面向視覺檢測的深度學習圖像分類網絡及在零部件質量檢測中應用
2019-11-16 11:04:40劉桂雄何彬媛吳俊芳林鎮秋
中國測試 2019年7期
關鍵詞:深度學習
劉桂雄 何彬媛 吳俊芳 林鎮秋


摘要:基于深度學習圖像分類是視覺檢測應用的基本任務。該文系統總結基于模型深度化圖像分類網絡、基于模型輕量化圖像分類網絡及其他優化網絡主要思想、網絡結構、實現技術、技術指標、應用場景,指出網絡模型深度化、輕量化分別有助于提高圖像分類準確性、實時性。最后,面向零部件質量檢測需求,應根據其類型多少、結構復雜程度、特征異同等特點,結合實時性要求,選擇合適的圖像分類網絡構建零部件質量智能檢測系統。
關鍵詞:圖像分類;深度學習;視覺檢測;零部件質量檢測
中圖分類號:TP301.6 文獻標志碼:A 文章編號:1674-5124(2019)07-0001-10
收稿日期:2019-05-04;收到修改稿日期:2019-06-02
基金項目:廣州市產學研重大項目(201802030006);廣東省現代幾何與力學計量技術重點實驗室開放課題(SCMKF201801)
作者簡介:劉桂雄(1968-),男,廣東揭陽市人,教授,博導,主要從事先進傳感與儀器研究。
0 引言
圖像分類是根據圖像所反映的不同特征信息,確定特定視覺目標類的概率來標記輸入圖像。它是目標檢測、語義分割等的基礎模型,是機器視覺檢測應用基本任務,是專家學者研究熱點之一[1]。圖像分類根據顏色、紋理、形狀、空間關系等特征將區分不同類別圖像,主要流程包括圖像預處理、圖像特征描述與提取[2]分類器設計與訓練[3]、分類結果評價等。通常在圖像特征描述與提取前,會進行圖像濾波[4]、尺寸歸一化[5]等預處理,圖像濾波目的在于增強圖像中目標與背景對比度,尺寸歸一化有助于圖像批量特征提取。不同類別的圖像特征具有多樣性、復雜性,同一類別的圖像特征則存在平移、旋轉、尺度變換、顏色空間變換等情況。因此,有效的圖像特征描述與提取方法應具備類內圖像特征不變性描述能力、類間圖像特征分辨與提取能力,是圖像分類任務的難點。分類器根據所提取圖像特征學習的分類函數或構造的分類模型,傳統分類器包括邏輯回歸[6]、K鄰近[7]與決策樹[8]等。經典圖像分類方法按照上述流程分步進行,最常用方法為基于視覺詞袋(bags of visual words,BoW)方法[9],將圖像塊仿射不變描述符的矢量量化直方圖[10]完成圖像特征提取,再輸入到樸素貝葉斯分類器(naive bayesclassifier,NBC)[11]或支持向量機(support vectormachine,SVM)[12]完成分類。經典圖像分類算法所采用特征均為圖像底層視覺特征,對具體圖像及特定的分類方式針對性不足,對于類別間差異細微、圖像干擾嚴重等問題,其分類精度將大大降低,在復雜場景中經典圖像分類方法難以達到好效果。
隨著視覺檢測技術發展與計算能力巨大提升,深度網絡已在圖像分類、視覺檢測任務上應用與發展。近年來,各種深度學習圖像分類方法已經被廣泛探討[13-18]。美國印第安納大學2007年詳細介紹幾種主要先進分類方法和提高分類精度的技術,討論影響分類性能一些重要問題,認為神經網絡等非參數分類器成為多元數據分類的重要方法[13]。南京大學2017年從強監督、弱監督兩個角度對比不同深度學習算法,討論深度學習作為圖像分類未來研究方向所面對挑戰[14]。美國賓夕法尼亞州立大學2018年研究視覺分析與深度學習的圖像分類方法,總結圖像分類網絡經典架構并展望基于深度學習的圖像分類方法應用前景[17]。目前基于深度學習圖像分類框架的圖像識別算法已廣泛應用于醫療CT圖像診斷[19]、汽車輔助駕駛[20-21]、制造產品質量檢測[22-24]等。在復雜多變的工業圖像檢測環境下,不同圖像分類場景具有不同檢測需求,如制造零部件質量檢測有類內差小[25]、圖像對比度低[26]等特點。經典圖像分類方法難以滿足復雜的工業檢測應用要求,深度學習圖像分類方法具備特征不變形描述能力、高維特征提取能力,能較好地解決上述問題。
