基于機器視覺的玉米種粒破損識別方法研究
2019-12-22 05:43:38徐文騰馬偉童金城謙
農機化研究 2019年2期
崔 欣,張 鵬,趙 靜,徐文騰,馬偉童,金城謙
(1.山東理工大學 農業工程與食品科學學院,山東 淄博 255000;2.雷沃重工股份有限公司,山東 濰坊 261206)
0 引言
我國是農業生產大國,玉米作為我國重要的糧食作物之一,于2012年開始成為我國第一大糧食作物,其戰略地位可見一斑[1]。由于玉米種粒在收獲、儲藏的過程中會因機械啃傷等各種因素產生損傷,影響發芽率及玉米產量,所以玉米種粒的播前破損檢測工作不可或缺。這一過程可以保證玉米種粒發芽率,對玉米的增產具有重要意義。
20世紀70年代初,機器視覺技術在生物醫學圖像和遙感圖像處理兩項應用中取得不俗成果,并由此開始逐漸發展起來[2]。隨著計算機技術的快速發展,計算機的性價比和處理速度不斷提高,為機器視覺相關技術的研究和應用奠定了堅實基礎,使機器視覺技術廣泛地應用于圖像分析、對象分類與品質檢測等領域中。機器視覺檢測技術與人工檢測技術相比,具有精度高、速度快、重復性好、信息量大等優點,在谷物外觀品質檢測領域的發展及應用前景十分廣闊。機器視覺技術在谷物外觀品質檢測中的應用主要有:農產品及作物種子表面裂紋檢測、農作物種子精選及分級、根據農產品表面信息進行損傷缺陷檢測并進行分級等。機器視覺檢測技術逐漸取代人工檢測,是自動化檢測發展的必然趨勢。因此,機器視覺檢測技術在農產品外觀品質檢測方面的研究具有比較高的理論價值和實際意義[3]。
在基于機器視覺的玉米種子外觀品質檢測方面的研究方面,國外一些發達國家起步的較早,于20世紀90年代就開展相關研究。研究內容主要包括玉米種粒的顏色、質量、尺寸等品質特征檢測及玉米種粒的缺陷檢測等。21世紀以來,我國也圍繞機器視覺技術逐漸開展了玉米種子品質檢測、品質分類、形態識別及自動精選等方面的研究。目前,國內外針對玉米種粒的破損檢測大多偏向于特征參數的提取檢測及算法研究上,有關破損玉米種粒智能自動識別模型的研究較少。
