一種語義稀疏服務聚類方法
2020-01-05 07:00:06胡文生謝芳
軟件導刊 2020年11期
胡文生 謝芳


摘 要:隨著SOA迅猛發展和互聯網上服務數量俱增,服務發現成為極具挑戰性的工作。傳統的服務發現方法在語義稀疏情境下精準度不高,主要是缺乏有效信息對發現工作的支持,無法對服務進行準確的類別劃分。針對此問題,提出一種基于BTM面向Web服務短文本描述的服務聚類方法S3C,該方法的主要思想是利用BTM在短文本聚類過程中使用Biterm(詞對)優勢對服務描述進行潛在特征表示,基于服務潛在特征使用Kmeans聚類方法進行服務聚類。BTM采用詞對的主題建模方式,能夠極大程度地擴展文本信息,解決短文本中的關鍵詞稀疏問題。采用PWeb數據集進行大量對比實驗可知,該方法與經典聚類方法相比,類簇的平均純度提高30%,平均熵降低近50%。
關鍵詞:服務聚類;語義稀疏服務;BTM模型;服務發現;人工智能
DOI:10. 11907/rjdk. 202157
中圖分類號:TP301 ??? 文獻標識碼:A?????? 文章編號:1672-7800(2020)011-0006-05
A Semantic Sparisity Web Service Clustering Approach
HU Wen-sheng,XIE Fang
(School of Computer Science, Hubei University of Technology, Wuhan 430068, China)
Abstract: With the rapid development of SOA and the increasing number of service on the Internet, service discovery has become a challenging task. The accuracy of traditional service discovery approach is not high in the context of senmantic sparseness, which is mainly due to the lack of effective information to support it. Faced with this issue, this paper proposed a web service clustering approach S3C based on BTM model for short text web servcie description. This approach takes advantage of BTM in short text clustering to establish latent feature vector of Web service, and use Kmeans to cluster service based on latent feature vector. The BTM uses biterm to train topic-model, which can greatly expand information and solve semantic sparsity in short text. Compared with the classical clustering approach, the proposed approach improves the average purity by 30% and reduces the entropy by nearly 50%.
Key Words:Web service clustering; semantic sparsity service; BTM model; Web service discovery; artificial intelligence
0 引言
