB/OL]. [2019-01-04]. https://arxiv.org/pdf/1807.01554.pdf.
[63]JAEGER S, CANDEMIR S, ANTANI S, et al. Two public chest X-ray datasets for computer-aided screening of pulmonary diseases [J]. Quantitative Imaging in Medicine and Surgery, 2014, 4(6): 475-477.
[64]JAEGER S, KARARGYRIS A, CANDEMIR S, et al. Automatic tuberculosis screening using chest radiographs [J]. IEEE Transactions on Medical Imaging, 2014, 33(2): 233-245.
[65]CANDEMIR S, JAEGER S, PALANIAPPAN K, et al. Lung segmentation in chest radiographs using anatomical atlases with nonrigid registration [J]. IEEE Transactions on Medical Imaging, 2014, 33(2): 577-590.
[66]DEMNER-FUSHMAN D, KOHLI M D, ROSENMAN M B, et al. Preparing a collection of radiology examinations for distribution and retrieval [J]. Journal of the American Medical Informatics Association, 2016, 23(2): 304-310.
[67]Open-i. Open access biomedical image search engine [DB/OL]. [2019-01-04]. https://openi.nlm.nih.gov.
[68]WANG X, PENG Y, LU L, et al. Chest X-ray8: hospital-scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 3462-3471.
[69]RAJPURKAR P, IRVIN J, ZHU K, et al. CheXNet: radiologist-level pneumonia detection on chest X-rays with deep learning [EB/OL]. [2019-01-04]. https://arxiv.org/pdf/1711.05225.pdf.
[70]RAJPURKAR P, IRVIN J, BAGUL A, et al. MURA dataset: towards radiologist-level abnormality detection in musculoskeletal radiographs [EB/OL]. [2019-01-04].https://stanfordmlgroup.github.io/competitions/mura/.
[71]程國華,陳波,季紅麗.基于3D全連接卷積神經網絡的CT圖像肺結節檢測系統[P].中國,CN 201710173432.6[P]. 2017-07-11(CHENG G H, CHEN B, JI H L. CT image pulmonary nodule detection system based on 3D fully connected convolutional neural network [P].China, CN 201710173432.6[P].2017-07-11)
程國華,陳波,季紅麗. 基于3D全連接卷積神經網絡的CT圖像肺結節檢測系統: CN201710173432.6[P/OL].2017-07-11[2019-01-04]. http://www2.drugfuture.com/cnpat/search.aspx.(CHENG G H, CHEN B, JI H L. CT image pulmonary nodule detection system based on 3D fully connected convolutional neural network: CN201710173432.6[P/OL]. 2017-07-11[2019-01-04]. http://www2.drugfuture.com/cnpat/search.aspx.)
[72]上海交通大學人工智能實驗室如何用AI定位肺結節[EB/OL]。[2019-05-04].https://www.jiqizhixin.com/articles/2017-10-24
機器之心.天池大數據競賽第一名,上海交通大學人工智能實驗室如何用AI定位肺結節[EB/OL]. [2019-01-04].https://www.jiqizhixin.com/articles/2017-10-24.(Heart of Machine. How to locate pulmonary nodules with AI in artificial intelligence laboratory of Shanghai Jiaotong University which is Tianchi Big Data Competition No. 1[EB/OL]. [2019-01-04]. https://www.jiqizhixin.com/articles/2017-10-24.)
[73]FRID-ADAR M, KLANG E, AMITAI M, et al. Synthetic data augmentation using GAN for improved liver lesion classification [C]// Proceedings of the IEEE 15th International Symposium on Biomedical Imaging. Piscataway, NJ: IEEE, 2018: 289-293.
[74]NIE D, TRULLO R,? LIANG J, et al. Medical image synthesis with context-aware generative adversarial networks [C]// Proceedings of the 2017 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 10435. Berlin: Springer, 2017: 417-425.
[75]林偉銘,高欽泉,杜民.卷積神經網絡診斷阿爾茲海默癥的方法[J].計算機應用,2017, 32(12):3504-3508.(LIN W M, GAO Q Q, DU M. Convolutional neural network based method for diagnosis of Alzheimers disease [J]. Journal of Computer Applications, 2017, 32(12): 3504-3508.)
[76]THYREAU B, SATO K, FUKUDA H, et al. Segmentation of the hippocampus by transferring algorithmic knowledge for large cohort processing [J]. Medical Image Analysis, 2018,43: 214-228.
[77]DONG H, YANG G, LIU F, et al. Automatic brain tumor detection and segmentation using U-net based fully convolutional networks [C]// Proceedings of the 2017 Annual Conference on Medical Image Understanding and Analysis, CCIS 723. Berlin: Springer, 2017: 506-517.
[78]RONNEBERGER O, FISCHER P, BROX T. U-net: convolutional networks for biomedical image segmentation [C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Berlin: Springer, 2015:234-241.
[79]MENZE B H, JAKAB A, BAUER S, et al. The multimodal brain tumor image segmentation benchmark (BRATS) [J]. IEEE Transactions on Medical Imaging, 2015, 34(10): 1993-2024.
[80]SHIN H, TENEHOLTZ N A, ROGERS J K, et al. Medical image synthesis for data augmentation and anonymization using generative adversarial networks [EB/OL]. [2019-01-04]. https://arxiv.org/pdf/1807.10225.pdf.
[81]VASCONCELOS C N, VASCONCELOS B N. Increasing deep learning melanoma classification by classical and expert knowledge based image transforms [EB/OL].[2019-01-04]. https:// arxiv.org/pdf/1702.07025v1.pdf.
[82]CIRESAN D C, GIUSTI A, GAMBARDELLA L M, et al. Mitosis detection in breast cancer histology images with deep neural networks [C]// Proceedings of the 2013 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 8150. Berlin: Springer, 2013: 411-418.
This work is partially supported by the Shanghai Pujiang Talent Plan (17PJ1432500).
WEI Xiaona, born in 1986, M.S. candidate. Her research interests include deep learning,medical image processing.
LI Yinghao, born in 1999. His research interests include machine learning, image reconstruction.
WANG Zhenyu, born in 1996, M. S. candidate. His research interests include deep learning, medical image processing.
LI Haozun, born in 1996. His research interests include deep learning, image reconstruction.
WANG Hongzhi, born in 1975, Ph. D., associate professor. His research interests include magnetic resonance imaging technology, medical image analysis.
猜你喜歡
西安航空學院學報(2022年2期)2022-07-04 07:45:42
汽車零部件(2020年3期)2020-03-27 05:30:20
表面工程與再制造(2019年1期)2019-05-11 08:52:04
商界(2019年12期)2019-01-03 06:59:05
家庭影院技術(2018年9期)2018-11-02 05:31:34
IT經理世界(2018年20期)2018-10-24 02:38:24
通信電源技術(2018年3期)2018-06-26 06:33:30
軍營文化天地(2018年1期)2018-02-10 05:19:25
小康(2017年16期)2017-06-07 09:00:59
學與玩(2017年12期)2017-02-16 06:51:12