本文將機器視覺技術運用到玉米種粒的破損識別檢測中,對玉米種粒圖像進行了噪聲分析、降噪和分割等預處理,并提取了玉米種粒的特征值。將機器學習中的支持向量機監督學習模型應用到玉米種粒的破損識別檢測中,通過訓練支持向量機(SVM)形成玉米種粒破損識別模型,從而根據玉米種粒的幾何、形狀特征自動判斷種粒是否合格,為實現玉米種粒的在線破損識別及自動分類奠定了基礎。
1 玉米種粒圖像獲取及預處理
1.1 圖像獲取
玉米種粒的圖像采集均在玉米種粒圖像獲取裝置上進行,如圖1所示。玉米種粒的品種是登海605;相機選用CCD工業相機,焦距4mm,光圈F1.2,安裝時鏡頭光軸距傳送轉盤的高度為15mm,采集的圖像尺寸為200×200像素;光源采用環形白色光LED燈,內直徑為27mm,外直徑為46mm。共采集破損玉米種粒圖像與完整玉米種粒圖像各100幅,用來進行圖像預處理、特征提取、對SVM進行訓練及識別效果檢測等工作。
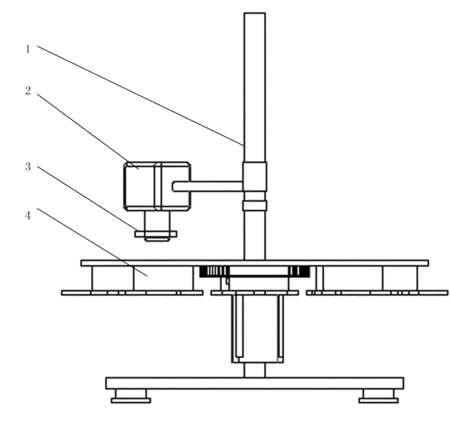
1.支架 2.CCD工業相機 3.環形光源 4.圖像采集區圖1 玉米種粒圖像獲取裝置
1.2 圖像預處理
在進行玉米種粒特征提取之前,需要將CCD采集到的玉米種粒圖像進行預處理。圖像預處理能很好地改善在圖像的獲取、傳輸、變換過程中因失真、噪聲、曝光不足或過量等因素與原圖像產生的差異,以便進行后續圖像識別等工作[4]。首先,將采集到的玉米種粒圖像進行灰度化處理,判斷噪聲類型,選擇適當的方法對圖像進行降噪;圖像降噪完成后,進行玉米種粒圖像的分割,通過忽略目標區域外的其他區域得到待檢圖像,以便進行特征提取。
1.2.1 圖像降噪
灰度化后的玉米種粒圖像如圖2所示。由圖2可知:采集到的玉米種粒圖像存在噪點及細小雜質點,噪聲種類人工初步判斷為椒鹽噪聲。采用差影法對采集到的玉米種粒圖像進行噪聲分析,在采集環境完全相同的前提下(即保證采集對象、采集設備、采集角度、光源光照強度等都相同),連續采集2幅玉米種粒的圖像,將獲得的2幅連續采集的圖像作減法運算,得到的分析結果如圖3所示。由圖3可以清晰地看出噪聲類型為椒鹽噪聲,據此判斷采集到的玉米種粒圖像噪聲類型為椒鹽噪聲[5]。用上述方法對另外兩組連續采集的玉米種粒圖像進行差影法分析,得出一致結論。
圖2 灰度化后的玉米種粒圖像