隨著面向服務的體系架構(Service Oriented Architecture,SOA)的迅猛發展,互聯網上Web服務數目呈持續增長趨勢。如何為用戶快速有效地推薦合適的服務成為一項極具挑戰性的研究任務。由于版權和資金等原因,大量UDDI服務注冊中心相繼關閉[1],基于搜索引擎技術的服務發現方法成為主流方式。常用搜索技術基本采用基于關鍵字匹配的方式,導致服務發現的精準度受到服務描述中缺少關鍵字或同形異義等因素的影響[2]。長期以來,服務聚類被視為解決該問題的一種有效途徑,并得到了學術界的廣泛關注[2-5],它將功能相似的服務聚類到一起從而減小搜索空間,提高服務發現效率[3]。例如文獻[2]從WSDL文檔中抽取服務特征建立特征向量,依照特征向量組織成不同的服務類簇。盡管上述服務聚類方法在不同情景下具有很好的效果,但是當面對服務描述語義稀疏時發現此過程中仍然會出現一些問題,造成這些問題的主要原因是諸多聚類算法在服務描述語義稀疏時,語義稀疏描述導致缺乏足夠的統計信息進而無法進行有效的相似度計算[6]。互聯網上最大的服務注冊中心ProgrammableWeb(http://www.programmableweb.com,PWeb)提供了針對各類服務的注冊功能,同時提供了服務關于功能的自然語言描述信息,通過這些信息進行服務分類。存在的關鍵問題是,這些服務描述往往以短文本形式存在,語義稀疏程度非常高。據統計,PWeb中服務數量最多的前10個分類中,服務描述文本平均長度僅為72,其中包含大量的無意義詞語。面對互聯網上與日俱增的服務規模,在語義稀疏的情境下,傳統服務聚類方法精確度普遍不高,影響服務發現和推薦效率。
1 相關工作
文獻[7]建立基于統計的模型動態計算服務相似性,促進搜索引擎發現服務的能力;文獻[8]基于層次Agglomerative聚類算法,采用一種自下而上的方式將功能相似的服務組織成不同類簇,提高服務發現效率;文獻[9]提出一種WTCluster服務聚類方法,利用Kmeans算法聯合WSDL和標簽相似性進行服務聚類;文獻[10]利用Petri網技術針對服務功能和過程兩個側面的相似性進行服務聚類,提升服務發現效率;文獻[11]提出一種支配服務的概念,通過分析服務支配關系構建服務與用戶請求之間的相關性;文獻[12]提出一種基于Info-Kmean與概要的增量學習方法,解決K-means算法中心點選取0值特征導致KL散度值無窮大的問題。
目前,基于主題模型的服務聚類研究有很多。文獻[13]使用PLSA(Probabilistic Latent Semantic Analysis)和LDA(Latent Dirichlet Allocation)從服務描述中發現服務的潛在主題,使用主題模型對OWL-S服務的Profile和功能描述進行聚類;文獻[9]利用LDA將WSDL中提取的特征描述構建成為層次結構,獲取關于服務的主題—特征分布,建立基于主題的服務發現技術;文獻[14]將WSDL文檔預處理獲取特征向量表征且與服務功能標簽相融合,利用WT-LDA模型實現服務聚類。
上述方法在不同程度上提高了服務聚類效率,但仍然存在以下不足:①參與聚類的服務文檔大多數是基于某種特定格式的服務描述文檔,缺乏對自然語言描述的服務發現方法研究;②針對自然語言短文本描述的服務發現方法經常會遭遇語義稀疏的情況,而服務發現過程中鮮有考慮此方面的問題。因此,本文提出一種基于BTM對服務描述進行特征構建的方法,有效規避描述信息的語義稀疏問題,在此基礎上利用服務潛在特征進行服務聚類的方法以提高服務聚類質量。
2 基于BTM的語義稀疏服務聚類方法
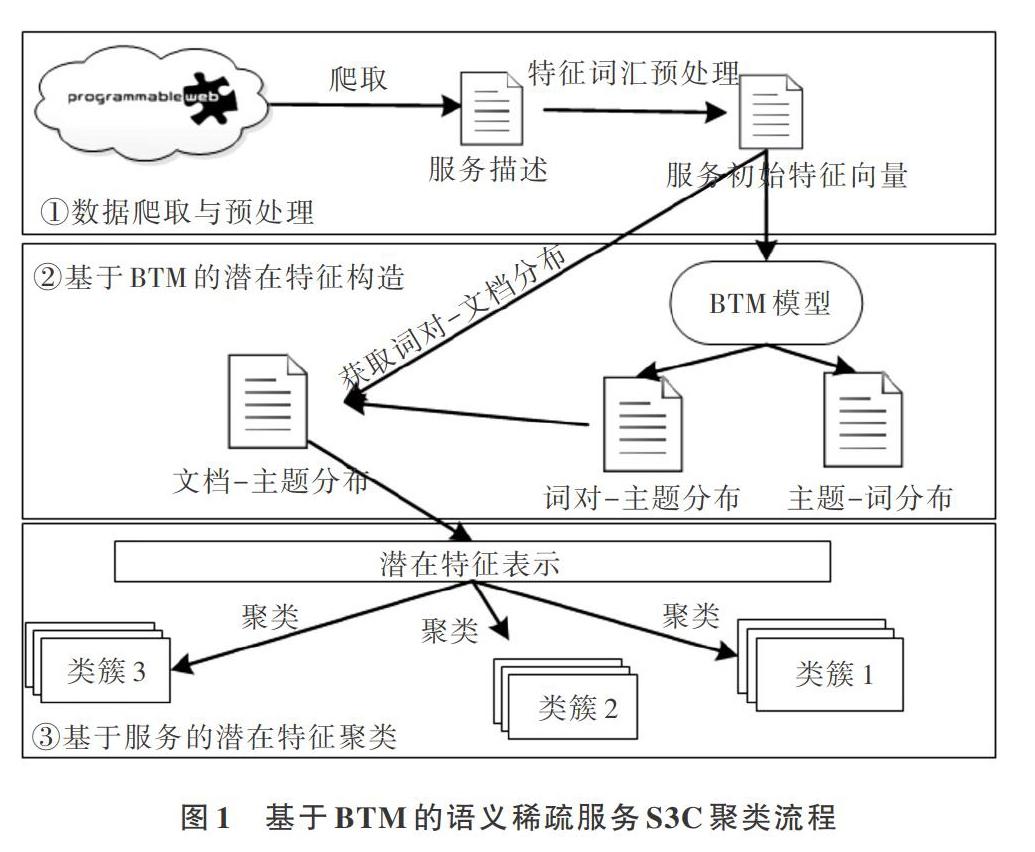
本文提出的基于BTM的語義稀疏服務聚類方法(Semantic Sparse Service Clustering,S3C)是一種基于主題模型進行服務聚類的方法,聚類過程主要分為3個階段:數據爬取與預處理、基于BTM的潛在特征構造和基于服務的潛在特征聚類,具體流程如圖1所示。第一階段,主要從服務注冊中心爬取服務的描述文件進行數據清洗;第二階段,通過訓練BTM模型獲取文檔—主題分布,構建服務的潛在特征;第三階段,依據上階段獲取的服務潛在特征,利用聚類算法進行聚類工作。
2.1 數據爬取與預處理
從PWeb中獲取服務的文本描述數據,獲得這些信息之后,創建表征服務內容的初始特征向量。
(1)建立初始向量:基于自然語言處理包NLTK實現服務描述文檔的分詞。
