融合信任信息的歐氏嵌入推薦算法
2019-11-15 04:49:03徐玲玲曲志堅徐紅博曹小威劉曉紅
計算機應用 2019年10期
徐玲玲 曲志堅 徐紅博 曹小威 劉曉紅


摘 要:為了改善推薦系統存在的稀疏性和冷啟動問題,提出一種融合信任信息的歐氏嵌入推薦(TREE)算法。首先,利用歐氏嵌入模型將用戶和項目嵌入到統一的低維空間中;其次,在用戶相似度計算公式中引入項目參與度和用戶共同評分因子以度量信任信息;最后,在歐氏嵌入模型中加入社交信任關系正則化項,利用不同偏好的信任用戶約束用戶的位置向量并生成推薦結果。實驗將TREE算法與概率矩陣分解(PMF)、社會正則化(SoReg)模型、社交的矩陣分解(SocialMF)模型、社交信任集成模型(RSTE)四種算法進行對比,當維度為5和10時,在Filmtrust數據集上TREE算法的均方根誤差(RMSE)比最優的RSTE算法分別降低了1.60%、5.03%,在Epinions數據集上TREE算法的RMSE比最優的社交矩陣分解模型(SocialMF)算法分別降低了1.12%、1.29%。實驗結果表明,TREE算法能進一步緩解稀疏和冷啟動問題,提高評分預測的準確性。
關鍵詞:社會化推薦;歐氏嵌入;協同過濾;矩陣分解;信任信息
中圖分類號:TP391
文獻標志碼:A
Abstract:? To solve the sparse and cold start problems of recommendation system, a Trust Regularization Euclidean Embedding (TREE) algorithm by fusing trust information was proposed. Firstly, the Euclidean embedding model was employed to embed the user and project in the unified low-dimensional space. Secondly, to measure the trust information, both the project participation degree and user common scoring factor were brought into the user similarity calculation formula. Finally, a regularization term of social trust relationship was added to the Euclidean embedding model, and trust users with different preferences were used to constrain the location vectors of users and generate the recommendation results. In the experiments, the proposed TREE algorithm was compared with the Probabilistic Matrix Factorization (PMF), Social Regularization (SoReg),Social Matrix Factorization (SocialMF)and Recommend with Social Trust Ensemble (RSTE) algorithms. When dimensions are 5 and 10, TREE algorithm has