本文系統總結面向視覺檢測的深度學習圖像分類網絡,對比各種基于深度學習的圖像分類網絡在ILSVRC競賽ImageNet2012[27]數據集中的分類性能,指出不同分類方法適用的視覺檢測任務場景,并結合基于深度學習零部件質量檢測技術加以分析與應用。
1 基于視覺檢測的深度學習圖像分類網絡
基于視覺檢測的深度學習圖像分類網絡按模型結構可分為模型深度化圖像分類網絡[28]、模型輕量化圖像分類網絡[29],兩者區別主要在于使用更深層卷積層以提取深層圖像特征還是通過減小網絡參數量、存儲空間滿足工業應用要求[30]。
1.1 圖像分類網絡性能評價指標
基于深度學習圖像分類方法是通過卷積神經網絡(convolutional neural networks,CNN)基本模型實現準確分類,由輸入層、卷積層、池化層、全連接層、輸出層構成[31]。通過多層卷積運算對圖像逐層提取特征,獲取更高階的統計數據再通過分類器實現圖像多分類。主要通過圖像分類準確率與模型復雜度評價深度學習圖像分類方法。
在圖像分類任務中,通常采用Top-1錯誤率、Top-5錯誤率對分類準確率進行評價[31]。Top-1錯誤率是用預測概率最大那一類作為分類結果,預測結果中概率最大的那個類錯誤,則認為分類錯誤,即Top-1錯誤率代表預測概率最大的那一類不是正確類別的比率;同理,Top-5錯誤率是用預測概率最大的前5名作為分類結果,前5名中不出現正確類即為分類錯誤,即Top-5錯誤率代表預測概率最大的5個類別中不包含正確類別的比率。
模型復雜度主要由時間復雜度、空間復雜度組成。時間復雜度決定模型的訓練、預測時間,如果復雜度過高,則會導致模型訓練和預測耗費大量時間,既無法快速地驗證模型構建方案、改善模型,也難以實現實時預測。空間復雜度主要由CNN結構決定,CNN規模越大,模型參數越多,訓練模型所需的數據量就越大,在提高圖像特征提取能力的同時,也會占用更多運算空間且易導致數據過擬合問題[32]。隨著硬件水平以及計算能力的快速發展,已經開始研究模型復雜度對訓練和預測的影響問題,如應用到一些對實時性要求高的項目中,需要研究更輕量化的網絡。時間復雜度可以通過浮點運算次數(floating-point operations,FLOPS)計算,即:
空間復雜度由網絡各層卷積核參數、輸出特征圖參數共同決定,即:式中:M——每個卷積核輸出特征圖尺寸;
K——每個卷積核尺寸;
Cl——第l個卷積層卷積核個數;
Cl-1——第l-1個卷積層卷積核個數;
D——網絡層數。
1.2 基于模型深度化的圖像分類網絡
基于網絡深度化的圖像分類模型是通過增加網絡深度提高圖像特征提取與表征能力,融合顏色、形狀等低層特征和語義特征等高層特征,在高特征維度中將不同類別圖像分離開來,提升圖像分類效果。
1)AlexNet
Alex Krizhevsky等[33]2012年設計出深層卷積神經網絡AlexNet,AlexNet是具有歷史意義的網絡結構,在其被提出之后,更多更深的神經網絡被提出,并成為圖像分類方法的基礎網絡模型。圖1為AlexNet模型網絡結構圖,整體結構分為上下兩個部分的網絡,分別對應兩個GPU(特定的網絡層需要兩塊GPU進行交互以提高運算效率)。以一個GPU為例,網絡總共的層數為8層,包括5層卷積和3層全連接層,將224×224×3圖像輸入到第一層卷積層,每一層卷積層的輸出作為下一層卷積層的輸入,經過5層卷積層后輸入到全連接層,每一層全連接層神經元個數為4096,最終由softmax分類器輸出圖像在1000類別預測中的分類概率。
AlexNet通過多層網絡實現深層次圖像特征提取以完成分類任務,較傳統方法分類準確率有很大提高,且通用性強。AlexNet每層使用線性整流函數(rectified linear unit,ReLU)作為激活函數,因其梯度下降速度更快,使得訓練模型所需的迭代次數大大降低,同時使用隨機失活(dropout)操作,在一定程度上避免因訓練產生的過擬合現象,計算量大大降低。在ILSVRC2012競賽中AlexNet奪得冠軍,其準確率遠超第二名(Top-5錯誤率為15.4%,第二名為26.2%),但受限于當時計算性能,AlexNet在網絡深度、特征提取效果上未能達到最理想水平。