查閱資料可知,去除椒鹽噪聲效果比較好的方法是中值濾波法,故本文對玉米種粒圖像采用中值濾波法進行圖像降噪。經中值濾波降噪處理過的玉米種粒圖像噪點大大減少(見圖4),適合對圖像進行下一步處理。
圖4 玉米種粒降噪后的圖像
1.2.2 圖像分割
對經過降噪處理的玉米種粒圖像進行圖像分割。玉米種粒的拍攝背景選擇與玉米種粒顏色反差較大的黑色,由于同一品種的不同玉米種粒在外觀、顏色等方面區別不大,其灰度直方圖峰值相似,故本文采用灰度閾值法中的二值化處理來對玉米種粒圖像進行分割。圖像二值化處理即選擇一個合適閾值,將圖像轉化為黑白二值圖像,從而完成目標圖像和背景圖像的分割。二值化分割具體定義為
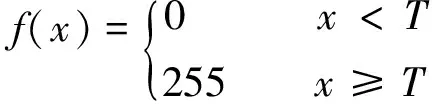
(1)
式中T—閾值。
通過觀察分析采集到的玉米種粒圖像的灰度直方圖,可以快速、準確地找出合適的圖像分割閾值約為20,如圖5(a)所示。圖5(b)為用此閾值分割后的玉米種粒圖像,可以看出分割后的玉米種粒圖像還存在部分大的噪點或者雜質點,所以本文將所有閉合區域的像素數最小值設為100,把圖像中像素數小于100的目標區域設置為背景。處理后的圖像如圖5(c)所示。此方法可以有效地去除圖像中較大的噪點和雜質點,得到的圖像中玉米種粒輪廓明顯,適合進行下一步的玉米種粒特征值提取工作。
2 玉米種粒圖像特征提取
在玉米種粒的圖像識別系統中,玉米種粒的特征參數的選用和提取直接關系到玉米種粒的識別精度。圖像的特征種類包括顏色特征、幾何特征、形狀特征及紋理特征等。由于玉米種粒的破損部分主要集中在胚部分,破損部分與完整玉米種粒顏色特征對比不明顯,所以本文不采用玉米種粒的顏色特征,只從幾何特征與形狀特征中提取特征參數作為玉米種粒破損的檢測指標[6-8]。
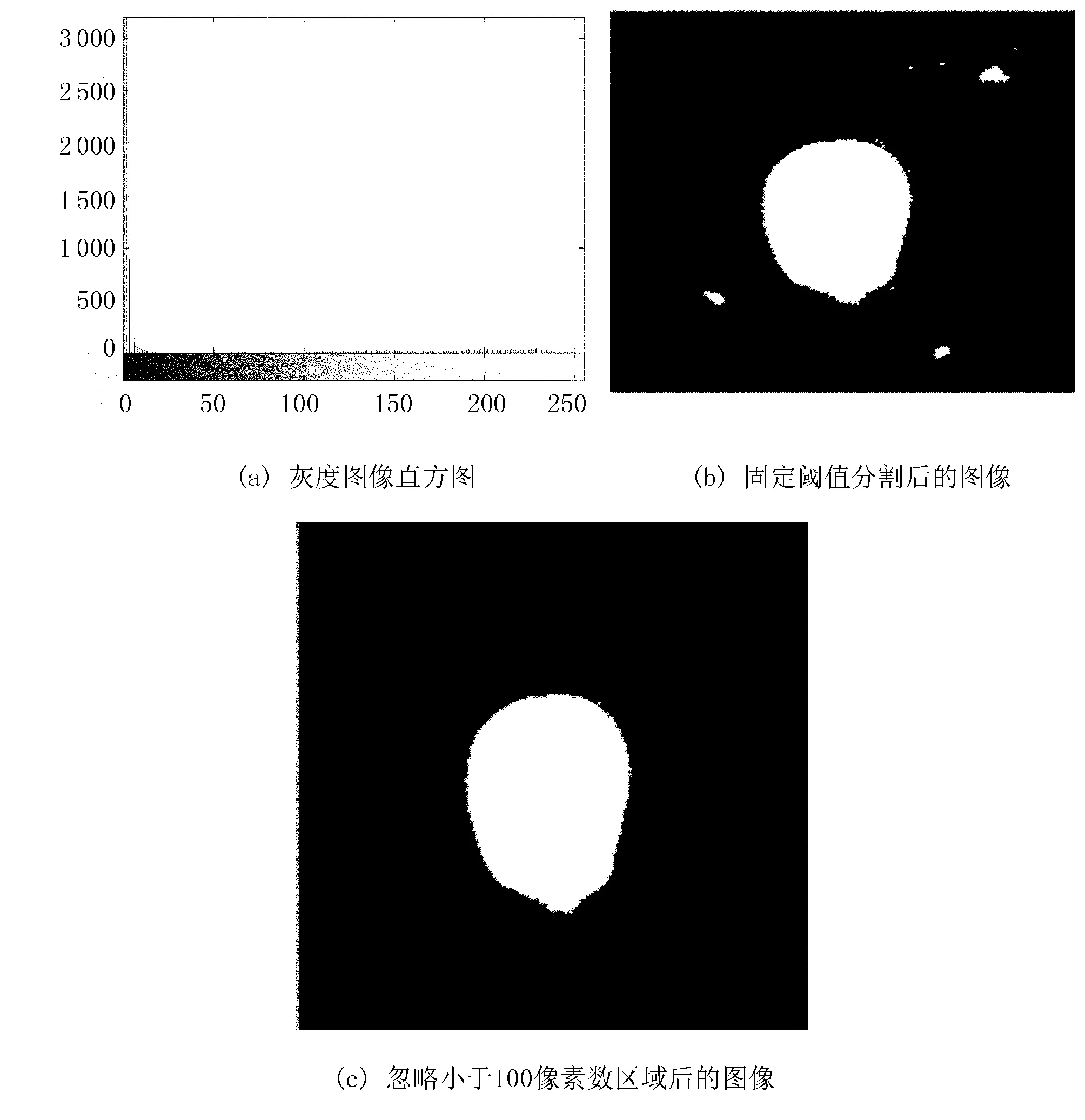
圖5 玉米種粒分割圖像
2.1 幾何特征提取
破損玉米種粒的外在形狀與完整玉米種粒差異較為明顯,所以本文選擇提取玉米種粒的部分形狀特征作為檢測指標。根據玉米種粒的形態特征,分別提取玉米種粒的周長、面積、周長面積比、長軸長、短軸長及長寬比6個幾何特征[9]。玉米種粒的幾何、外觀特征示意圖如圖6所示。
