基于Hadoop平臺的數據挖掘算法的研究
2019-11-03 14:07:16王紅勤潘正軍袁麗娜
電腦知識與技術 2019年23期
關鍵詞:大數據
王紅勤 潘正軍 袁麗娜
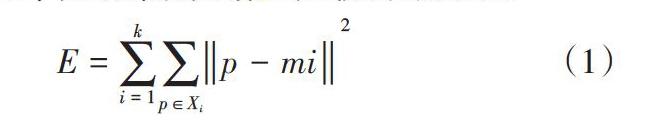
摘要:在深入分析傳統數據挖掘方案已經不能滿足大數據的挖掘任務的基礎上,為了提高大數據環境下的數據挖掘速度,對分布式計算構架 Hadoop 進行分析與研究。文中搭建了Hadoop云計算平臺的數據挖掘系統,對數據挖掘算法中聚類算法K-Means進行了設計,在Hadoop平臺上實現了K-Means算法的優化,使用Hadoop分布式系統進行數據挖掘任務具有良好的效率,分析結果表明了其具有較大的潛力。
關鍵詞:數據挖掘算法;大數據;Hadoop平臺
中圖分類號:TP391? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2019)23-0009-03
開放科學(資源服務)標識碼(OSID):
隨著移動互聯網的發展,每日所產生地數據量呈現指數級增長,對于海量的非結構的數據來說,傳統的數據挖掘技術已經無能為力。如何從這些數據中獲取有用的信息,便成了關鍵問題。開源云計算平臺Hadoop的出現,適應了這種海量數據挖掘的需求。
根據大數據環境的特點,為進一步提升數據挖掘的效率,研究相應的數據挖掘算法變得十分的迫切。本文選擇將數據挖掘的算法運行在Hadoop分布式[1]云計算平臺上,對聚類算法K-Means進行研究,并且在該平臺上實現了K-Means算法[2],由于較合適的初始K值難以確定,在Hadoop平臺上對該算法進行改進,改進后的K-Means算法,計算速度快,可以高效地處理海量數據[3]。
1 相關技術介紹
1.1 Hadoop簡介
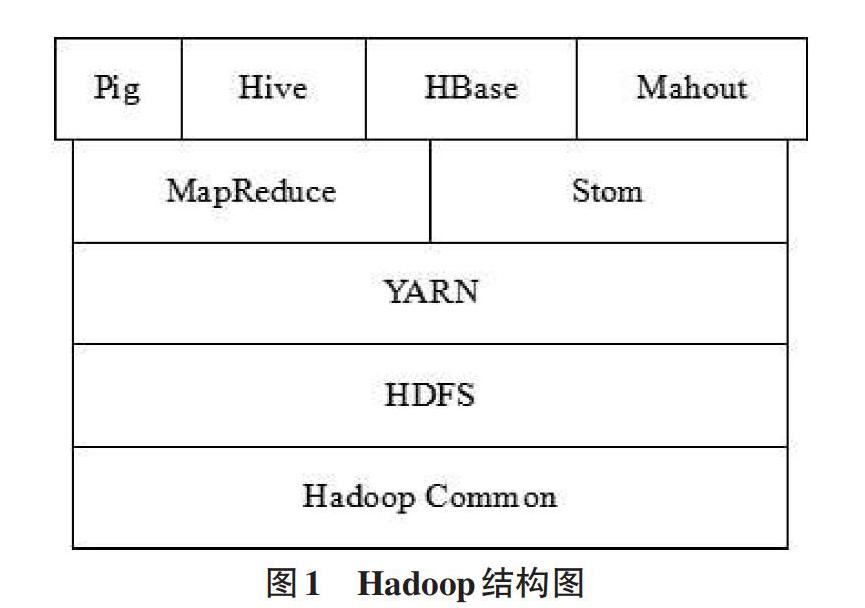
Hadoop是一款穩定的、可擴展的、可用于分布式計算的開源軟件。它是一個允許使用簡單編程模型實現跨越計算機集群進行分布式大型數據集處理的框架。Hadoop結構如圖1所示,Hadoop核心模塊主要由HDFS、MapReduce兩大模塊組成,其中HDFS實現多臺機器上的數據存儲,MapReduce實現多臺機器上數據的計算[4]。
Hadoop 2時代中,HDFS(Hadoop Distributed File System,Hadoop分布式文件系統)與資源管理器YARN(Yet Another Resource Negotiator)結合,使得HDFS上存儲的內容可以被更多的框架使用,提高資源利用率,YARN也為MapReduce大型數據集并行處理技術提供了便利。
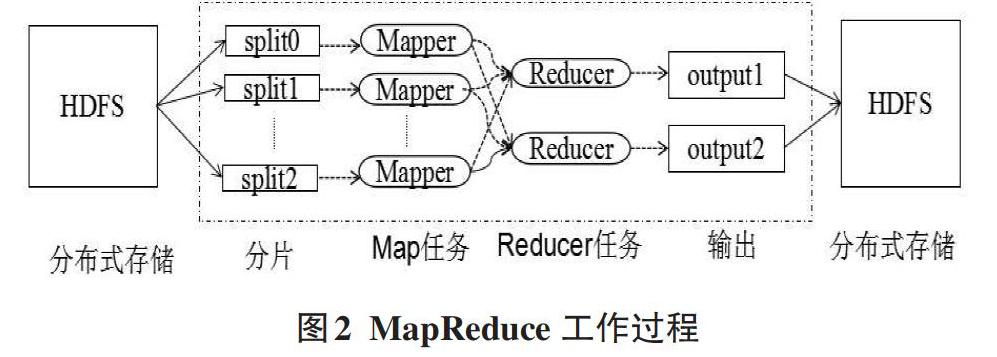
MapReduce是一種分布式計算框架,它用于并行地處理大規模的數據集,它利用Map和Reduce函數來完成復雜的并行計算。MapReduce在處理數據時,首先從HDFS中取出數據塊,進行分片,每個分片對應一個Mapper任務,Mapper計算的結果通過Reducer進行匯總,得出最終的結果進行輸出。Hadoop的MapReduce工作過程如圖2所示。
1.2 數據挖掘
數據挖掘是從大量的、不完全的、有噪聲的、模糊的、隨機的數據中提取有用的信息。通常數據挖掘需要有數據清理、數據變換、數據挖掘實施過程、模式評估和知識表示等8個步驟。數據挖掘的過程需要反復執行,從而達到提取有用數據的目的。
數據挖掘根據數據的類型和數據的特點,選擇相應的挖掘算法。常用的數據挖掘算法有K-Means,C4.5,SVM,Apriori, PageRank等等。
2 基于Hadoop平臺的K-Means挖掘算法
2.1 Hadoop數據挖掘平臺的搭建
數據挖掘接合Hadoop平臺,采用并行化計算的思維,構建Hadoop集群的數據挖掘平臺,該平臺集成了數據的存儲、分析與處理過程。基于的Hadoop 集群的數據挖掘平臺如圖3所示。
