基于深度Q網絡的人群疏散機器人運動規劃算法
2019-11-15 04:49:03周婉胡學敏史晨寅魏潔玲童秀遲
計算機應用 2019年10期
周婉 胡學敏 史晨寅 魏潔玲 童秀遲
摘 要:針對公共場合密集人群在緊急情況下疏散的危險性和效果不理想的問題,提出一種基于深度Q網絡(DQN)的人群疏散機器人的運動規劃算法。首先通過在原始的社會力模型中加入人機作用力構建出人機社會力模型,從而利用機器人對行人的作用力來影響人群的運動狀態;然后基于DQN設計機器人運動規劃算法,將原始行人運動狀態的圖像輸入該網絡并輸出機器人的運動行為,在這個過程中將設計的獎勵函數反饋給網絡使機器人能夠在“環境行為獎勵”的閉環過程中自主學習;最后經過多次迭代,機器人能夠學習在不同初始位置下的最優運動策略,最大限度地提高總疏散人數。在構建的仿真環境里對算法進行訓練和評估。
實驗結果表明,與無機器人的人群疏散算法相比,基于DQN的人群疏散機器人運動規劃算法使機器人在三種不同初始位置下將人群疏散效率分別增加了16.41%、10.69%和21.76%,說明該算法能夠明顯提高單位時間內人群疏散的數量,具有靈活性和有效性。
關鍵詞:深度Q網絡;人群疏散;運動規劃;人機社會力模型;強化學習
中圖分類號:TP391.7
文獻標志碼:A
Abstract: Aiming at the danger and unsatisfactory effect of dense crowd evacuation in public places in emergency, a motion planning algorithm of robots for crowd evacuation based on Deep Q-Network (DQN) was proposed. Firstly, a human-robot social force model was constructed by adding human-robot interaction to the original social force model, so that the motion state of crowd was able to be influenced by the robot force on pedestrians. Then, a motion planning algorithm of robot was designed based on DQN. The images of the original pedestrian motion state were input into the network and the robot motion behavior was output. In this process, the designed reward function was fed back to the network to enable the robot to autonomously learn from the closed-loop process of “environment-behavior-reward”. Finally, the robot was able to learn the optimal motion strategies at different initial positions to maximize the total number of people evacuated after many iterations. The proposed algorithm was trained and evaluated in the simulated environment. Experimental results show that the proposed algorithm based on DQN increases the evacuation efficiency by 16.41%, 10.69% and 21.76% respectively at three different initial positions compared with the crowd evacuation algorithm without robot, which proves that the algorithm can significantly increase the number of people evacuated per unit time with flexibility and effectiveness.