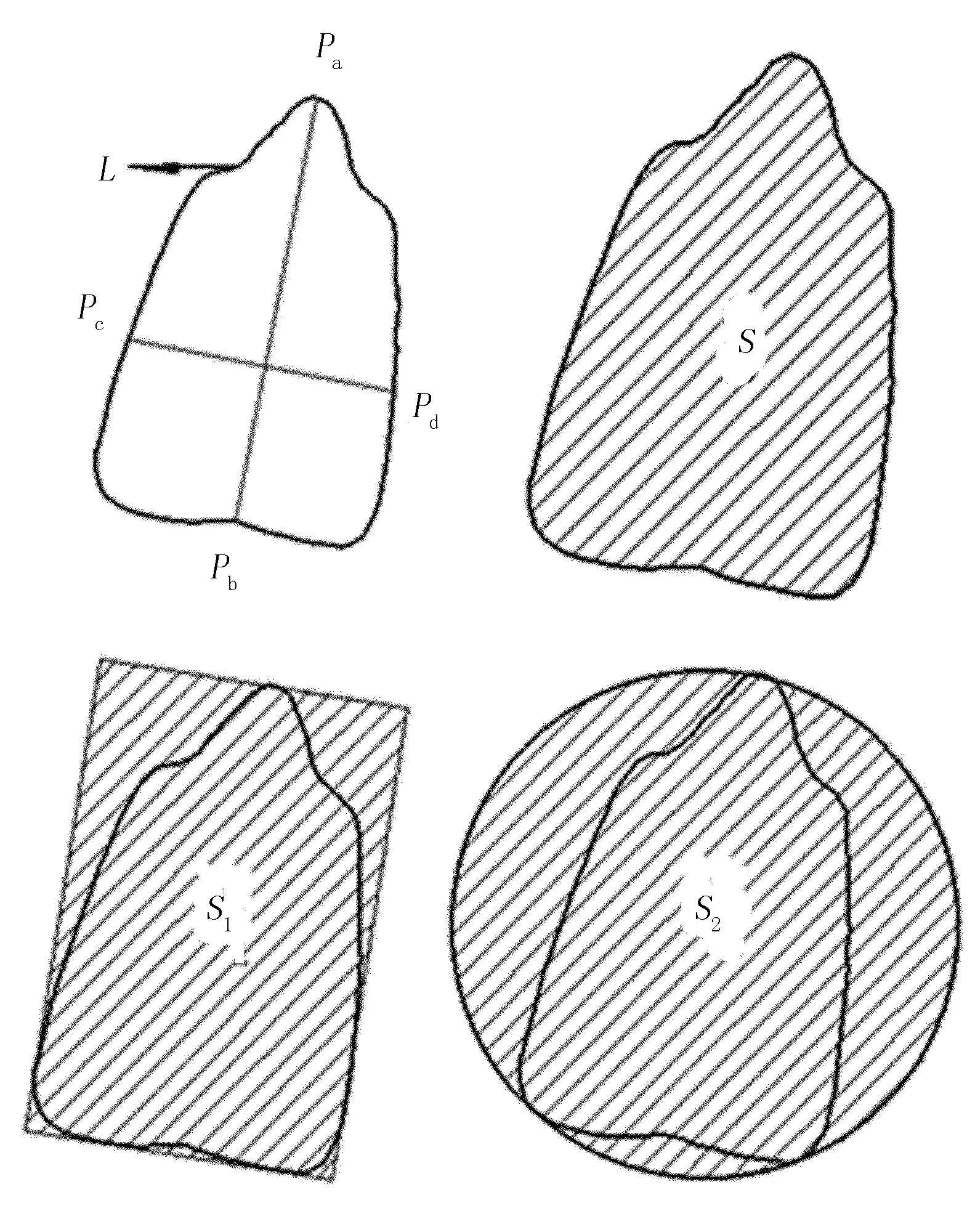
圖6 玉米種粒幾何及外觀特征示意圖
圖6中,L為周長;Pab為長軸長度;Pcd為短軸長度;S為面積;S1為最小外接矩形面積;S2為最小外接圓面積。幾何特征及參數如表1所示。

表1 玉米種粒幾何特征及參數
2.2 形狀特征提取
除上述6個幾何特征之外,還提取了玉米種粒的10個形狀特征,其中包括玉米種粒的矩形度(S/S1)、圓形度(4πS/L2)、緊湊度(S2/Lab),如表2所示。

表2 玉米種粒的形狀特征及參數
除此之外,還包含7個彼此獨立的Hu不變矩特征量。矩在其數學定義中可以表征隨機量的分布情況,如果把灰度或者二值圖像看作一個二維密度分布函數,就可以把矩概念引入到圖像分析中。各階矩的物理意義分別為:零階矩(m00)表征二值圖像的面積;一階矩(m01,m10)表征目標區域質心位置;二階矩(m02,m11,m20)反映目標的主軸、輔軸的長短及主軸方向角;三階矩(m03,m12,m21,m30)描述圖像細節,如目標的方向和斜度、反應目標的扭曲程度等。Ming-Kuei Hu在1962年利用二階和三階中心矩構造了7個不變矩,即Hu不變矩。Hu不變矩滿足RST(rotate,scale,translation,即旋轉、縮放、平移)不變性,不因目標在圖像中的位置、大小、角度而有所改變,對于識別紋理簡單的圖像識別精度較高,效果較好。7個Hu不變矩的具體定義如式(2)~式(8)所示。式中,ηpq分別代表各階矩中心矩。
I1=η20+η02
(2)
I2=(η20-η02)2+(2η11)2
(3)
I3=(η30-3η12)2+(3η21-η03)2
(4)
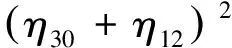
(5)
I5=(η30-3η12)(η30+η12)×
[(η30+η12)2-3(η21+η03)2]+
(3η30-η03)(η21+η03)×
[3(η30+η12)2-(η21+η03)2]
(6)
I6=(η20-η02)[(η30+η12)2-(η21+η03)2]+
