基于衰減式生成對抗網絡的單幅圖像陰影去除
2019-10-31 09:21:33廖斌譚道強吳文
計算機應用 2019年9期
廖斌 譚道強 吳文


摘 要:圖像中的陰影是投影物體的重要視覺信息,但也會對計算機視覺任務造成影響。現有的單幅圖像陰影去除方法因魯棒陰影特征的缺乏或訓練樣本數據的不足與誤差等原因,無法得到好的陰影去除結果。為了準確生成用于描述陰影區域光照衰減程度的蒙版圖像,進而獲得高質量的無陰影圖像,提出了一種基于衰減式生成對抗網絡的單幅圖像陰影去除方法。首先,敏感因子引導的衰減器被用來提升訓練樣本數據,為后續的生成器與判別器提供符合物理光照模型的陰影樣本圖像。其次,生成器將結合感知損失,并在判別器的督促下得到最終陰影蒙版。與相關研究工作比較,所提方法能有效恢復陰影區域的光照信息,可以得到更為逼真、陰影邊界過渡更加自然的無陰影圖像。利用客觀指標評價陰影去除結果。實驗結果表明,該方法能在多個真實場景下有效去除陰影,去陰影結果視覺一致性良好。
關鍵詞:圖像處理;陰影去除;生成對抗網絡;衰減器;光照模型
中圖分類號:TP391.41
文獻標志碼:A
Single image shadow removal based on attenuated generative adversarial networks
LIAO Bin*, TAN Daoqiang, WU Wen
School of Computer Science and Information Engineering, Hubei University, Wuhan Hubei 430062, China
Abstract:
Shadow in an image is important visual information of the projective object, but it affects computer vision tasks. Existing single image shadow removal methods cannot obtain good shadow-free results due to the lack of robust shadow features or insufficiency of and errors in training sample data. In order to generate accurately the shadow mask image for describing the illumination attenuation degree and obtain the high quality shadow-free image, a single image shadow removal method based on attenuated generative adversarial network was proposed. Firstly, an attenuator guided by the sensitive parameters was used to augment the training sample data in order to provide shadow sample images agreed with physical illumination model for a subsequent generator and discriminator. Then, with the supervision from the discriminator, the generator combined perceptual loss function to generate the final shadow mask. Compared with related works, the proposed method can effectively recover the illumination information of shadow regions and obtain the more realistic shadow-free image with natural transition of shadow boundary. Shadow removal results were evaluated using objective metric. Experimental results show that the proposed method can remove shadow effectively in various real scenes with a good visual consistency.