Key words: Deep Q-Network (DQN); crowd evacuation; motion planning; human-robot social force model; reinforcement learning
0 引言
隨著城市經濟建設的快速發展,大型購物中心、體育館、影劇院等高密度人群的公共場所越來越多。當緊急突發事件發生時,逃生的人群往往會在出口處擁擠而形成堵塞,容易發生事故,存在著極大的安全隱患。傳統人員安全疏散的方法有人工協助疏散和擺放靜止物體協助疏散。前者極度浪費人力資源,并且對工作人員的安全造成威脅,而后者難以有效地適應變化的環境,疏散效果不理想。因此,在公共場所發生緊急突發事件時,如何快速、科學地疏散人群是公共安全領域中一個亟待解決的問題。
國內外科學研究者在人群疏散問題上進行了深入的研究并建立了多種模擬人群行為的模型,其中由Helbing等[1]提出的社會力模型(Social Force Model, SFM)大量用于研究緊急人群疏散。另一方面,隨著計算機科學技術的發展,機器人越來越智能化,利用機器人疏散人群的方法也越來越多。Robinette等[2]提出機器人引導人群疏散到逃生出口;Boukas等[3]提出基于元胞自動機模型對人群疏散進行仿真,并利用仿真結果得到的反饋使移動機器人疏散人群。雖然這些利用機器人疏散人群的方法有一定的成效,但是由于實際疏散場景復雜,人群密度高,并且這些算法不具有學習能力,因而難以適應復雜的實際人群疏散場景。
在機器人疏散人群方法中,機器人的運動規劃算法是核心,直接決定疏散效果的好壞。運動規劃作為機器人領域的一個重點研究問題,是指在一定條件的約束下為機器人找到從初始狀態到目標狀態的最佳路徑和運動參數。傳統運動規劃方法是在先驗環境下,預先設定規則,機器人依據規則實現運動規劃。然而當遇到動態未知的環境時,此類方法由于靈活性不強而難以適應復雜環境。近幾年來,越來越多的運動規劃研究者把目光集中到機器學習方面,其中文獻[4]提出的深度強化學習就是運動規劃領域的研究熱點之一。深度強化學習是一種“試錯”的學習方法,自主體隨機選擇并執行動作,然后基于環境狀態變化所給予的反饋,以及當前環境狀態再選擇并執行下一個動作,通過深度強化學習算法在“動作反饋”中獲取知識,增長經驗。深度強化學習的開創性工作深度Q網絡(Deep Q-Network, DQN)通過探索原始圖像提取特征進行實時策略在視頻游戲等領域有了重大突破,Mnih等[5]利用智能體在策略選擇方面超越了人類的表現。隨后Mnih等[6]又提出了更接近人思維方式的人智能體運動規劃算法,并應用于Atari游戲,取得了驚人的效果。隨著AlphaGo的成功,深度強化學習在運動規劃問題上應用越來越廣泛,例如用于無人車[7]、無人機和多智能體[8]等領域。同時,Giusti等[9]利用深度強化學習在機器人的導航上也取得了廣泛的應用。基于深度強化學習算法的機器人在復雜未知的環境中學習速度更快、效率更高、靈活性更強,因此將深度強化學習應用于人群疏散機器人的運動規劃算法是解決人群疏散難題的一個有效途徑。
針對目前人群疏散機器人自主學習等問題以及深度強化學習的優點,本文提出一種基于深度Q網絡的人群疏散機器人運動規劃算法。該算法中,在基于人機社會力模型的前提下,機器人能夠通過自身的運動影響周圍人群的狀態。通過Su等[10]提出的卷積神經網絡(Convolutional Neural Network, CNN),提取人群疏散圖像的特征;設計面向人群疏散機器人運動規劃的DQN算法,通過DQN分析特征并進行運動規劃,給出機器人的運動策略。在獲取當前環境給予的反饋后,自動調整其運動參數,讓機器人運動到最佳的狀態,從而影響周圍人群的運動狀態,達到疏散人群的目的。本文方法既能解決公共安全領域中人群疏散的難題,又為深度強化學習算法在機器人領域的應用提供新思路。
1 機器人與人群的交互作用模型
本文采用文獻[11]中提出的人機社會力模型作為機器人與人群的交互作用模型。人機社會力模型以SFM為基礎。SFM是基于牛頓第二定律,將人群中的個體當成離散的質點,將人的運動軌跡看作是受到合力的作用效果,并綜合考慮人群心理因素設計的行人動力學模型,能夠解釋行人逃生時行為的本質。SFM中行人受到的合力由以下三種組成:自驅動力、人與人之間的相互作用力、人與障礙物之間的相互作用力。人機社會力模型是在原始的SFM中加入了機器人對人的作用,利用人機之間的相互作用力來影響人群的行為,從而達到疏散人群的效果。