2)ZFNet
紐約大學Matthew Zeiler等[34]2013年在AlexNet基礎上進行微小改進從而設計出ZFNet網絡,提出圖像反卷積方法實現卷積特征可視化,證明淺層網絡學習到的是圖像邊緣、顏色和紋理特征,而深層網絡學習到的是圖像抽象特征,指出網絡有效原因與性能提升方法。圖2為ZFNet網絡結構圖,ZFNet基本保留AlexNet骨干結構,由于AlexNet第一層卷積核尺寸、步長過大,提取的特征混雜大量高頻與低頻信息而缺少中頻信息,故ZFNet將第1層卷積核的大小由11×11調整為7×7,步長(stride)從4改為2。
ZFNet設計反卷積網絡實現卷積特征可視化,發現第一層的卷積核對特征提取影響大,提出第一層卷積核進行規范化方法,如果RMS(root meansquare)超過0.1,就把卷積核的均方根固定為0.1。同時,ZFNet論證更深網絡模型在圖像平移、旋轉等條件下分類魯棒性更好,層次越高的特征圖,其特征不變性越強。ZFNet是ILSVRC2013分類任務冠軍,Top-5錯誤率為14.7%。ZFNet以實踐方法展示網絡不同層級的特征提取結果與性能,但沒有從理論角度解釋網絡原理與設計規則。
3)VGGNet
針對AlexNet的大卷積核問題,牛津大學計算機視覺組和Google DeepMind項目研究員共同探索卷積神經網絡深度與其性能之間的關系[35],提出用若干較小尺寸卷積核代替大尺寸卷積核,能夠有效提高特征提取能力,從而提升圖像分類準確性。Karen Simonyan等[36]2014年提出VGG網絡模型,其將卷積神經網絡深度推廣至16~19層,以VGG16為例,圖3為VGG16網絡結構圖,圖像輸入后經過第一段卷積網絡,包括兩個卷積層與一個最大池化層后輸出,再進入與第一段結構相同的第二段卷積網絡,之后通過反復堆疊的3×3小型卷積核和2x2最大池化層,最后通過全連接層輸出到softmax分類器。
VGGNet在AlexNet基礎上采用多個小卷積核代替大卷積核,增強圖像特征非線性表達能力、減少模型參數。如一個7×7卷積核可看作是3層3x3卷積核的疊加,但一個7×7卷積核有49個模型參數,只能提供一層特征圖像、一種感受野,而3層3x3卷積核只有27個模型參數,提供3層不同尺度下的特征圖像。VGGNet是ILSVRC2014競賽的亞軍,在Top-5中取得6.8%的錯誤率,VGGNet表明增加網絡層數有利于提高圖像分類的準確度,但過多層數會產生網絡退化問題[37],影響檢測結果,最終VGGNet的層數確定在16層和19層兩個版本。同時由于網絡層數過多而造成參數過多,會使得模型在不夠復雜的數據上傾向于過擬合。
4)GoogLeNet
AlexNet與VGGNet均從增加網絡深度來提取不同尺度下圖像特征進而提高圖像分類性能,而Szegedy C等[38]2015年提出的GoogLeNet模型除考慮深度問題,還采用模塊化結構(Inception結構)方便模型的增添與修改。GoogLeNet將全連接甚至是卷積中的局部連接,全部替換為稀疏連接以達到減少參數的目的。圖4為Inception v1結構結構圖,該模塊共有4個分支,第一個分支對輸入進行1×1卷積,它可以降低維度、減少計算瓶頸、跨通道組織信息,從而提高網絡的表達能力;第二個分支先使用1×1卷積,然后連接3×3卷積,相當于進行了兩次特征變換;第三個分支先是1×1的卷積,然后連接5×5卷積;最后一個分支則是3×3最大池化后直接使用1×1卷積。
GoogLeNet最大特點是引入Inception結構,優勢是控制計算量和參數量的同時,也具有非常好的分類性能。Inception結構中間層接另兩條分支來利用中間層的特征增加梯度回傳,使得其參數量僅為Alexnet的1/12,模型計算量大大減小;其次網絡最后采用平均池化(average pooling)來代替全連接層將準確率提高0.6%,圖像分類精度上升到一個新的臺階。Inception模塊提取3種不同尺度特征,既有較為宏觀的特征又有較為微觀的特征,增加特征多樣性,Top-5錯誤率為6.67%。 GoogLeNet網絡雖然在減少參數量上做出一定貢獻,但大參數量仍限制其在工業上應用。
