基于數(shù)據(jù)挖掘的化工生產(chǎn)事故致因主題抽取
2019-11-06 10:00:24樊運(yùn)曉
中國(guó)安全生產(chǎn)科學(xué)技術(shù) 2019年10期
牛 毅,樊運(yùn)曉,高 遠(yuǎn)
(中國(guó)地質(zhì)大學(xué)(北京)工程技術(shù)學(xué)院,北京 100083)
0 引言
近年來(lái),盡管我國(guó)化工安全生產(chǎn)形勢(shì)整體趨好,但化工安全生產(chǎn)事故依然多發(fā)[1]。從歷史事故中學(xué)習(xí)經(jīng)驗(yàn)對(duì)進(jìn)一步遏制事故的發(fā)生具有重要意義,然而人們往往更關(guān)注重大事故,而忽視小事故。海因里希曾在統(tǒng)計(jì)大量事故后提出著名的事故金字塔理論:傷亡、輕傷和無(wú)傷害事故的比例為1∶29∶300[2],即1起嚴(yán)重事故背后必然有更多的小事故發(fā)生,要防止嚴(yán)重事故發(fā)生必須先減少或消除小事故,小事故同樣具有重要的研究?jī)r(jià)值[3]。在化工生產(chǎn)過(guò)程中,企業(yè)積累了大量的小型事故文本數(shù)據(jù),但受數(shù)據(jù)量大、記錄粗糙以及相應(yīng)信息處理能力不足等因素限制,數(shù)據(jù)價(jià)值未得到充分利用,進(jìn)而制約了對(duì)事故的深入研究。因此,如何從這些雜亂的事故信息中高效挖掘潛在價(jià)值,已成為亟待解決的問(wèn)題。
當(dāng)前針對(duì)化工事故數(shù)據(jù)應(yīng)用的研究,還主要停留在對(duì)事故類型、事發(fā)區(qū)域或時(shí)段的簡(jiǎn)單統(tǒng)計(jì)分析方面[4]。面對(duì)復(fù)雜的事故發(fā)生機(jī)理,單一的統(tǒng)計(jì)指標(biāo)不能充分描述事故的特征[5]。在此背景下,一些學(xué)者嘗試通過(guò)數(shù)據(jù)挖掘技術(shù)對(duì)事故數(shù)據(jù)進(jìn)行事故分類[6],事故聚類[5]和事故潛在關(guān)聯(lián)規(guī)則挖掘[7]等方面研究,然而這些研究大多集中于道路交通[8]和建筑施工[9]等領(lǐng)域,在化工安全生產(chǎn)事故中的應(yīng)用還相對(duì)較少。相較于數(shù)值型數(shù)據(jù),文本數(shù)據(jù)作為事故記錄的主要形式,蘊(yùn)含著事故更深入的細(xì)節(jié),但由于結(jié)構(gòu)復(fù)雜、記錄粗糙等原因,對(duì)大量化工事故文本數(shù)據(jù)系統(tǒng)的挖掘則更為缺乏。
基于上述問(wèn)題,本文引入可從大量事故文本數(shù)據(jù)中提取主題和關(guān)鍵信息的數(shù)據(jù)挖掘方法:潛在狄利克雷分配(Latent Dirichlet Allocation,LDA)主題模型和社會(huì)網(wǎng)絡(luò)分析法,以某化工企業(yè)1 578起小型事故為樣本,利用該方法進(jìn)一步挖掘事故致因及其分布規(guī)律,實(shí)現(xiàn)對(duì)化工事故的更深入分析,為企業(yè)事故預(yù)防工作提供有力支持。
