多卷積神經網絡模型融合的皮膚病識別方法
2019-11-12 09:27:48許美鳳國雷達宋盼盼遲玉婷杜少毅耿松梅張勇
西安交通大學學報 2019年11期
許美鳳,國雷達,宋盼盼,遲玉婷,杜少毅,耿松梅,張勇
(1.西安交通大學第二附屬醫院皮膚病院,710004,西安; 2.西安交通大學軟件學院,710049,西安;3.西安交通大學人工智能與機器人研究所,710049,西安;4.西安交通大學第一附屬醫院胸外科,710061,西安)
皮膚癌的發病率非常高,是最常被診斷的癌癥類型。基底細胞癌是最常見的皮膚癌,所以盡早發現基底細胞癌對預防和治療很關鍵[1]。脂溢性角化病與基底細胞癌的臨床癥狀和皮膚病理影像具有非常高的相似性。醫生一般通過觀察每個切片的皮膚病理影像特征來判斷所屬類別,由于醫生具有個體差異性,一旦醫生出現判別疲勞,準確率將會下降。在醫療條件不完善的情況下,基底細胞癌和脂溢性角化病的誤診率很高,這導致許多患者無法得到及時有效的治療。隨著機器學習技術的發展,可以使用機器學習方法對它們進行自動識別,以提高醫生的效率,并解決醫療條件不足時病患的確診和治療。
隨著數據量的擴增和計算能力的提高,深度學習已廣泛用于醫學影像診斷中,例如:使用3D全卷積網絡分割器官和血管[2];使用無監督GANet對病理圖像進行識別[3];使用目標檢測方法在乳房X光照片上檢測并識別惡性或者良性病變[4];使用生成對抗網絡生成高質量的肝臟病變感興趣區域,用于提高肝臟病變識別準確率[5]等。卷積神經網絡(CNN)是深度前饋神經網絡,已成功應用于圖像識別研究。自Lecun等識別手寫數字[6]以來,基于CNN的圖像識別、檢測、分割、配準和檢索已成為熱門話題。雖然CNN單模型如AlexNet[7]、PCANet[8]、VGG[9]和GoogLeNet[10]已經能夠獲得較準確的圖像識別結果,但仍有很大的改進空間。
本文為了提高模型的識別準確性,首先在基底細胞癌和脂溢性角化數據集上訓練多個單模型,以獲得良好的識別結果。由于單個模型的準確性有限,可以使用多個模型集合來準確識別病理切片。其次,由于投票和線性回歸等傳統融合方法無法很好地處理噪聲,因此提出了一種基于最大相關熵準則(MCC)的多模型融合方法,用于降低噪聲干擾并提高模型的準確性[11-12]。最后,對基底細胞癌和脂溢性角化病進行了識別實驗,結果表明,本文提出的模型相比單個模型具有很高的準確性和抗噪性。
1 卷積神經網絡

圖1 CNN方法的結構