the Root Mean Squared Error (RMSE) decreased by 1.60% and 5.03% respectively compared with the optimal algorithm RSTE on the dataset Filmtrust.While on the dataset Epinions, the RMSE of TREE algorithm was respectively 1.12% and 1.29% lower than that of the optimal algorithm SocialMF. Experimental results show that TREE algorithm further alleviate the sparse and cold start problems and improves the accuracy of scoring prediction.Key words:? social recommendation; Euclidean embedding; collaborative filtering; matrix factorization; trust information
0 引言
隨著互聯網和信息技術的飛速發展,信息呈現指數式增長,用戶面臨著信息超載問題。為了幫助用戶更好地發現所需信息,推薦系統[1]應運而生。協同過濾技術作為推薦系統的重要組成部分,受到學術界和工業界越來越多的關注。協同過濾技術又可以分為基于記憶和基于模型的兩種推薦方法。基于記憶的推薦方法[2]主要通過利用用戶項目評分矩陣,根據相似用戶或相似項目,對用戶進行推薦;而基于模型的推薦方法[3-4]主要利用機器學習等方法訓練模型。在基于模型的協同過濾推薦方法中,矩陣分解技術因其具有較好的可擴展性和正確率,在推薦系統中扮演著重要角色。
矩陣分解技術的實質是在低維空間上通過潛在因子來表示用戶和項目,將較大的用戶項目評分矩陣分解為兩個低維潛在特征矩陣的點積,常用的方法包括概率矩陣分解(Probabilistic Matrix Factorization, PMF)[3]、改進的奇異值分解(Singular Value Decomposition enhancement,SVD++)模型[5]等。但是,矩陣分解技術僅能獲得用戶和項目的潛在特征,對于推薦結果的可解釋性較差。作為矩陣分解技術的一種替代形式,Khoshneshin等[6]提出了歐氏嵌入(Euclidean Embedding, EE)模型,該模型采用歐氏距離代替矩陣分解中的點積,將用戶和項目嵌入到統一的歐氏空間中,用距離來衡量用戶偏好。由于距離的大小和用戶偏好的程度成反比,用戶更喜歡離其最近的項目,因此可以通過距離搜索到用戶最感興趣的K個項目,從而達到快速推薦的目的。在此基礎上,Yin等[7]提出了加入時間的歐氏嵌入(Temporal EE, TEE)模型,該模型通過在EE模型中加入時間因子,捕捉用戶評分行為的動態性。
與傳統推薦算法一樣,EE模型和TEE模型均易遭受數據稀疏性和冷啟動問題。為改善這些問題,信任信息作為一種輔助信息被引入到推薦系統當中。這里的信任信息指的是在用戶間的交互過程中,一個用戶對另一個用戶產生的依賴和預期,在一定程度上反映了用戶的偏好[8]。例如,在Filmtrust數據集中,用戶會根據對電影的相似喜好,用1標注本身的信任用戶,從而建立信任關系。基于矩陣分解的社交推薦模型[8]表明,信任信息的引入可以改善傳統推薦系統的局限性,原因在于存在信任關系的用戶之間具有相似的偏好并互相影響,能夠有效地補充稀疏的用戶項目評分信息。