Key words:
image processing; shadow removal; generative adversarial network; attenuator; illumination model
0 引言
陰影雖能為圖像深度和物體幾何形狀預估等計算機視覺研究工作提供重要依據,但其存在也會加大物體檢測、目標跟蹤等任務的難度。因此,在諸多計算機視覺應用中需要去除圖像中的陰影。單幅圖像陰影去除一直是計算機視覺和圖像處理領域的一個研究熱點。
陰影去除常包含陰影定位和去陰影這兩個步驟。在陰影定位過程中,文獻[1-3]中使用陰影檢測的方法,文獻[4-5]中使用人工交互標注的方法確定陰影的位置,然后再分別使用自定義的特征對全陰影和半陰影區域進行重建。然而,陰影檢測本身就十分困難。傳統基于物理模型的方法僅僅在處理高清圖像時才能得到不錯的效果。基于統計學習的方法則過度依賴自定義的陰影特征[2]。用戶交互雖然能準確地定位陰影,但處理大數據量圖像時非常耗時耗力。利用卷積神經網絡表征學習的能力,文獻[2]和文獻[6]中的深度網絡能夠學習陰影檢測所需要的特征,但受到數據集規模的限制,這兩個網絡層次都較淺。此外,這兩種方法以區域塊的形式運用卷積神經網絡,后續還要進行全局優化以保持圖像的連貫性。在去陰影過程中,已有的陰影去除方法大致可分為以下兩類。文獻[7-10]中的方法均基于梯度域去陰影,而文獻[1,2,4,11-12]中的方法均基于圖像顏色域去陰影。文獻[8-9]中通過比較光照不變圖和原始RGB圖像進行陰影檢測,然后提出一系列基于梯度的方法進行陰影去除。但這些基于梯度的方法僅僅只改變陰影邊界或半陰影區域的梯度變量,因此對于全陰影區域的光照變量并不適用。基于顏色域的陰影去除方法通常采用分類[1-2]和用戶交互[11-12]的方法區分全陰影和半陰影區域。其中,文獻[2]中使用兩個獨立的卷積神經網絡對陰影進行檢測并區分全陰影和半陰影區域,然后基于貝葉斯公式的方法提取描述陰影區域光照衰減程度的蒙版圖像。文獻[12]中在全陰影和半陰影區域分別使用不同的低級特征,使用馬爾可夫隨機場找出半陰影區域,然后使用強度表面恢復法去除陰影。文獻[13]中基于棧式條件生成對抗網絡提出了一種多任務學習的方法,將陰影檢測與陰影去除并行,能得到不錯的效果。文獻[14]中繞開了陰影檢測環節,通過圖像本征分解得到無陰影的圖像。但是,基于本征圖像的方法可能會改變非陰影區域的顏色。文獻[15]中提出了一種基于卷積神經網絡的方法,結合圖像中陰影的外表模型以及語義模型構建多語境結構,為陰影圖像生成陰影蒙版,從而達到陰影去除的效果,但因為沒有從根源上選擇誤差較低的訓練集,使得陰影去除圖像的像素在全局均會發生變化,這并不符合陰影去除的初衷。
基于以上問題和不足,本文基于一種新的生成對抗網絡進行單幅圖像的陰影去除,能為待處理的陰影圖像生成更為準確的陰影蒙版圖像,從而得到更為真實的無陰影圖像。根據文獻[7]可知,陰影圖像可由無陰影圖像和陰影蒙版圖像在像素級別上相乘得到,因此得到了陰影蒙版圖像就能得到陰影去除圖像。所提網絡由衰減器、生成器和判別器等3個部分構成。首先,為了減小樣本存在的誤差,篩選訓練樣本。利用帶敏感因子的衰減器生成額外的樣本訓練網絡以提高所提模型的擬合能力。衰減器的輸入為樣本陰影圖像和標注陰影區域的陰影二值掩膜構成的四通道圖像,旨在生成新的符合物理光照模型的陰影圖像。這些新的數據一方面能擴大數據集增加模型的可靠性以及擬合能力,另一方面生成的圖像與經過篩選的訓練樣本一樣,與它們對應的真實無陰影圖像具有較小的誤差,這能提高模型訓練的精度。其次,在衰減器提供充足訓練樣本的前提下,生成器結合感知損失函數,旨在生成準確的陰影蒙版;而判別器不斷更新,并給予生成器反饋。最終判別器與衰減器、生成器達到平衡。然后直接將待處理陰影圖像作為生成器的輸入就能直接得到其對應的陰影蒙版圖像。