(2)詞干還原:利用NLTK提供的PorterStemmer算法將特征向量中的特征詞匯進行詞干還原,例如,Learned和Learning具有相同詞干Learn。
(3)移除功能詞:功能詞匯指諸如“the”、“a”等對服務特征沒有實際意義的詞,需要從文檔中移除此類功能詞。
完成上述數據清理過程,為潛在特征構造提供數據支持。
2.2 基于BTM的潛在特征構造
BTM和LDA都是主題模型。BTM模型中,即使文本只有10個關鍵詞,也會構造出45個Biterm,該方法極大程度地解決了LDA對短文本處理存在的弊端。同時,大量實驗發現,使用Biterm對文本建模要比用單一詞語建模能夠更好地挖掘文本的隱藏主題。
2.2.1 BTM模型
BTM概率圖模型如圖2所示,首先生成基于BTM模型的語料庫。從概率圖模型可以發現:對于一個短文本的服務描述文檔,不同詞對所對應的主題Z=1,2,…,z是獨立的,這是BTM與傳統主題建模方法的顯著區別。BTM針對整個語料集合[B]中每個詞對[b(wi,wj)]進行建模,未對文檔的生成過程進行建模,在學習過程中尚未獲得服務文檔的主題分布,得到的僅是詞對—主題與主題—詞的分布。為了獲取文檔—主題分布,本文采用貝葉斯公式推理得到服務文檔的主題分布。
使用式(1)計算每個詞對的概率。
使用式(2)計算整個語料庫[B]的概率。
首先,根據全概率公式,使用式(3)表示文檔主題—分布。
其中,利用貝葉斯公式計算詞對—主題分布,如式(4)所示。
式(3)中,[P(b|d)]可以將服務描述文檔中詞對的經驗分布作為[P(b|d)]估算值,具體如式(5)所示。
其中,[nd(b)]表示文檔d中詞對b出現的次數。
2.2.2 參數估算
利用BTM獲得服務描述文檔的主題分布,必須要估算出BTM中參數[θ]和[φ]的設置。常用參數估算方法有期望傳播、變分推理和Gibbs抽樣等[15],本文采用Gibbs抽樣方法作為BTM的參數估算方法,如式(6)所示。
對于語料集合[B]中的每一個詞對[b(wi,wj)],計算詞對的條件概率分布,獲得其主題分布[zb],其中[z-b]表示在集合[B]中除該詞對外的主題分配,[nz]表示主題z分配給詞對[b]的次數,[nwi|z]表示主題z分配給單詞[wi]的次數,[nwj|z]表示主題z分配給單詞[wj]的次數,M表示特征詞的個數。
根據詞對—主題分布情況,利用式(7)和式(8)計算出參數[θ]和[φ]。
其中,[φw|z]表示主題z中單詞w的概率,[θz]表示主題z的概率,[B]是詞對集合中詞對的總數。
2.3 基于服務的潛在特征聚類
根據上文分析,通過式(3)使用貝葉斯公式計算得到服務的文檔—主題分布[P(z|d)]。通過大量實驗對比,采用式(9)的方法對每個服務描述進行表示,將服務表示轉換成潛在特征。
將服務表示成潛在特征后,使用Kmeans方法對服務進行聚類,聚類具體過程見算法1。
算法1 語義稀疏的服務聚類算法
輸入:服務集合SS,超參數[α]、[β],主題數目。
輸出:服務類簇。
1 初始化Z,并使得|Z|等于聚類數目。
2 WHILE 算法未收斂 DO
3??? FOR iter = 1 TO Niter DO
4??????? FOR [b∈B]DO
5??????????? 基于[P(z|z-b,B,α,β)],采樣[zb]
6??????????? 更新[nz],[nwi|z]和[nwj|z]
ENDFOR
ENDFOR
ENDWHILE
7 得到參數Θ和Ф。
8 根據式(3)—式(5),建立主題—服務分布,使用式(9)建立服務潛在特征表征。
9 基于服務潛在特征,使用K-means算法對服務進行聚類,最終返回服務類簇。
第1-7步使用Gibbs抽樣獲得BTM模型的模型參數;第8步基于式(3)—式(5)計算獲得服務的文檔—主題分布,根據式(10)構建服務的潛在特征表示;第9步實現服務聚類,并返回服務的類簇信息。
3 實驗評價
3.1 實驗準備
實驗數據來源于PWeb,該網站提供的服務具有詳細的Profile信息。實驗過程中爬取10 050個Web服務及其相關信息,篩選了包含服務最多的5個類別,總共包含2 761個Web服務,數據統計如表1所示。
使用純度(purity)和熵(entropy)作為評價指標,其中,純度越高,且熵越小,表明服務聚類的效果越好。設類簇[ci]包含個數為[ni],使用式(10)和式(11)計算每個類簇的純度和所有類簇的平均純度。