1 數(shù)據(jù)挖掘
數(shù)據(jù)挖掘是指通過(guò)統(tǒng)計(jì)、機(jī)器學(xué)習(xí)等方法,從大量數(shù)據(jù)中挖掘?qū)ρ芯炕驔Q策具有深層價(jià)值信息的過(guò)程。
1.1 化工安全生產(chǎn)事故數(shù)據(jù)特征
目前,文本數(shù)據(jù)是各行業(yè)安全生產(chǎn)事故的最主要記錄形式之一,其中重特大事故會(huì)以事故調(diào)查報(bào)告的形式詳細(xì)剖析,然而數(shù)量上占絕大多數(shù)的輕傷或無(wú)人員傷亡的小事故往往只進(jìn)行簡(jiǎn)單的記錄,由于其記錄粗糙、數(shù)量龐大以及不被重視等原因,針對(duì)這些文本數(shù)據(jù)的挖掘還十分缺乏。以化工行業(yè)為例,化工安全生產(chǎn)事故文本數(shù)據(jù)通常是以描述性的文字對(duì)事故發(fā)生過(guò)程及原因的記錄,記錄雖然粗糙,但蘊(yùn)含著事故經(jīng)過(guò)和生產(chǎn)一線工作狀況等關(guān)鍵細(xì)節(jié),同樣具有巨大的利用價(jià)值和挖掘空間。
1.2 LDA主題模型
潛在狄利克雷分配(Latent Dirichlet Allocation,LDA)是由Blei提出的1種主題挖掘模型[10],該模型基于一定規(guī)則從海量文本中抽取主題,并根據(jù)主題分布對(duì)文本數(shù)據(jù)進(jìn)行聚類,其中主題是指文本數(shù)據(jù)所蘊(yùn)含的潛在主旨或核心思想。目前,該模型已廣泛應(yīng)用于圖書(shū)情報(bào)、熱點(diǎn)評(píng)論主題抽取[11]等領(lǐng)域。LDA也稱為三層貝葉斯概率模型,如圖1所示,其結(jié)構(gòu)由文本、主題和詞項(xiàng)3部分組成,其中每個(gè)文本由一系列服從概率分布的主題構(gòu)成,主題又由一系列服從概率分布的詞項(xiàng)構(gòu)成[10]。

圖1 三層貝葉斯概率結(jié)構(gòu)模型Fig.1 Three-layer Bayesian probabilistic structure model
1)主題生成過(guò)程:LDA主題模型如圖2所示,圖2中主要符號(hào)含義:α,β為狄利克雷先驗(yàn)參數(shù);m表示第m個(gè)文本;θm表示文本m的主題分布;n表示文本m的詞項(xiàng)數(shù);zm,n表示文本m的第n個(gè)詞項(xiàng)對(duì)應(yīng)的主題;wm,n表示文本m的第n詞項(xiàng);φzm,n表示主題的詞項(xiàng)分布;K表示主題總數(shù);M表示文本總數(shù);k表示第k個(gè)主題;Nm表示第m篇文檔的詞項(xiàng)總數(shù);Dir表示狄利克雷分布;Mult表示多項(xiàng)式分布。