本文的主要貢獻:1)提出一種基于衰減式生成對抗網絡的陰影去除框架,能為待處理的陰影圖像生成對應的陰影蒙版,從而實現陰影去除;2)提出了一種帶敏感因子的衰減器,能夠生成不同衰減程度且符合物理光照模型的陰影衰減圖像,以作為額外可靠的數據集;3)與傳統的生成器不同,本文將結合感知損失,并與判別器進行對抗訓練,以大幅度提高生成蒙版的準確性,得到更自然的無陰影圖像,在多個測試數據集上均能得到良好的結果。
1 衰減式生成對抗網絡
傳統基于陰影蒙版的陰影去除方法在估算陰影蒙版時需要提前定位陰影的位置。而定位陰影常常需要做陰影檢測[1-2]或者使用用戶交互的方式[4-5]標注出陰影的位置。因陰影檢測的過程本身就十分具有挑戰性,且這一過程常常因為缺乏魯棒的陰影特征[1,16-17]造成陰影檢測不夠準確或只在處理高清圖像時才能得到較好的結果[18]。基于用戶交互的方式雖然能更為準確地定位陰影的位置,但整個檢測過程缺乏全自動性,大批量處理圖像時,需要較多的資源。生成對抗網絡[19-21]作為一種圖像生成模型無需提前定位陰影的位置,也可應用于生成陰影蒙版。文獻[19]提出的生成對抗網絡由一個生成器G和一個判別器D組成。生成器接收一個隨機噪聲從而生成一幅逼真的圖像。判別器從訓練集中學習從而判斷生成器生成的圖像是真還是假。這兩個部分是博弈關系。生成器生成圖像旨在讓判別器難以辨別真假,從而從訓練集中學習出數據的分布。文獻[20]則進一步拓展文獻[19],允許在生成器和判別器中引入額外的條件變量。文獻[21]基于文獻[20],使用一幅輸入圖像作為約束條件,訓練生成對抗網絡以生成另一幅圖像。利用深度神經網絡自動學習特征的能力,可以大幅減小因人為選定特征而對結果造成的誤差。由此,根據文獻[21],將樣本陰影圖像作為約束條件,旨在讓生成器生成逼真的陰影蒙版,以達到當前判別器無法分辨的程度;而判別器在提高自己判別能力的同時也激勵著生成器能力的提升;直至判別器無法辨認生成器生成的圖像的真假之后,使用式(1)[7]計算得到無陰影圖像:
x=y·x′(1)
其中:x為陰影圖像;y為陰影蒙版,表示由陰影造成的光照衰減效應;x′為無陰影圖像。
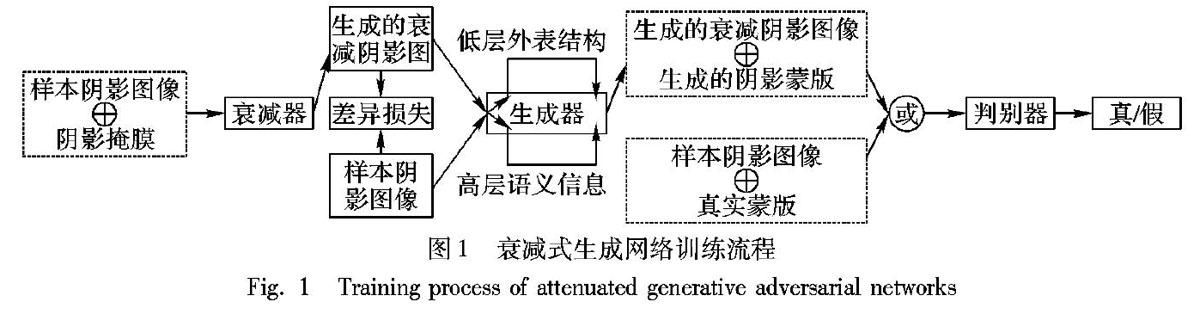
文獻[21]對于陰影圖像中非陰影區中偏暗的區域、光照衰減程度多樣化的陰影區域以及陰影邊界處理能力較差,導致無法生成準確的陰影蒙版,從而無法得到真實的無陰影圖像。受到文獻[22]的啟發,該文使用一個卷積神經網絡為主體進行陰影檢測,可以提供額外的訓練數據,用以提高網絡的泛化能力,從而使得網絡能夠準確地區分非陰影區域中顏色偏暗區域和真實的陰影的區域。同樣,本文在生成對抗網絡的基礎之上,引入一個衰減器A實現類似于文獻[22]的功能,以提高整體網絡的泛化能力。但文獻[22]只應用于陰影檢測,方法仍然具有較大的局限,雖然基于光照模型,能生成較為逼真的衰減陰影圖像,但其在訓練階段,每次僅能為樣本陰影圖像生成一幅衰減的陰影圖像,而且衰減的程度不可控制,有些樣本中的陰影衰減程度較高,而還有很多樣本幾乎不衰減。基于以上這些問題,本文進一步提出敏感因子引導的衰減器輔以生成對抗網絡進行訓練,每次訓練通過調整步長來控制敏感因子的取值,從而來生成相對于輸入圖像不同衰減程度的陰影圖像。在本文中將所提網絡稱為衰減式生成對抗網絡。通過增大可靠的衰減陰影圖像樣本,所提網絡的處理能力得到大幅度增強,其訓練流程如圖1所示。
衰減式生成對抗網絡由一個衰減器、一個生成器以及一個判別器組成。為了減小樣本存在的誤差,使用像素的均方根誤差(Root Mean Square Error,RMSE)[23]篩選客觀數據集作為所提網絡的訓練樣本。樣本訓練集中每組圖像將由樣本陰影圖像、標識陰影位置的陰影二值掩膜、真實的無陰影圖像、樣本陰影圖像的真實陰影蒙版這四幅圖像組成。如圖1所示,訓練過程中,衰減器的輸入為訓練樣本中的陰影圖像及其陰影檢測的二值掩膜結果,其中⊕表示將三通道的RGB陰影圖像和單通道的二值陰影檢測結果堆疊成為四通道的輸入,而受到敏感因子的引導與差異損失的約束,衰減器能夠生成多幅符合物理光照模型的圖像。生成器使用衰減器的輸出作為額外的訓練數據,結合感知損失,旨在生成準確的陰影蒙版。判別器判斷衰減器產生的陰影衰減圖像和生成器生成的陰影蒙版是否為真,同時給予衰減器以及生成器信息反饋,以達到相互促進相互學習的目的。網絡訓練完畢后,便可舍棄衰減器與判別器,直接將待處理的陰影圖像作為生成器的輸入,即可得到其對應的陰影蒙版,結合式(1)便能得到陰影去除結果。