該平臺引入的HDFS分布式存儲模式,主要對海量數據進行挖掘。數據挖掘初期,對數據進行查詢、分析,接下來對數據進行預處理,任務分配,在Hadoop大數據處理層,采用MapReduce、HDFS,使用相應的數據挖掘算法(算法層主要包括K-Means、SVM等算法),進行數據建模,從海量的數據中,挖掘出有用的數據。經數據挖掘后,再進行數據分析,可以發現重要的數據流,得出一些重要的結論,
2.2 聚類算法K-Means
聚類是將一組數據按照相似性歸成若干類別,這樣的一組數據對象的集合叫作簇,對每一個這樣的簇都要進行描述。它的目的是使得屬于同一類別的數據之間的距離盡可能小而不同類別上的個體間的距離盡可能的大。
K-means算法, 也被稱為K-平均或K-均值算法,是一種得到最廣泛使用的聚類算法。 它是將各個聚類子集內的所有數據樣本的均值作為該聚類的代表點,算法的主要思想是通過迭代過程把數據集劃分為不同的類別,使得評價聚類性能的準則函數達到最優(平均誤差準則函數E),從而使生成的每個聚類(又稱簇)內緊湊,類間獨立。
K-means聚類算法使用平均誤差準則函數來評價其聚類性能,給定數據集X,其中只包含描述屬性,不包含類別屬性。假設X包含k個聚類子集X1,X2,…XK;各個聚類子集中的樣本數量分別為n1,n2,…nk;各個聚類子集的均值代表點(也稱聚類中心)分別為m1,m2,…mk。E代表所有對象的平方誤差總和,P代表數據對象,mi是數據集Xi的平均值。E值越小,說明聚類的結果質量越高。誤差平方和準則函數公式如(1)所示。
[E=i=1kp∈Xip-mi2]? ? ? ? ? ? ? ? ? ? ? ? (1)
3 改進后K-Means算法的設計與實現
由于原K-Means算法存在一些問題,如K值人工輸入、K個中心的初始位置難以確定、孤立點會使類聚結果偏離中心等。我們將對K-Means算法進行優化,基于Hadoop,對其實現并行化優化。
3.1 K-Means算法的設計與實現過程
在Hadoop集群環境中,使用K-Means算法,并行化處理該流程。K-Means算法的并行化處理的過程:將所有的數據,分布到不同的節點上,每個節點只對自己的數據進行計算,每個節點能夠讀取上一次迭代生成的聚類中心,并計算本節點里的數據應該屬于哪一個聚類中心,每一個節點迭代中根據自己的數據,產生新的聚類中心。
K-Means算法的并行處理是一個不斷循環迭代的過程,分為三個階段:Map階段、Combine階段和Reduce階段。
Map階段:該過程主要讀取數據文件,且讀取上一次迭代結果中的聚類中心值,編寫map()函數處理,并產生新的聚類中心。在map()函數,構造全局變量centerString,centerString用于保存上一次迭代的聚類中心值,讀取一個數據,函數就計算一次數據與原聚類中心的距離,將其中的最小值賦值給centerpoint,計算出來的centerpoint是新的聚類中心。
Map階段的主要部分代碼如下:
String str=value.toString();
String[] centerString=str.split("| | | | ");
double[] centerpoint=new double[m];
System.out.println(pointString.length);
if (pointString.length==60) {
for (int i = 0; i < m; i++) {
centerpointt[i]=Double.parseDouble(str[i]);
}
int minCent=-1;
double distance=0.0d;
double minDistance=Double.MAX_VALUE;
System.out.println(minDistance);
Combine階段:在此階段,將Map階段處理后的聚類進行處理 ,求出所有聚類中心的平均值,當數據處理完成后,MapTask對所有的平均值進行一次合并,生成整個簇的平均值,即為整個簇的均值。