由于在緊急情況下疏散人群時機器人的運動分析較為復雜。文獻[11]參照人與人之間的作用力來設計人機作用力的表達形式,如式(1)所示:
其中: fir為機器人對行人i的作用力,即人機作用力;rir表示人與機器人的幾何中心距離;Ar和Br分別指人機作用力的作用強度和作用范圍;k、κ為常量系數;nir表示機器人指向行人i的單位向量;tir為與nir正交的單位矢量。
其中:mi為行人i的質量;vi(t)為行人i的速度; fs為行人i的自驅動力; fij為行人i和j的相互作用力; fiw為行人i與障礙物之間的相互作用力。??在人機社會力模型中,機器人能夠通過自身的運動來影響和改變周圍行人的運動狀態,從而為人群疏散提供機器人與人群的交互作用模型。
2 基于深度Q網絡的機器人運動規劃算法
在機器學習方法中,深度神經網絡具有表達復雜環境的能力,而強化學習是解決復雜決策問題的有效手段,因此將兩者結合起來能夠為復雜系統的感知決策問題提供解決思路。DQN是一種經典的深度強化學習模型,是深度學習和強化學習的結合,也就是用深度神經網絡框架來擬合強化學習中的Q值,可以使機器人真正自主學習一種甚至多種策略[12]。本文在人機社會力模型的基礎上,針對人群疏散的問題,基于DQN模型設計面向人群疏散機器人的運動規劃算法,優化機器人的運動方式,從而影響人群的運動,提高人群疏散的效率。
2.1 深度Q網絡
DQN是一種結合了CNN與Q學習(Q-Learning)[13]的算法。
CNN的輸入是原始圖像數據(作為狀態),輸出是提取的特征;Q-learning通過馬爾可夫決策[14]建立模型,核心為三元組:狀態、動作和獎勵(反饋)。智能體根據當前環境的狀態來采取動作,在獲得相應的獎勵后,能通過試錯的方法再去改進動作,使得在接下來的環境下智能體能夠做出更優的動作,得到更高的獎勵。
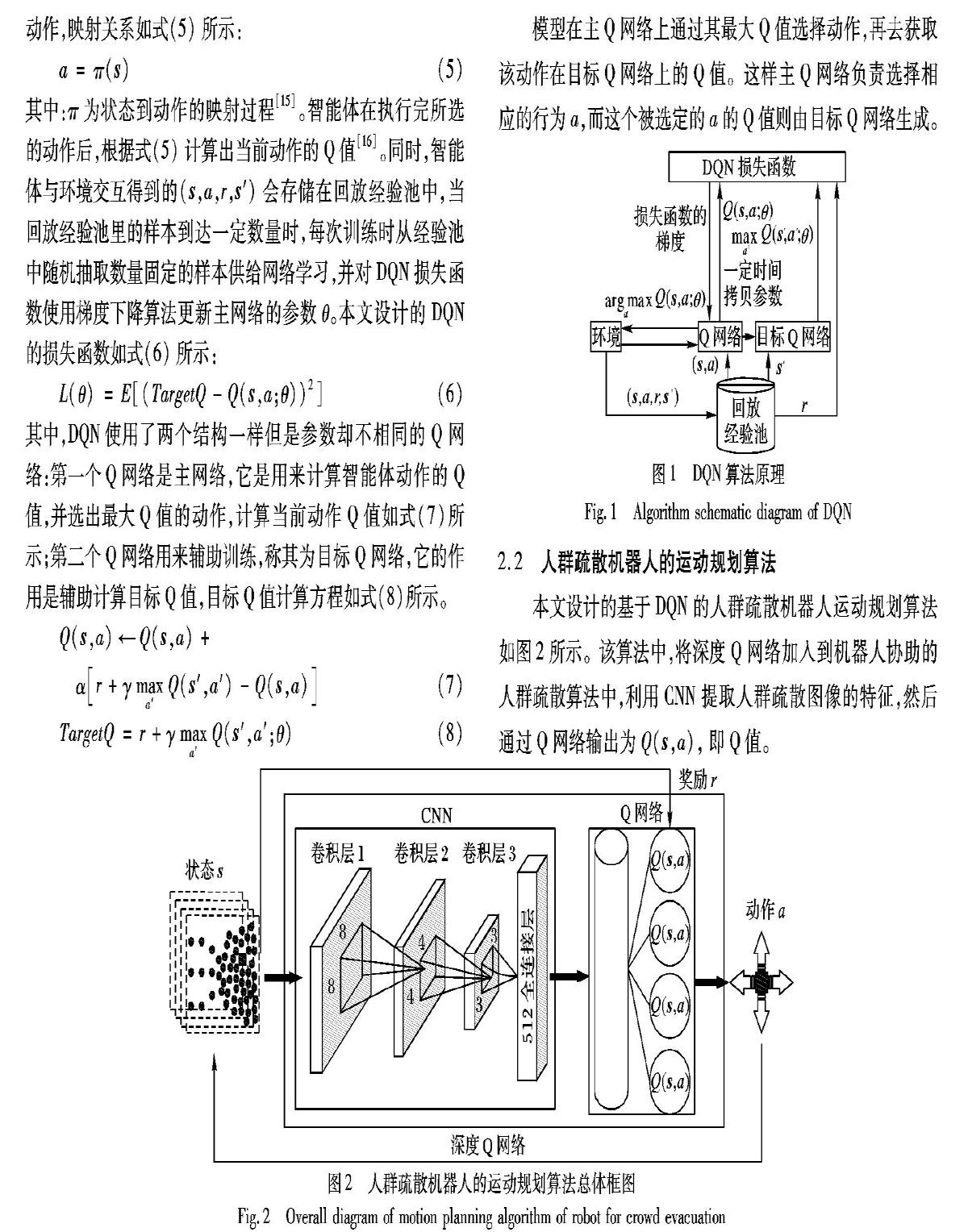
DQN用強化學習來建立模型和優化目標,用深度學習來解決狀態表示或者策略表示,它從環境中獲取數據,將感知的狀態輸入到Q網絡,使機器人選擇最大Q值的動作,每隔一定時間將主Q網絡的參數復制給目標Q網絡,并且網絡會通過損失函數進行反向傳播更新主網絡的參數,反復訓練,直至損失函數收斂,其算法流程如圖1所示。
圖1中:s為智能體的當前狀態;s′為智能體的下一個狀態;r為獎勵;a為機器人的當前動作;a′為機器人的下一個動作;γ為折扣因子;θ為網絡權值。智能體感知當前時刻下的狀態s,根據狀態與動作之間的映射關系來采取在當前環境的動作,映射關系如式(5)所示:
其中:π為狀態到動作的映射過程[15]。智能體在執行完所選的動作后,根據式(5)計算出當前動作的Q值[16]。同時,智能體與環境交互得到的(s,a,r,s′)會存儲在回放經驗池中,當回放經驗池里的樣本到達一定數量時,每次訓練時從經驗池中隨機抽取數量固定的樣本供給網絡學習,并對DQN損失函數使用梯度下降算法更新主網絡的參數θ。本文設計的DQN的損失函數如式(6)所示:
其中,DQN使用了兩個結構一樣但是參數卻不相同的Q網絡:第一個Q網絡是主網絡,它是用來計算智能體動作的Q值,并選出最大Q值的動作,計算當前動作Q值如式(7)所示;第二個Q網絡用來輔助訓練,稱其為目標Q網絡,它的作用是輔助計算目標Q值,目標Q值計算方程如式(8)所示。
模型在主Q網絡上通過其最大Q值選擇動作,再去獲取該動作在目標Q網絡上的Q值。這樣主Q網絡負責選擇相應的行為a,而這個被選定的a的Q值則由目標Q網絡生成。
2.2 人群疏散機器人的運動規劃算法
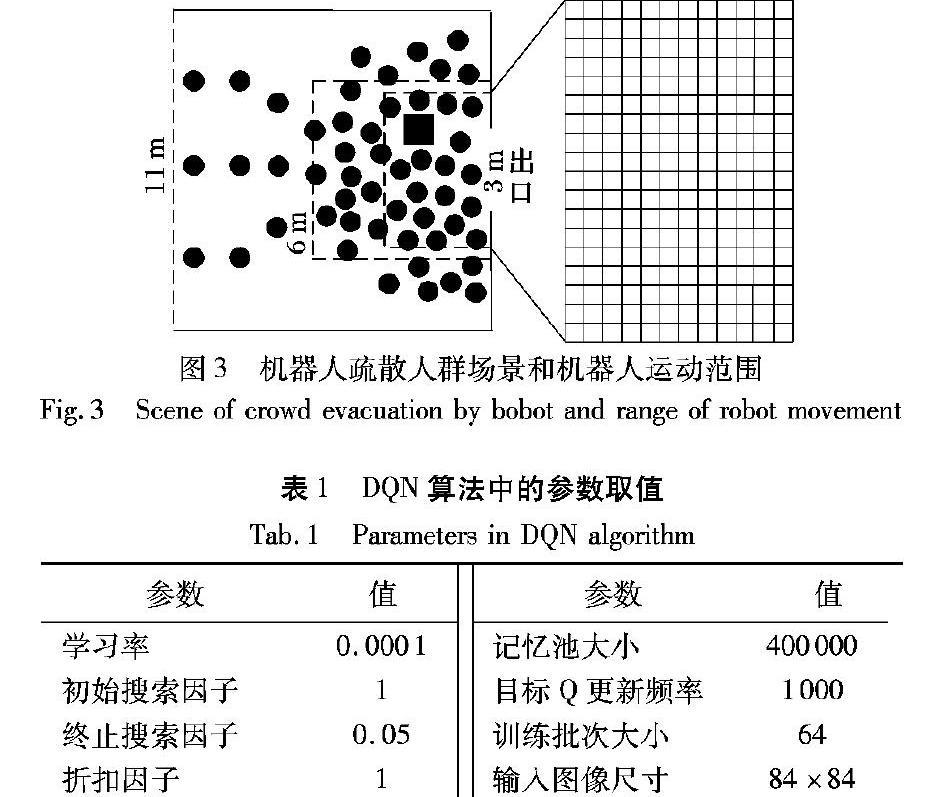
本文設計的基于DQN的人群疏散機器人運動規劃算法如圖2所示。該算法中,將深度Q網絡加入到機器人協助的人群疏散算法中,利用CNN提取人群疏散圖像的特征,然后通過Q網絡輸出為Q(s,a),即Q值。
機器人會根據當前人群疏散場景圖像的狀態st采取機器人協助疏散的動作at,進而根據獎勵函數獲得一個獎勵rt,并且達到下一個狀態st+1,機器人由獎勵來判斷該時刻自己選擇的動作的好壞,并更新值函數網絡參數。接著再由下一個狀態得到一個獎勵,循環獲得獎勵值,直至訓練結束,得到一個較好的值函數網絡。
本文設計的算法本質是機器人基于人群疏散的環境感知得到s,通過DQN選擇a并且得到獎勵r,從而對機器人的運動規劃進行優化。因此,設計狀態、動作和獎勵的算法對于本文提出的運動規劃算法起到至關重要的作用。
