上海煙草數據中心卷煙零售數據庫的架構優化
2019-11-14 07:54:02陳德莉
中國煙草學報 2019年5期
陳德莉
上海煙草集團有限責任公司,信息中心上海,上海長陽路717號 200082
隨著煙草行業信息化發展的不斷深入,上海煙草數據中心的數據倉庫逐年積累的數據不斷增多,在國家局煙草專賣局推出下行數據之后,上海煙草數據中心接入物流打掃碼數據、零售戶訂單數據,社會庫存數據等,其中零售戶訂單數據的數據量逐年增多,逐步達到10TB以上,難以保障原有的數據加工、數據更新等數據處理性能。基于上述背景,研究并提出了零售戶數據處理性能優化方法。
目前,處理海量數據的軟件產品分為兩類,一類是基于大規模并行處理(MPP)架構的關系型數據庫;另一類是基于Hadoop平臺的軟件產品。MPP(Massively Parallel Processing),即大規模并行處理,在數據庫非共享集群中,每個節點都有獨立的磁盤存儲系統和內存系統,業務數據根據數據庫模型和應用特點劃分到各個節點上,每臺數據節點通過專用網絡或者商業通用網絡互相連接,彼此協同計算,作為整體提供數據庫服務。非共享數據庫集群有完全的可伸縮性、高可用、高性能、優秀的性價比、資源共享等優勢。MPP采用無共享資源結構,優勢體現在大規模存并行計算上[1-3]。Hadoop分布式文件系統(HDFS)是運行在通用硬件上的分布式文件系統,它可提供一個高度容錯性和高吞吐量的海量數據存儲解決方案[2]。通過對這兩種軟件產品的評估,并基于現有關系型數據庫的運行環境,決定引入MPP架構的關系型數據庫:一方面可以通過改變數據庫的架構提升數據處理性能;另一方面,可以不改變現有數據庫產品以及相關技術降低性能優化造成的影響程度,以最小的投入完成性能提升[3]。在升級數據庫架構之后,對現有的數據架構做了進一步的優化,主要包括了數據物理模型和數據處理兩方面。
1 零售戶訂單數據處理現狀
1.1 數據庫架構
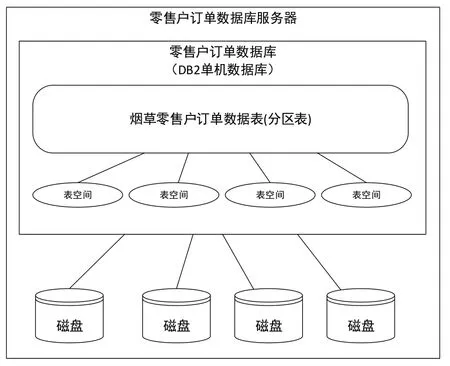
圖1 上海煙草數據中心零售戶訂單數據架構現狀Fig.1 Current architecture of retail order database of Shanghai tobacco data center
上海煙草數據中心零售戶訂單數據庫架構如圖1所示:零售戶訂單數據存儲在一臺DB2單機數據庫中,數據以分區表的方式存儲,每個月作為一個數據分區,每個分區的數據分別存儲在不同的表空間上。
1.2 數據處理業務
