基于深度卷積神經網絡的真實感渲染降噪方法
2019-11-22 08:23:10李寧謙丁建
現代計算機 2019年29期
李寧謙,丁建
(西華大學計算機與軟件工程學院,成都610039)
0 引言
從場景模型中產生一幅真實感圖像需要在圖像的每個像素點計算一個復雜的高維積分。蒙特卡洛渲染(MC)系統通過在多維空間中追蹤光線(采樣)去估算積分值。雖然可以通過少量采樣快速產生渲染結果,但是估算的結果相對于真實值具有較大的誤差,這些誤差在渲染結果中表現為大量噪點,因為蒙特卡洛估計方法的方差根據采樣數量的增加而線性減小,所以為了得到更加精確的估計結果往往需要大量采樣。計算大量采樣需要消耗較長的渲染時間,這種時間消耗局限了蒙特卡洛方法在現代渲染工業中的應用范圍。其中一種解決方法是對場景投放少量光線快速渲染出一副噪聲圖像然后使用濾波器作為后驗方法來對噪聲圖像進行過濾,從而得到無噪聲的結果。這種方法也被稱為圖像空間降噪方法,是近年來廣泛研究的課題[1]。雖然已經提出了大量的圖像空間蒙特卡洛渲染降噪方法,但是其中表現較為優秀的是基于回歸的方法[6],高階回歸提升了一定的渲染質量,然而這些質量的提升是以不斷增加的復雜度為代價,同時回報卻越來越小,這是因為高階回歸容易造成過擬合從而引入噪聲導致。為了避免對噪聲過擬合問題提出了一種基于監督學習的蒙特卡洛降噪方法[7],通過一組低采樣的噪聲圖像和相應的高采樣圖像作為訓練數據,最終得出回歸模型,然而這種方法使用一個相對簡單的多層感知機作為學習模型,并且僅用了少量的場景圖像產生訓練數據,除此之外,這種方法將濾波器進行硬編碼也限制了降噪系統的靈活性。
本文為了應對這些缺陷提出了基于卷積神經網絡的直接降噪監督學習框架,本框架的輸入向量僅需要三個輔助特征,即深度、視角空間法線、反照率。本文所提出的網絡訓練方法,簡單、穩定,收斂時間將近36小時。除此之外,為了應對訓練深度卷積神經網絡時梯度消失的問題,本文將殘差結構應用于卷積網絡結構對此問題做出了改善。
本文的主要貢獻如下:
(1)提出了一種魯棒性更高的單幀蒙特卡洛渲染降噪方法,訓練數據的輸入大為簡化,僅僅需要常見渲染器提供的少量輔助特征。
(2)驗證了直接降噪的有效性,同時也證明了輔助特征對神經網絡的降噪效果有一定的提升作用。
(3)將殘差網絡應用于渲染降噪,增加了卷積神經網絡的深度,使神經網絡的學習能力更加強大。
1 卷積神經網絡降噪
本節具體介紹基于深度學習渲染降噪的方法,其中包含網絡結構的關鍵設計思路,輔助特征的選擇。
1.1 降噪模型
蒙特卡洛降噪的目標是獲取盡可能接近真實像素顏色值Cˉp的被過濾像素顏色C?p的值,為了獲取這個估計值,通常對每像素矢量塊Xp的鄰域進行操作來產生過濾輸出的像素顏色p,給定降噪函數g(Xp;θ),參數θ代表降噪參數,每像素理想降噪參數能夠被表示成:

被過濾的像素顏色值為C?p=g(Xp;θ?p),l(Cˉ,C?)是真實顏色值與被降噪顏色值之間的損失函數。輸入向量Xp由以下組成:
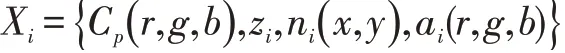
Cp:像素顏色值
zi:深度值
ni( x,y ):視角空間法線
ai(r,g,b):反照率
公式(1)中的函數g 即為需要學習的降噪模型。
1.2 卷積網絡降噪結構
本文所使用的網絡結構于圖1 中顯示。卷積神經網絡在網絡的每一層都使用多個卷積核,具有圖像空間共享的可訓練權重,卷積結構相對于傳統圖像降噪方法更加適合降噪任務。此外,通過激活函數將多個層連接在一起,卷積神經網絡能夠學習高度非線性函數,這樣的函數對于獲得高質量的輸出非常重要。