隨著硬件設備性能的提高和數據量的急速增加,深度學習方法已成為醫學圖像的主要處理方法,圖1為CNN方法的結構。CNN通過卷積核對原始圖像進行卷積以提取圖像的特征,然后使用激活函數使神經網絡具有非線性特征。池化層用于在縮小圖像尺度的同時保留提取到的圖像相關特征。全連接層能夠將前面層的特征融合在一起,并最終產生預測輸出。批量歸一化方法[13]對每層的輸入分布進行調整,從而加速神經網絡計算并改善神經網絡梯度。神經網絡通過反向傳播來學習每個參數的權重[14]。每層卷積核所學習的特征是不同的,前面的卷積層的卷積可以學習圖像的局部特征,后面的卷積層能夠學習圖像的全局特征,因此在識別相似的圖像時,提取局部特征的網絡層更為重要[15]。在醫學圖像處理中,標注數據的數量通常是有限的,因此許多醫學圖像處理需要使用遷移學習[16]。遷移學習是一種可以將在現有任務上表現良好的模型遷移到類似的任務中并取得較好效果的方法[17]。因此,可以使用在其他大型數據集上的預訓練模型作為初始模型的參數,然后將其在目標任務上進行遷移學習,以便模型可以快速收斂到更好的結果。
在CNN模型中,ResNet[18]、Xception[19]和DensNet[20]為主要的圖像識別網絡,其原理如下。隨著神經網絡的深度增加,梯度消失和梯度爆炸使得網絡變得難以訓練。ResNet使用深度殘差網絡,可以有效地解決此問題。作為Inception v3的改進,Xception引入了基于Inception v3的深度可分卷積,在不增加網絡復雜度的同時提高了精度。DensNet是一種新的卷積網絡架構,引入了相同尺度的特征之間的密集連接。DenseNet的優點是減輕了消失梯度,增強了特征的傳播,促進了特征的重用,并大大減少了參數的數量。在一系列圖像識別數據集上,DenseNet以較少的計算實現了更高的性能。
2 多卷積神經網絡模型融合方法
2.1 多模型融合框架
雖然CNN單模型取得了很大進展,但準確性仍然有限。為了解決這個問題,通常使用多模型融合方法。傳統的多模型融合方法,例如基于投票和線性回歸的方法等,雖然可以提高模型的準確性[21],但是還有可以改進的空間。投票法的缺點是準確率高的模型與準確率低的模型的權重相同,使得具有最高準確率的單個模型對集合模型的貢獻變小。因此,融合模型方法的核心是如何學習權重以最大化準確率。圖2顯示了模型融合的框架,其中包括在數據集上訓練DensNet、Xception和ResNet模型,然后學習每個單模型對最終模型的權重。

圖2 基于DensNet、Xception和ResNet的融合模型框架
學習不同模型權重的經典方法是線性回歸,通常使用均方誤差(MSE)作為線性回歸損失函數[22],MSE用于度量預測值與真實值之間差異。因此,基于已訓練的3個單模型,使用MSE來學習每個模型的參數。