1)狀態空間設計。
狀態空間是機器人從環境中獲取的感知信息的集合,它在DQN中是Q-Learning的主線,為Q網絡提供信息數據;并且,每個輸入的狀態都能夠前向傳播,通過網絡獲得行動的Q值。由于原始圖像尺寸過大,處理數據需要占用計算機大量的內存空間與計算資源,并且圖像中還包含了許多諸如邊界像素等無效的信息,因此本文只將機器人附近的區域作為狀態輸入圖像,并對原始人群疏散圖像進行縮放處理,處理后輸入圖像的尺寸為84×84像素。為獲取前后幀的動態信息,本文對離當前時刻最近的n(本文中n=4為經驗值)幀場景圖像進行灰度化處理,并同時輸入CNN中。因此最終輸入狀態的圖像尺寸為84×84×4,用公式表述如(9)所示:其中:S為狀態的集合;st表示當前時刻輸入的狀態圖像;t為當前時刻?在本文設計的DQN模型中,用一個CNN來擬合Q函數,以降低深度Q網絡算法復雜度。由于本文輸入圖像為仿真圖像,圖像內容較為單一,所以本文設計提取狀態的CNN網絡結構較為簡單,如圖2所示。本文設計的模型一共有4層, 其中包括3個卷積層與一個全連接層。第一層卷積運算卷積核大小為8×8,步長為4;第二層卷積運算卷積核大小為4×4,步長為2;第三層卷積運算卷積核大小為3×3,步長為1;最后經過全連接層后輸出512個節點的映射集合。
2)動作空間設計。
動作空間是機器人根據自身的狀態采取的行為的集合,也是實現機器人運動規劃的運動參數,它在DQN中相當于指令集。本文中機器人的行為策略采用的是貪婪算法,貪婪算法是在對問題求解時,對每一步都采用最優的選擇,希望產生對問題的全局最優解[17]。機器人根據設定的參數探索概率ε的大小來選擇動作模式,并采取Q值最大的貪心動作。ε越大,機器人能更加迅速地探索未知情況,適應變化;ε越小,機器人則趨于穩定,有更多機會去優化策略。由于深度Q網絡適用于智能體采取離散動作,而實際場景中機器人往往采用連續的動作疏散人群。但只要相鄰動作間隔時間短,離散動作可近似為連續動作。機器人作為人群疏散的智能體,只有一個運動方向無法起到疏散效果;選取兩個方向又具有運動范圍的局限性,很難達到最優;如果選取8向運動,訓練復雜度太大。因此綜合考慮疏散效果和訓練復雜度,本文設計的機器人的動作采取上、下、左、右4個離散動作。動作集合如式(10)所示:
3)獎勵函數設計。
獎勵是對機器人選擇動作好壞的判斷根據,獎勵函數在DQN中起到引導學習的作用。DQN利用帶有時間延遲的獎勵構造標簽,即每一個狀態都有著對應的獎勵。在機器人協助的人群疏散中,目的是讓擁擠的人群更快速地疏散完畢,因此當前時刻撤離的人數是對機器人當前行為最直接的反饋。然而,倘若機器人在本次的動作對該次逃生出的人數有負影響,但在后幾次運動中疏散人群數量較多,也不能簡單判斷本次機器人選擇的動作是不合理的,因此本文采用機器人執行了一個動作后,未來人群在m(本文中m=5,經驗值)次迭代過程中疏散的人數作為環境給予學習系統的獎勵。通過逃出的人數值,可自然形成獎勵值。因此本文設計的獎勵函數如式(11)所示。
4)算法參數設計。
在深度強化學習算法中,參數的設計與調整對訓練的效果有很大的影響。本文基于DQN的人群疏散機器人運動規劃算法的參數如表1所示。
其中:學習率是指在優化算法中更新網絡權重的幅度大小,學習率太高會使網絡學習過程不穩定,而學習率太低又會使網絡經過很長時間才會達到收斂狀態。實驗結果表明,學習率設為0.0001時,網絡能較快地收斂到最優,因此本文選擇學習率為0.0001。隨機貪婪搜索中的搜索因子作為選取隨機動作的概率,在觀察時期,智能體是完全隨機選擇動作,因此本文選擇初始搜索因子為1;而隨著迭代次數增加,隨機動作概率逐漸減小,智能體會越來越依賴于網絡學習到的知識來選擇動作,因此選擇終止搜索因子為0.05。折扣因子表示時間的遠近對預期回報的影響程度,由于在本實驗中,即刻回報與未來回報同等重要,因此本文將折扣因子設為1。記憶池用來存儲樣本數據,在智能體學習過程中,網絡會從記憶池中隨機抽出一定量的批次進行訓練,經嘗試,本文選擇記憶池大小為400000。批次大小是每一次訓練神經網絡送入模型的樣本數,大批次可以使網絡訓練速度變快,但批次過大對硬件設備配置要求高,經實驗,本文將批次大小設為64。目標Q為目標網絡的輸出,周期性的更新目標Q可以提高算法的穩定性,經實驗,本文選擇目標Q更新頻率為1000。輸入網絡的圖像需保證圖像的清晰度并且確保囊括環境的基本特征,輸入圖像尺寸太大不易網絡訓練,輸入圖像尺寸太小又不易于網絡提取特征,因此基于本文環境,選擇輸入的圖像尺寸為84×84像素。