零售戶訂單數據的應用主要是統計若干零售戶訂單指標用于一些分析型報表,指標包括零售戶需求量和訂單量、三維五率、零售戶個數等。零售戶訂單數據處理的業務流程如圖2所示:
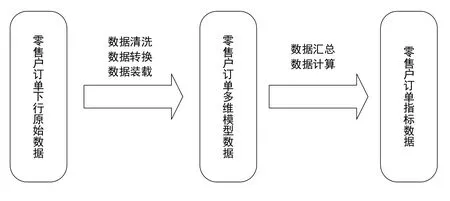
圖2 上海煙草數據中心零售戶訂單數據處理業務流程Fig.2 Retail order data processing flow of Shanghai tobacco data center
零售戶訂單數據分為三層,第一層是零售戶訂單原始數據,該層數據為零售戶訂單原始數據,通過國家局零售戶訂單數據下行到數據中心,該層數據加工不對數據做任何的轉換,是國家局零售戶訂單數據的拷貝副本;第二層是零售戶訂單多維模型數據,該層數據由原始數據通過數據清洗、數據轉換、數據裝載等數據處理之后生成。數據清洗是指清洗原始數據中的臟數據,數據轉換是指將原始數據轉換為星型或者雪花型模型數據;第三層是零售戶訂單指標數據,該層數據由多維模型數據計算生成,用于各類報表和應用。
2 零售戶訂單數據處理性能問題分析
根據統計每個數據處理環節的耗時,上海煙草數據中心處理零售戶訂單數據的性能瓶頸主要在于數據匯總。原始訂單數據的時間細粒度為“日”,平均每天的數據量為800萬條,通常都需要計算某段周期的數據,例如周訂單量、月訂單量、月零售戶個數、三個月零售戶個數、年零售戶個數等,這些數據匯總處理耗用大量的時間。其中,統計零售戶個數耗時最長,零售戶個數指標的統計口徑為:周期內有訂單量的零售戶數量。計算零售戶指標的耗時如下:

表1 計算零售戶指標耗時情況Tab.1 Time consuming for calculating retailer indexes
通過分析上述性能問題,發現統計零售戶訂單數據的性能瓶頸主要在于數據匯總環節。現有煙草零售戶訂單數據部署在一臺單機DB2數據庫上,若要提升數據處理性能,使得計算時間能夠減少至60分鐘以內,在硬件方面,升級單機服務器硬件資源已經意義不大,需要使用支持并行處理的海量數據處理產品,橫向擴展硬件資源,提升數據處理并行度。為了驗證其可行性,將若干年份的煙草零售戶訂單數據遷移到MPP架構的DB2數據庫以及Hadoop平臺的HIVE中,測試兩個平臺下匯總1年煙草零售戶訂單數據的性能,發現兩者的數據匯總性能相對于現單機數據庫平臺均提升,運行耗時如表2所示。
