《蘭亭集序》英譯本的語料庫文體學分析
2019-11-07 09:50:16張磊
現代語文 2019年7期
張磊


摘? 要:運用語料庫文體學理論,以《蘭亭集序》的羅經國譯本和林語堂譯本為語料并建立語料庫,借用語料庫分析工具,從詞匯、句子、篇章等層面對二者的翻譯進行對比分析。羅譯本忠實于原文,注重逐字逐句進行翻譯,力求準確傳達原文的含義,書面化色彩較濃。但句子結構和選用單詞較長,用詞重復,有時會造成譯文冗余,增加閱讀的負擔。林語堂在傳達原文含義的基礎上,選用豐富、精煉的詞匯和句子結構,譯文簡潔凝練,口語化較為突出,便于英語讀者理解。
關鍵詞:《蘭亭集序》;英譯本;語料庫文體學
《蘭亭集序》是“書圣”王羲之所作,它不僅是書法中的精品,也是古代散文中的經典。《蘭亭序》文辭簡練,記述了蘭亭周圍的山水之美和作者與朋友聚會的歡樂之情,抒發了作者對生死無常的感慨。因其文學價值很高,出現了很多英譯本。研究比較多的有林語堂英譯本、謝百魁英譯本、孫大雨英譯本和羅經國英譯本。這些譯本的出現,對中華優秀傳統文化的傳播,發揮著重要作用。
2004年,Elena Semino & Mick Short在Corpus Stylistics:Speech,Writing and Thought Presentation in a Corpus of English Writing(《語料庫文體學:英語書面文本中的言語、書寫與思想表達》)一書中,首次提出語料庫文體學這一概念。它是指用定量描寫和定性描寫相結合的方法,以語料庫為工具,對各種文體的文本特征進行分析和研究的學科[1]。本文運用語料庫文體學理論,以《蘭亭集序》的羅經國譯本和林語堂譯本為語料并建立語料庫,借用語料庫分析工具,從詞匯、句子和篇章三個層面對二者的翻譯風格進行對比分析。
一、文獻綜述
《蘭亭集序》作為經典名篇,受到很多文學研究者的關注。通過在中國知網(CNKI)上檢索發現,有關《蘭亭集序》的研究論文有260篇,這些論文,大致可分為三類:
第一類是從文本本身出發,分析其蘊含的文學價值,或是與其他文學作品進行對比分析。如:彭建、宋會鴿認為,王羲之與友人的蘭亭之行,是一次悟道之旅,作者對人生的審美觀超越了對生死觀的恐懼。作者既感知天道,也悟出人道,唱出了一曲絕美的生命戀歌[2]。尹雅萍將石崇的《金谷詩序》與王羲之的《蘭亭集序》這兩篇序文進行對比,從總體上看,二者都是敘中夾議。石崇的《金谷詩序》語言簡潔,敘事清晰,是簡潔樸素的記敘文;而王羲之的《蘭亭集序》以議論為主,以作者的思考為主要內容,情感豐富,意味深長,是情理兼長的議論文。王序強烈的情感抒發與深刻的哲理思考相融合,給人觸動與深思,較于石序更為后世所認可[3]。