3 實驗與結果分析
本文設計的人群疏散仿真環境和機器人運動規劃算法均使用Python語言實現,其中DQN算法基于TensorFlow平臺實現。
3.1 室內人群疏散模擬場景設計
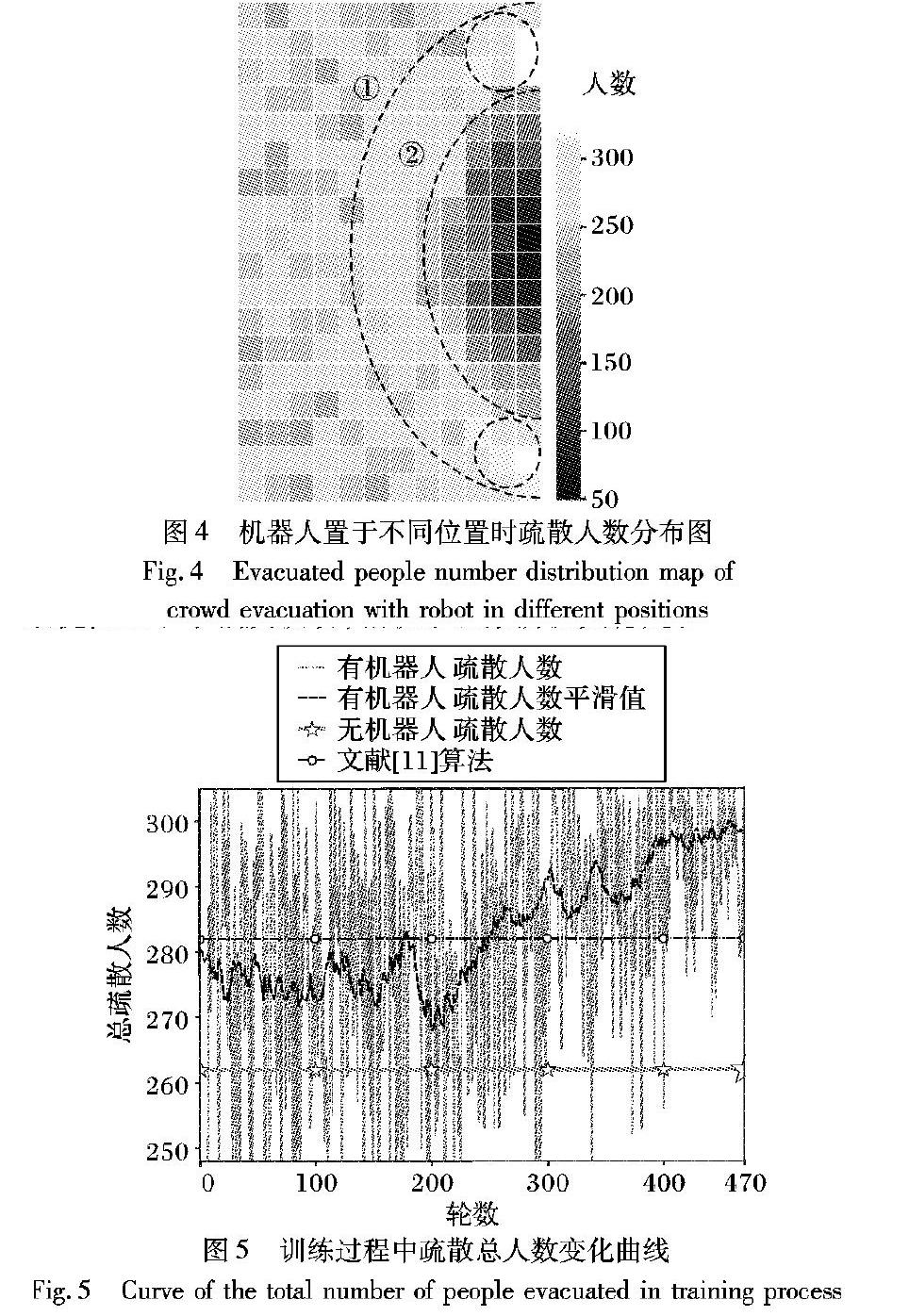
只有一個出口的室內場景,如醫院、酒店的大廳等場所,是最可能發生緊急事件需要進行人群疏散的場景,因此本文設計一個矩形中帶有一個出口的室內場景,并將其作為實驗環境,如圖3左圖所示。場景大小為11m×11m,出口寬度為3m,四周外圍實線方框代表墻壁,左邊虛線代表行人進入通道。本文設定圖3為某酒店大廳內安全通道的模擬場景,圖中左側虛線往左的部分區域發生了緊急事件,大樓內虛線左側的人群從虛線上的三個入口進入通道,并從通道右側的安全出口逃離危險。本文放置一個智能機器人在安全出口附近,并指定機器人的運動范圍,讓機器人通過深度Q網絡學會最優的疏散策略。當緊急事件發生時,場景中的行人由于恐慌和從眾心理會聚集在出口附近形成密度很大的群體。為逃離危險,各方向行人在自驅動力下向出口聚集,同時受到四周行人的相互作用力,使綜合前向作用力很小甚至為負,導致人群向出口的移動速度很小甚至反向運動, 從而極度降低了疏散效率。
為了提高人群的運動速度,增加單位時間內的疏散總人數,本文基于人機社會力模型,在人群中加入一個機器人,讓機器人在一定的范圍內運動,通過機器人的運動來影響人群,提高人群疏散的效率。由于人群疏散重點區域在出口附近,且為保證輸入網絡的圖像清晰和易于訓練,因此選取出口附近的矩形區域作為觀測區域,用于計算機器人的環境狀態,如圖3左圖中6m×6m的外側虛線框區域所示。在輸入DQN時,該區域通過均勻采樣得到84×84像素的圖像。此外,由于人群疏散的主要區域也在出口附近,因此選擇將出口附近的一個3.6m×5.4m長方形區域作為機器人的運動范圍,如圖3左圖中內側虛線框區域所示。為減少計算量和噪聲,本文設定機器人的運動速度為0.6m/s,其狀態每秒迭代2次,則每次迭代機器人移動距離為0.3m,在場景中的運動位置組成了12×18的矩形網格區域,如圖3右圖中的矩形網格所示。
為了驗證算法的有效性,采用單位時間內疏散的人數作為實驗評判標準。實驗中每次人群疏散單位時間為100s,在單位時間內疏散的總人數是疏散效果及性能的直接體現;同時,直接將機器人兩次迭代之間的逃生人數作為機器人一次運動的獎勵rt,每一輪人群疏散實驗中將每次機器人運動所得獎勵(一次機器人運動疏散人數)累加,即得到本文評判疏散效果的性能參數,即總疏散人數。實驗初始人數為100,初始位置在場景中隨機生成,并且設定人群按照一定的間隔時間從左邊進入場景。實驗中每次人群疏散單位時間為100s,實驗目的是最大化單位時間內疏散總人數,提高疏散效率。行人的半徑設定為0.3m,用黑色實心圓表示(如圖3所示),速度由初速度和其受到的綜合作用力決定;行人期望速度為6m/s;
機器人的邊長為1m,用黑色矩形表示,機器人在運動范圍內有上、下、左、右4個動作。為減少噪聲的干擾,在每一次人群疏散實驗中,機器人的狀態每迭代1次,行人運動狀態迭代5次。此外,為保證行人源源不斷進入場景,從圖3中左側三個位置每秒各產生1個水平速度為6m/s、縱向速度為0的行人,如圖3所示。
3.2 靜止機器人的人群疏散
由于在人群中合理擺放靜止物體對人群也有疏散作用,因此本文在訓練運動機器人之前,先探討靜止不動的機器人對人群疏散的影響。為觀察靜止機器人處在不同位置對行人的運動,以及對固定時間內疏散總人數的影響,本文將機器人的運動范圍劃分成如圖3右邊所示的12×18的網格,并將機器人置于每個小方格所在位置,保持靜止狀態,測試并記錄單位時間內總逃生人數;并且,將靜止機器人在每個小方格位置中對應的疏散總人數映射為二維圖像,以白色為背景,每個小方格顏色為由白色到黑色由疏散人數決定的離散采樣,如圖4所示,標尺上數字代表總疏散人數。
通過分布圖可以看出將靜止機器人置于不同位置時總疏散人數呈現明顯的分層結構。在以出口為圓心的半圓內,越靠近出口,總疏散人數越少,即對人群疏散有負面影響。在此半圓中,水平方向單位距離疏散人數值的變化比豎直方向更大一些。較好的疏散位置處在以出口中心為圓心的帶狀區域內,如圖4所示。當越過該帶狀區域后,即曲線①往左,總疏散人數沒有太大的變化。疏散人數變化大的位置在帶狀區域靠近門的位置,如圖4中曲線②所在的位置附近的區域。最優疏散位置及區域在出口附近上下兩側靠近右邊墻體的位置,如圖4中兩個橢圓區域所示。當機器人置于此區域時,單位時間內的疏散人數最多,即機器人的最佳疏散位置。