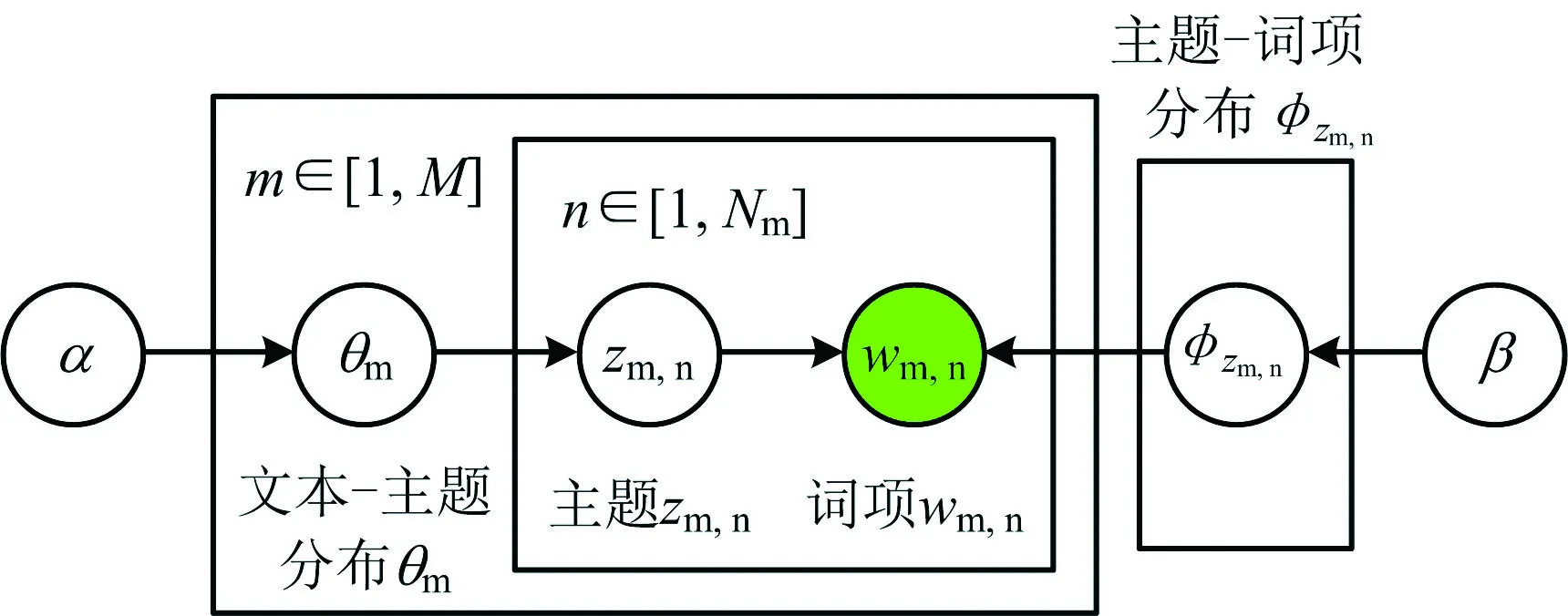
圖2 LDA主題模型Fig.2 LDA probability model
主題詳細(xì)生成過(guò)程為[12]:
①?gòu)牡依死追植鸡林腥由晌臋nm∈(1,M)的主題分布θm,θm|α~Dir(α);
②針對(duì)文檔m中的每個(gè)詞項(xiàng)wm,n,其中,n∈(1,Nm):a.從多項(xiàng)式分布θm中取樣生成該詞項(xiàng)wm,n的主題zm,n|θm~Mult(θm);b.從詞項(xiàng)分布φzm,n中取樣最終生成詞項(xiàng)wm,n|φzm,n~Mult(φzm,n),其中φzm,n|β~Dir(β)。在給定參數(shù)α,β情況下,模型的聯(lián)合概率分布為:
(1)
2)參數(shù)估計(jì):圖2中,陰影圓圈表示觀測(cè)變量,非陰影圓圈表示潛在變量,模型求解前需要對(duì)潛在變量進(jìn)行估計(jì)。本文中,模型的參數(shù)估計(jì)主要基于變分推斷EM算法。其原理為:通過(guò)近似隱藏變量的后驗(yàn)分布來(lái)簡(jiǎn)化問(wèn)題,通過(guò)尋求最大似然解來(lái)進(jìn)行參數(shù)估計(jì)[12]。
1.3 Tf-idf算法
事故記錄中每個(gè)關(guān)鍵詞是蘊(yùn)含事故信息的基本單元,考慮到一些詞頻少的關(guān)鍵詞可能攜帶更多的事故信息,因此利用Tf-idf(Term frequency-inverse document frequency)算法[13]對(duì)事故關(guān)鍵詞進(jìn)行加權(quán)處理。算法原理為:一個(gè)關(guān)鍵詞在整個(gè)數(shù)據(jù)集中出現(xiàn)頻率不高,但在某起事故中多次出現(xiàn),則認(rèn)為該關(guān)鍵詞既對(duì)該起事故有很好的代表性,又對(duì)其他事故有很好的區(qū)分能力,那么此關(guān)鍵詞在該事故中具有較高的權(quán)重。通過(guò)加權(quán)處理可有效避免這些關(guān)鍵事故信息的流失。
1.4 社會(huì)網(wǎng)絡(luò)分析法
社會(huì)網(wǎng)絡(luò)分析法旨在對(duì)系統(tǒng)要素間的關(guān)系進(jìn)行量化研究[14],一個(gè)網(wǎng)絡(luò)通常由“點(diǎn)”和“邊”構(gòu)成,“點(diǎn)”表示各個(gè)要素,“邊”表示要素間的關(guān)系,“邊”的粗細(xì)程度表示關(guān)聯(lián)程度。事故致因要素間并非簡(jiǎn)單的線性關(guān)系,而是構(gòu)成復(fù)雜的關(guān)系網(wǎng)絡(luò),為進(jìn)一步發(fā)掘事故要素間的關(guān)系,基于社會(huì)網(wǎng)絡(luò)分析法,將關(guān)鍵詞看作“點(diǎn)”,關(guān)鍵詞之間的關(guān)聯(lián)看作“邊”,構(gòu)建事故關(guān)鍵詞網(wǎng)絡(luò)。算法原理為:在整個(gè)事故文本數(shù)據(jù)集中,若2個(gè)關(guān)鍵詞同時(shí)出現(xiàn)在一個(gè)句子的頻率超過(guò)一定值時(shí),則認(rèn)為這2個(gè)關(guān)鍵詞有關(guān)聯(lián),該頻率大小反映了關(guān)聯(lián)度的強(qiáng)弱。