其中,[ni]代表類簇[ci]中包含的服務數目,[nji]代表第j個分類中被成功分入[ci]中的服務數目。
使用式(12)和式(13)計算每個類簇的熵和所有類簇的熵。
3.2 結果與分析
3.2.1 方法性能
為了評測本文所提出S3C方法的聚類性能,將其與3種常用的服務聚類方法進行性能對比。
(1)K-means:該方法是基于劃分的聚類算法,實驗過程中,直接使用K-means對服務進行聚類。
(2)Agglomerative:該方法是基于自底向上的層次聚類算法,實驗過程中,直接使用Agglomerative方法對服務進行聚類。
(3)LDA:該模型是一種無監督的主題聚類模型,實驗過程中,直接使用LDA模型對服務進行聚類。
在實驗過程中,使用BTM開源代碼(http://code.google.com/p/btm)構造潛在特征,超參數采用文獻[16]中設置的[α]=50/K,[β]=0.01。
從圖3得出如下結論:①S3C算法不論是在純度還是熵上的表現都優于其它方法,特別是與直接使用LDA相比,算法性能得到明顯提升,說明S3C算法是有效的;②K-means算法、Agglomerative算法和LDA模型在基于語義稀疏服務聚類的時候性能并不好,說明傳統算法在語義稀疏的環境下容易遭受相似度計算困難的問題,進一步驗證了文獻[6]結論的正確性。實驗結果說明,基于BTM的方法在語義稀疏的情境下進行服務聚類的優勢,也進一步說明在聚類中考慮語義稀疏的必要性。
3.2.2 參數影響
主題個數K的選取是影響主題模型性能的重要因素。本文采用基于貝葉斯模型[17]選擇方法,確定本文所用實驗數據的主題數目。在不同K值下運行Gibbs抽樣算法,觀測[log(P(w|K))]變化情況。具體實驗結果如圖4所示,當主題數目K=200時,后驗概率能夠得到最好性能,主題模型對于給定數據取得最佳擬合度。因此,S3C中主題個數K的取值選取為200。同時,S3C中對BTM超參數設定選擇文獻[16]中設置的[α]=50/K,[β]=0.01。
4 結語
本文基于BTM提出了一種面向語義稀疏的服務聚類方法S3C,使用公開服務注冊中心Pweb真實數據進行相關實驗,驗證基于BTM的語義稀疏服務聚類方法的可行性和有效性[18]。與經典的服務聚類方法進行對比,S3C方法在聚類純度、熵等方面均具有更好的聚類效果,從平均純度看,該方法達到0.68,比其它方法提升30%左右;從平均熵看,該方法降低到0.41,性能提升50%左右。下一步研究重點:①在語義稀疏服務聚類的基礎上研究面向領域的服務發現技術[19-20];②研究推薦與發現相結合的服務發現方法[21-22],提升服務發現過程中的個性化程度。
參考文獻:
[1] Al-MASRI E, MAHMOUD QH. Investigating web services on the World Wide Web[C]. Proceedings of the 17th International Conference on World Wide Web,2008:795-804.
[2] ELGAZZAE K, HASSAN A.E and MAERIN P. Clustering wsdl documents to bootstrap the discovery of web services[C]. Proceedings of 2010 IEEE International Conference on Web Services (ICWS), 2010: 147-154.
[3] WU J, CHEN L, ZHENG Z. Clustering web services to facilitate service discovery[J]. Knowledge and Information Systems, 2014, 38(1):207-229.
[4] AZNAG M,AUAFAFOU M,JARIR Z. Leveraging formal concept analysis with topic correlation for service clustering and discovery[C]. Proceedings of 2014 IEEE International Conference on Web Services (ICWS),2014:153-160.