3.3 運動機器人的人群疏散
靜止機器人疏散分布圖大致由疏散效果較差的門口半圓區域、較優的帶狀區域(包括最優的橢圓區域)、無明顯變化的帶狀外區域組成,因此本文任意選取對這三種區域具有代表性的4個位置作為機器人初始位置集,測試本文提出的基于DQN的機器人運動規劃算法,觀察機器人運動軌跡。訓練DQN時,每次人群疏散實驗隨機從4個位置中選取一個作為機器人初始位置。
在DQN中,獎勵的變化是衡量模型訓練是否有效的重要參數。在本文提出的人群疏散機器人運動規劃算法中,獎勵由疏散的人數直接決定,因此為了顯示模型訓練的過程,將訓練過程中人群疏散的輪數與每輪實驗中單位時間內疏散的人數的變化關系用曲線表示,分析本文方法的有效性,如圖5所示。每輪實驗的單位時間為100s,即每輪實驗中,人群和機器人的初始狀態記為t=0s的時刻,人群疏散實驗到t=100s時結束,然后人群回到初始狀態,機器人從初始位置集隨機選取一個位置作為機器人的初始位置,重新開始新的一輪實驗。本文模型訓練時人群疏散實驗總輪數為470。
訓練前期處于觀察階段,機器人隨機選擇動作,每輪的逃生總人數相差較大。由于總體曲線波動較大,將其平滑處理,更能表現出訓練效果的變化。由圖5可看出,輪數小于200時的總疏散人數波動較大;訓練中期處于探索階段, 機器人通過記憶池中的數據學到越來越優化的動作序列;訓練后期則是網絡參數的微調階段,此時只有小概率探索,逃生人數在最優值上下小幅度波動,相較于觀察階段更穩定。
未設置任何機器人情況下的人群疏散主要基于人與人之間的社會力模型,疏散場景與添加機器人時的場景一致。此種情況下,單位時間內(100s)疏散總人數為262人,如表2中的數據和圖5中由星型標注的直線所示。
在測試階段,為觀察機器人運動規劃過程,本文在三個代表性區域額外各選取一個位置作為機器人的初始位置,分別記為P1、P2和P3,測試機器人在100s內人群疏散實驗中的運動過程,并記錄其運動軌跡,分別作為測試實驗1、測試實驗2和測試實驗3,其過程分別如圖6所示。三次實驗的總疏散人數如表2所示。為方便觀察機器人的運動方式,將機器人的運動軌跡畫在分布圖上,并研究不同時段機器人所處的位置。此外,為驗證機器人是否找到最優位置或區域,本文用虛線橢圓標記機器人最后10s的運動軌跡,如圖6所示。
測試過程采用本文設計的算法,機器人運動狀態每迭代1次,利用DQN的動作價值評估函數,對當前狀態下的每個動作進行評估,選取價值最大的,即期望下總疏散人數最多的動作作為機器人的運動規劃結果。在測試實驗1(如圖6(a)所示)中,機器人運動起點為P1,終點為Q1。疏散總人數達305人,與無機器人時疏散262人相比,疏散人數增加了16.41%。由于DQN算法在軌跡上的每個位置都選取當前價值最大的動作,則出現圖6(a)中機器人向著最優區域運動的軌跡,同時因機器人每個動作都是所在狀態下最優的,疏散人數最多的,最優動作的累加使總疏散人數最大,因此運動軌跡是起點為P1時的最優軌跡。
由于在帶狀外區域單位距離疏散人數值變化不大,當人群有波動時容易產生噪聲,造成偶爾機器人往左運動的現象。當機器人所處狀態中,疏散人數分布圖的某一方向的梯度與其他方向相比越大時,DQN價值函數對此狀態下最優動作的評估越準確。如測試實驗2(如圖6(b)所示)中的前7s運動軌跡所示,從P2開始到t=3s,左方向一直是單位距離疏散人數值增加最快的方向。從t=3s到t=7s的軌跡與圖4中②虛線所框半圓相切,可看出向下是疏散人數分布圖的梯度最大的方向。實驗2中,機器人運動起點為P2,終點為Q2。疏散總人數達290人,與無機器人時疏散262人相比,疏散效率增加了10.69%。
在測試實驗3(如圖6(c)所示)中,機器人運動起點為P3,終點為Q3。開始時機器人處在帶狀區域大概中間位置,周圍疏散人數分布圖的梯度較小,加上噪聲干擾,導致機器人初段運動軌跡較波折,但總方向是往下,即為人群疏散較好的位置運動。由于DQN能最大化獎勵的原理,總疏散人數也被最大化了,疏散總人數達到319人,與無機器人時疏散人數相比增加了21.76%。此外,在三次實驗中,機器人總會沿著梯度下降最快的路線到達最優區域及其附近區域。
為表明本文方法的有效性,除了與無機器人時對比外,還與文獻[11]中采用傳統的機器人運動規劃人群疏散算法進行對比,因兩者的行人運動都基于人機社會力模型,場景相似,具有較好的可比較性。為保證對比實驗的有效性,本文選取文獻[11]中的最優參數。經實驗,在單位時間內(100s),傳統方法疏散總人數為282人。