2 化工事故致因挖掘流程
化工事故致因挖掘主要包括數(shù)據(jù)收集與處理、事故致因挖掘、結(jié)果可視化分析等3個(gè)主要環(huán)節(jié),具體流程如圖3所示。
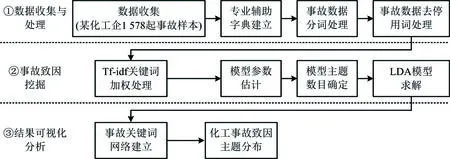
圖3 化工事故主題抽取流程Fig.3 Chemical accident theme extraction process
2.1 數(shù)據(jù)收集與處理
本研究的數(shù)據(jù)來(lái)源為國(guó)內(nèi)某大型化工集團(tuán)2010—2016年期間的1 578起事故記錄,該企業(yè)為中國(guó)最具代表性的化工企業(yè)之一。企業(yè)擁有較完善的事故信息采集系統(tǒng),1 578起事故中大多為輕傷和設(shè)備損壞事故(少量死亡、重傷事故),記錄內(nèi)容為事故發(fā)生后第一時(shí)間對(duì)事故經(jīng)過(guò)、生產(chǎn)環(huán)境和事故原因的文字性描述,蘊(yùn)含著事故發(fā)生時(shí)的關(guān)鍵細(xì)節(jié),且所有數(shù)據(jù)的記錄形式統(tǒng)一,利于對(duì)該數(shù)據(jù)集進(jìn)行系統(tǒng)地潛在規(guī)律挖掘。原始事故數(shù)據(jù)示例見(jiàn)表1。

表1 原始事故數(shù)據(jù)(示例)Table 1 Accident data after modification(example)
為達(dá)到模型計(jì)算的要求,同時(shí)提高模型效率及準(zhǔn)確性,事故致因挖掘前,需將原始事故數(shù)據(jù)進(jìn)行分詞、去停用詞等一系列處理:
1)分詞處理:Jieba分詞包是1個(gè)基于python實(shí)現(xiàn)的分詞工具,借助該工具對(duì)事故文本數(shù)據(jù)進(jìn)行分詞處理。由于要分析數(shù)據(jù)的背景為化工事故,為了避免分詞過(guò)程中無(wú)法識(shí)別某些化工或安全專業(yè)名詞的情況,結(jié)合化工企業(yè)相關(guān)規(guī)范,制定了適用于化工安全事故分析的輔助字典,見(jiàn)表2。

表2 化工安全專業(yè)領(lǐng)域字典(部分)Table 2 Chemical safety professional domain dictionary (partial)
2)去停用詞:事故記錄中存在許多對(duì)事故分析無(wú)意義的詞項(xiàng),為提高模型效率,將這些詞項(xiàng)加入停用詞表,并將其過(guò)濾,即去停用詞處理。
2.2 事故致因挖掘