第二類是從英漢對比角度,對《蘭亭集序》的翻譯進行闡述。如:任慶亮、鄧晶晶以具體事例為基礎,分析了《蘭亭集序》翻譯中對文化的處理。他們指出,首先,要尊重英漢差異,注意到形合與意合語言的特點;其次,譯者要了解原文作者的民族文化。只有做到這兩點,才能較準確忠實地傳達出原文的意思[4]。雷蔚茵、楊曉春通過對《蘭亭集序》原文與英譯本的對比分析,發現了中西思維的差異。他們指出,在《蘭亭集序》原文中,體現的是具體思維和螺旋式思維方式,而在其英譯本中,體現的是抽象思維和直線式思維方式[5]。
第三類是從教學角度出發,以《蘭亭集序》的課堂設計為把手,探討文言文的教學策略。如:劉李娥以《蘭亭集序》為例,探討了以培養職業能力為基礎的高職大學語文教學設計。她認為,在教學過程中,要注重將職業能力與專業學習緊密結合,使學生注意到語文教學對專業學習的重要性。此外,教師要合理運用多種信息化手段,采用多種方式組織教學,激發學生的學習興趣,促進學生體驗和思考,形成新的知識點[6]。
綜上所述,雖然語料庫文體學已經在很多領域、具體文本中得到運用,但目前還沒有學者采用語料庫文體學理論對《蘭亭集序》的英譯進行分析。有鑒于此,筆者擬進行這方面的嘗試,為《蘭亭集序》及《蘭亭集序》翻譯的研究提供一種新的思路。
二、研究方法
東晉穆帝永和九年(353年)三月三日,王羲之與謝安、孫綽等四十一位名士,在山陰(今浙江紹興)蘭亭“修禊”,與會的人士都有詩作,王羲之為這些詩作寫了一篇序文,即為《蘭亭集序》。羅經國將題目譯為“Prologue to the Collection of Poems Composed at the Orchid Pavilion”,較為忠實地傳達出原文的信息,但作為題目來說,過于冗長;林語堂則將題目譯為“At the Orchid Pavilion”,只是簡單地交待了事件的發生地點,雖然體現出作為題目的簡潔明了,卻遮蔽了相關信息的傳達。此外,羅經國還采用注釋的方式,向英語讀者詳細地解釋了中國的傳統文化習俗。
本文所選用的《蘭亭集序》英譯本,一個是羅經國翻譯的(以下簡稱“羅譯本”)[7](P15),另一個是林語堂翻譯的(以下簡稱“林譯本”)[8](P56)。根據需要,運用北京外國語大學開發的軟件TreeTagger3對兩個譯本進行詞性賦碼。同時,運用語料庫檢索分析軟件UAM Corpus Tool和AntConc3.5.0,并結合相關的統計學研究方法,對兩個譯本的翻譯語言特征和與這些特征相關的變量進行比較,進而探究兩位譯者的風格是否具有顯著性差異,最后對二者翻譯風格的總體特征進行概括總結。
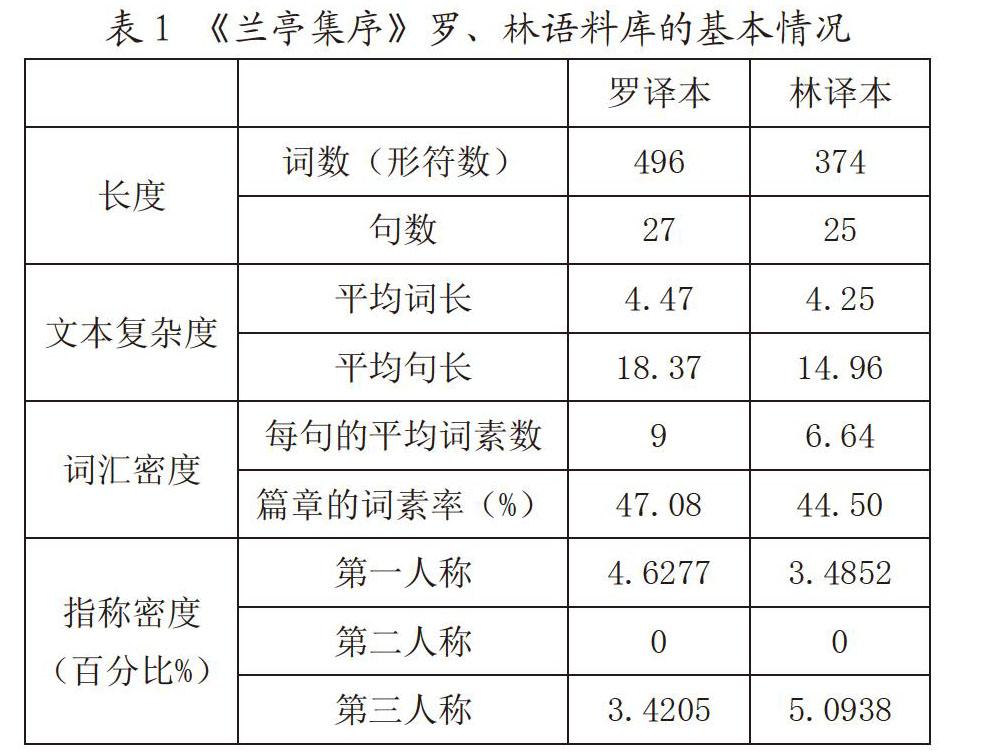
筆者還運用軟件UAM Corpus Tool對羅譯本和林譯本的基本情況進行了統計分析。具體如表1所示:
由表1可知,羅譯本比林譯本的詞匯密度高,表明羅譯本比林譯本用詞豐富;同時,羅譯本的句數雖與林譯本句數相差無幾,這表明羅譯本不易閱讀、較難理解。羅譯本與林譯本都不運用第二人稱,羅譯本較多運用第一人稱,以一種直接的方式向讀者敘述所見所聞,具有真實感和親切感;而林譯本較多運用第三人稱,以一種客觀的方式向讀者敘述事實,更具說服力。相比之下,林譯本的語言風格更加直白、客觀。下面筆者將運用軟件AntConc3.5.0,從詞匯、句法和篇章三方面,對羅譯本和林譯本進行對比分析。
三、兩個譯本的詞匯對比
(一)類符形符比
類符形符比(type/token ratio)能反映所研究語料庫的用詞情況。類符形符比越高,表明該文本的用詞越豐富。但形符數的增長與類符數的增長不一定成正相關,所以,有時類符形符比不能充分反映用詞的豐富程度。Baker認為,標準化類符形符比(standardized type/token ratio)的高低與作者用詞豐富度的高低成正比[9]。此時就要用標準化類符形符比來反映語料庫的用詞情況。我們對《蘭亭集序》兩個譯本語料庫的類符形符比進行了統計,具體如表2所示:
由表2可知,羅譯本在形符數和類符數上大于林譯本,這樣表明羅譯本在翻譯篇幅上要多于林譯本。不過,羅譯本的類符形符比,特別是標準化類符形符比卻低于林譯本,這表明林譯本的詞匯的豐富度較高。例如:
(1)原文:是日也,天朗氣清,惠風和暢。仰觀宇宙之大,俯察品類之盛。所以游目騁懷,足以極視聽之娛,信可樂也。
羅譯本:It is a fine day. The sky is clear and the breeze is gentle. Looking upward, we see the great expanse of the universe. Looking downward, we see the great variety of living things. Then we look around as far as the eyes can see and feel elated, enjoying ourselves to the utmost both visually and aurally. What a delightful experience it is!
林譯本:It is a clear spring day with mild, caressing breeze. The vast universe, throbbing with life, lies spread before us, entertaining the eye and pleasing the spirit and all the senses. It is perfect.