2 網絡構成細節
2.1 敏感因子引導的衰減器
衰減器的引入可以為后續生成器提供符合物理光照模型的訓練數據集,而使用敏感因子作為引導則可以控制原始陰影圖像中陰影區域的衰減程度以及數量,這將極大程度地提高模型對于多種場景下不同程度陰影的處理能力。敏感因子引導的衰減器加強了非陰影區域中顏色偏暗區域的識別能力,從而生成更加合理、準確的陰影蒙版。在訓練過程中,為衰減器構造合適的損失項并形成損失目標函數以達到以上目的。
設M(x)是陰影圖像x的陰影掩膜,A(x)為衰減器A關于x和M(x)的輸出。首先,為了讓衰減器的輸出在非陰影區域的像素值保持不變,構建損失項L1旨在抑制x在非陰影區域中像素的改變,如式(2)所示:
L1(x)=∑iM(x)(A(x)i-xi)2(2)
其中i表示的是像素的序號。
其次,衰減器生成的圖像應該遵守物理光照模型。生成圖像在陰影區域中的所有像素改變的幅度應該盡可能一致,如式(3)所示:
L2(x)=∑c∈{R,G,B}V(ln(A(x)ci-ln(xci)))(3)
其中:L2是物理損失,確保生成器生成的圖像是真實可信的。(·)c表示一個像素在c通道上的像素值,c∈{R,G,B}。V(·)為求方差運算,其衡量了各個像素變化量的離散程度。
僅僅使用上述的兩種條件作為約束并不能生成衰減程度一致的衰減圖像,每次衰減也只能得到一幅隨機衰減程度的圖像,因此,衰減器還應該有控制其衰減敏感度的敏感因子參數μ。衰減器雖然仍然受限于輸入的場景圖像,但通過調節μ能生成衰減程度不同的陰影圖像用于衰減式生成對抗網絡的訓練。同時,參數μ也權衡生成圖像與樣本陰影圖像在陰影區域之間的差異。如式(4)所示:
L3(x)=∑i∈M(x),μ∈[0,1](μxi-A(x)i)2(4)
其中L3是敏感損失。當μ接近于1的時候,優化目標函數時,會使得陰影內部像素在滿足物理約束的基礎上,不會改變太多。通過改變μ的大小。就可以產生衰減不同程度的陰影圖像。在實驗過程中, μ在[0,1]中采樣,步長為0.2,則可將原始訓練集擴大5倍。
最終,衰減器A的損失目標函數由損失項L1、L2、L3加權得到,如式(5)所示:
LA(x)=λ1L1(x)+λ2L2(x)+λ3L3(x)(5)
如圖2所示,給出了不同敏感因子取值所得到的陰影衰減圖像。圖2(a)為樣本陰影圖像。圖2(b)是通過文獻[22]生成的衰減圖像,衰減程度不可控,且只能生成單幅衰減圖像。圖2(c)、圖2(d)、圖2(e)分別為3個不同的敏感因子控制的圖像。通過比較,較大的μ得到的圖像,其陰影區域的顏色深度越接近樣本陰影圖像;反之,較小的μ將會得到陰影較弱的圖像,值得注意的是,受到式(2)的約束,衰減器生成的陰影圖像在非陰影區域是不會改變的。使用不同衰減程度圖像訓練所提網絡中的生成器,將使得生成器的能力顯著提升。
衰減器的內部結構如表1所示。其中,卷積層5(3)表示第5個卷積層重復3次;ReLU為激活函數;BN為批標準化[24];4/4表示衰減器的輸入為一幅四通道圖像,分別由三通道的RGB陰影圖像和單通道的陰影二值掩膜組成,其輸出是一幅在陰影區域存在衰減效果的陰影圖像,該圖像同樣為RGB三個通道,表示為3/3。
2.2 多語境嵌入的生成器和判別器
在衰減式生成對抗網絡中,衰減器A輸出的圖像A(x)(包括生成的衰減圖像和原始的樣本圖像)作為生成器G的輸入。生成器G將A(x)作為條件變量,旨在生成陰影蒙版G(A(x))。G試圖模擬由輸入圖像A(x)和樣本真實陰影蒙版y組成的訓練數據的分布。判別器D的輸入為(A(x),y)或(A(x),G(A(x))),并且需要判斷該組圖像是否是真的訓練數據。構建目標函數如式(6)所示:
G=Ex,y~pdata(x,y)[ln D(A(x),y)]+Ex~pdata(x)[ln(1-D(A(x),G(A(x))))+λ4LL1(G)(6)