根據上述測試,引入海量數據處理產品提升零售戶訂單數據的處理性能是可行的。此外,目前的數據處理效率也并非達到最優在數據處理業務方面,從多維模型數據直接計算各周期的指標數據,會存在部分數據重復匯總的情況,例如月零售戶指標與近3個月零售戶指標,月度數據是重復匯總的。因此還需要優化現有數據架構,包括數據物理模型,數據處理業務流程等,以此提升數據處理效率。

表2 在DB2 MPP數據庫、Hadoop平臺、DB2單機數據庫下匯總1年零售戶訂單數據Tab.2 Performances of DB2 MPP, Hadoop and DB2 for summing 1-year retailer order data
3 數據庫架構優化
3.1 數據庫架構優化設計
目前,基于大規模并行處理(MPP)技術處理海量數據的軟件產品分為兩類,一類是基于大規模并行處理(MPP)架構的關系型數據庫;另一類是基于Hadoop平臺的軟件產品。上海煙草集團數據中心列舉了若干評估項對兩類產品進行評估,評估項列表如下所示:
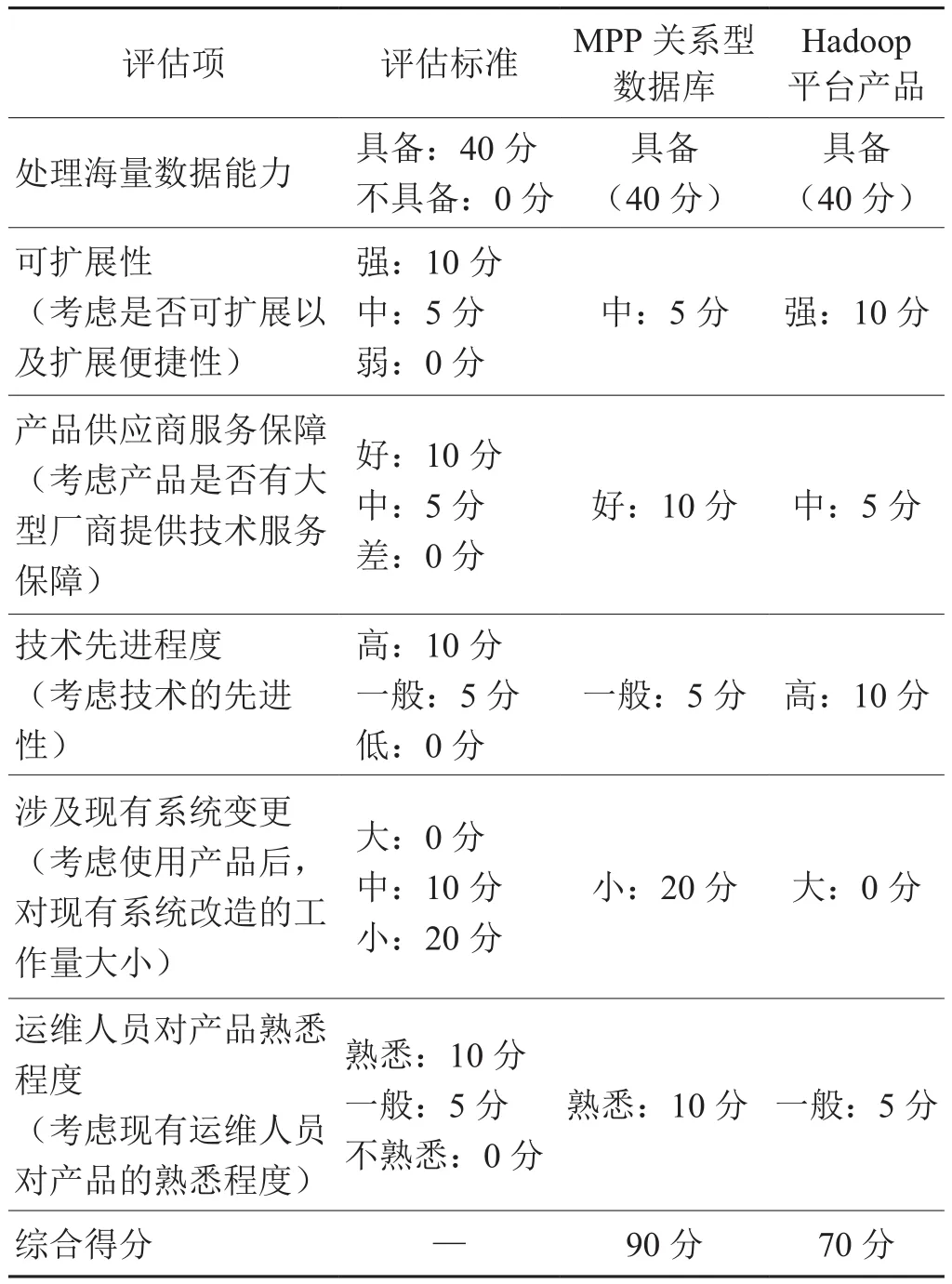
表3 海量數據處理產品選型評估項列表Tab.3 List of evaluation for massive data processing products
根據評估結果,決定采用基于大規模并行處理(MPP)架構的關系型數據庫作為處理的煙草行業訂單數據的平臺,提升處理性能。針對單機數據庫在處理海量數據時的性能問題,重構數據庫架構為大規模并行處理MPP架構,以并行處理的方式計算煙草零售戶訂單數據相關計量指標,提升數據處理性能。簡單來說,MPP是將任務并行的分散到多個服務器和節點上,在每個節點上計算完成后,將各自部分的結果匯總在一起得到最終的結果。總體架構如圖3所示:
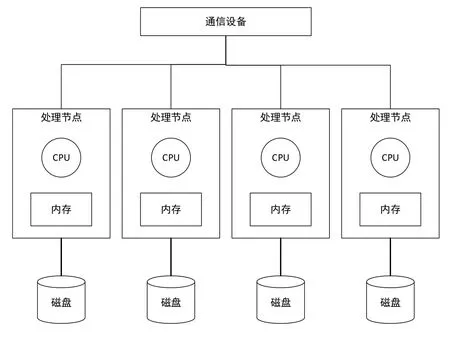
圖3 大規模并行處理總體架構Fig .3 Massive parallel processing (MPP) architecture
根據上述大規模并行處理MPP數據庫架構,在數據中心增設以大規模并行處理MPP為架構的數據庫,用于存儲和處理煙草零售戶訂單數據。MPP數據庫中的訂單數據均勻的分布在每個處理節點的磁盤上,獨享每個處理節點的硬件資源,在處理數據時,每個節點并行計算,達到提升性能的目的。
3.2 數據庫架構優化實現
上海煙草數據中心配置5臺服務器用于部署MPP數據庫,數據庫平臺為IBM DB2。其中,1臺服務器作為主節點,用于數據庫軟件安裝和處理節點之間的通信,4臺服務器作為處理節點,用于數據存儲和計算。其硬件配置如下:
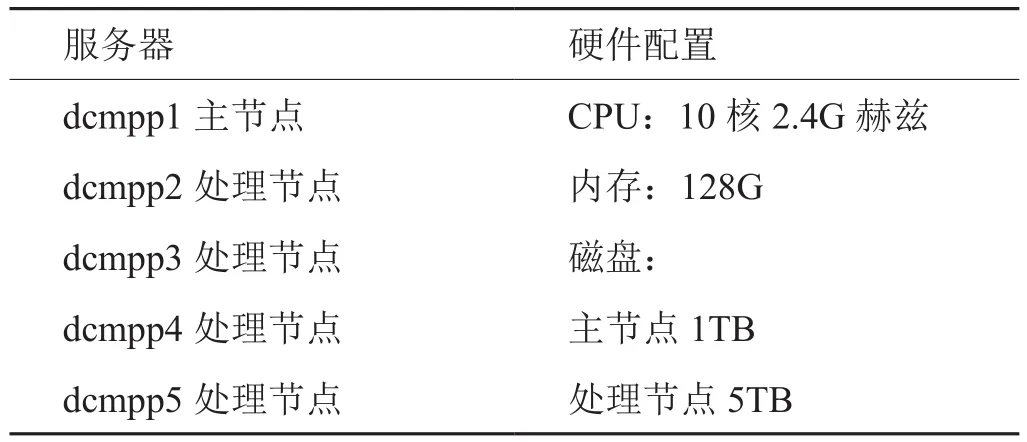
表4 上海煙草數據中心MPP數據庫硬件配置Tab.4 MPP hardware configuration of Shanghai tobacco data center
以MPP架構安裝DB2數據庫的實現過程如下:
(1)數據庫安裝
在主節點安裝數據庫軟件,設置與各處理節點間的無密碼通信,在每個器節點配置通信端口,并為主節點和處理節點配置數據庫分區,實現以MPP架構安裝DB2數據庫。
(2)處理節點上的磁盤劃分
處理節點用于存儲和處理零售戶訂單數據,可以在每個處理節點中創建若干個容量相同的磁盤分區,提升每個節點的IO并行度。
(3)數據庫表空間創建
為數據庫設置合理的緩沖池,分區組;可以將磁盤分區作為存儲器添加到數據庫并創建數據庫自動管理的大型表空間和臨時表空間,以此提升表空間性能。
(4)優化數據庫參數
調整數據庫性能參數優化性能,參數包括:應用堆大小、最大請求IO數量、排序堆、索引掃描速度、最大并行度、通信緩沖池大小、最大文件打開數量、應用程序堆大小等。
4 數據架構優化
4.1 數據架構優化設計
在數據庫架構升級成大規模并行處理(MPP)架構后,原先的數據架構也需要做相應的優化,主要體現在數據物理模型和數據處理流程兩個方面。
4.1.1 數據物理模型優化設計
(1)分區鍵設計
在大規模并行處理MPP架構模式下,任何資源都是非共享的,也包括了磁盤非共享,數據在存儲時必須均勻的分布到各處理節點的磁盤上,否則各處理節點處理的數據量不同,導致各節點處理耗時不同。可以使用哈希分布的方式,由數據庫將數據鍵的值映射成哈希值,均勻存儲到每個處理節點。設計數據庫分區的基本原則是:將數據量大的表分布在所有分區上提高并行處理能力;將數據量小的表放置在單一分區上;減少分區間的通信[4]。
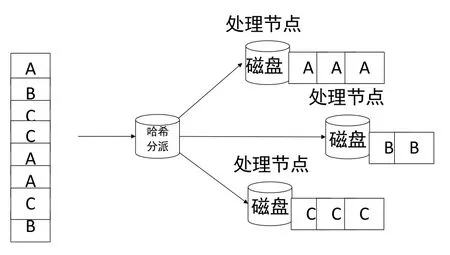
圖4 MPP數據庫均勻分布數據原理Fig.4 Data allocation mode of MPP database
數據分區鍵可以是一個字段,也可以是多個字段,數據分區鍵的值需要滿足數量多,分布廣的特點,以確保數據可以均勻分布到每個處理節點。
(2)數據表分區設計
對于海量結構化數據,可以設置數據分區表提升數據訪問性能。表在數據庫中是一個邏輯的概念,數據分區表可以視作一個包含了多個子表的表簇[5],當存儲海量結構化數據時,可以設置數據分布表,數據被拆分為若干個部分,分別存儲到數據分區表中的每一個子表,減少不必要的數據訪問。
