利用姿態信息實現異常行為檢測
2019-11-05 11:14:52鄭爽張軼
現代計算機 2019年27期
鄭爽,張軼
(四川大學計算機學院,成都610065)
0 引言
異常行為檢測是計算機視覺領域具有重要應用價值的一個領域。異常行為檢測在公共安全防護,家庭老人防護中都有重要的意義。隨著時間的發展,公共場所,如ATM 機附近,交通要道的安全越來越受重視,監控隨處可見,但要24 小時監控,預防或阻止異常時間的發生需要投入極大的人力和物力[1]。若監控設備能夠檢測異常事件并報警,則能有效地阻止異常事件的發生。如在家庭中,如果獨居老人摔倒或者暈倒,監控可以及時報警,也能使老人得到及時的救治;在智能交通中,如能及時發現撞人逃逸則能讓交管部門采取主動行動。
在深度學習興起以后,將其應用到異常行為檢測領域中,使得這個領域有了很大的進步。但要做到準確、及時地檢測到異常行為依然存在巨大的困難,其主要體現在:①不同場景下的異常行為類型不同,很難直接定義。②在某個場景下正常行為發生的次數多,異常行為發生的次數少,數據非常不平衡。本文采用了如文獻[2]的異常檢測方法直接使用正常數據進行訓練,通過重構誤差來檢測異常行為、應對數據不平衡問題,并提出結合姿態特征來提高網絡的準確率。
1 相關工作
1.1 異常行為檢測
異常行為檢測是行為識別的子領域[1],近年來在基于深度學習的行為識別領域,最突出的兩種網絡就是雙流網絡和C3D 網絡[3],其他的方法大多數是兩種網絡的改進。
雙流網絡利用了兩個二維深度卷積網絡,分別處理視頻幀和幀間的光流。視頻幀中包含了行為的空間信息,而光流包含了視頻的運動信息。在分別提取兩種信息特征以后進行混合,得以同時利用視頻幀的空間和運動信息[4]。最初的雙流網絡缺點是能處理的行為時間比較短,不能提取長時間行為的特征,且準確率有待提高[3]。于是有了許多改進的網絡架構:如文獻[5-6]中提到的方法,通過在訓練過程中混合特征來提高準確率。文獻[7]提出分段提取行為特征并進行混合使網絡可以處理更長時間段的行為。上述網絡都依賴光流,但光流的提取也耗費時間。Tran D 等人[8]提出了一個三維網絡,可向網絡直接輸入連續的幀。端到端的訓練,使之快于雙流網絡,但是輸入幀的數量是有限的,依舊限制了行為的時長。文獻[9-10]中又提出通過擴展輸入大小來提升網絡。
上述網絡都采用了監督學習,要進行異常行為檢測,只需要將需要檢測的行為設置為異常類,就可以識別檢測,但訓練這樣的網絡通常需要大量的異常類數據,而真實情況下異常行為的數據非常稀少,且難以收集[11]。例如在銀行ATM 機附近的監控中,很難收集到搶劫、偷竊的視頻,一是因為這些行為發生的次數較少,二是因為監控數據量非常大,要從大量的數據中找出這些行為非常困難[12]。因為有大量的正常數據,Akcay 等人[2]提出了僅使用正常數據做訓練的異常檢測方法。
本文受文獻[2]的啟發,用同樣的方法來應對數據不平衡問題。但是這種方法更關注整個視頻幀的分布,其中存在許多冗余信息。受文獻[13-14]啟發,本文利用了人體姿態信息,使網絡更關注視頻中人的行為,提高異常行為檢測的準確率。為提取人體姿態信息,本文采用了基于深度學習的姿態估計網絡。
1.2 姿態估計
姿態估計算法又分單人姿估計和多人姿態估計[15],在異常行為檢測的場景中一般會有多人存在,所以使用多人姿態估計。多人姿態估計分為兩種,自頂向下的或者自底向上的[16]。自頂向下的方法是指先檢測出視頻幀中的人,然后檢測每個人的關節點,估計人體的姿態[17]。自底向上的方法則是,向檢測出視頻幀中人體的關節點,然后聚類[16]。
Insafutdinov 等人[16]提出的就是自底向上的方法,先找人體出關節點,然后對關節點進行聚類。文獻[18]中的方法也是自底向上的,并將姿態估計應用到了視頻追蹤中。Cao 等人[19]改進了自底向上的方法,使之速度更快。但自底向上的方法準確率并不高。文獻[17]使用了自頂向下的方法,通過YOLO、SSD 等網絡先檢測人體,然后對檢測到對人體進行姿態估計,雖然速度有所下降,但是準確率得到了提高。為了得到較高準確率的姿態信息,本文采用文獻[17]中的網絡提取視頻幀中行人的姿態信息。
2 實現
針對異常行為數據難以獲取的問題,本文采用了基于生成對抗網絡思想的半監督的異常檢測算法[2-3]。生成對抗網絡最初在文獻[20]中提出,其主要目的是生成足夠真實的圖片。一般生成對抗網絡包含兩個子網絡,一個生成器子網絡,一個判別器自網絡。生成器生成圖片,判別器判斷輸入圖片的真假,經過對抗訓練,使生成器最終可以生成足夠真實的圖片。Makhzani 等人[21]提出了對抗自編碼器與生成對抗網絡有同樣的訓練思想。它有一個編碼器和一個解碼器,編碼器從圖片中提取特征向量,解碼器通過特征向量重構圖片。鑒別器的作用與生成對抗網絡一致。
本文采用與文獻[2]一致的網絡結構,在對抗自編碼器的基礎上再添加一個編碼器,對比真實視頻幀和生成視頻幀特征向量的差異。網絡結構如圖1。