Ma等[9]提出的社交信任集成(Recommend with Social Trust Ensemble, RSTE)模型,通過線性組合用戶自身的偏好和朋友的偏好影響來進行評分預測。Jamali等[10]提出的社交矩陣分解(Social Matrix Factorization, SocialMF)模型,通過考慮用戶和朋友之間應該具有相似的偏好,并加入信任傳播來約束用戶的潛在特征矩陣。陳婷等[11]提出基于概率矩陣分解的信任模型(Trust-PMF),高效融合了相似關系和信任關系。李衛疆等[12]利用信任傳播屬性填充信任矩陣,從而實現了用戶評分矩陣和信任矩陣結合。吳賓等[13]提出的聯合正則化矩陣分解推薦模型結合了物品間的關聯關系和社會關系。余永紅等[14]考慮到朋友在不同領域內對用戶影響不同這一行為,提出了一種融合用戶地位信息的社交推薦算法。
雖然上述方法都取得了較好的推薦效果,但大部分社交推薦方法采用矩陣分解技術來融合信任信息,通過歐氏嵌入來融合信任信息的工作相對較少。Li等[15]提出了基于歐氏嵌入的社交推薦(Social Recommendation approach based on EE, SREE)模型,在EE模型中引入社交信息,本質是線性組合用戶自身的偏好和朋友的偏好進行評分預測。但SREE忽視了不同信任用戶偏好的多樣性,這一多樣性體現在信任用戶的偏好可能有很大的差異性,一些信任用戶的偏好可能與目標用戶類似,而另一些信任用戶的偏好可能與目標用戶完全不同。
為了進一步緩解數據稀疏性和冷啟動問題,考慮不同信任用戶偏好的差異性,本文提出了一種融合信任信息的歐氏嵌入推薦(Trust Regularization EE, TREE)算法。本文算法通過引入項目參與度以及用戶共同評分因子來改進用戶評分相似度,并在歐氏嵌入模型的基礎上加入社交信任正則化項進行約束,使得用戶與其喜歡的項目和信任朋友間的空間距離較近,進而利用距離生成推薦結果,提高了推薦的準確性。
1 融合信任信息的歐氏嵌入推薦算法
在推薦系統中,假定有m個用戶和n個項目,相應地用戶集合為U={u1,u2,…,um},項目集合為I={i1,i2,…,in},則用戶項目評分矩陣為Rm×n。另外,在社交網絡中,存在由信任度表示的社交關系矩陣Sm×m。通過給定的用戶項目評分矩陣R和用戶間的社交關系矩陣S,社交推薦的目的是融合這兩種數據源,依據已知信息,預測用戶u對未觀測項目i的評分ru,i。
1.1 度量信任度
由于推薦系統數據集中的信任信息為二值信息,1表示信任,0表示不信任。在社交關系矩陣S中無法細化地區分用戶間的信任信息,導致所有信任用戶對目標用戶的影響權重都相同,忽略了信任用戶的不同偏好,影響了推薦的準確度。因此,首先需要對用戶間的信任關系進行量化。
通過利用用戶之間的評分相似度來對信任度進行度量,并在用戶評分相似度的基礎上引入項目參與度以及用戶共同評分因子進行改進。傳統的用戶評分相似度采用皮爾遜相關系數,公式如下:
其中: ru,i和rv,i分別為用戶u和用戶v對項目i的評分;u和v分別表示用戶u和用戶v對項目的平均評分;I(u)∩I(v)表示用戶u和用戶v共同評分的項目集合。
傳統的評分相似度公式僅側重于用戶的平均打分習慣帶來的偏差問題,沒有考慮不同項目的評分數量對相似度的影響。針對這一問題,引入項目參與度來衡量相似度。從項目評分數量的角度將項目分為熱門項目和冷門項目,熱門項目為得到用戶大量評分的項目,冷門項目為得到用戶較少評分的項目。由于大多數用戶對熱門項目都有評分,因此熱度越高的項目的評分對度量用戶興趣相似度的作用越小。在衡量用戶相似度時,需要引入項目參與度,區別熱門項目和冷門項目的影響,公式如下:
其中:C(i)表示對項目i的評分數量。當C(i)的值較大時,項目i為熱門項目,用戶u和用戶v同時對項目i進行評分時,項目參與度ide(i)較小;而當C(j)的值較小時,項目j為冷門項目,用戶u和用戶v同時對項目j進行評分時,項目參與度ide(j)則較大。因此,本文加入項目參與度后的相似度公式為:
其中:ide(i)為式(2)所表示的項目i的參與度。
另外,傳統的評分相似度還存在另一問題:當用戶共同評分的項目數量很少時,通過式(1)計算的相似度會非常高[18]。因此引入用戶共同評分因子改進這一問題帶來的影響,用戶共同評分因子的計算公式如(4)所示。
其中:Iu和Iv分別為用戶u和用戶v的評分項目集合;Iu∩Iv為兩個用戶共同評分的項目數量;max(Iu,Iv)為兩個用戶評分最多的項目數量。
因此,最終的信任度計算公式如下所示:
其中:weight(u,v)∈[0,1]為用戶共同評分因子;Sim*(u,v)為利用式(3)計算得到的用戶相似度。如式(5)所示,該信任度的度量方法融合了較多用戶信息,能夠較為準確地捕捉用戶間的社交信任關系,衡量信任用戶的不同偏好。
1.2 TREE模型
歐氏嵌入模型本質上是基于用戶的評分信息,在統一的歐氏空間中找到用戶和項目的位置。為了緩解數據稀疏性和冷啟動問題,TREE模型在歐氏嵌入模型中引入了社交信任信息,目的是使每個用戶在空間中不僅和所喜歡的項目的距離較近,還與偏好相似的信任用戶的距離較近。
為了達到這一目標,合理地調整用戶位置向量和項目位置向量。首先,隨機初始化兩個k秩矩陣分別表示用戶位置矩陣和項目位置矩陣,基于歐氏嵌入模型得到用戶與項目間的歐氏距離;同時,度量用戶信任信息,將皮爾遜相關系數、項目參與度和用戶共同評分因子結合來度量用戶間的信任度,填充用戶社交關系矩陣;再者,考慮到不同信任用戶的偏好多樣性,在社交信任正則化項里區別對待不同偏好的信任用戶,使得用戶評分信息和社交信任信息共同決定用戶和項目的位置。其主要優點體現在當用戶對項目的評分較少時,可通過社交信任信息找到用戶的合適位置。因此,TREE目標函數為:
在社交關系矩陣S中,存儲的僅為用戶間直接的信任信息,實際上用戶間還存在間接信任關系。為了引入用戶間接的信任信息,TREE模型也考慮到用戶間的信任傳播,這一點與社會正則化模型(Social Regularization, SoReg)[16]相似。例如用戶u信任用戶k,用戶k信任用戶v,雖然用戶u和用戶v不存在直接的信任關系,但通過最小化式(7)和式(8),也能間接地使用戶u的位置向量xu靠近用戶v的位置向量xv,從而尋求更優的xu本文采用隨機梯度下降法對式(6)的目標函數進行尋優,定義學習率為η,則更新規則為:
表示真實值與預測值之間的誤差;N-(u)表示信任用戶u的用戶集合;由更新規則得到最終的用戶位置向量xu和項目位置向量yi,代入u,i= μ+bu+bi-(xu-yi)(xu-yi)T可獲得預測評分,進而推薦給用戶評分最高的前K個項目,并且這些項目距離用戶較近。
TREE算法的具體描述如算法1所示。
算法1 TREE算法。
輸入 用戶項目評分矩陣R,社交關系矩陣S,用戶和項目位置向量的維度d,學習率η,迭代次數Iter。
輸出 用戶對未觀測項目的評分。
步驟1 隨機初始化兩個k秩的用戶和項目位置矩陣Xu和Yi、偏置項bu和bi。
步驟2 通過式(1)~(5)計算最終的用戶信任度,即結合式(1)的皮爾遜相關系數、式(2)的項目參與度和式(4)的用戶共同評分因子,從而量化用戶間的社交關系。
步驟3 采用隨機梯度下降法尋優目標函數,即式(6)。由式(9)~(12)在迭代次數Iter范圍內分別更新偏置項bu和bi、用戶位置向量xu、項目位置向量yi。