LL1(G)=Ex,y[‖y-G(A(x))‖](7)
其中:x~pdata(x)為x服從pdata(x)分布,E為求期望運算。
針對如何在去除陰影過程中提高陰影邊緣的清晰度這一問題,為鼓勵生成圖像G(A(x))與真實陰影蒙版y差距更小,在實驗過程中增加1個額外的感知損失,LL1距離(真實圖像和生成圖像)。此時判別器的損失不變,生成器的損失變了。加入LL1后可在陰影邊緣局部減少陰影模糊程度,提高清晰度。LL1一方面在鼓勵生成圖像要盡量靠近目標圖像,一方面使用感知損失協助生成圖像在語義上與目標圖像更為相近。
生成器的內部結構與衰減器,而判別器的內部結構如表2所示,其本質同樣是一個卷積神經網絡,其中,LReLU為激活函數。6/6表示判別器的輸入是一個圖像對,分別是陰影圖像和陰影蒙版圖像。將RGB陰影圖像和RGB的陰影蒙版圖像堆疊成六通道作為判別器的輸入。陰影圖像為衰減器的輸出,其中包括樣本陰影圖像與陰影衰減圖像。而陰影蒙版圖像有可能來源于樣本真實陰影蒙版或來源于生成器為樣本陰影圖像生成的陰影蒙版圖像。判別器的輸出為圖像對是否為真的概率,即陰影蒙版是該樣本陰影圖像對應的陰影蒙版的可能性。
2.3 網絡訓練細節
衰減式生成對抗網絡的訓練可視為衰減器、生成器與判別器之間的一場博弈,并可形式化為求解目標函數,如式(8)所示:
minA,G maxD LA(x)+G(8)
如式(8)所示,衰減器與生成器一組與判別器進行對抗訓練,判別器旨在最大化目標函數,而衰減器和生成器卻試圖最小化目標函數。
為了求解目標函數(8),達到局部最優解,在選取激活函數時,應該注意如下問題。衰減器/生成器的學習率通常較小,可以使用ReLU 加快訓練速度。在判別器輸出層使用 Sigmoid。這是因為Sigmoid在特征相差明顯時的效果很好,在循環過程中會不斷地增強特征效果。而判別器的其他層均選用收斂速度快又不易使神經元壞死的 LReLU。這是因為ReLU 函數雖然收斂速度快,但其最大的缺點是當輸入小于零時的梯度為 0,這樣就導致負值的梯度被設置為 0,此時神經元會處于失活狀態,不會對任何數據有所反應,尤其是當學習率很大時,神經元會大面積壞死 ,
使用Tensorflow[26]實現本文網絡,LReLU的斜率設置為0.2。使用了Adam優化方法和一個交替梯度更新策略求解式(8)。首先,固定衰減器和生成器中的權值,采用梯度下降更新判別器中的權值;然后同理,固定判別器中的權值不變,使用梯度下降更新生成器和衰減器中的權值。而在更新生成器中的權重時,優先訓練外表結構分支和語義分支,然后再將這兩個分支通過一個卷積層連接到一起,則可完成生成器的一次迭代。按照均值為0、方差為0.2的正態分布初始化衰減器、生成器和判別器中所有的卷積層和反卷積層的權重,設置偏置值為0。數據增大采用圖像裁剪的方法,將原始286×286的圖像隨機裁剪成多個256×256的子圖像,得到4張子圖,然后進行水平翻轉得8張子圖進一步增大數據集。通過大量實驗,當λ1=0.2,λ2=0.3,λ3=0.3,λ4=0.2時可以得到較好的結果。
3 實驗結果分析
本文實驗中使用Ubantu 18.04操作系統,內存為8GB,雙核Inter CPU I5,圖像處理器(GPU)采用NVIDIA GTX 1080Ti。在數據集部分,挑選UIUC(University of Illinois at Urbana-Champaign)[1]、ISTD(a new Dataset with Image Shadow Triplets)[13]和SRD(a new Dataset for Shadow Removal)[15]這3個有代表性的數據集進行測試。其中:SRD[15]包含3088組陰影和無陰影圖像;UIUC[1]包含76組陰影和無陰影圖像;ISTD[13]包含1870組陰影、陰影掩膜和無陰影圖像。本文經過一系列預處理,便于提供給所提網絡學習。具體地,首先,篩選上述3個數據集中一共5034組圖像,使用RMSE計算陰影圖像和真實無陰影圖像在非陰影區域的誤差,選取誤差最少且場景多樣的800組圖像。