4η11(η30+η12)(η21+η03)
(7)
I7=(3η21-η03)(η30+η12)×
[(η30+η12)2-3(η21+η03)2]-
(η30-3η12)(η21+η03)×
[3(η30+η12)2-(η21+η03)]
(8)
Hu不變矩提取流程圖如圖7所示。
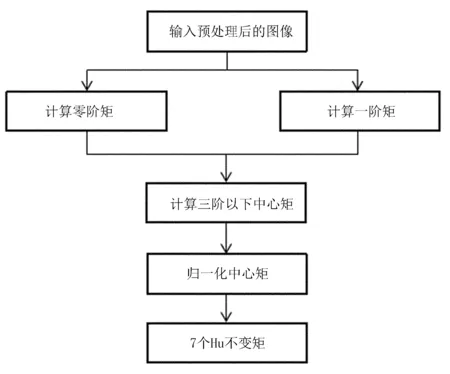
圖7 提取Hu不變矩流程圖
3 玉米種粒圖像識別檢測算法
本文提出的破損玉米種粒識別方法可以概括為3部分,即玉米種粒的預處理、玉米種粒特征提取、模型訓練與目標識別。圖像識別流程圖如圖8所示。
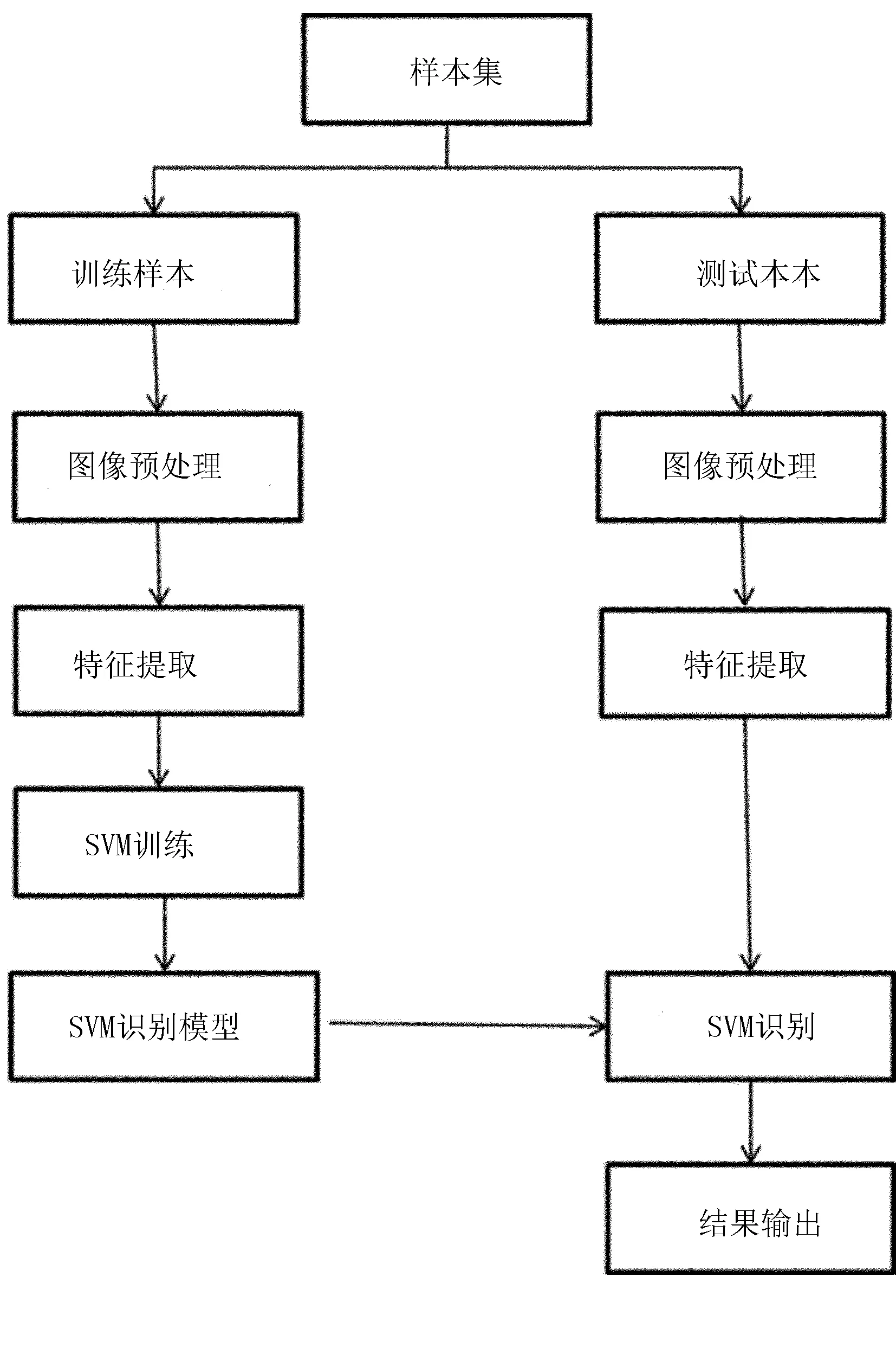
圖8 圖像識別流程圖
3.1 支持向量機分類原理
支持向量機(SVM,Support Vector Machine)是20世紀90年代初由Vapnik和Corinna Cortes等人根據統計學習理論提出的一種機器學習的新方法[10-11]。SVM是一個有監督的學習模型,與傳統的人工神經網絡相比,結構更加簡單而且泛化(generalization),能力明顯提高,通常應用在模式識別、分類以及回歸分析等領域。
支持向量機的核心思想在于核函數,就是利用合適的非線性映射把低維空間向量集映射到一個較高維數的特征空間,并在這個空間里找到一個具有最大邊界的最優線性分類面(最優分類超平面)(見圖9),從而解決了低維空間向量集難以劃分的問題。

圖9 最優分類超平面示意圖
SVM最初是針對二值分類問題提出的,對于樣本集(xi,yi),i=1,2,...,n;xi∈Rn;yi∈{-1,1},構造分類面WX+b=0,能將兩類樣本準確無誤地分開,并且使兩類之間的分類超平面距離達到最大[12]。W為權值向量;X為輸入向量;b為偏置。線性判別函數的一般形式為g(x)=WX+b,用同倍縮放W、b的方法進行歸一化,使離分類面最近的樣本滿足|g(x)|=1,那么兩類所有樣本都滿足|lg(x)|≥1,兩類樣本的分類間隔為2/‖W‖。
綜上所述,SVM分類器要解決的問題用數學來表述:在滿足式(9)的前提下,求式(10)的最小值,則