當設置數據分區表時,需要明確指定表分區鍵以及鍵值范圍,表分區鍵以及鍵值的范圍可以根據具體的數據使用情況而定,一般時間序列的數據以日期字段作為數據表分區鍵,按月、季、年等周期分區。
(3)數據索引設計
在大規模并行處理(MPP)數據庫中對表中的字段設置分區索引,提升數據查詢性能;除此之外,還可以使用多維聚簇分區索引(MDC),MDC在物理上按照某個或者某幾個字段進行群集,采用了“BLOCK”來進行索引的組織,一個BLOCK會包含很多條傳統索引機制所采用的“行”記錄,因而提高了索引的粒度。使得索引的定位變得更快。
4.1.2 數據處理流程優化設計
目前數據處理過程中存在重復匯總數據的情況也影響了性能,MPP數據庫提升數據處理并行度,而優化原有的數據處理業務層次,減少大批量數據重復匯總則可以提升數據處理效率。在多維模型數據層和指標數據層之間添加一個中間層,中間層的數據按時間周期匯總。通過拆解各指標數據的計算過程,提煉其中重復匯總的數據,將這些數據納入中間層做統一匯總,在指標數據計算時,直接提取已匯總的數據計算,提升計算效率。
中間層可以視為指標數據的預處理層,由于在計算指標數據時,通常的統計周期為周、月、季、年等。中間層可以充分利用MPP數據庫大規模并行處理的性能優勢,預先按時間周期快速匯總數據,縮小了在指標計算時的數據規模,提升處理性能;對于個別無法使用中間層數據計算的指標,也可直接使用多維模型數據層的數據計算。
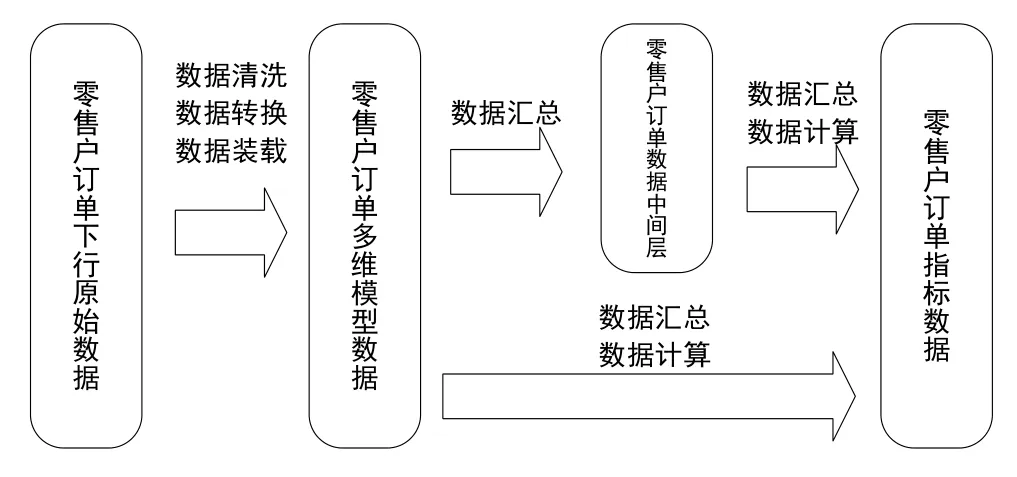
圖5 數據處理流程優化設計Fig.5 Optimization of data processing flow
4.2 數據架構優化實現
4.2.1 數據物理模型優化實現
零售戶訂單數據中涉及的業務數據主要為零售戶信息和卷煙訂單信息。其中零售戶信息包括零售戶號、地區、城鄉分類、經營業態、經營規模;訂單信息包括:訂單號、賣出方、卷煙條碼、需求量、訂單量、訂單金額。
(1)分區鍵設定
在MPP數據庫中零售戶訂單數據的分區鍵設為[訂單號,卷煙條碼],訂單號和卷煙條碼其兩者的組合滿足數量多,分布廣的特點,是合適的分區鍵。
(2)數據表分區設定
以數據的業務日期為表分區鍵按月分區數據。大部分零售戶訂單數據涉及的統計指標以月為周期,按月分區數據,可以有效提升數據訪問性能。
(3)數據索引設定