然后,將這800組圖像中陰影圖像和無陰影圖像相減,在3個通道上設置閾值為20,再進行形態學濾波,最后人工調整錯誤的陰影像素標簽,為數據集得到相應的陰影二值掩膜作為其陰影檢測的結果,其中來自于ISTD的數據因自帶了陰影檢測結果則跳過這一步驟。最后為每組圖像補充上真實陰影蒙版構成每四幅圖像一組的綜合篩選數據集。抽取綜合篩選數據集中20%的數據用于本文方法的可行性檢驗。挑選綜合篩選數據集中的幾組圖像作為示例,如圖3所示。
理以及人工標注修正的陰影二值掩膜。圖3(d)真實陰影蒙版,其體現了陰影造成的光照衰減效應,為RGB三通道圖像。
在綜合篩選數據集中選取四幅圖像,從獲取陰影蒙版角度,將本文方法與文獻[15]的方法進行比較,文獻[15]提出了一種基于卷積神經網絡的方法,其構建多語境結構,為陰影圖像生成陰影蒙版,該方法十分具有代表性,而且也能得到不錯的結果。分別使用文獻[15]與本文方法為陰影圖像生成陰影蒙版,結果如圖4所示。
圖4(c)中因為文獻[15]的方法使用的訓練數據集存在較大誤差,使得后續的陰影去除結果在非陰影區域也會存在大量的變化。如圖4(f)所示,無論是海報上的人物、草地上、墻上以及地面上的陰影,在恢復之后明顯會出現過亮的情況,導致陰影邊界尤為明顯。而觀察圖4(d),本文方法能夠得到更加準確的陰影蒙版。比較圖4(b)和圖4(d),可以發現,在陰影以外的區域,本文方法幾乎不會存在虛假的蒙版信息,這使得本文方法在后續的無陰影圖像中,在非陰影區域幾乎不會發生變化,結果更加合理。如圖4(g)所示,可以發現這四組實驗中,本文方法因為能夠得到準確的陰影蒙版,使得無陰影結果在非陰影區域得到了完整的信息保留,相比文獻[15]方法,陰影邊界過渡更加自然。
在綜合篩選數據集中挑選四幅不同場景的陰影圖像,從陰影去除的角度,將本文方法與文獻[1]和文獻[13]的方法進行比較。這兩種方法非常具有代表性:文獻[1]的方法基于傳統機器學習的方法,使用自定義的陰影特征,先將陰影檢測出來,然后基于物理光照模型將陰影去除;文獻[13]的方法利用基于條件生成對抗網絡的多任務學習方法,能夠同時進行陰影檢測和陰影去除任務。陰影去除的結果如圖5所示。
從圖5可以看出,文獻[1]的方法因使用缺乏魯棒性人為定義的陰影特征,從而導致陰影檢測的不精準,最終無法得到令人滿意的陰影去除結果。如第一行中草地上遮陽傘的部分陰影、第二行中水泥地面上較淺的陰影、第三行中大面積地貼磚、第四行中手持磚塊的人物陰影均無法得到準確的檢測,從而導致這些區域均未經處理。文獻[13]的方法相比文獻[1]的方法能夠得到更好的結果,但是復原區域存在明顯的亮度偏高、輕度模糊的情況,圖像整體過渡不均勻,例如第一行到第三行中依然能夠看到遮陽傘的輪廓,第四行中人物的軀干,這說明深度網絡對于陰影的檢測與識別能力已經遠遠超過了基于自定義特征陰影檢測能力,但是在去除能力上仍然具有較大的上升空間。樣本場景的不足、精度的不夠以及沒有結合感知損失等原因造成深度網絡陰影去除能力的不足。本文方法繼承了深度神經網絡的特征學習能力,為陰影圖像直接生成陰影蒙版。衰減器生成的衰減的陰影圖像作為強大的數據支撐,使得模型對于任意程度的陰影都有較為魯棒的識別能力,拓展了模型的泛化能力。引入感知損失的生成器能夠生成更為精準的陰影蒙版圖像,從而能夠得到好的陰影去除結果。本文方法處理這4幅圖像時,還原的陰影區域的亮度信息更為準確,陰影邊界過渡更為自然的同時減少對非陰影區域像素的改變,圖像整體更為均勻。在綜合篩選數據集上,使用RMSE和結構相似度(Structural SIMilarity index, SSIM)[23]作為衡量指標,將本文方法與上述具體代表性的單幅圖像陰影去除方法進行客觀數據比較。其中RMSE計算了去陰影圖像和真實無陰影圖像對應的每個像素的誤差,而SSIM反映了結構信息,其更符合人類視覺的感知。
將本文方法與文獻[1,13,15]的方法進行量化評估,如表3所示。測試圖像為綜合篩選數據集的20%,這些圖像均具有相應的真實無陰影圖像、陰影檢測結果。將陰影去除圖像與真實無陰影圖像從陰影區域、非陰影區域以及整體區域進行量化分析,分別計算測試圖像的RMSE與SSIM值的平均值。RMSE值越低說明陰影去除圖像與真實無陰影圖像之間的誤差越小,SSIM值越大說明陰影去除圖像從結構上與真實無陰影圖像之間更為相似。因為文獻[1]的方法基于傳統機器學習方法,對陰影區域缺乏魯棒的特征導致陰影檢測十分不準確,從而導致不能擁有較好的陰影去除結果,所以在RMSE上具有較大的誤差,在SSIM上相似度也偏低。文獻[15]的方法基于卷積神經網絡提出一種端到端的陰影蒙版