從例(1)可直觀地發現羅譯本的篇幅比林譯本長。“仰觀宇宙之大,俯察品類之盛”,羅經國采取直譯的方式,將其譯為:“Looking upward,we see the great expanse of the universe.Looking downward,we see the great variety of living things.”再現了原文的觀察視角與排列順序,但句子較長,所用詞匯也多有重復。而林語堂的處理方式較為簡潔明了,采用意譯、省譯的方式將其譯為:“The vast universe,throbbing with life”,這符合英語的言說方式和思維方式。可以說,正是這種差異導致了兩者形成不同的翻譯風格,同時在一定程度上說,也正是兩者翻譯風格的不同造成了兩個譯本詞匯使用的差異。它們之間是互為因果、相輔相成的關系。
(二)詞匯密度
詞匯密度(lexical density)是指文本的實詞數占總詞數的比例。Baker曾指出,因為虛詞在句中主要起銜接和語法的作用,所以一般情況下,句中的實詞要會比虛詞傳達更多的信息[10]。潘登、熊兵認為,從統計學來說,詞匯密度與文本的信息量呈正相關[11]。因此,詞匯密度越高,說明實詞數越多,句子所承載的信息量就越大。在英語中,實詞又稱開放性詞類,主要分為名詞、動詞、形容詞和副詞[12](P55)。筆者運用Urea和Stubbs提出的方法[13],對羅、林兩譯本的詞匯密度進行統計,公式為:
由于此前兩譯本都已經運用TreeTagger3進行了詞性賦碼,所以很容易統計出各類實詞的數量。具體如表3所示:
由表3可知,在名詞和動詞使用方面,羅譯本遠遠高于林譯本;在形容詞和副詞使用方面,羅譯本雖然也高于林譯本,但兩者相差不大。從總體上看,羅譯本的詞匯密度為57.06%,也高于林譯本的詞匯密度(55.88%)。這表明羅經國譯本承載的信息量較多,雖然傳遞給讀者的內容較為豐富、完整,但是卻增加了譯文的難度,不便于讀者理解。例如:
(2)原文:此地有崇山峻嶺,茂林修竹,又有清流激湍,映帶左右,引以為流觴曲水,列坐其次。
羅譯本:Here are high mountains and lofty ridges which are overgrown with tall bamboo groves and dense forests. A clear stream with a rapidly running current that winds like a belt, shining in the bright sun, is ideal for floating wine vessels. We sit by the water in proper order, sipping wine and composing poems.
林譯本:In the background lie high peaks and deep forests. While a clear, gurgling brook catches the light to the tight and to the left. We then arrange ourselves, sitting on its bank, drinking in succession from the goblet as it floats down the stream.
在例(2)中,羅經國用“high mountains and lofty ridges”來翻譯“崇山峻嶺”,并用定語從句與后句“茂林修竹”連接在一起,雖然較為忠實地傳達了原文的含義,但信息量過大,不便于英語讀者的接受。而林語堂則用簡潔的短語“high peaks”和“deep forests”來表達“崇山峻嶺”和“茂林修竹”,向讀者描述出一幅形象的畫面,不僅言簡意賅、深入淺出,而且符合英語讀者的思維表達,便于他們理解。
(三)單詞長度
平均詞長(Mean word Length)是指文本中單詞(或形符)的平均長度。詞長在一定程度上能反映出文本用詞的難易情況。由表1可知,羅譯本中的平均詞長為4.47,林譯本的為4.25,表明羅譯本的用詞比林譯本的要長,難度也更大一些。筆者在運用軟件AntConc3.5.0基礎上,又運用正則表達式對羅、林譯本中不同詞長的單詞進行了統計,如表4所示:
由表4可知,羅、林譯本中的單詞多是由2個、3個和4個字母組成的,不過,羅譯本要略多于林譯本。同時,單詞在6個字母以上的,羅譯本也多于林譯本。為了更直觀地了解羅、林譯本中所用單詞長度,筆者分別對兩個譯本中5個字母及以內的單詞所占比例和6個字母及以上的單詞所占比例進行了統計,具體如圖1所示:
由圖1可知,林譯本中5個字母及以內的單詞所占比例要高于羅譯本,但6個字母及以上的單詞所占比例是低于羅譯本的。這表明,羅譯本中選用的單詞較長,難度也相應較高,而林譯本的選詞簡單,便于理解。例如:
(3)原文:雖無絲竹管弦之盛,一觴一詠,亦足以暢敘幽情。
羅譯本:Through lacking musical accompaniment, each of us is inclined to pour forth his innermost feelings.
林譯本:No music is provided, but with drinking and with song, our hearts are gay and at ease.