通過(guò)對(duì)原始數(shù)據(jù)處理,得到適合模型計(jì)算的1 578起事故數(shù)據(jù)。基于Python編程語(yǔ)言,利用前文所介紹的LDA主題模型、Tf-idf算法以及社會(huì)網(wǎng)絡(luò)分析法,對(duì)1 578起事故數(shù)據(jù)進(jìn)行事故致因主題抽取、關(guān)鍵詞加權(quán)以及建立關(guān)鍵詞關(guān)系網(wǎng)絡(luò)等工作。其具體流程如圖3中②部分所示。
2.3 結(jié)果可視化分析
為幫助企業(yè)管理者更直觀地了解企業(yè)安全狀況及事故致因分布規(guī)律,將事故關(guān)鍵詞關(guān)聯(lián)規(guī)則、事故致因主題分布等抽象結(jié)果以文字—圖像交互的形式展現(xiàn)出來(lái),利用Gephi等可視化工具,繪制事故關(guān)鍵詞關(guān)系網(wǎng)絡(luò)、事故致因主題分布圖等可視化結(jié)果。
3 結(jié)果及分析
3.1 事故關(guān)鍵詞權(quán)重矩陣
事故記錄中每個(gè)關(guān)鍵詞所蘊(yùn)含信息的重要程度不同,因此利用Tf-idf算法,建立文檔—關(guān)鍵詞權(quán)重矩陣,見(jiàn)表3。矩陣中的權(quán)重代表了關(guān)鍵詞在事故中的重要程度,權(quán)重越高重要度越高。例如,事故‘3’中,關(guān)鍵詞“不慎”的權(quán)重較高,說(shuō)明注意力問(wèn)題可能是導(dǎo)致該事故發(fā)生的主要原因。
3.2 事故關(guān)鍵詞關(guān)系網(wǎng)絡(luò)
基于社會(huì)網(wǎng)絡(luò)分析法,利用Gephi軟件繪制關(guān)鍵詞關(guān)系網(wǎng)絡(luò)圖,如圖4所示。整個(gè)事故集中,重要度越高的關(guān)鍵詞,越靠近關(guān)系網(wǎng)絡(luò)的中心位置,且關(guān)鍵詞標(biāo)簽越大。相關(guān)的關(guān)鍵詞由直線相連,直線的粗細(xì)則代表了關(guān)聯(lián)程度的大小。由圖4可知,“操作”、“檢查”、“設(shè)備”等關(guān)鍵詞位于整個(gè)關(guān)系網(wǎng)絡(luò)的樞紐,尤其是“操作”,位于關(guān)系網(wǎng)絡(luò)的最中心,說(shuō)明不安全操作仍是事故預(yù)防工作中需重點(diǎn)防范的對(duì)象。
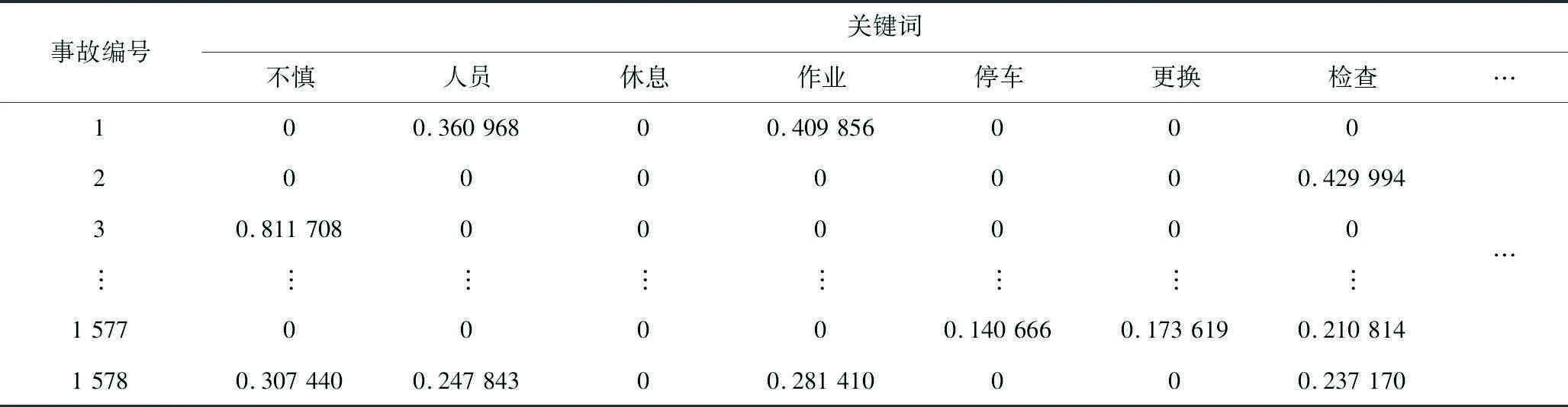
表3 關(guān)鍵詞權(quán)重矩陣(部分)Table 3 Keyword weight matrix (partial)
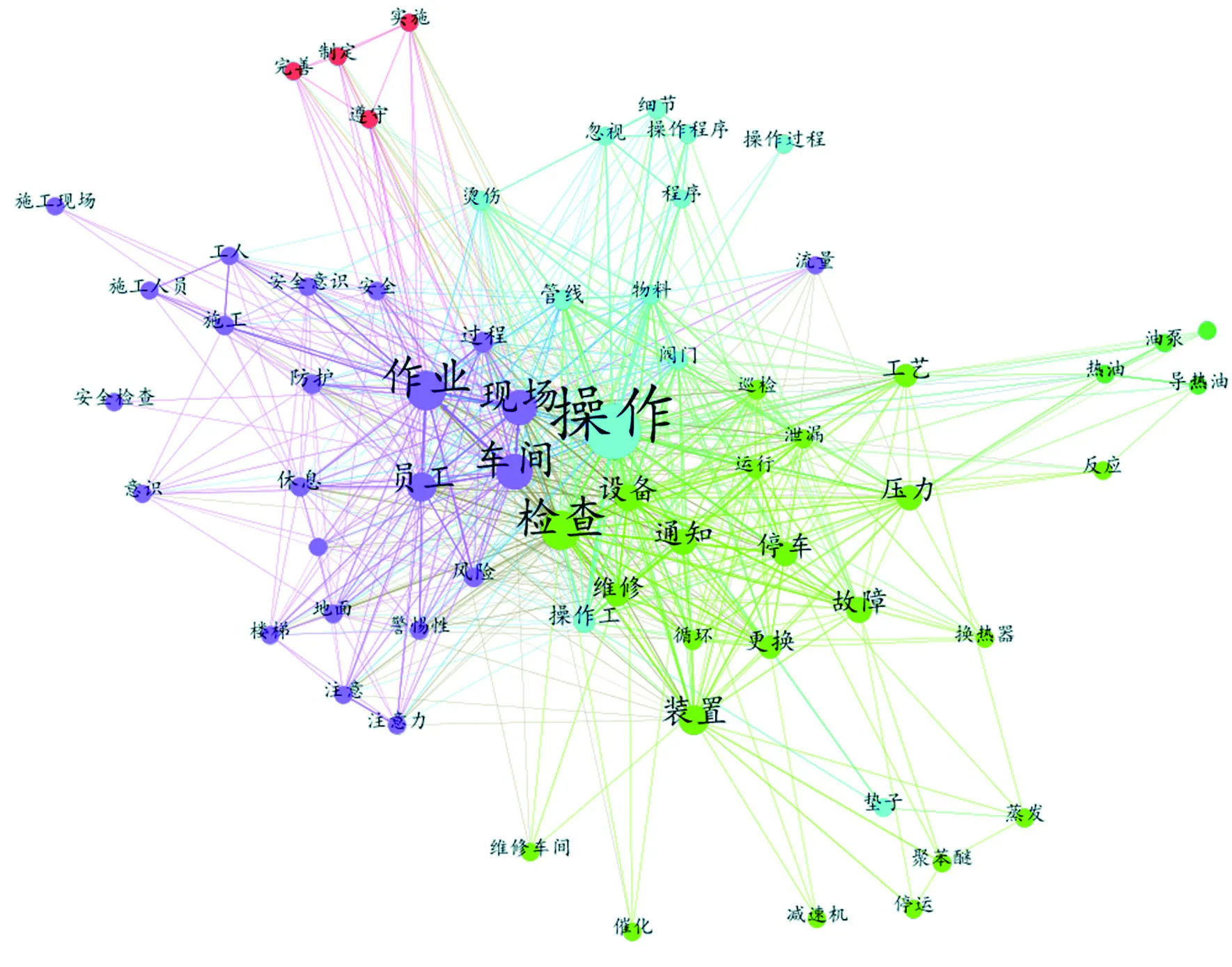
圖4 關(guān)鍵詞關(guān)系網(wǎng)絡(luò)Fig.4 Keywords Telational network
3.3 事故致因主題結(jié)果分析
1)主題數(shù)確定
本文采用困惑度指標(biāo)[15]來(lái)確定主題數(shù)目,困惑度指標(biāo)越小說(shuō)明建模能力越好,則主題數(shù)目為最優(yōu),計(jì)算公式為:
(2)
式中:perplexity表示困惑度;m表示第m篇文檔;P(wm)表示第m篇文檔每個(gè)單詞的概率;Nm表示第m篇文檔的詞項(xiàng)總數(shù)。困惑度隨主題數(shù)目變化時(shí)的曲線如圖5所示,從圖5中可以看出,當(dāng)主題數(shù)為5時(shí),困惑度指標(biāo)曲線處于低谷,此時(shí)模型效果最優(yōu),因此將主題數(shù)確定為5個(gè)。
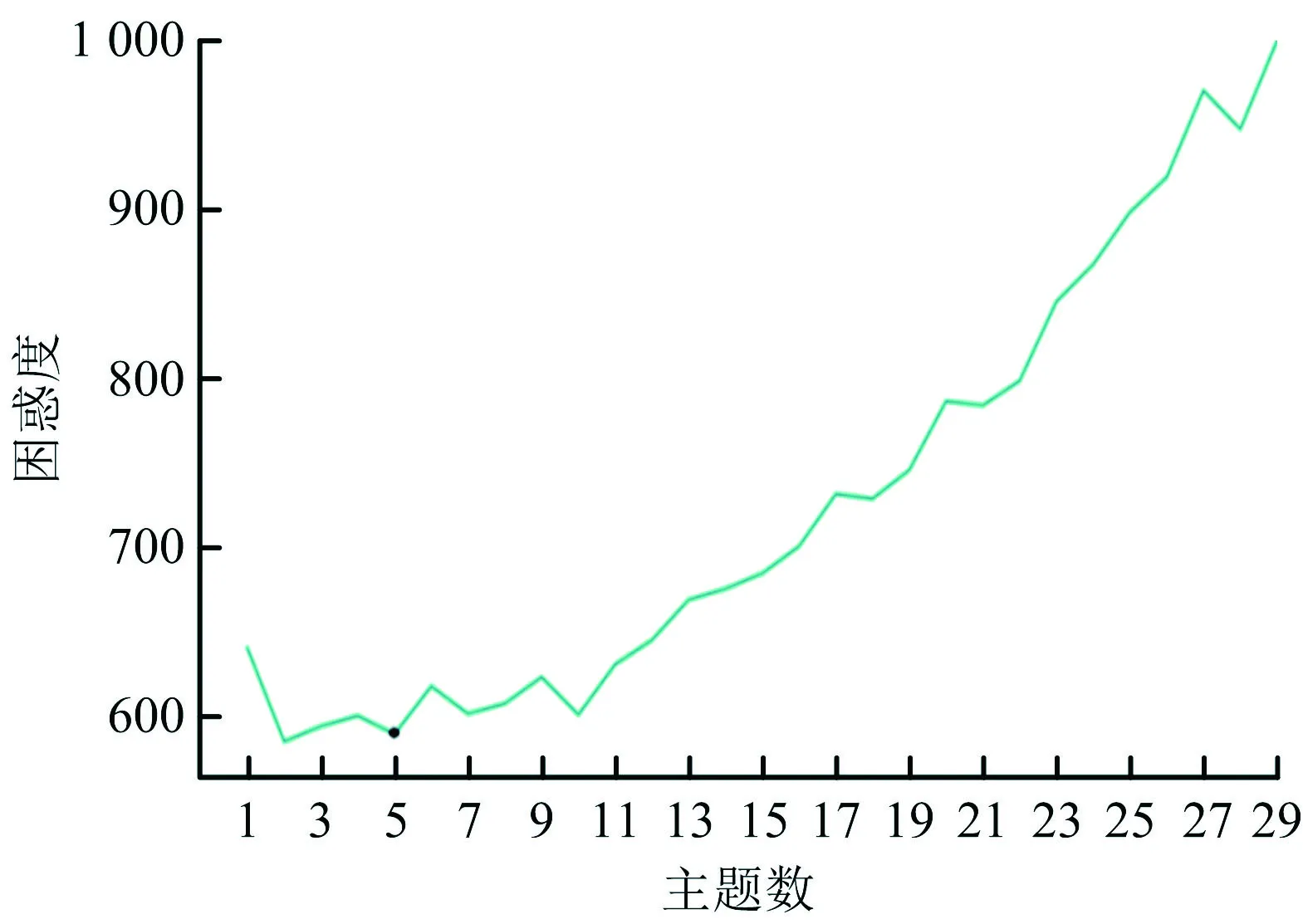
圖5 困惑度指標(biāo)Fig.5 Perplexityindicator
2)事故致因主題抽取結(jié)果
事故致因主題抽取結(jié)果見(jiàn)表4,通過(guò)主題模型求解,得到事故致因主題和關(guān)鍵詞,并分析每個(gè)主題關(guān)鍵詞之間的關(guān)系得到事故致因總結(jié)。其中,事故致因主題揭示了造成事故發(fā)生的主要原因類別,主題關(guān)鍵詞反映了導(dǎo)致事故發(fā)生的關(guān)鍵細(xì)節(jié),事故致因總結(jié)則是根據(jù)關(guān)鍵詞對(duì)主題進(jìn)一步細(xì)分為若干致因。
運(yùn)用可視化工具pyLDAvis,繪制事故致因主題分布圖,如圖6所示。圖6中左側(cè),圓圈代表不同的主題,主題標(biāo)號(hào)與表4中相對(duì)應(yīng),圓圈大小代表了每個(gè)主題包含的事故數(shù)量,圓圈之間的距離代表了主題之間的關(guān)聯(lián)程度。圖右側(cè)為頻率最高的30個(gè)關(guān)鍵詞列表。由圖6可知,主題①數(shù)量最多,主題①,②距離接近且有重合部分,說(shuō)明相關(guān)性較強(qiáng),主題④,⑤則數(shù)量最少。
對(duì)各事故致因主題具體分析如下:

表4 主題抽取結(jié)果Table 4 Topic extraction results
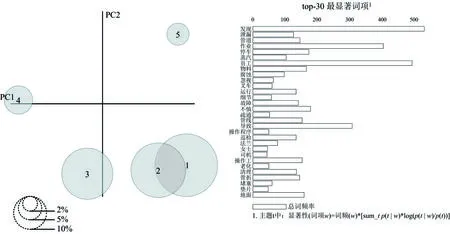
圖6 主題分布可視化Fig.6 Theme distribution visualization
1)員工注意力主題。由表4可知,在員工注意力主題方面,導(dǎo)致事故發(fā)生的主要表現(xiàn)為:在車間、樓梯等危險(xiǎn)性較高區(qū)域,由于員工警惕性不強(qiáng)或注意力不集中而導(dǎo)致了事故發(fā)生。關(guān)鍵詞“休息”反映出,休息不足或疲勞是造成注意力不集中的重要原因,“車間”“樓梯”則是員工在注意力不集中時(shí)事故高發(fā)的區(qū)域。在圖4關(guān)鍵詞網(wǎng)絡(luò)中,該主題關(guān)鍵詞處于中心位置,說(shuō)明在關(guān)系網(wǎng)絡(luò)中具有較高重要度。由圖6可以看出,主題①數(shù)量最多,且與主題②有較高相關(guān)性。因此,從數(shù)量角度看,員工注意力不集中是造成事故發(fā)生的重要原因;從相關(guān)性角度看,員工注意力問(wèn)題與作業(yè)現(xiàn)場(chǎng)風(fēng)險(xiǎn)管理問(wèn)題之間存在較強(qiáng)關(guān)聯(lián)。