Reduce階段:每個reduce收到某一個簇的信息,包括該簇 的id以及該簇的數據點的均值及對應于該均值的數據點的個數pointNum,經過Reduce后,輸出當前的迭代計數、均值及屬于該質心的數據點的個數。
Reduce階段主要部分代碼如下:
String strSting;
String[] pointString;
double[] center=new double[m];
for (int i = 0; i < m; i++) {
center[i]=0;
}
int pointNum=0;
for (Text vaule:values) {
line=values.toString();
pointString=line.split("| | | | | |");
for (int i = 0; i < m; i++) {
center[i]=Double.parseDouble(pointString[i]);
pointNum++;
}
for (int i = 0; i < m; i++) {
center[i]/=pointNum;
result=result+point[i];
}
result=result+Key.toString();
context.write(NullWritable.get,new Text(result));
}
}
3.2 實驗結果
為了測試改進后的K-Means算法的性能,實驗中分別設定10000、100000、1000000、2000000、3000000條記錄的數據來進行測試,對每一組實驗重復執行30次,計算平均值作為最終的結果。為了實驗結果的準確性,實驗采用由5臺機器構成的集群環境和3臺機器構成的集群環境進行測試,測試的結果如表1所示。
實驗結果表明,在Hadoop集群環境中,使用優化后的K-Means算法,運行的效率遠遠高于傳統的算法。數據規模越大,性能就越好。
為了驗證數據的可伸縮性,實驗將選擇5組不同數目的節點進行實驗,他們分別是1個、3個、5個、7個和9個。觀察實驗結果,我們會發現,隨著節點數目地増加,完成算法的所用時間如圖4所示,實驗測試結果中,橫坐標表示節點數,縱坐標表示完成時間且單位為103s。
從實驗的運行結果可以看出,隨著Hadop集群中節點數的不斷增多,每個任務所需要的時間在逐漸減少。通過實驗,說明優化后的算法,能夠有效用于大數據的處理。
4 結束語
大數據時代已經到來,為了提高大數據環境下的數據挖掘速度,本文設計了基于 Hadoop平臺的數據挖掘環境,研究了K-Means算法原理和執行流程,并使用MapReduce編程思想,對K-Means算法進行了優化,并通過實驗證明了,在云計算平臺的集群中,使用K-Means算法進行數據挖掘的處理,具有較好的挖掘高效率和良好的擴展性能。
參考文獻:
[1] 王宏志,李春靜.Hadoop集群程序設計與開發[M].人民郵電出版社,2018:32.
[2] 韓雅雯.kmeans 聚類算法的改進及其在信息檢索系統中的應用[D].云南大學,2016.
[3] 黃奇鵬,盧山.海量關系數據去重處理技術研究與優化[J].計算機與數字工程,2018,10.
[4] 魯焱.大數據共享平臺的系統架構與建設思路[J].圖書館理論與實踐,2017(04):86-90.
[5] 徐浙君.云計算下的一種數據挖掘算法的研究[J].科技通報,2018(11) :209.
[6] Issa J.Performance characterization and analysis for Hadoop K-Means iteration[J].Journal of Cloud Computing 2016,5 (1):1-15.
【通聯編輯:代影】
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