yi(wTxi+b)-1≥0i=1,2,...n
(9)
(10)
3.2 支持向量機核函數選擇
支持向量機通過非線性變換,將輸入空間映射到高維度特征空間,可以用低維輸入空間的某函數代替高維特征空間的內積計算,大大降低計算量,有效避免“維數災難”,這樣的函數即被稱為核函數。
核函數包括線性核函數、多項式核函數及高斯核函數等。其中,高斯核函數最常用,可以將數據映射到無窮維,也叫做徑向基函數(RBF)。本文在多種核函數中選用了RBF核函數,此核函數可以適用于低維、高維及不同樣本量等情況[13-14]。
3.3 SVM訓練
本文在完成玉米種粒的破損檢測及分類的前提下,盡量簡化識別分類系統,縮短檢測時間。根據識別系統要實現的功能,選擇使用二值SVM分類器。利用圖像采集裝置采集玉米種粒圖像,將采集到的玉米種粒圖像均分為訓練樣本和測試樣本,即訓練樣本和測試樣本均含各不相同的50幅完整玉米種粒圖像和50幅不同程度的破損玉米種粒圖像。用訓練樣本對SVM進行訓練,特征量共16個,將待檢測的玉米種粒分為兩類,“合格”輸出為1,“不合格”輸出為0,即SVM訓練有16個輸入量、2個輸出量。
建立訓練樣本集,選擇RBF核函數,將輸入玉米種粒圖像樣本進行歸一化并構造核矩陣H{1,1},計算出權值向量W和超平面系數b,最終構造出最優分類超平面并訓練獲得識別模型。
4 試驗設計與結果分析
4.1 試驗設計
本文的實驗運行平臺的計算機主機配置:Intel(R) Core(TM) i5-3230M CPU@2.60GHz,RAM 8.00GB,顯卡NVIDA GeForce GT 650M;試驗運行環境:MatLab R2014a編程語言環境。
4.1.1 Hu不變矩的不變性試驗
為驗證Hu不變矩的旋轉、縮放和平移不變性,本文設計了1組測試Hu矩不變性的試驗。利用圖像采集裝置分別采集同一粒玉米種子正放、順時針旋轉90°、縮放0.5倍、向右平移20像素等4幅圖像,確保采集環境完全相同,圖像大小均為200×200像素。將4幅圖像分別進行Hu矩計算,得到Hu不變矩的值,如表3所示。
表3 玉米種粒圖像旋轉、縮放和平移后的Hu不變矩