5)ResNet
為了解決網絡層數過多而造成梯度彌散或梯度爆炸問題,Kaiming He等[39,2016年提出ResNet(residual neural network)網絡,通過殘差塊模型解決“退化”問題,該模型是ILSVRC 2015冠軍網絡。ResNet提出的殘差塊(residual block)結構主要思想是在網絡中增加直連通道,即高速路神經網絡(highwaynetwork)思想。圖5為ResNet網絡結構圖,圖像輸人后,維度匹配的跳躍連接(short connection)為實線,反之為虛線,維度不匹配時,可選擇兩種同等映射方式:直接通過補零來增加維度、乘以W矩陣投影到新的空間,使得理論上網絡一直處于最優狀態,性能不會隨著深度增加而降低。
當模型變復雜時,會出現準確率達到飽和后迅速下降產生更高訓練誤差、隨機梯度下降(stochasticgradient descent,SGD)優化變得更加困難等現象。Residual結構用于解決上述問題,使得網絡模型深度在很大范圍內不受限制(目前可達到1000層以上),ResNetTop-5錯誤率為4.49%,同時參數量比VGGNet低,效果非常突出。ResNet是目前深度化模型代表,但是深度化使得網絡龐大,所占存儲空間更多。
綜合以上分析,基于模型深度化圖像分類網絡采用增加網絡層數提高圖像特征提取效果,引入殘差塊模型解決層數過多帶來的“退化”問題,提取并融合深層網絡圖像抽象特征與淺層網絡圖像邊緣、顏色和紋理特征,有效提高圖像分類高準確率,但網絡深度化模型復雜、占用空間大,適合用于圖像特征復雜、圖像分類實時性要求不高的場合。
1.3 基于模型輕量化的圖像分類網絡
與圖像分類網絡深度化方法不同,基于模型輕量化的圖像分類網絡主要是解決模型存儲問題和模型預測速度問題,使得圖像分類網絡兼顧分類準確率的同時提高效率,實現分類網絡移動端應用。圖像分類輕量化方法有對參數和激活函數進行量化以減少占用空間、設計更高效的特征提取方式和網絡結構等。
1)ShuffleNet
ShuffleNet網絡是由Face++團隊Zhang X等2017年提出的輕量化網絡結構,其主要思路是使用點態組卷積層(group convolution,Gconv)與通道混合(channel shuffle)來減少模型使用的參數量[40]。圖6為ShuffleNet網絡結構圖,在ResNet基礎上將1×1卷積核換成1×1Gconv,其次在第一個1×1Gconv之后增加1個通道混合以實現分組卷積信息交換,最后在旁路增加平均池化層,以減小特征圖分辨率帶來的信息損失。
ShuffleNet采用ResNet的思想,在提取圖像深層次特征同時通過減少模型參數量實現卷積層信息交換。在ImageNet 2012數據集上時間復雜度為38 MFLOPs,但通道混合在工程實現時會占用大量內存及出現指針跳轉而導致耗時。
2)DenseNet
Gao H等[41]2017年通過脫離加深網絡層數(ResNet)和加寬網絡結構(Inception)來提升網絡性能的定式思維,從圖像特征角度提出DenseNet網絡。DenseNet網絡通過特征重用和旁路設置,減少網絡參數量及在一定程度上緩解梯度消失問題產生。圖7為DenseNet網絡構圖,第i層輸入不僅與i-1層輸出相關,還有之前所有層輸出有關,對于一個L層網絡,DenseNet共包含L×(L+1)12個連接,相比ResNet,這是一種密集連接,而且DenseNet是直接連接來自不同層特征圖,能夠實現特征重用與融合。
DenseNet作為另一種有較深層數的卷積神經網絡,具有如下特點:相比ResNet參數數量更少;通過旁路加強特征重用與新特征提取;網絡更易于訓練,并有一定正則效果;緩解梯度消失與模型退化問題。250層DenseNet參數大小僅為15.3MB,在ImageNet 2012數據集中Top-5錯誤率為529%。