使用f(xi)來表示集合模型中的第i個樣本預測值。xi=[pi1,pi2,pi3]T表示第i個樣本在3個模型中的輸出概率,其中pij=[pij1,pij2]T,j=1,2,3,表示第i個樣本在第j個模型中分別屬于基底細胞癌的概率和脂溢性角化病的概率。使用w=[w1,w2,w3]表示融合模型的權重,wj表示第j個模型的權重。因此,f(xi)可以表示為
w1pi1+w2pi2+w3pi3+b=
[w1,w2,w3][pi1,pi2,pi3]T+b=wxi+b
(1)
式中b是常數項。現假設有m個樣本,可以通過最小化MSE來測量預測值f(xi)和第i個樣本真實標簽yi之間的差異,即
(2)
基于MSE的多模型融合方法學習每個模型的不同權重,可以結合每個單模型的優點,以最大化每個模型對最終效果的貢獻,提高模型的靈敏度和準確性。預測值與真實值越接近,則最終的損失越小;反之,預測值與真實值之間的損失呈二次方增加。這意味著噪聲和異常值對整體影響很大。在正常情況下,MSE適用于遵循正態分布的數據,但如果存在許多噪聲,MSE則不是最優的相似性估計器。
2.2 基于相關熵準則的多模型融合方法
眾所周知,MSE并不能有效克服數據中的噪聲,但基底細胞癌和脂溢性角化病的數據有很多噪聲,各個單模型的判別結果也不穩定,所以基于MSE的方法效果不佳。因此,本文提出了一種基于MCC的多模型融合方法來解決這個問題。
相關熵與MSE非常類似,也適用于量化兩個隨機變量A和B之間的相似性,變量A和B的相關熵為
Vσ(A,B)=E[?σ(A-B)]=
(3)
式中:?σ(·)是核函數;σ是核寬度;E(·)代表數學期望。核寬度控制評估相似性的窗口,核函數將輸入空間映射到更高維度的空間,1/2σ2稱為核參數。
本文將相關熵準則應用于學習多個單模型的參數并減少噪聲的影響。相關熵目標函數定義為
J2(w,b)=
(4)
相關熵準則用于量化預測值和真實值之間的相似性。當預測值等于真實值時,熵準則獲得最大值。隨著預測值和真實值之間的差異增加,熵的極限趨近于0。這意味著當預測值和真值之間存在較大差異時,該方法對噪聲和異常值具有良好的抑制效果。
優化目標是通過最大化式(4)的值來學習參數w和b。梯度上升方法可迭代地求解目標函數的最大值。梯度上升方法意味著每次迭代都在函數的當前梯度的正方向上執行。wk-1、wk分別表示第(k-1)次和第k次權重更新的矩陣,bk-1和bk分別表示第(k-1)次和第k次更新的值。可對目標函數執行梯度上升方法,即
(5)
(6)
式中λ為學習速率。通過對熵準則進行梯度上升,經過多次迭代使目標函數接近最大值,以達到學習參數w、b的目的。