圖1 子網絡結構
故實驗可以只使用含有正常行為的數據對網絡進行訓練。向網絡輸入含有正常行為的視頻幀,對抗自編碼器提取特征向量并重構視頻幀,判別器判斷圖片的真假,使重構的視頻幀與輸入視頻幀一致,然后提取重構視頻幀的特征向量與輸入圖片的特征向量對比。
在訓練結束后,僅使用生成器加編碼器部分進行推測。如圖1 所示,假設輸入幀為x,編碼器提取特征向量z:

解碼器通過特征向量z 重構幀x':

編碼器提取重構幀x'的特征向量z':

然后對比z 和z'之間的差異。因為訓練的時候僅使用正常數據,網絡只學習到了正常數據的分布,所以可以很好地重構正常視頻幀,不能很好地重構異常幀。如果輸入幀是正常幀,z 和z'的差異就很小,如果是異常幀,則差異較大。
模型訓練好后,進行測試,網絡[2]在測試時其性能會隨著batch size 的減小而退化,因為文獻[2]提出的網絡使用了Batch Norm 層。Batch Norm 是Ioffe 等人[22]在2015 年提出的,其使用具有重大的意義。Batch Norm層對每層數據進行批量歸一化,加速了網絡的訓練,使以前許多難以訓練的網絡可以進行訓練。Batch Norm通過估計數據的方差和均值對數據進行歸一化,但是其方差和均值的估計依賴batch size,所以測試時如果減小batch size 就會使方差和均值的估計不準確導致性能的下降,所以我們修改文獻[2]中網絡的Batch Norm 層,將其替換為Group Norm 層。Group Norm[23]是在2018 年提出的,這種歸一化方式是基于分組思想的,將輸入數據的通道分組,通過組內數據進行方差和均值的估計,這樣數據的歸一化就不再依賴batch size,即使在測試時減小batch size 也不會導致模型性能的下降。Group Norm 分組的多少對于模型的性能也有一定的影響,越少越接近Batch Norm,所以我們使每層的分組數不定,但保證每組內有兩個通道。
現在大多數異常檢測網絡都只使用了視頻幀的像素信息,對于異常行為檢測任務,像素信息中存在許多復雜而冗余的信息,而異常檢測網絡會關注整個幀的信息,也會學習整個幀的分布,而不僅僅是行為的分布,所以我們希望網絡能更加關注視頻幀中的人體。但因為人的行為和環境有關系,我們又不能完全放棄環境信息,所以希望能夠利用環境信息的同時更加關注視頻幀中的人類行為。受文獻[13-14]的啟發,本文采用了姿態信息,姿態信息包含了人體的關節點和關節之間的關系,它是結構化的信息,可以過濾掉冗余信息,更容易表達語義。人體的姿態的變化更能表現人的行為,如果出現異常,其特征更為顯著,使得網絡更加關注人體的行為。也使網絡可以更好地學習行為的分布。文獻[4]提出的算法同時利用了像素信息和光流信息,受此啟發,本文也采用兩個子網絡來分別處理像素信息和姿態信息。
由于像素信息的分布和姿態信息的分布完全不同,所以本文沒有選擇在訓練過程中對兩個網絡提取的特征進行混合,而是在最后對網絡預測結果進行加權平均。因為在不同的環境下,異常行為不同,所以環境對結果的影響也不同,故針對不同的數據集應該有不同的權值。故提出如圖2 的雙路網絡。
對于像素信息處理子網絡,采用上述改進的網絡,使網絡能夠很好地學習整個幀的分布,并能生成足夠真實的幀。對于處理姿態的子網絡,本文提出在上述改進的網絡前面加上姿態提取處理過程,本文采用Alphapose[17]提取人體的姿態,Alphapose 是一個自頂向下的姿態估計網絡,在估計人體姿態后使用非極大抑制來提高估計的準確率,本文采用姿態信息包含了17 個關節點,分別是雙眼、雙耳、鼻子、肩、手肘、手腕、左右臀、膝蓋、腳踝。這些關節點和其關系能夠很好地表達一個人的姿態。在提取姿態信息后,對其進行二值化處理,進一步去掉冗余信息。然后GAN 的輸入為姿態圖,使得上述改進的GAN 可以很好地關注人的正常行為,并能夠重構正常行為的姿態。
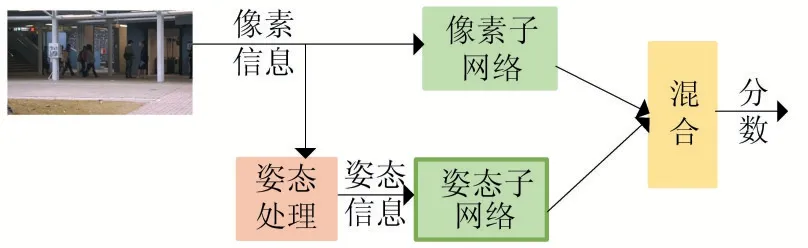
圖2 雙路網絡結構
最后對兩種信息進行混合,混合方式如下。最后得到一個重構差異分數來判斷幀中是否存在異常,分數計算如下:
S' 是最后的分數,S 是兩路網絡的混合結果。 w1是像素子網絡輸出結果的權重,w2是姿態子網絡輸出結果的權重。 scorer是像素子網絡輸出的分數,scorep是姿態子網絡輸出的分數,其計算公式如下:

3 實驗
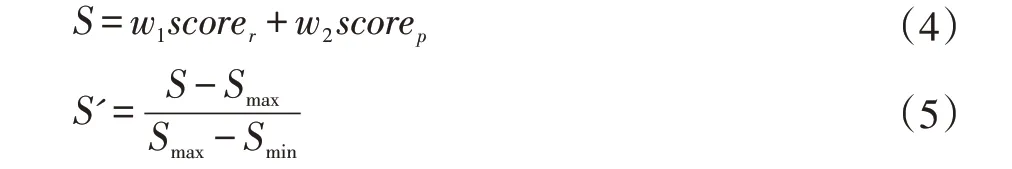
本文采用PyTorch 框架實現。學習率為0.0002,使用Adam 優化,設置其動量參數為0.5,輸入幀大小為256。所有的參數都參照了文獻[2]。本文使用公開數據集Avenue ped1 ped2 來驗證模型效果。
Avenue 數據集:這是香港中文大學大道的監控視頻,其中包含16 個訓練視頻,21 個測試視頻,一共30652 幀,其中15328 個訓練幀,15324 個測試幀,訓練幀中僅包含正常行走的視頻,而測試幀中包含正常行走的正常幀和跑步,扔垃圾等異常行為的異常幀。
UCSD 數據集:整個數據集是一條人行道的監控,又分為ped1 和ped2 兩個部分。Ped1 共有70 個視頻,其中包含了34 個訓練視頻,36 個測試視頻,其中訓練視頻只包含正常行走的幀,而測試視頻中包含行走和騎自行車等異常幀。Ped2 中共有28 個視頻,其中16個訓練視頻。12 個測試視頻。訓練視頻如以上兩個數據集一樣只包含行走視頻,而測試視頻同時包含正常和異常視頻幀。
常用于評價異常檢測模型優劣的是受試者工作特征曲線(ROC)。曲線的橫軸為假正例率,即測試為真,但實際為假的樣本占負樣本的比例;縱軸為真正例率,即,測試為正,且實際為正的樣本占所有正樣本的比例。每個點代表不同閾值下的真正率和假正率。圖3是模型在CUHK Avenue 數據集上測試的ROC 曲線。
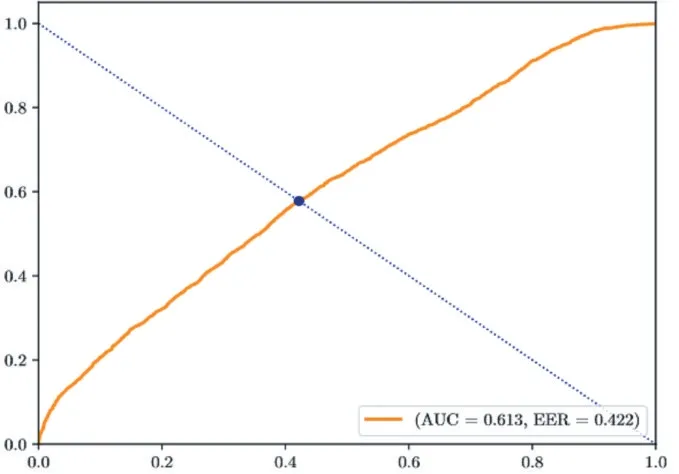
圖3 在CUHK Avenue 數據集上測試的ROC曲線
AUC 則是ROC 曲線下的面積,作為評價的標量,AUC 值大的模型優于AUC 值小的模型。為了驗證雙路網絡的有效性,本文對比了雙路網絡和其他算法在不同數據集上的AUC 值,為評估不同歸一化層帶來的影響,本文對比了使用不同歸一化層在不同數據集上的AUC 值,結果如表1 所示。
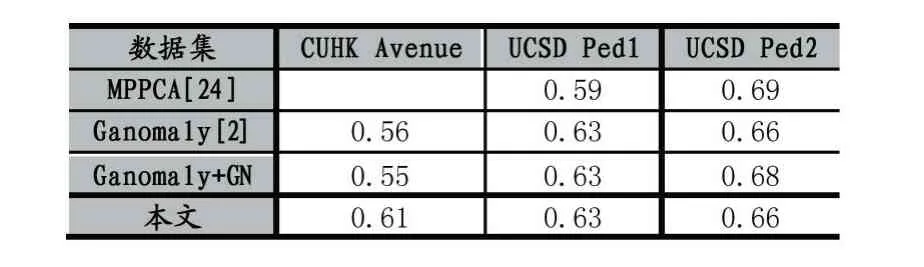
表1 算法在不同數據集上的AUC 值
從表1 可以看出其中Avenue 數據集的效果優于其他兩個數據集,通過分析可知,Avenue 數據集中的圖像更清晰,人物并不密集,距離攝像頭較近,能夠提取到的姿態信息更明確,而UCSD 數據集中行人比較密集,相對Avenue 中的人更小,提取到的姿態信息顯得比較模糊,所以導致Avenue 的效果優于其他數據集。由此可知姿態信息對模型的性能有明顯的影響。從表中結果可以看出,使用Group Norm 層并不會太大地影響網絡的性能,且使用Group Norm 層后,模型性能也不會隨著batch size 的下降而降低。測試視頻幀結果如圖4-圖5。