3)MobileNet v2
Sandler M等[42]2018年研究更高效的網絡結構MobileNet v2,以深度可分離的卷積作為高效的構建塊,提出倒置殘差結構(inverted residual structure,IRS),提高梯度在乘數層上傳播能力、內存效率。圖8為MobileNet v2倒置殘差結構圖,方塊的高度代表通道數,中間的深度卷積較寬,先使1×1卷積層升維,再使用3X3卷積層ReLU對特征濾波,最后用1×1卷積層+ReLU對特征再降維,呈現倒立狀態,理論上保持所有必要信息不丟失,獲得更優精確度。
MobileNet v2網絡在參數為MobileNet v170%的情況下減少兩倍運算數量,在Google Pixel手機上測試結果比MobileNet v1快30%~40%。該網絡能保持類似精度條件下顯著減少模型參數和計算量,使得實時性與精度得到較好平衡。
基于模型輕量化的圖像分類網絡突破深層化網絡模型復雜度高、網絡退化的問題,通過設計更高效的卷積方式以減少網絡參數、自動化神經架構搜索網絡優化計算效率而不損失網絡性能,使得圖像分類網絡實現工業檢測或移動端的實時應用。
1.4 其他分類網絡
除基于模型深度化、輕量化的圖像分類網絡外,一些圖像分類網絡通過多模型融合進一步降低模型復雜度、提高模型分類準確性。
1)Inception v2、v4
Szegedy C 2017年在Inception v1基礎上研究,指出利用中間層特征增加梯度回傳可以提取多層圖像特征,但沒有真正解決大參數量導致訓練速度問題。Szegedy C等[43],在 Inception v2中提出BN(batch normalization)在用于神經網絡某層時會對每一個小批量數據內部進行標準化處理,使輸出規范化到N(0,1)正態分布,減少內部神經元分布的改變,使得大型卷積網絡訓練速度加快很多倍,同時收斂后分類準確率也可以得到大幅提高,一定程度上可以不使用dropout降低收斂速度的方法,卻起到正則化作用,提高模型泛化性。Inception v4將Inception模塊結合殘差連接(residual connection),極大地加速訓練,同時極大提升性能[44]。
2)DPN
多模型融合通過結合多個網絡優勢提高圖像分類網絡性能。Chen Y等[45]2017年提出DPN(dualpath networks)融合ResNet與DenseNet的核心思想,利用分組操作使得DPN模型、計算量更小,訓練速度更快。DPN結合ResNet特征重用與DenseNet提取新特征優勢,通過雙路徑網絡共享公共特性,同時保持雙路徑體系結構探索新特性的靈活性,DPN在ImageNet數據集上達到與ResNet-101相當的分類效果基礎上,其模型尺寸、計算成本、內存消耗僅為后者的26%、25%、8%。
表1為各種圖像分類網絡性能對比表。可以看出,基于模型深度化、寬度化的圖像分類網絡分別在分類準確率、模型復雜度性能上表現優異,在工業應用中,應根據應用場景、任務要求選擇圖像分類網絡。
2 圖像分類網絡在零部件質量檢測中應用
零部件質量圖像檢測過程中,首先對獲取的零部件裝配圖像進行特征提取,其次根據零部件類型、缺陷等進行分類識別,最后根據零部件圖像分類結果完成質量評價。結合零部件質量檢測應用需求,發揮圖像分類網絡在特征提取、識別分類中的優勢,能夠有效完成零部件圖像特征提取、零部件質量檢測任務[46-47]。
2.1 零部件圖像特征提取
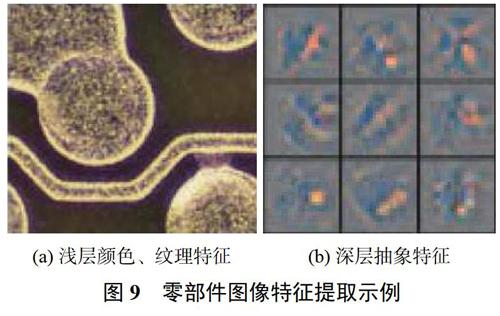