參數σ影響所提方法中的回歸效果和抵抗噪聲的能力。從式(4)可知:如果σ較大,則所提方法具有與基于MSE的融合方法類似的性能,這意味著它不能有效克服噪聲;如果σ較小,則所提方法將能抵抗噪聲并產生更好的結果。另外,方法的收斂速度也受σ的影響,σ越大,則收斂速度越快。
3 實驗比較和分析
本節通過實驗評估了本文方法在基底細胞癌和脂溢性角化病的病理切片上的識別表現。實驗數據來自西安交通大學第二附屬醫院皮膚病院,基底細胞癌病理切片有1 100例,脂溢性角化病理切片有2 000例,通過旋轉與部分裁剪來獲得更多的訓練數據。實驗中將單模型與本文方法在識別精確率、召回率和準確率共3個方面進行比較,同時也將本文方法與傳統的融合模型進行比較,以證明基于MCC的多模型融合方法的有效性。
3.1 與單模型比較
使用在ImageNet上預訓練的網絡模型作為初始權重,將其用于訓練CNN模型。ResNet的輸入圖像尺寸為224×224像素,Xception與DensNet的輸入圖像尺寸為299×299像素。使用Adam優化方法[23],初始學習率為0.01。學習率衰減策略為在10個迭代周期中驗證集損失不再下降時,設置學習率為原來學習率的1/10。模型訓練的迭代周期為300次。
表1給出了本文提出的基于MCC的融合方法與單模型DensNet、Xception和ResNet在基底細胞癌與脂溢性角化數據集上的效果,可以看出:在3個單模型中,DensNet具有最高的精度,ResNet精度和靈敏度最低,基于MCC的多模型融合方法的準確性和靈敏度高于單模型。圖3顯示了各個單模型和基于MCC的融合方法預測結果,圖中:中間橫線上方是基底細胞癌圖像,橫線下方是脂溢性角化圖像,淺色框表示樣本識別錯誤,深色框表示樣本識別正確。 從圖3可以看出:在基底細胞癌和脂溢性角化病數據集中,單模型ResNet、Xception、DensNet在給出的案例圖片中都有錯誤識別結果,而提出的融合模型可以對案例中單模型識別錯誤的圖像進行正確地識別,說明本文方法有效。
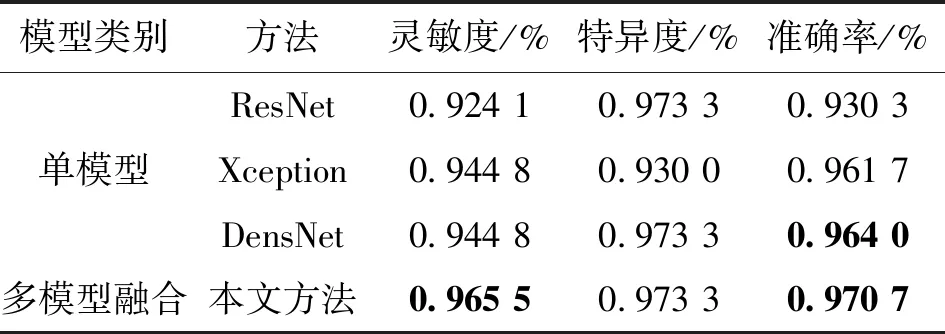
表1 本文MCC方法與單模型方法在基底細胞癌與脂溢性角化數據集上的識別效果比較
注:表中加粗數據為最優值。

a:原始病理圖像;b:ResNet識別結果;c:Xception識別結果;d:DensNet識別結果;e:基于MCC的融合方法識別結果圖3 ResNet、Xception、DensNet和基于MCC的融合方法分類結果比較
3.2 與多模型方法比較
將所提方法與傳統的多模型融合方法進行比較。由于每個單模型的輸出可以是標簽或相應的概率,所以將它們分別用作多模型融合方法的輸入。