Table 3 The Hu invariant moments of corn seed images after rotated, scaled and translation
4.1.2 SVM模型測試試驗
針對前面訓練得到的SVM識別模型,為驗證其可行性與準確率,設計了一組SVM識別模型測試試驗。
用預先采集的測試樣本對得到的SVM識別模型進行驗證,以測試識別正確率、測試識別時間作為衡量SVM模型的指標。其中,測試識別率是指正確識別的玉米種粒的個數占所有參檢玉米種粒的比值;測試識別時間是指用訓練好的SVM識別模型對測試樣本進行識別所需時間;試驗重復10次,各指標的值取10次的平均值。
用100幅測試樣本圖像對SVM模型進行驗證,將每次測試得到的100個玉米種粒完整性檢測結果與人工判斷結果做對比,以人工判斷為準,計算模型識別正確率,并記錄測試100幅圖像所需時間。識別正確率與識別時間取10次測試均值之后,最終得到結果的如表4所示。

表4 試驗結果
4.2 試驗結果分析
針對Hu矩不變性的驗證試驗,由表3數據可知:玉米種粒在目標區域內旋轉90°、縮放0.5倍、向右平移20像素后Hu矩沒有變化,證明圖像的Hu不變矩具有不變性。
針對SVM識別模型的測試試驗,由表4中數據結果可知:經過10次試驗,訓練得到的SVM玉米種粒圖像識別模型對玉米種粒破損識別準確率達到95%以上,識別100幅圖像的時間為1.27s,識別效果較好,識別速度較快。
5 結論
1)利用差影法確定了玉米種粒圖像噪聲類型,采用中值濾波法對圖像降噪,通過灰度閾值法完成了圖像的分割。
2)提取了玉米種粒的周長、面積、周長面積比、長軸長、短軸長及長寬比6個幾何特征和矩形度、圓形度、緊湊度和7個Hu不變矩10個形狀特征,共16個特征值。利用提取的玉米種粒的16個特征量對SVM進行訓練,構造了SVM智能識別模型。
3)對圖像Hu不變矩的不變性進行試驗驗證,結果表明:圖像的Hu矩具有旋轉、縮放和平移不變性。
4)對訓練好的SVM識別模型的識別精度及識別時間進行測試,結果表明:SVM識別模型能夠較好地完成對玉米種粒破損的識別。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