圖4 提取到的視頻序列中的姿態圖

圖5 子網絡重構視頻序列姿態圖
圖4 是從視頻幀中提取出來并進行二值化處理后的姿態信息,圖5 是網絡中間生成的姿態信息。從圖中可以看出,網絡可以很好地學習姿態圖的分布,并重構。
圖6 展示了包含正常行為的視頻幀,而圖7 是子網絡重構的視頻幀可以看出兩者之間的差別并不大。

圖6 包含正常行為的視頻幀序列

圖7 子網絡重構包含正常行為的視頻幀序

圖8 包含異常行為的視頻幀序列
圖8 為包含異常行為的視頻幀序列,其中異常行為由紅框標出。圖9 為子網絡中間重構的視頻幀,可以看出,網絡并不能很好地重構包含異常行為的幀。其差異較大。通過對比其特征向量的差異,則能檢測出是否存在異常行為。

圖9 子網絡重構包含異常行為的視頻幀序列
4 結語
本文采用了半監督的方法來進行異常行為檢測以應對數據不平衡問題,并因異常檢測方法并不只關注人類行文而提出了一個雙路網絡來加強異常檢測網絡對人體行為的關注,以增加異常行為的準確率。從本文的實驗可以看出,將姿態應用于其中是非常有效的,姿態越準確對網絡性能的提升幫助越大。在后續的工作中將會使用更加準確的姿態信息,并針對群體異常行為和單人異常行的姿態特征做研究。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
