基于高低階特征交叉的校園課程推薦系統研究
2019-11-16 05:36:23冉昊璽
科教導刊·電子版 2019年27期
冉昊璽
摘 要 推薦系統是利用用戶的相關特征進行的相關物品推薦,大多應用于商業,展現了不凡的效果。針對當前高 校存在的課程種類繁多、學生選課困難、教學資源浪費等現象,本文遷移商業中的類似人群拓展思想,提出校園課程 推薦系統,并充分利用因子分解機和多層感知機,實現了低階和高階的特征交叉,達到了更佳的推薦效果,從而改善 了教學資源利用率,提高了學生的選課興趣。
關鍵詞 推薦系統 神經網絡 因子分解機 在線選課
中圖分類號:G645 文獻標識碼:A
0引言
推薦系統原是電子商務網站通過用戶對象的相關信息,為其提供相應的商品信息和建議,并幫助用戶實現商品 購買的決策,其中的個性化主要通過用戶屬性和其興趣來體現。隨著推薦系統在商業中的巨大成功,推薦系統也不斷 受到數據挖掘界的重視和深入研究,已經形成了一套相對成熟的科學方法,并應用到了實踐中。
隨著校園各類型的課程不斷增加,學生選到并不適合自己的課程的可能性也隨之增高,并且學生因掌握了較少的 課程信息而無法在五花八門的課程中找到最佳的選擇。與此同時,學校在課程資源上也造成了相應的損失。由于學生 對于選課的“失誤”可能性較高,很多課程因此被埋沒或被過高的追捧。比如,一個課程僅僅因為學長單方面的推薦而使 得某一課程有大量的學生選擇而使得課程爆滿,許多真正適合這一課程的學生無法選到,而另一些并不適合這一課程 的學生進入了這一課程而從此陷入了痛苦中。這一系列的選課不均衡現象反映了學生在時間和精力的浪費,同時,學 校寶貴的教學資源也因此大量浪費。這一切原因,可以歸結為學生無處獲取很好地選課指導。
針對這一問題,我借鑒了電子商務中的推薦系統,并提出了課程推薦系統(Curriculum Recommendation System, 此后簡寫為 CRS)將此類問題近似看做一個 click-through-rate 問題,具體來說則是針對是否選擇某一課程的二分類 問題,借鑒了 2018 年的騰訊算法大賽,將其中涉及到的問題–類似人群拓展(lookalike)進行了遷移。類似人群拓展 的目標是利用廣告主已有的消費者,找出和已有消費者相似的潛在消費者,以此拓展業務。本文中提出的 CRS 系統也 是利用了這一想法,通過某一課程已參與的學生群體作為種子群體(廣告行業亦稱作種子包),找出和這類群體類似的 學生群體(廣告行業亦稱作擴展人群),并在他們的個人學生教務管理主頁進行課程的推薦。
在模型設計時,考慮到這一問題設計到的特征的多樣性和復雜性,需要大規模的特征交叉,于是本文參考了適合 于大規模數據的梯度提升樹方法,以及在高階特征交叉問題中效果顯著的神經網絡 和在低階問題 中可以較快的實現大量數據的特征交叉的因子分解機。另外,對于大量的特征,本文在特征選擇上則是借鑒了 LightGBM 算法的重要性分析,對重要性指標較高的特征進行了保留。由于數據集存在大量非實數特征,本文采用了 獨熱和 embedding 的聯合方法,實現了由非實數值向實數值的轉化以及數據分布的降維。