2)作業(yè)現(xiàn)場(chǎng)風(fēng)險(xiǎn)管理主題。作業(yè)現(xiàn)場(chǎng)安全檢查不到位、安全防護(hù)缺失、維修不及時(shí)以及未識(shí)別風(fēng)險(xiǎn)是作業(yè)現(xiàn)場(chǎng)風(fēng)險(xiǎn)管理主題的主要表現(xiàn)。由圖4和圖6可知,該主題在分布和數(shù)量上都與主題①較為相似,說(shuō)明作業(yè)現(xiàn)場(chǎng)風(fēng)險(xiǎn)管理不足也是造成事故發(fā)生的重要原因之一,且與主題①具有一定關(guān)聯(lián)性。因此,可以啟發(fā)管理者在事故預(yù)防工作中,關(guān)注并切斷2致因主題之間的某些關(guān)聯(lián)要素,以提高預(yù)防工作的效果。例如,通過(guò)完善作業(yè)現(xiàn)場(chǎng)的風(fēng)險(xiǎn)管理,降低“車間”、“工作現(xiàn)場(chǎng)”的不安全狀態(tài),進(jìn)而提高生產(chǎn)系統(tǒng)的容錯(cuò)率。
3)設(shè)備主題。設(shè)備主題由設(shè)備檢查與維修、設(shè)備故障和變更管理等問(wèn)題組成。通過(guò)對(duì)主題關(guān)鍵詞分析,“檢查”“維修”“巡檢”等關(guān)鍵詞突出的是設(shè)備維護(hù)不足問(wèn)題,這就導(dǎo)致設(shè)備的不安全狀態(tài)得不到及時(shí)發(fā)現(xiàn)和消除,從而產(chǎn)生安全隱患;“更換”等關(guān)鍵詞則說(shuō)明企業(yè)在變更管理工作中存在缺陷,未能消除由于設(shè)備變更而引起的事故隱患。由圖6可知,該主題數(shù)量較多,也是導(dǎo)致事故發(fā)生的主要原因之一。
4)制度主題。從制度主題的關(guān)鍵詞可以看出,主題主要由制度不完善、制度制定與實(shí)施、施工人員對(duì)制度不遵守等問(wèn)題組成。從主題分布圖中可知,相較于前3個(gè)主題,該主題數(shù)量明顯較少,且與其他主題的相關(guān)性較弱。但制度本身是較為抽象的概念,往往在事故記錄中難以直接體現(xiàn),盡管如此,制度主題依然是5個(gè)事故致因主題之一,足以說(shuō)明安全制度或管理體系問(wèn)題的嚴(yán)峻性和重要性。
5)化學(xué)物質(zhì)及工藝主題。上述4個(gè)致因主題都涉及到人因或組織缺陷,主題⑤則更加側(cè)重于化學(xué)物質(zhì)或工藝過(guò)程中本身的性質(zhì)和反應(yīng)。從主題關(guān)鍵詞推斷,“導(dǎo)熱油”、“聚苯醚”等化學(xué)物質(zhì)和“換熱”、“蒸發(fā)”、“催化反應(yīng)”等工藝過(guò)程中釋放的能量是造成人員傷害及裝置破壞的主要致因。因此,企業(yè)應(yīng)在適當(dāng)區(qū)域設(shè)立防護(hù)設(shè)施以減輕該類事故對(duì)工人及設(shè)備造成的危害。