步驟4 使用步驟3最終更新后的bu、bi、xu、 yi,通過u,i= μ+bu+bi-(xu-yi)(xu-yi)T計算預測評分。
2 實驗與結果分析
2.1 數據集信息及評價標準
本文實驗采用Filmtrust和Epinions兩個數據集進行驗證,數據集的評分信息和信任信息如表1所示。
本文所有實驗采用5折交叉驗證,預測結果取5次的平均值。由于本文重點在于評分預測問題,因此采用平均絕對誤差(Mean Absolute Error, MAE)和均方根誤差(Root Mean Squared Error, RMSE)評價標準來衡量算法的預測準確度,并與其他算法進行比較。MAE和RMSE的計算公式如下:
其中:ru,i表示用戶u對項目i的實際評分;u,i表示用戶u對項目i的預測評分;T表示測試集中數據的數量。MAE和RMSE越小,表示預測效果越好。
2.2 對比算法及參數選擇
為了驗證本文模型的推薦準確度,選取與PMF[6]、SoReg[16]、SocialMF[10]、RSTE[9]四種模型進行對比,方法參照文獻[17]的參數設置,最佳參數為:
1)PMF。在Filmtrust數據集上,λ=0.1;在Epinions數據集上,λ=0.01。
2)SoReg。在兩種數據集上,λ=0.001, β=0.1。
3)SocialMF。 在Filmtrust數據集上,λ=0.001,λt=1;
在Epinions數據集上,λ=0.001,λt=5。
4)RSTE。在 Filmtrust數據集上,λ=0.001,α=1;
在Epinions數據集上,λ=0.001,α=0.4。
另外,TREE模型在兩數據集上的最佳參數通過實驗可得λ=0.001,γ=0.01。關于信任權重γ的選取在2.5節給出了實驗說明。
2.3 算法間性能比較
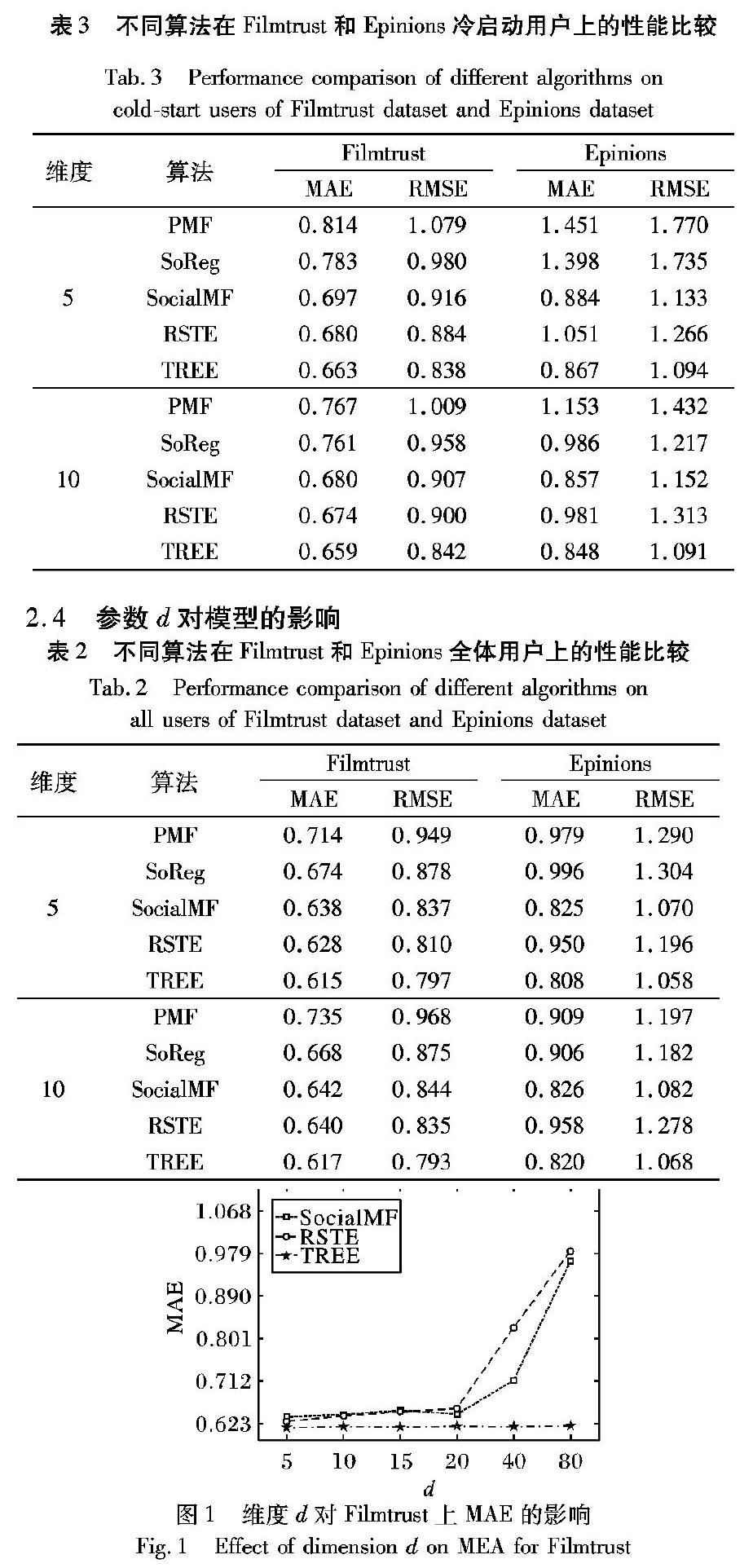
為了探究算法對于冷啟動問題的影響,在測試集中選取訓練集中評分數量少于5的用戶作為冷啟動用戶。選取維度d為5或者10,5種算法分別在全體用戶和冷啟動用戶進行測試。
從表2易知:
1)在Filmtrust數據集上,維度為5時,TREE模型相對于PMF、SoReg、SocialMF、RSTE在RMSE上分別降低了16.02%、9.23%、4.78%、1.60%;維度為10時,分別降低了18.08%、9.37%、6.04%、5.03%。可見,TREE在Filmtrust數據集上的有效性。
相對于Filmtrust數據集,模型在Epinions數據集上的預測結果整體下降,原因在于該數據集較稀疏,易遭受過擬合問題。在Epinions數據集上,維度為5時,TREE模型相對于PMF、SoReg、SocialMF、RSTE在RMSE上分別降低了17.98%、18.87%、1.12%、11.54%;維度為10時,分別降低了10.78%、9.64%、1.29%、16.43%。
2)在全體用戶上,SoReg、SocialMF以及RSTE算法在評分預測方面明顯優于PMF算法,可見信任信息的引入對于推薦的準確度有一定的提升。同時,TREE模型優于SoReg算法,表明本文在歐氏嵌入模型上加入社交正則化項一定程度上優于在傳統矩陣分解的基礎上加入的社交正則化項算法。
[7] YIN L, WANG Y, YU Y. Collaborative filtering via temporal Euclidean embedding[C]// Proceedings of the 2012 Asia-Pacific Web Conference, LNCS 7235. Berlin: Springer, 2012: 513-520.