圖像特征提取是分類的基礎。在零部件質量檢測過程中,由于零部件種類各異,不同零部件圖像有不同特點,需根據具體檢測對象選擇合適的特征提取網絡,進而完成質量檢測任務。傳統零部件圖像特征提取采用提取圖像角點特征實現圖像分類。郭雪梅等[48]2017年提出面向標準件裝配質量的PI-SURF檢測區域劃分技術,利用SURF(speeded-uprobust features)提取特征描述感興趣點,實現機箱裝配標準件分類;黃堅等[49]2017年分析Harris、Shi-Tomasi、Fast方法角點特征提取機理與判定條件,提出多角點結合的機箱標準件圖像特征提取方法。圖9為零件圖像特征提取示例,傳統圖像特征提取方法能夠很好地學習零部件顏色、紋理等特征,在類型差異大、顏色對比鮮明的零部件特征提取效果較好,但對對比度低、類內差小零部件則需要提取其深層抽象特征。
深度學習圖像分類網絡能從淺層網絡提取圖像邊緣、顏色和紋理特征,從深層網絡提取圖像抽象特征。李宜汀等[50]2019年提出基于Faster R-CNN(faster regions with convolutional neural network)的缺陷檢測方法,提取零件圖像稀疏濾波與VGG-16雙重深度特征,實現零件缺陷分類。基于模型深度化的圖像分類網絡能夠滿足多層圖像特征提取要求,分類準確性高。
2.2 零部件質量檢測
根據圖像分類網絡提取的圖像特征,網絡完成零部件分類識別,結合零部件質量評價標準完成零部件質量檢測。Deng等[51]2018年提出PCB自動缺陷檢測系統,通過深度神經網絡完成缺陷分類,降低PCB缺陷檢測的誤檢率與漏檢率。筆者團隊前期研究機箱裝配質量智能檢測方法[52],目前正在研究基于深度學習圖像分類網絡在機箱裝配質量檢測應用,圖10為機箱裝配零部件質量檢測流程圖,待測機箱裝配圖像輸入后通過CNN網絡進行零部件特征提取,根據各層提取信息完成零部件分類,最后結合制定的裝配標準實現機箱裝配質量檢測。
零部件質量檢測首先提取圖像淺層及深層特征;其次利用分類器對零部件分類,分類有時需滿足檢測具體要求,如有無缺陷、遮擋等;最后根據質量評價標準對分類結果做出評判。零部件質量檢測屬于對象復雜、特征多的圖像識別檢測任務,且需要滿足一定實時性要求,應選擇網絡層數較深且模型復雜度較小的網絡以滿足其準確性和實時性。
3 結束語
圖像分類是機器視覺檢測應用的基本任務,根據網絡模型特點可分為深度化圖像分類網絡、輕量化圖像類網絡和其他改進網絡。基于深度學習圖像分類網絡廣泛應用于零部件質量檢測領域,總結如下:
1)基于模型深度化圖像分類網絡采用增加網絡層數,提取深層網絡圖像抽象特征與淺層網絡圖像邊緣、顏色和紋理特征,實現圖像分類高準確率。深度化圖像分類網絡特點是分類準確性高,適合用于圖像特征復雜的檢測任務。
2)基于模型輕量化圖像分類網絡突破深層化網絡瓶頸問題——網絡退化、模型復雜度高,通過設計更高效的卷積方式以減少網絡參數、自動化神經架構搜索網絡優化計算效率而不損失網絡性能,適用于實時工業檢測或移動端。
3)一些圖像分類網絡通過多模型融合方法,發揮不同網絡在不同層級圖像特征提取優勢,結合參數量小、計算速度快優點,進一步降低模型復雜度,提高模型分類準確性。
4)零部件質量檢測任務包括零部件圖像特征提取、零部件分類識別、結合質量評價標準的零部件質量評價。應用過程中應根據零部件類型復雜、特征多等特點,結合實時性要求,構建零部件質量智能檢測系統。
參考文獻
[1]FREEMAN W T,ADELSON E H.The design and use ofsteerable filters[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,1991(9):891-906.
[2]ZHANG D,LIU B,SUN C,et al.Learning the classifiercombination for image classification[J].Journal ofComputers,2011,6(8):1756-1763.
[3]BAY H,TUYT].,AARS T,VAN G L.Surf:Speeded uprobust features[C]//Springer.European Conference onComputer Vision,2006:404-417.