1特征工程
1.1特征構造
在特征構造這個階段主要是進行對長度特征的構造。其中涉及到的特征主要為向量特征,如學生信息的歷史課程 特征和教師信息中的歷史教學課程特征。長度特征即為將特征中的向量的長度進行統計。
另外,對于離散化特征,則是通過神經網絡中的 embedding 層進行模型可以進行計算的形式。
1.2特征提取
在特征提取階段,本文主要是針對業務邏輯和經驗,對一些特殊的特征進行了提取。對于選課信息中的選課時間, 可從中提取兩個特征。先進行時間范圍的劃分。出于實際考慮,選課階段分為預選、正選、不推選三個階段,我們將 選課階段提取出來構造為一個離散型特征。此外,在每個階段的時間也有所不同,在每個階段選課時間的分布會隨著 天數的增加而不斷下降,形成一個類長尾分布,并且選課時間只是在一天的一個固定時間段進行(例如 10:00am - 6: 00pm),因此我們可以將某一天的某一個小時內的時間作為一個數值,在這個時段內的時間均為這個數值,從而形成 一個數值型特征。這樣我們便得到了選課時段和選課具體時間兩個特征。而對于選課年份,我們也同樣需要進行保留。
對于學生信息中的 id,同樣可以進行特征的提取。由于學號的特殊性,我們可以從中獲得學生的年級,所在學院 及專業,編號等信息,其思想較為簡單,這里不再贅述。需注意一點,這些提取特征均為離散型特征。
1.3特征選擇
當前的特征相對較少,但是當特征的不斷挖掘,亦或是實際計算環境對于數據量的限制較高時,大量的特征由于 計算時間過長,并不能較好的達到工程上對于的需求,因此,在這里需要對特征進行篩選,亦即特征選擇。
本文主要利用的是 GDBT 算法實現的特征重要性分析,較為便利的工具是開源的 LightLGB 。它利用 生成的梯度提升樹,通過分析不同特征在分類時的利用次數實現了重要性的分析。在計算環境受限的情況下,可以選 擇保留前 20 個特征作為最終數據進行訓練。
2 CRS系統
2.1高低階特征交叉
在這里,高低階特征交叉分為兩個的部分:高階部分和低階部分。低階部分可視為因子分解機的改進,高階部分 則是使用了神經網絡和 embedding 的方法。
2.1.1低階部分
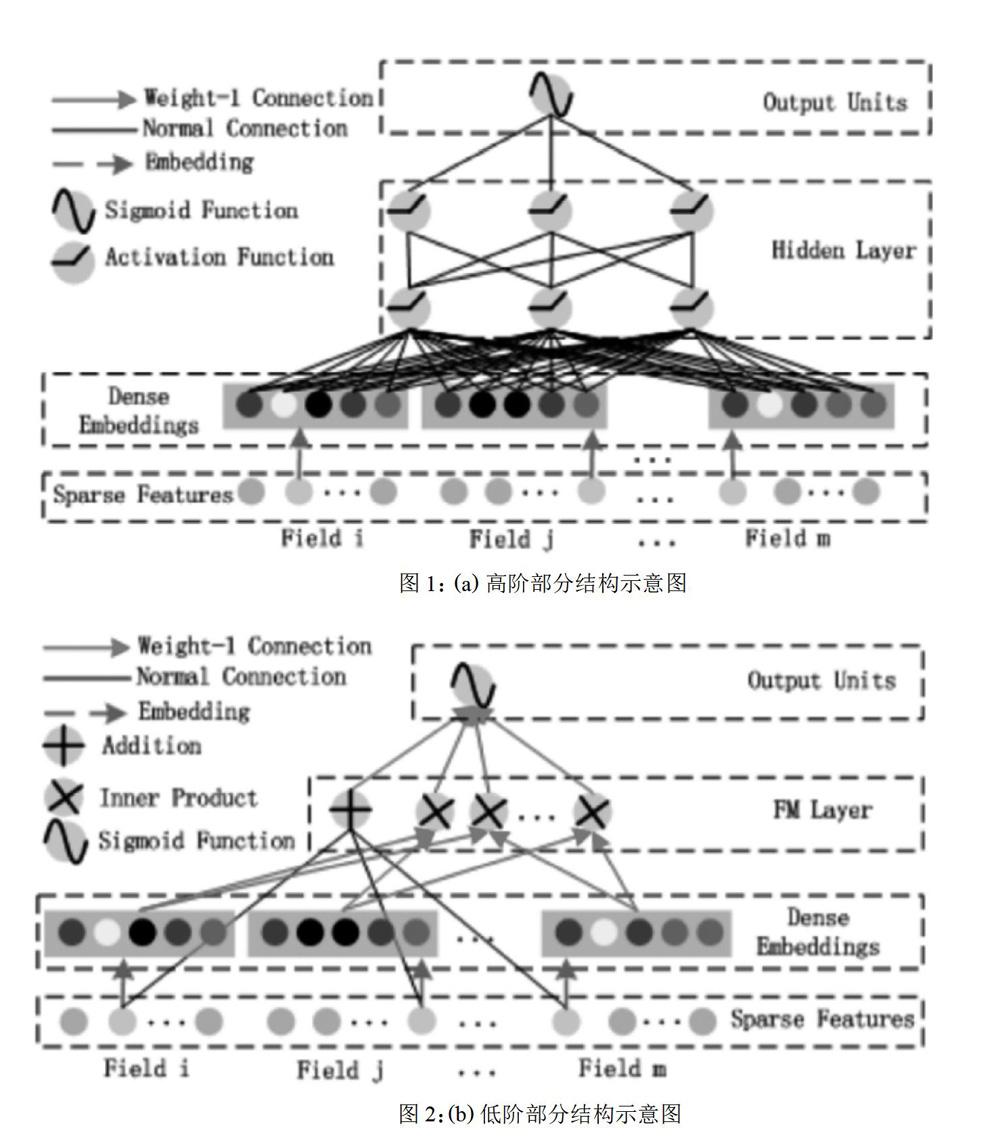
如圖 1 所述的是模型設計所用到的因子分解機的優化形態。其構造主要分為一階部分和二階部分,一階部分可以 看做為單特征在一階特征空間的映射,二階部分則是針對問題進行的對原因子分解機進行的優化,它將特征向量先通 過 Deep 部分訓練好的 embedding 層,從而實現降維,再進行特征的兩兩交叉。這樣,便實現了一個自動化的特征工程。 然而,FM 算法暴露的缺點是其缺乏靈活性,即其只是進行了兩個特征的結合,對于多特征的情況卻有所缺失。Deep 部分則通過其對于高階特征交叉的學習,很好的彌補了這一點。