生成方式,但因其受到訓練樣本的限制,在深淺程度不同的陰影場景下,不能得到較好的陰影去除結果,其RMSE和SSIM上的表現雖然相比文獻[1]的方法有了較大提升,但仍然具有較大的上升空間。文獻[13]的方法基于多任務學習使用兩個聯合的生成對抗網絡分別完成陰影檢測和陰影去除的工作,同樣受到訓練數據集的約束且并未考慮生成圖像和目標圖像之間的感知損失。因此其結果雖優于文獻[15]的方法,但仍然沒有本文方法好。本文方法在該誤差評估上具有最低的誤差值以及最高的結構相似度。基于傳統學習方法的文獻[1]方法消耗時間較長,文獻[13,15]的方法和本文方法均基于深度學習,在訓練好模型后進行預測,在算法時間上有明顯優勢。
4 結語
本文為得到體現陰影圖像中光照衰減效應的陰影蒙版圖像,從而得到更加真實、自然的無陰影結果,提出一種新的陰影去除框架。所提框架由一個帶敏感因子的衰減器、一個生成器以及一個判別器組成。帶有敏感因子的衰減器能夠以不同的程度生成符合物理光照模型的陰影圖像,這大大地增加了訓練數據的數量,同時也增加了模型對于不同程度陰影的識別與處理能力。生成器使用衰減器的輸出作為額外的訓練數據用于訓練,結合了感知損失,旨在生成逼真的陰影蒙版。判別器判斷衰減器產生的陰影衰減圖像和生成器生成的陰影蒙版是否為真,同時給予生成器信息反饋,使其能與生成器共同進步。在客觀數據集上,對所提方法進行了諸多實驗,在像素的均方根誤差以及結構相似性上均能得到較好的成績。下一步,將會把所提框架應用于視頻去陰影領域,同時解決無陰影視頻結果在幀與幀之間的時空連貫性。
參考文獻
[1]GUO R, DAI Q, HOIEM D. Paired regions for shadow detection and removal [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(12): 2956-2967.
[2]KHAN S H, BENNAMOUN M, SOHEL F, et al. Automatic shadow detection and removal from a single image [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(3): 431-446.doi:10.1109/TPAMI.2015.2462355.
[3]張營,朱岱寅,俞翔,等.一種VideoSAR動目標陰影檢測方法[J].電子與信息學報,2017,39(9):2197-2202. doi: 10.11999/JEIT161394.ZHANG Ying, ZHU Daiyin, YU Xiang, et al.. Approach to moving targets shadow detection for VideoSAR[J]. Jounal of Electronics & Information Technology, 2017, 39(9): 2197-2202. doi: 10.11999/JEIT161394.
張營,朱岱寅,俞翔,等.一種VideoSAR動目標陰影檢測方法[J].電子與信息學報,2017,39(9):2197-2202.(ZHANG Y, ZHU D Y, YU X, et al. Approach to moving targets shadow detection for VideoSAR [J]. Journal of Electronics and Information Technology, 2017, 39(9): 2197-2202.)
[4]ZHANG L, ZHANG Q, XIAO C. Shadow remover: image shadow removal based on illumination recovering optimization [J]. IEEE Transactions on Image Processing, 2015, 24(11): 4623-4636.doi:10.1109/TIP.2015.2465159.