圖1 卷積網絡模型設計
1.3 加入殘差塊的降噪結構
基于反向傳播法計算梯度優化的神經網絡,由于反向傳播求隱藏層梯度時利用了鏈式法則,梯度值會進行一系列的連乘,導致淺層隱藏層的梯度會出現劇烈的衰減,這也就是梯度問題的本源,殘差網絡通過跳躍連接有效地將梯度流動到淺層網絡中,使得淺層部分的網絡權重參數能夠得到很好的訓練。本文在上文提出的卷積神經網路中加入殘差塊,并將網絡深度加深有效地改善了最終的降噪效果,殘差網絡[8-9]如圖2所示。
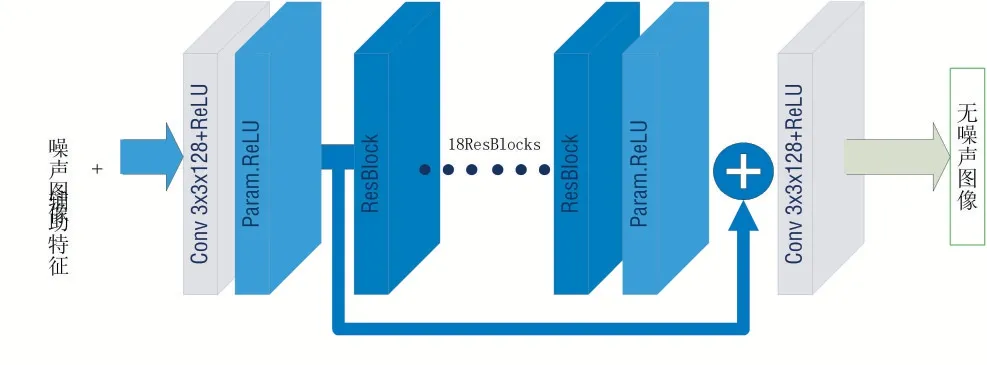
圖2 加入殘差塊的神經網絡結構
1.4 輔助特征以及預處理
對于HDR 圖像的輸入,根據對數變換將圖像進行范圍壓縮,此變換步驟對于最終結果有一定的平滑效果,總而言之,輸入向量由以下9 個通道組成:
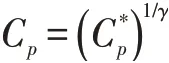
(1)輸入噪聲圖像(3 通道,需范圍壓縮處理)
(2)深度圖像(1 通道,需范圍壓縮處理)
(3)視角空間向量(2 通道)
(4)反射率(3 通道)
2 實驗
2.1 數據
為了使深度神經網絡能夠學習輸入與輸出數據之間復雜的關系,同時也要避免過擬合出現,因此進行本實驗需要獲取大量數據。目前,基于深度學習的渲染降噪實驗沒有公共數據集,本文在進行實驗之前需要花費大量時間去準備一個數據量較大的數據集(渲染器選用Tungsten),數據集中包含的物體類型較為多樣,也有各種分布式效果(運動模糊、焦散等)圖3 顯示了本數據集中的部分訓練數據。
2.2 訓練參數
本文實驗選用深度學習框架為TensorFlow,操作系統環境為Windows,采用GPU 加速,設置patch size 為128×128,步長為80,最終得到57k 個patch 塊用來訓練。網絡優化器使用Adam,動量值設置為0.9,L1-loss作為損失函數。訓練使用最小批次量為10,訓練迭代次數為106,學習率表如下:
(1)對于首1000 次迭代使用0.01 的學習率
(2)對于次1000 次迭代使用0.001 的學習率
(3)其余迭代使用104的學習率
本網絡一共有13847296 個可訓練參數,訓練一共耗時36 個小時。

圖3 部分訓練數據集示例
3 結果與對比分析
本文方法與NFOR、LBF、KPCN[10]進行對比,對于NFOR 使用作者的開源代碼,作者已經將源代碼加入Tungsten 渲染器,對于KPCN,直接選用作者已訓練模型,對于LBF 方法,作者已將該方法集成到PBRT2。本文的主要關注點在快速渲染高質量圖像,例如:游戲渲染、虛擬現實、原型設計等,這些應用渲染速度非常重要,然而每像素采樣(SPP)過高將會降低渲染速度,因此選用的噪聲圖像以及特征圖像都是以4SPP 渲染,真實圖像(Ground Truth)以32K SPP 或者更高的采樣數量渲染,確保圖像在人眼感知上沒有噪聲存在。為了衡量這些方法的表現,本文使用RelMSE(Relative MSE)與SSIM(Structural Similarity Index)作為降噪結果的衡量標準,兩者數值變化范圍為0 到1,1 代表具有與真實圖像完美的匹配程度,圖4 顯示了降噪結果,數據顯示為降噪時間,不包含渲染時間。
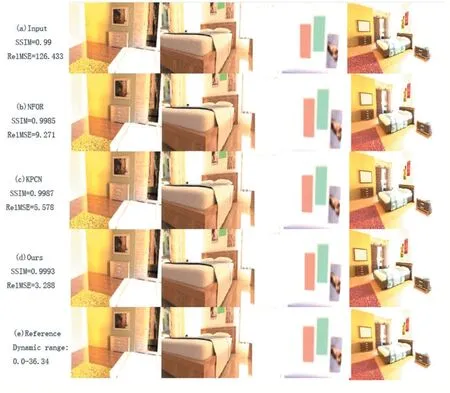
圖4
4 結語
在所有的降噪測試中,本文選用的方法始終優于其他幾種解決方案,表1 顯示了所有降噪結果的SSIM數值。NFOR 在少部分場景中RelMSE 效果更好,但是漫反射效果卻有很多污斑,KPCN 方法魯棒性不強,因為這種方法需要大量的輔助特征,如果不能有效地利用輔助特征,往往會造成降噪圖像過度模糊。
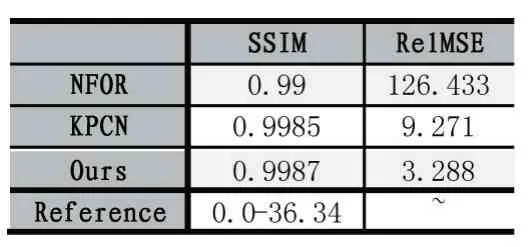
表1
因為本文的方法針對于單幀蒙特卡洛渲染圖像,如果直接將本方法應用于動畫序列幀,那么降噪結果并不具有時域連貫性,其中一種解決思路是使用視頻時域一致性濾波器。然而,更好的解決思路是通過前后兩幀之間添加循環連接(Recurrent Connections)來解決神經網絡中的時間一致性問題,未來的工作將圍繞這種方法展開。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
兒童故事畫報(2019年5期)2019-05-26 14:26:14
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
新聞傳播(2015年10期)2015-07-18 11:05:40