其中 w ∈ Rd, Vi ∈ Rk。相加單元(〈w, x〉)代表一階特征的重要性,而其后的內積單元表示二階特征交叉的重要性。 如圖 2 所述的為一個含有 embeddiing 層的前饋神經網絡。由于在 CTR 預測問題中,特征存在很多類別型特征從 而變得高度稀疏,所以為了將這些特征變成純粹的、連續的數值型特征,我們引入了 embedding 層,從而使得 CTR 問題得以在神經網絡中進行學習。
2.2 CRS 系統
在模型設計之初,考慮到當下極為火熱且實際工程中效果極佳的神經網絡,便嘗試將其加入模型中,然而,神經網 絡在處理復雜問題的優秀能力使其輕易達到了高階的特征交叉,卻自然的忽視了最為基礎的低階特征交叉。于是,參 考因子分解機的原理,并結合這一行業的特質,將獨熱處理后的多特征看做一個域,并實現域與特征的交叉,從而達 到更具說服力的特征輸入。
此外,對于模型輸入,大部分特征為非實數型特征,而神經網絡和因子分解機輸入的數據均為實數型數據,因此, 我們需要對類別特征進行獨熱處理(one-hot)。但是,與此同時,我們需要用 embedding 的方法來解決獨熱處理帶來 的數據分布維度過高問題。這樣,我們就將模型輸入分為三類:單值連續型、單值離散型、多值離散型,其中,單值連 續型即為可以直接進行特征交叉的實數型特征,而單值離散型和多值離散型均需通過 embedding 層來實現實數向量的這一模型的輸出為一個實數值,即為某一學生選擇某一課程的相關性,我們將這一學生對多個候選課程進行相關 性計算,并對每個結果進行排列,取最高的幾個值對應的課程進行推薦(例如 top10)。這樣,便實現了模型從設計到 訓練再到具體環境的流程。
CRS系統,不僅可以輔助學生進行課程的決策,更可對其進行功能的延展。例如,課程推薦系統可以通過預測學 生的選課情況,從而了解學生對于課程的偏好,從側面實現了對某一課程的評估,使得課程評估變得更具客觀性。這 樣一來,CRS 系統可以幫助校方進行課程信息的調整及開設。
此外,CRS 系統經過模型與數據集的改動,可以解決回歸問題,實現學生對于某一課程的選課情況的預測。這樣 可以更好地幫助校方調整課容量,從而摒棄了以往僅僅通過主觀、感性的判斷而人為設定的課容量,對于新課的開設 也是具有很好的指導意義。例如,對某個新開設的課程,其在多個校區均有開設,通過 CRS 系統,便可預測不同校區 的選課情況,并對這一課程的教室類型和容量進行調整。這樣一來,校方減少了教學資源的浪費,實現了精度化的課 程開設。從這些應用來看,課程推薦系統同樣對于學校有著巨大的指導作用。
3實驗驗證
3.1實驗環境