可明顯看出本文提出的基于深度Q網絡的算法在訓練穩定后的疏散人數明顯比傳統方法多。此外,文獻[11]方法需要針對每個實驗場景,反復手動調整來優化人群疏散的參數,工作量大且模型難以達到最優;而本文模型能夠通過DQN自主在環境中學習,尋找最優的疏散策略,靈活性更好、更具智能性,適合大多現實中的場景。
綜上所述,通過本文提出的基于DQN的機器人運動規劃算法,機器人能夠學習在不同初始位置下的最優運動策略,最大限度地提高總疏散人數,與無機器人干預以及傳統人群疏散方法相比,能夠有效地提高緊急情況下疏散人群的效率。
4 結語
本文提出了一種基于深度Q網絡的機器人運動規劃算法,并應用于人群疏散算法中,協助完成疏散人群。此算法不僅適用于本文場景,同樣也適用于與本文場景有相同特性的其他室內人群疏散的場景。該方法結合了深度學習中的CNN和強化學習中的Q-learning,通過當前時刻下環境圖像到機器人運動指令的端到端的學習,改變機器人的運動狀態,利用機器人與行人之間的相互作用,使機器人能夠在擁擠的情況下更加靈活、有效地疏散人群。本文實驗部分模擬了室內密集人群的逃生場景。結果表明,人群疏散機器人會隨著訓練的迭代次數增加而積累學習的經驗,從而能夠運動到最優位置,有效地疏散人群。由于應用DQN算法需要大量計算資源,容易產生維度災難,本文通過源源不斷產生人群使場景內人數在一定范圍內波動來解決維度災難的問題。因此,未來的工作將集中在解決固定疏散人數時深度強化學習面臨的問題,使疏散效率達到更優,并且利用3D場景模擬實際的攝像機拍攝的視頻來解決人群疏散的問題。
參考文獻(References)
[1] HELBING D, MOLNR P. Social force model for pedestrian dynamics[J]. Physical Review E: Statistical Physics, Plasmas, Fluids & Related Interdisciplinary Topics, 1995, 51(5): 4282-4286.
[2] ROBINETTE P, VELA P A, HOWARD A M. Information propagation applied to robot-assisted evacuation[C]// Proceedings of the 2012 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2012: 856-861.
[3] BOUKAS E, KOSTAVELIS I, GASTERATOS A, et al. Robot guided crowd evacuation[J]. IEEE Transactions on Automation Science and Engineering, 2015, 12(2): 739-751.
[4] POLYDOROS A S, NALPANTIDIS L. Survey of model-based reinforcement learning: applications on robots[J]. Journal of Intelligent and Robotic Systems, 2017, 86(2): 153-173.
[5] MNIH V, KAVUKCUOGLU K, SLIVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533.
[6] MNIH V, KAVUKCUOGLU K, SLIVER D, et al. Play Atari with deep reinforcement learning[EB/OL]. [2018-12-10]. http://export.arxiv.org/pdf/1312.5602.
[7] HWANG K, JIANG W, CHEN Y. Pheromone-based planning strategies in Dyna-Q learning[J]. IEEE Transactions on Industrial Informatics, 2017, 13(2): 424-435.