[4]ITTI L,KOCH C,NIEBUR E.A model of saliency-basedvisual attention for rapid scene analysis[J].IEEE Transactionson Pattern Analysis&Machine Intelligence,1998(11):1254-1259.
[5]GUO Y,LIU Y,OERLEMANS A,et al.Deep learning forvisual understanding:A review[J].Neurocomputing,2016,187(C):27-48.
[6]MENAR]]S.Applied logistic regression analysis[M].London:Sage Publications,2002:61-80.
[7]AMATO G,FALCHI F.OnkNN classification and localfeature based image similarity functions[C]//InternationalConference on Agents and Artificial Intelligence,2011:224-239.
[8]BREIMAN L.Random forests[J].Machine Learning,2001,45(1):5-32.
[9]BAY H,ESS A,TUYTELAARS T,et al.Speeded-up robustfeatures(SURF)[J].Computer Vision and ImageUnderstanding,2008,110(3):346-359.
[10]DENIZ O,BUENO G,SALHDO J,et al.Face recognitionusing histograms of oriented gradients[J].Pattern RecognitionLetters,2011,32(12):1598-1603.
[11]MARON M E,KUHNS J L.On relevance,probabilisticindexing and information retrieval[J].Journal of the ACM(JACM),1960,7(3):216-244.
[12]JOACHIMS T.Making large-scale SVM learning practical[R].Universitat Dortmund,1998.
[13]LU D,WENG Q.A survey of image classification methodsand techniques for improving classification performance[J].International Journal of Remote Sensing,2007,28(5):823-870.
[14]羅建豪,昊建鑫.基于深度卷積特征的細粒度圖像分類研究綜述[J].自動化學報,2017,43(8):1306-1318.
[15]RAWAT W,WANG Z.Deep convolutional neural networksfor image classification:A comprehensive review[J].NeuralComputation,2017,29(9):2352-2449.
[16]楊真真,匡楠,范露,等.基于卷積神經網絡的圖像分類算法綜述[J].信號處理,2018,34(12):1474-1489.
[17]YANG L P,MACEACHREN A,MITRA P,et al.Visually-enabled active deep learning for(geo)text and imageclassification:a review[J].ISPRS International Journal ofGeo-Information,2018,7(2):65-103.
[18]田萱,王亮,丁琪.基于深度學習的圖像語義分割方法綜述[J].軟件學報,2019(2):440-468.
[19]LIU X,HOU F,QIN H,et al.Multi-view multi-scale CNNsfor lung nodule type classification from CT images[J].PatternRecognition,2018,77:262-275.
[20]TONUTTI M,RUFFALDI E,CATTANEO A,et al.Robustand subject-independent driving manoeuver anticipationthrough Domain-Adversarial Recurrent Neural Networks[J].Robotics and Autonomous Systems,2019,115:162-173.
[21]李云鵬,侯凌燕,王超.基于YOLOv3的自動駕駛中運動目標檢測[J].計算機工程與設計,2019(4):1139-1144.
[22]馬曉云,朱丹,金晨,等.基于改進Faster R-CNN的子彈外觀缺陷檢測[J/OL].激光與光電子學進展:1-14[20]9-05-04].http://kns.cnki.net/kcms/detail/31.1690.TN.20190308.1705.004.html.
[23]常海濤,茍軍年,李曉梅.Faster R-CNN在工業CT圖像缺陷檢測中的應用[J].中國圖象圖形學報,2018,23(7):1061-1071.
[24]IWAHORI Y,TAKADA Y,SHINA T,et al.DefectClassification of Electronic Board Using Dense SIFT andCNN[J].Procedia Computer Science,2018,126:1673-1682.
[25]趙浩如,張永,劉國柱.基于RPN與B-CNN的細粒度圖像分類算法研究[J].計算機應用與軟件,2019,36(3):210-213,264.
[26]王陳光,王晉疆,趙顯庭.低對比度圖像特征點提取與匹配
[J].半導體光電,2017,38(6):888-892,897.
[27]RUSSAKOVSKY O,DENG J,SU H,et al.Imagenet largescale visual recognition challenge[J].International Journal ofComputer Vision,2015,115(3):211-252.
[28]REDMON J,DIVVALA S,GIRSHICK R,et al.You onlylook once:Unified,real-time object detection[C]//Proceedingsof the IEEE Conference on Computer Vision and PatternRecognition,2016:779-788.