[8] 劉華鋒, 景麗萍, 于劍. 融合社交信息的矩陣分解推薦方法研究綜述[J]. 軟件學報, 2018, 29(2): 340-362. (LIU H F, JING L P, YU J. Survey of matrix factorization based recommendation methods by integrating social information[J]. Journal of Software, 2018, 29(2): 340-362.)
[9] MA H, KING I, LYU M R. Learning to recommend with social trust ensemble[C]// Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2009: 203-210.
[10] JAMALI M, ESTER M. A matrix factorization technique with trust propagation for recommendation in social networks[C]// Proceedings of the 4th ACM Conference on Recommender Systems. New York: ACM, 2010: 135-142.
[11] 陳婷, 朱青, 周夢溪, 等. 社交網絡環境下基于信任的推薦算法[J]. 軟件學報, 2017, 28(3): 721-731. (CHEN T, ZHU Q, ZHOU M X, et al. Trust-based recommendation algorithm in social network[J]. Journal of Software, 2017, 28(3): 721-731.)
[12] 李衛疆, 齊靜, 余正濤, 等. 融合信任傳播和奇異值分解的社會化推薦算法[J]. 計算機工程, 2017, 43(8): 236-242. (LI W J, QI J, YU Z T, et al. Social recommendation algorithm integrating trust propagation and singular value decomposition[J]. Computer Engineering, 2017, 43(8): 236-242.)
[13] 吳賓, 婁錚錚, 葉陽東. 聯合正則化的矩陣分解推薦算法[J]. 軟件學報, 2018, 29(9): 2681-2696. (WU B, LOU Z Z, YE Y D. Co-regularized matrix factorization recommendation algorithm[J]. Journal of Software, 2018, 29(9): 2681-2696.)
[14] 余永紅, 高陽, 王皓, 等. 融合用戶社會地位和矩陣分解的推薦算法[J]. 計算機研究與發展, 2018, 55(1): 113-124. (YU Y H, GAO Y, WANG H, et al. Integrating user social status and matrix factorization for item recommendation[J]. Journal of Computer Research and Development, 2018, 55(1): 113-124.)
[15] LI W, GAO M, RONG W, et al. Social recommendation using Euclidean embedding[C]// Proceedings of the 2017 International Joint Conference on Neural Networks. Piscataway: IEEE, 2017: 589-595.
[16] MA H, ZHOU D, LIU C, et al. Recommender systems with social regularization[C]// Proceedings of the 4th ACM International Conference on Web Search and Data Mining. New York: ACM, 2011: 287-296.
[17] GUO G, ZHANG J, YORKE-SMITH N. A novel recommendation model regularized with user trust and item ratings[J]. IEEE Transactions on Knowledge and Data Engineering, 2016, 28(7): 1607-1620.
[18] 肖文強, 姚世軍, 吳善明. 一種改進的top-N協同過濾推薦算法[J]. 計算機應用研究, 2018, 35(1): 105-108, 112. (XIAO W Q, YAO S J, WU S M. Improved top-N collaborative filtering recommendation algorithm[J]. Application Research of Computers, 2018, 35(1): 105-108, 112.)