本文使用Python語言和TensorFlow深度學習工具實現,云端服務器配置有16核CPU,64GB內存和4個NVIDIA RTX2080Ti。
3.2學生-課程的相關性預測和排序
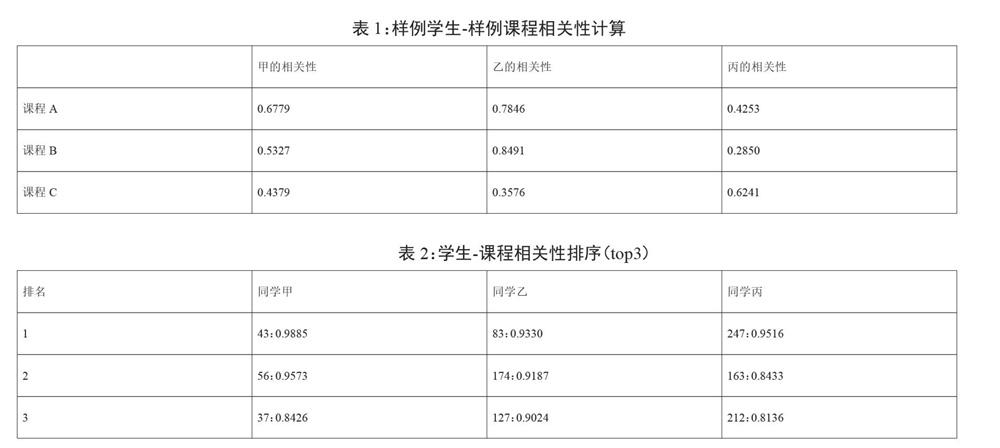
為了驗證模型設計和實驗方案的可行性,利用現有的已經清洗并脫敏的學生屬性、選課屬性數據集進行了學生-課程相關性的計算實驗。表1中的相關性為樣例學生和樣例課程的相關性計算,表2為學生-課程相關性的前三相關性,即推薦候選課程排名前三的名單。由表2可以簡單得出,通過CRS系統的計算,可以將學生的已有信息轉化為一種更為普遍的對課程的偏好,如同學丙的top3課程均與文學和歷史相關,而同學丙便是歷史學院的學生;由表1同樣可以得到一些和常識相對應的信息,如同學甲、乙均位于校區0,而他們對于開設在校區1的課程相關性較強(如課程A和課程B)。當然,通過CRS一樣可以挖掘出一些有趣的事件,如生源地為河北的同學大多有對計算機類課程的偏好。以上實驗結果因此可以簡單驗證CRS系統的可行性。
4總結
本作提出了 CRS 系統,其不僅可以充分的利用大學現有的校園數據資源,實現對學生個性化的課程推薦,甚至可 以利用其很好的延展性,應用到校方的課程開設中并為其做出指導作用,最終實現了對學生進行課程推薦和輔助學校 進行課程開設決策的最終目的。
然而,在實際應用中,由于每個課程,計算量相當龐大,這在實際情況下是不可行的。因此我提出了以下方案:率 先進行課程的聚類,通過 CRS 系統對課程組別的推薦來減少這一計算量;另外,我們也可設定一個學生與課程相關性 指標的閾值,將高于這一閾值的課程放入這一學生的候選課程名單,減少課程數從而降低計算的復雜度。
在校園的課程數據的應用中,仍有許多的特征亟待挖掘,由于推薦系統的復雜性,為了簡化挖掘過程,本文在實 現時,對大量的學生特征進行了適當的取舍(如選擇某一課程的學生的信息,以及由于選修和必修課程出現的一些差 異情況),使得 CRS 系統的適用性更強,適用范圍更廣。
參考文獻
[1] Junxuan Chen&Baigui Sun&Hao Li&Hongtao Lu&Xian-Sheng Hua. Deep ctr prediction in display advertising[J].In Proceedings of the 24th ACM international conference on Multimedia,2016:811–820.
[2] Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system[J].In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining,2016:785–794.