[5]ZHANG L, ZHU Y, LIAO B, et al. Video shadow removal using spatio-temporal illumination transfer [J]. Computer Graphics Forum, 2017, 36(7): 125-134.doi:10.1111/cgf.13278.
[6]SHEN L, CHUA T W, LEMAN K. Shadow optimization from structured deep edge detection [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2015: 2067-2074.doi:10.1109/CVPR.2015.7298818.
[7]LIU F, GLEICHER M. Texture-consistent shadow removal [C]// Proceedings of the 2008 European Conference on Computer Vision, LNCS 5305. Berlin: Springer, 2008: 437-450.doi:10.1007/978-3-540-88693-8_32.
[8]FINLAYSON G D, HORDLEY S D, DREW M S. Removing shadows from images [C]// Proceedings of the 2002 European Conference on Computer Vision, LNCS 2353. Berlin: Springer, 2002: 823-836.doi:10.1007/3-540-47979-1_55.
[9]FINLAYSON G D, HORDLEY S D, LU C, et al. On the removal of shadows from images [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(1): 59-68.doi:10.1109/TPAMI.2006.18.
[10]MOHAN A, TUMBLIN J, CHOUDHURY P. Editing soft shadows in a digital photograph [J]. IEEE Computer Graphics and Applications, 2007, 27(2): 23-31.doi:10.1109/MCG.2007.30.
[11]CHUANG Y, CURLESS B, SALESIN D H, et al. A Bayesian approach to digital matting [C]// Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2001, 2: 264.
[12]ARBEL E, HEL-OR H. Shadow removal using intensity surfaces and texture anchor points [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(6): 1202-1216.
[13]WANG J, LI X, HUI L, et al. Stacked conditional generative adversarial networks for jointly learning shadow detection and shadow removal [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2018: 1788-1797.
[14]BARRON J T, MALIK J. Shape, illumination, and reflectance from shading [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(8): 1670-1687.
[15]QU L, TIAN J, HE S, et al. DeshadowNet: a multi-context embedding deep network for shadow removal [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2017: 2308-2316.
[16]ZHU J, SAMUEL K G G, MASOOD S Z, et al. Learning to recognize shadows in monochromatic natural images [C]// Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2010: 223-230.
[17]LALONDE J, EFROS A A, NARASIMHAN S G. Detecting ground shadows in outdoor consumer photographs [C]// Proceedings of the 2010 European Conference on Computer Vision, LNCS 6312. Berlin: Springer, 2010: 322-335.
[18]FINLAYSON G D, DREW M S, LU C. Entropy minimization for shadow removal [J]. International Journal of Computer Vision, 2009, 85(1): 35-57.
[19]GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014, 2: 2672-2680.
[20]MIRZA M, OSINDERO S. Conditional generative adversarial nets [C]// Proceedings of the 2014 Advances in Neural Information Processing Systems. Montreal,Canada: [s.n.], 2014: 2672-2680.
[21]ISOLA P, ZHU J, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 5967-5976.
[22]LE H, VICENTE T F Y, NGUYEN V, et al. A+D net: training a shadow detector with adversarial shadow attenuation [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11206. Berlin: Springer, 2018: 680-696.
[23]施文娟,孫彥景,左海維,等.基于視頻自然統計特性的無參考移動終端視頻質量評價[J].電子與信息學報,2018,40(1):143-150.(SHI W J, SUN Y J, ZUO H W, et al. No-reference mobile video quality assessment based on video natural statistics [J]. Jounal of Electronics and Information Technology, 2018, 40(1): 143-150.
[24]IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// Proceedings of the 32nd International Conference on International Conference on Machine Learning. Lille, France: [s.n.], 2015: 448-456.
[25]JOHNSON J, ALAHI A, LI F. Perceptual losses for real-time style transfer and super-resolution [C]// Proceedings of the 2016 European Conference on Computer Vision, LNCS 9906. Berlin: Springer, 2016: 694-711.
[26]WONGSUPHASAWAT K, SMILKOV D, WEXLER J, et al. Visualizing dataflow graphs of deep learning models in TensorFlow [J]. IEEE Transactions on Visualization and Computer Graphics, 2018, 24(1): 1-12.
This work is partially supported by the National Natural Science Foundation of China(61300125).
LIAO Bin, born in 1979, Ph. D., professor. His research interests include image and video processing.
TAN Daoqiang, born in 1995, M. S. candidate. His research interests include computer image processing.
WU Wen, born in 1994, M. S. candidate. His research interests include image video processing.