在例(3)中,羅譯本的譯句共有15個單詞,其中6個字母及以上的單詞有8個,約占53.3%。而林譯本的譯句中共有17個單詞,其中6個字母及以上的單詞有3個,約占18.2%。我們知道,文言文中的措辭注重簡潔凝練,以少總多。羅譯本為了準確傳達原文的含義,喜歡用長詞來翻譯原文,導致譯文中長詞較多,增加了譯文的閱讀難度。而林語堂沒有嚴格地對原文進行還原,喜歡用簡單的詞匯進行描述,更為利落、傳神地再現出聚會者的悠閑情懷,就此而言,他在風格上是更貼近原文、更忠實原文的。
四、兩個譯本的句法對比
陳建生等(2010)指出,平均句長是衡量翻譯風格的典型因素[14]。一般說來,平均句長的值越大,表明文本中句法結構越復雜。由表1可知,羅譯本的平均句長為18.37,林譯本的平均句長為14.96。這說明林譯本句法結構較為簡單,而羅譯本句法結構較為復雜。
繆昌義(2004)按照結構成分,將英語句子分為四類:簡單句、并列句、復雜句和并列復雜句[15]。筆者對這一分類進行了簡化處理,把并列句、復雜句和并列復雜句統稱為復雜句,并運用正則表達式和軟件AntConc3.5.0,對兩個譯本中的句子進行了統計。具體如表5所示:
由表5可知,林譯本中簡單句數多于羅譯本,而復雜句數少于羅譯本。這再次表明林譯本句子結構簡單,利于讀者理解。為了更直觀地了解兩個譯本中句子的使用情況,筆者又對各類句子的所占比例進行了統計,具體如圖2所示:
由圖2可知,林譯本中的簡單句所占比例為32%,遠遠高于羅譯本的18.52%。而羅譯本中的復雜句所占比例為81.48%,又高于林譯本的68%。這說明羅譯本中句子結構較為復雜,以英語為母語的讀者理解起來有一定難度。
五、兩個譯本的篇章對比
中國古代散文語言凝練,句子之間很少用到連詞,注重意合。邵志洪曾指出,漢語中的意合是指詞語或句子間的連接,不是依靠連接詞而是憑借語義或語句間的邏輯關系實現的[16](P11)。而英語作為形合語言,詞語或句子間的銜接則要通過連接詞來實現。
在《蘭亭集序》中,幾乎沒有連接詞,漢語讀者自能從字里行間理解其語法意義。不過,將《蘭亭集序》譯為英文后,譯者必然會添加“and、or、but”等連詞來表示邏輯關系。筆者運用軟件AntConc3.5.0對羅、林譯本中的連接詞情況進行了統計,具體如圖3所示:
由圖3可知,羅譯本連接詞所占比例為7.66%,略高于林譯本的6.95%。這說明羅經國、林語堂都重視英語連接詞的使用,同時林譯本的篇章結構要相對簡單一點。
同時,筆者還運用可讀性分析器BFSU Readability Analyzer 1.1對羅、林譯本的可讀性(Readability)進行了分析。可讀性分析器是一種用來提取英語文本基本可讀性統計數據的工具。軟件BFSU Readability Analyzer 1.1是由北京外國語大學的賈云龍編寫、由許家金和賈云龍設計。該軟件可計算出一系列有關可讀性的典型因素。其中,由Flesch于1948年提出的福萊士易讀分數(Flesch Reading Ease)和福萊士難度級數(Flesch-Kincaid Grade Level)是評定文章難易程度的重要因素[17]。福萊士易讀指數和福萊士難度級數的計算公式分別為(ASL指平均句長,ASW指平均詞長):
福萊士易讀指數=206.835-(1.015×ASL)-(1.015×ASW)
福萊士難度級數=(0.39×ASL)+(11.8×ASW)-15.59
為了便于理解福萊士易讀指數,賈云龍和許家金提出文本難度指數(Text Difficulty)[18]。文本難度指數=100-福萊士易讀指數。福萊士易讀指數測試以百分制來評定文本的分數,分數越高(0~100),文本越容易理解,標準文本的分數大多在60~70之間。而文本難度指數中,分數(0~100)越高,文本越難理解。福萊士難度級數從0到10.0對文本進行評定,正常值在7.0~8.0之間。
基于軟件BFSU Readability Analyzer 1.1,筆者對羅、林譯本進行了分析,具體如圖4所示:
由圖4可知,林譯本的福萊士易讀指數高于羅譯本,文本難度指數和福萊士難度級數都低于后者。這表明林語堂的譯本比羅經國的譯本簡單,容易理解。同時也表明,羅經國的翻譯風格較為繁復,而林語堂的翻譯風格更加簡潔。
本文通過運用語料庫文體學,對《蘭亭集序》的羅經國譯本和林語堂譯本進行對比分析。可以看出,羅譯本忠實于原文,注重逐字逐句進行翻譯,力求準確傳達原文的含義,書面化色彩較濃。但句子結構和選用單詞較長,用詞重復,有時會造成譯文冗余,增加閱讀的負擔。林語堂在傳達原文含義的基礎上,選用豐富、精煉的詞匯和句子結構,譯文簡潔凝練,口語化較為突出,便于英語讀者理解。可見,羅譯本和林譯本在翻譯風格上是存在一定區別的。總的來看,語料庫文體學這種將定性研究與定量研究相結合的研究范式,具有重要的理論意義與實踐價值,它不僅能提供一種全新、客觀的思路和方法,而且在很多研究領域都有著廣闊的應用前景。
參考文獻:
[1]劉靖,黃立波.《語料庫文體學》述介[J].外語教學與研究,2010,(3).
[2]彭建,宋會鴿.“俯”“仰”之間的生命戀歌——解讀王羲之《蘭亭集序》[J].語文教學通訊(學術刊), 2017,(11).
[3]尹雅萍.石崇《金谷詩序》與王羲之《蘭亭集序》比較研究[J].河北科技師范學院學報(社會科學版), 2017,(4).
[4]任慶亮,鄧晶晶.《蘭亭集序》漢譯英轉換中的英漢語言文化對比[J].雞西大學學報,2016,(8).
[5]雷蔚茵,楊曉春.論中西思維方式的差異在漢英語篇翻譯中的體現——《蘭亭集序》漢英語篇對比分析[J].牡丹江大學學報,2012,(5).
[6]劉李娥.基于職業能力培養的高職大學語文課程教學設計——以《蘭亭集序》為例[J].智庫時代,2018,(42).
[7]羅經國.古文觀止精選(漢英對照)[M].北京:外語教學與研究出版社,2005.
[8]林語堂.古文小品譯英[M].北京:外語教學與研究出版社,2009.
[9]Baker,M.Towards a Methodology for Investigating the Style of a Literary Translator[J].2001,(2).
[10]Baker,M.Corpora in Translation Studies:An Overview and Some Suggestions for Future Research[J].Target,1995,(7).
[11]潘登,熊兵.基于語料庫的大學簡介英譯文詞匯特征及翻譯研究[J].外國語文研究,2017,(5).
[12]胡壯麟.語言學教程(第三版)[M].北京:北京大學出版社,2007.
[13]Stubbs,M.Lexical Density:A Computational Technique and Some Findings[A].In Coulthard,M. (ed.). Talking about Text:Studies Presented to David Brazil on His Retirement[C]. Birmingham:English Language Research University of Birmingham,1986.
[14]陳建生,伊麗,林婷婷.《狼圖騰》英文譯本翻譯特征之考察——一項基于可比語料庫的研究[J].內蒙古師范大學學報(哲學社會科學版),2010,(1).
[15]繆昌義.英語句子分類的再思考[J].昭通師范高等專科學校學報,2004,(1).
[16]邵志洪.漢英對比翻譯導論[M].上海:華東理工大學出版社,2005.
[17]Flesch,R.A New Readability Yardstick[J].Journal of Applied Psychology,1948,(3).
[18]http://office.microsoft.com/en-us/help/HP101485061033. aspx