[29]LAW H,DENG J.Cornernet:Detecting objects as pairedkeypoints[C]//Proceedings of the European Conference onComputer Vision(ECCV),2018:734-750.
[30]CHOLLET F.Xception:Deep learning with depthwiseseparable convolutions[C]//Proceedings of the IEEEconference on computer vision and pattern recognition,2017:1251-1258.
[31]JIA Y,SHELHAMER E,DONAHUE J,et al.Caffe:Convolutional architecture for fast feature embedding[C]//Proceedings of the 22nd ACM International Conference onMultimedia,2014:675-678.
[32]HE K,SUN J.Convolutional neural networks at constrainedtime cost[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition,2015:5353-5360.
[33]KRIZHEVSKY A,SUTSKEVER I,HINTON G E.Imagenetclassification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems,2012:1097-1105.
[34]ZEILER M D,FERGUS R.Visualizing and understandingconvolutional networks[C]//European Conference on ComputerVision,2013:818-833.
[35]LIN T Y,MAR S.Visualizing and understanding deep texturerepresentations[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition,2016:2791-2799.
[36]SIMONYAN K,ZISSERMAN A.Very deep convolutionalnetworks for large-scale image recognition[C]// 2015International Conference on Learning Representations,2015:1-14.
[37]BENGIO Y,SIMARD P,FRASCONI P.Learning long-termdependencies with gradient descent is difficult[J].IEEETransactions on Neural Networks,1994,5(2):157-166.
[38]SZEGEDY C,LIU W,JIA Y,et al.Going deeper withconvolutions[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition,2015.
[39]HE K,ZHANG X,REN S,et al.Deep residual learning forimage recognition[C]//Proceedings of the IEEE Conference onComputer Vision and Pattern Recognition,2016:770-778.
[40]ZHANG X,ZHOU X,LIN M,et al.Shufflenet:An extremelyefficient convolutional neural network for mobiledevices[C]//Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition,2018:6848-6856.
[41]HUANG G,LIU Z,VAN DER MAATEN L,et al.Denselyconnected convolutional networks[C]//Proceedings of theIEEE Conference on Computer Vision and PatternRecognition,2017.
[42]SANDLER M,HOWARD A,ZHU M,et al.Mobilenetd2:Inverted residuals and linear bottlenecks[C]//Proceedings ofthe IEEE Conference on Computer Vision and PatternRecognition,2018:4510-4520.
[43]IOFFE S,SZEGEDY C.Batch normalization:Acceleratingdeep network training by reducing internal covariateshift[C]//International Conference on Machine Learning,2015:448-456.
[44]SZEGEDY C,IOFFE S,VANHOUCKE V,et al.Inception-v4,inception-resnet and the impact of residual connections onlearning[C]//Thirty-First AAAI Conference on ArtificialIntelligence,2017.
[45]CHEN Y,LI J,XIAO H,et al.Dual path networks[C]//Advances in Neural Information Processing Systems,2017:4467-4475.
[46]TAO X,ZHANG D,MA W,et al.Automatic metallic surfacedefect detection and recognition with convolutional neuralnetworks[J].Applied Sciences,2018,8(9):1575.
[47]SHIPWAY N J,BARDEN T J,HUTHWAITE P,et al.Automated defect detection for fluorescent penetrantinspection using random forest[J].NDT&E International,2019,101:113-123.
[48]郭雪梅,劉桂雄,黃堅,等.面向標準件裝配質量的PI-SURF檢測區域劃分技術[J].中國測試,2017,43(8):101-105.
[49]黃堅,劉桂雄,林鎮秋.基于多角點結合的機箱標準件圖像特征提取方法[J].中國測試,2017,43(9):123-127.
[50]李宜汀,謝慶生,黃海松,等.基于Faster R-CNN的表面缺陷檢測方法研究[J/OL].計算機集成制造系統:1-19[2019-05-04].http://kns.cnki.net/kcms/detail/11.5946.tp.20190110.1415.002.html.
[51]DENG Y S,LUO A C,DAI M J.Building an AutomaticDefect Verification System Using Deep Neural Network forPCB Defect Classification[C]//2018 4th InternationalConference on Frontiers of Signal Processing(ICFSP),2018.
[52]何彬媛,黃堅,劉桂雄,等.面向機箱標準件裝配質量局部特征的智能檢測技術[J].中國測試,2019,45(3):18-23.
(編輯:李剛)
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