實驗結果分析發現,一些由切片制作過程中產生的異常數據被錯誤識別,對于這些含有噪聲的異常數據,單模型的判別結果誤差較大。基于MCC的多模型可以減少噪聲數據與相同類型數據之間的差異,從而減少噪聲數據對結果的影響。表2是本文MCC方法與其他融合方法在基底細胞癌與脂溢性角化數據集上的識別效果比較。圖4為多種模型上基底細胞癌與脂溢性角化的識別結果。圖中:中間橫線上方是基底細胞癌圖像,橫線下方是脂溢性角化圖像;淺色框表示樣本識別錯誤,深色框表示樣本識別正確。
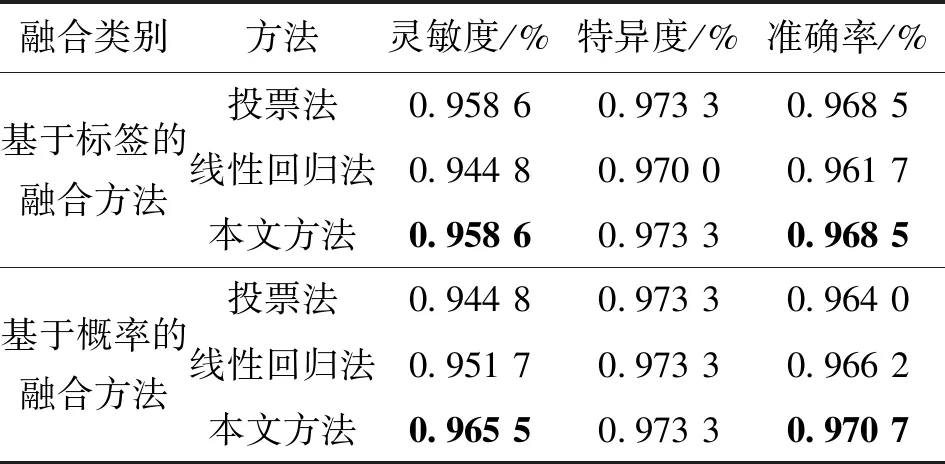
表2 本文MCC方法與其他融合方法在基底細胞癌與脂溢性角化數據集上的識別效果比較
注:表中加粗數據為最優值。
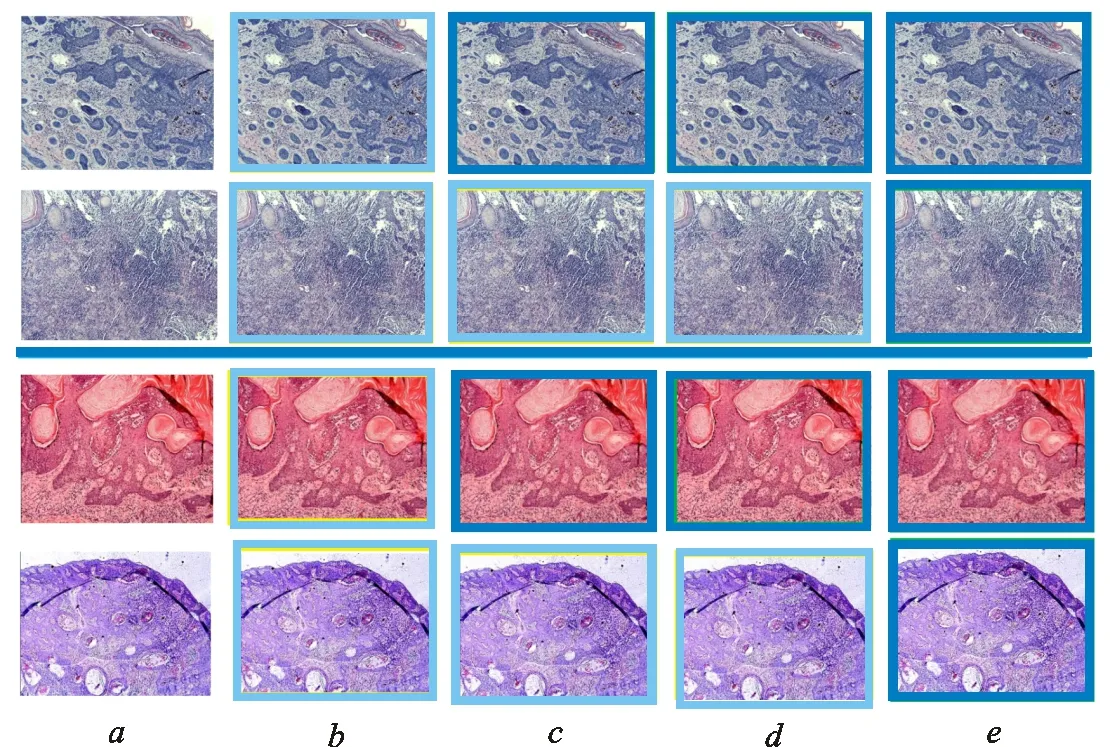
a:原始病理圖像;b:準確率最高單模型DensNet識別結果;c:基于概率的投票法識別結果;d:基于概率的MSE方法識別結果;e:基于概率的MCC方法識別結果圖4 基底細胞癌與脂溢性角化圖像的識別結果
比較表1和表2可知,融合模型的準確率高于單模型。由表2可知:基于標簽的投票法的結果優于基于概率的投票法的結果,因此如果使用投票法,則輸入最好是標簽;基于MCC的多模型融合方法的靈敏度和準確度優于其他集合模型,因此本文方法可以有效地克服噪聲并獲得更好的結果。
若基底細胞癌與脂溢性角化圖像非常相似,則單模型識別概率接近0.5,即單模型對這類圖像識別效果較差。融合模型可以在此類數據上獲得更好的結果。這是由于單模型學到的特征不足以區分這種小差距,多模型融合方法可以通過學習權重來擴大間隙,從而獲得可靠的結果。綜上可知,基于MCC的多模型融合方法比其他融合方法效果更好。
4 結 論
本文針對皮膚病臨床特征非常相似、不易區分且帶有大量噪聲等問題,建立了一種基于MCC的多CNN模型融合方法,并在皮膚病識別中獲得了較高的識別率。本文得出的主要結論如下。
(1)建立了多深度學習模型融合方法。使用遷移學習方法訓練獲得各個單模型的最佳結果,并利用投票法、回歸分析法等方法分別進行多個模型的融合,在構建的皮膚病數據集中的實驗證明了多模型融合方法相比于單模型具有更高的準確率。
(2)提出了基于MCC的多深度學習模型融合方法。該方法能有效克服皮膚病理切片中噪聲多的問題,學習多個單模型對最終結果的貢獻程度。實驗結果表明,該方法能夠有效地提高模型識別的靈敏度和準確度,獲得更好的泛化能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
現代出版(2020年3期)2020-06-20 07:10:34
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