設置[賣出方]、[零售戶號]、[卷煙條碼]、[地區]字段的分區索引,提升這些字段與維度表關聯的性能;設置[業務日期,地區編碼]字段為多維聚簇分區索引(MDC),使相同鍵值的數據在物理上存儲在相鄰的數據塊,提升數據讀取性能。
4.2.2 數據處理流程優化實現
在統計煙草零售戶訂單數據相關的指標前,預先以周、月等時間周期維度以及組織機構、地區等維度匯總訂單量、需求量、零售戶數等度量作為煙草零售戶訂單中間層數據,部署在MPP數據庫上,縮小統計最終指標的數據源的數據量,以此提升數據處理性能。計算后的指標數據其數據量已經減少,以單機數據庫的方式存儲,提供各數據集市和應用系統使用。數據量對比如下所示:

表5 1年煙草零售戶訂單數據在預處理前與預處理后的數據量Tab.5 Amount of 1-year retail order data before and after pretreatment
5 結論
在完成上述優化后,將單機數據庫中的零售戶訂單多維模型數據同步到MPP架構數據庫,并初始化中間層匯總數據,統計從零售戶訂單多維模型數據處理成為指標數據的運行耗時,驗證零售戶數指標計算性能。分別統計優化前在單機數據庫上使用原有業務處理流程的運行耗時和在MPP數據庫上使用優化后業務處理流程的運行耗時(兩者均計算1年的零售戶訂單量數據),其計算耗時如下:
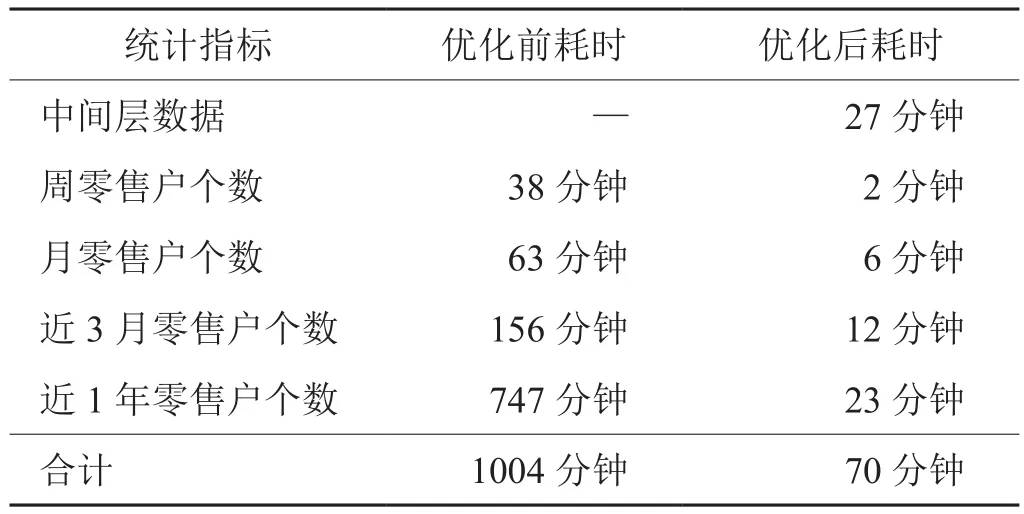
表6 優化前單機數據庫與優化后MPP數據庫計算零售戶指標耗時Tab.6 Time consuming of calculating retailer indexes before and after optimization
對比優化前后的數據同時耗時,優化后的性能提升90%以上,優化效果顯著。
本文針對上海煙草數據中心零售戶訂單數據處理性能問題進行了全面的分析和研究,給出了優化方法,主要在數據庫架構和數據處理業務兩個方面,從實施過程和驗證的結果來看,解決了上海煙草數據中心零售戶訂單數據處理性能問題。
通過上述的優化實施和驗證,在煙草零售戶訂單數據處理方面取得了一定效果并積累的較多的實施經驗,后續將在以下幾個方面繼續優化和完善:
(1)基于已有的MPP數據庫架構,增加若干數據庫節點,測試性能提升與數據庫節點的數量關系,計算最優節點數。
(2)進一步研究和優化數據處理業務,提升零售戶訂單處理性能。
(3)基于上述研究成果,在上海煙草數據中心內形成統一的海量數據處理技術標準。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