[8] IMANBERDIYEV N, FU C, KAYACAN E, et al. Autonomous navigation of UAV by using real-time model-based reinforcement learning[C]// Proceedings of the 14th International Conference on Control, Automation, Robotics and Vision. Piscataway: IEEE, 2016: 1-6.
[9] GIUSTI A, GUZZI J, CIRESAN D C, et al. A machine learning approach to visual perception of forest trails for mobile robots[J]. IEEE Robotics and Automation Letters, 2016, 1(2): 661-667.
[10] SU M C, HUANG D, CHOW C, et al. A reinforcement learning
approach to robot navigation[C]// Proceedings of the 2004 International Conference on Networking, Sensing and Control. Piscataway: IEEE, 2004: 665-669.
[11] 胡學敏, 徐珊珊, 康美玉, 等. 基于人機社會力模型的人群疏散算法[J]. 計算機應用, 2018, 38(8): 2165-2166. (HU X M, XU S S, KANG M Y, et al. Crowd evacuation based on human-robot social force model[J]. Journal of Computer Applications, 2018, 38(8): 2165-2166.)
[12] XIE L H, WANG S, MARKHAM A, et al. Towards monocular vision based obstacle avoidance through deep reinforcement learning[EB/OL]. [2018-12-10]. https://arxiv.org/pdf/1706.09829.pdf.
[13] LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL]. [2019-01-10]. https://arxiv.org/pdf/1509.02971.pdf.
[14] CUENCA , OJHA U, SALT J, et al. A non-uniform multi-rate control strategy for a Markov chain driven networked control system[J]. Information Sciences, 2015, 321: 31-47.
[15] 趙玉婷, 韓寶玲, 羅慶生. 基于deep Q-network雙足機器人非平整地面行走穩定性控制方法[J]. 計算機應用, 2018, 38(9): 2459-2463. (ZHAO Y T, HAN B L, LUO Q S. Walking stability control method based on deep Q-network for biped robot on uneven ground[J]. Journal of Computer Applications, 2018, 38(9): 2459-2463.)
[16] CHEN Y, LIU M, EVERETT M, et al. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning[C]// Proceedings of the 2007 IEEE International Conference on Robotics and Automation. Piscataway: IEEE, 2017: 285-292.
[17] CHEN D, VARSHNEY P K. A survey of void handling techniques or geographic routing in wireless network[J]. IEEE Communications Surveys and Tutorials, 2007, 9(1): 50-67.