通過(guò)聚類結(jié)果可以看出,5個(gè)主題中,4個(gè)涉及到人因或組織層面的缺陷,并占據(jù)事故致因絕大多數(shù)比重,說(shuō)明事故預(yù)防的重點(diǎn)應(yīng)放在改善人員安全素養(yǎng)和安全管理體系建設(shè)等方面。
4 結(jié)論
1)通過(guò)LDA主題模型、社會(huì)網(wǎng)絡(luò)分析法等數(shù)據(jù)挖掘技術(shù),以某化工企業(yè)2010—2016年文本類型事故數(shù)據(jù)為樣本,通過(guò)挖掘關(guān)鍵詞權(quán)重、事故構(gòu)成要素關(guān)聯(lián)關(guān)系、事故致因主題等潛在信息,實(shí)現(xiàn)了對(duì)該類事故數(shù)據(jù)的進(jìn)一步識(shí)別與認(rèn)識(shí)。
2)通過(guò)LDA主題模型抽取到的5個(gè)主題分別為員工注意力主題、作業(yè)現(xiàn)場(chǎng)風(fēng)險(xiǎn)管理主題、設(shè)備主題、制度主題、化學(xué)物質(zhì)及工藝主題。分析聚類結(jié)果可知,員工注意力不集中、現(xiàn)場(chǎng)風(fēng)險(xiǎn)管理不足、設(shè)備檢修不及時(shí)是導(dǎo)致事故發(fā)生的最主要原因,且員工注意力和現(xiàn)場(chǎng)風(fēng)險(xiǎn)管理之間存在較強(qiáng)關(guān)聯(lián)性;人因和組織結(jié)構(gòu)缺陷是導(dǎo)致大量事故發(fā)生的根本原因。
3)本文數(shù)據(jù)來(lái)源為單一化工企業(yè),研究結(jié)果對(duì)化工行業(yè)具有一定參考價(jià)值,同時(shí)為其他行業(yè)事故文本數(shù)據(jù)挖掘提供了思路,但更系統(tǒng)的事故致因挖掘分析需要更全面的數(shù)據(jù)支撐。
 中國(guó)安全生產(chǎn)科學(xué)技術(shù)2019年10期
中國(guó)安全生產(chǎn)科學(xué)技術(shù)2019年10期
- 中國(guó)安全生產(chǎn)科學(xué)技術(shù)的其它文章
- 煤礦企業(yè)重大災(zāi)害預(yù)防與安全保障體系構(gòu)建與運(yùn)行評(píng)價(jià)
- 點(diǎn)火位置對(duì)污水管網(wǎng)可燃?xì)怏w爆燃特性影響模擬研究*
- 爆破荷載作用下隧道中隔巖穩(wěn)定性研究
- 面向縣(市)的地震應(yīng)急處置輔助決策系統(tǒng)研究*
- 中國(guó)安全生產(chǎn)標(biāo)準(zhǔn)現(xiàn)狀統(tǒng)計(jì)分析*
- 大數(shù)據(jù)安全技術(shù)在涉眾型經(jīng)濟(jì)犯罪案件偵查中的應(yīng)用*
——評(píng)《數(shù)字經(jīng)濟(jì)時(shí)代的智慧城市與信息安全》