[3] Yuchin Juan&Yong Zhuang&Wei-Sheng Chin&Chih-Jen Lin. Field-aware factorization machines for ctr pre- diction[J].In Proceedings of the 10th ACM Conference on Recommender Systems,2016:43–50.
[4] Guolin Ke&Qi Meng&Thomas Finley&Taifeng Wang&Wei Chen&Weidong Ma&Qiwei Ye&Tie-Yan Liu. Lightgbm:A highly efficient gradient boosting decision tree[J].In Advances in Neural Information Processing Systems,2017:3146–3154.
[5] Steffen Rendle.Factorization machines[J].In 2010 IEEE International Conference on Data Mining,2010:995–1000.
[6] Ruoxi Wang&Bin Fu&Gang Fu&Mingliang Wang.Deep & cross network for ad click predictions[J].In Proceedings of the ADKDD17,2017:12.
[7] Jun Xiao&Hao Ye&Xiangnan He&Hanwang Zhang&Fei Wu&Tat-Seng Chua. Attentional factorization machines: Learning the weight of feature interactions via attention networks[J].arXiv preprint arXiv:1708.04617,2017.
附錄
A 數據集相關細節
數據集的來源為四川大學學生部分數據中的學生基本信息和選課信息。我們將數據分為五個部分:學生基本信息 數據、選課信息、教師基本信息、教室信息。另外,特征存在三類:數值型(numeric),離散型(discrete),向量型 (vector),長度型(length),時間型(time)。其中,數值型為浮點數;離散型為類別 id,可進行獨熱處理;向量型為單個特征中存在多個離散值的數組,且數組長度不定;長度型為特殊的數值型,其為從向量型特征中數組長度的取值; 時間型為特殊的數值型,由于在這個背景中涉及到時序問題,將數據中涉及的時間特征按從小到大進行獨熱處理,并 按數值型特征對待。
對于訓練集和測試集中的標簽表示某個學生是否選擇某個課程,分為兩個值:0、1。0 表示選課,1 表示不選課。
下面將對數據集中的主要特征進行列舉:
(1)學生基本信息:學生 id(discrete),年齡 (numeric),年級 (numeric),性別 (discrete),生源地 (discrete),歷史 課程 (vector)。
(2)選課信息:選課 id(discrete),課程名,開設學院 id(disc? rete),課程號 id(discrete),課序號 id(discrete), 選課時間,開設學院 id,課程類型 id,教師 id,校區 id,周次,教學樓 id,教室 id,課容量。
(3)教師基本信息:教師 id,教師所屬學院 id,性別,年齡,歷史教學課程。
(4)教室信息:教室 id,所在教學樓 id,所在樓層,教室類型,教室大小,教室新舊情況注意:①在學生 id 中需保留原始學生號用于之后的特征工程。②選課信息為選課信息和課程信息的合并,為便于總結,在這里進行了簡化。③教師基本信息和學生基本信息中,歷史課程均為課程 id 的集合。④教室信息中,教室新舊情況可視為簡化特征,例如將最近的裝修年份作為新舊程度劃分的標準;教室大小可按照教室面積的標準劃分;教室類型為人為界定特征,比如未有任何設備的教室為最低級別,具有多媒體、師生互動設 備等條件則為不同的類型。
下面將對訓練集和測試集的基本內容進行分析:
訓練集和測試集均包括選課 id、學生 id 以及是否選課這三個特征,其中訓練集與測試集的比例按照 20:1 劃分。另 外,由于這個分類問題中正負樣本數量的明顯差距,我們采用正負樣本 1:20 來進行數據的采樣。對于空缺值及異常 值,均以-1 填充。
B 模型訓練細節
以下列舉了一些主要參數及對應的默認值:
feature_dim_dict – 特征字典,以字典的格式保存特征的域,例如 {sparse:{field_1:4,field_2:3, field_3:2},dense:{field_4,field_5}}
embedding_size=8 – embedding 層的輸出向量長度 dnn_hidden_units=(128, 128) – deep 部分的網絡結構 l2_reg_linear=0.00001 – 應用在 FM 部分的 L2 正則化 l2_reg_embedding=0.00001 – 應用在 embedding 層的 L2 正則化 l2_reg_dnn=0 – 應用在神經網絡隱層的 L2 正則化
task=binary – 訓練任務,這里默認的是二分類問題