[5] CAO B, LIU X F, RAHMAN M, et al. Integrated content and network-based service clustering and Web APIs recommendation for mashup development[J]. IEEE Transactions on Services Computing, 2020, 13(1):99-113.
[6] TANG J, WANG X,GAO H. Enriching short text representation in micro-blog for clustering[J]. Frontiers of Computer Science, 2012, 6(1):88-101.
[7] SHU Z, XIE S,LI Q. Single-phase back-to-back converter for active power balancing, reactive power compensation, and harmonic filtering in traction power system[J]. IEEE Trans. Power Electron, 2011, 26(2):334-343.
[8] AGARWAL N, SIKKA G, AWASTHI L K. Enhancing web service clustering using length feature weight method for service description document vector space representation[J].Expert Systems with Applications,2020:113682.
[9] CHEN L, HU L, ZHENG Z, et al. Wtcluster: utilizing tags for web services clustering[C]. International Conference on Web Services, 2011:91-98.
[10] JINBO X, JUN R, LEI C, et al. Enhancing privacy and availability for data clustering in intelligent electrical service of IoT[J]. IEEE Internet of Things Journal, 2018: 1-5.
[11] SKOUTAS D,SACHARIDIS D.Ranking and clustering web services using multi-criteria dominance relationships[J].IEEE Transactions on Services Computing, 2010, 3(3):163-177.
[12] CAO J, WU Z,WU J. SAIL: Summation-based incremental learning for information-theoretic text clustering[J].IEEE Transactions on Cybernetics,2013, 43(2):570-584.
[13] CASSAR G,BARNAGHI P,MOESSNER K. Probabilistic methods for service clustering[C].Proceedings of the 4th International Workshop on Semantic Web Service Matchmaking and Resource Retrieval, 2010,99: 1-4.
[14] CHEN L, WANG Y, YU Q, et al. WT-LDA: User tagging augmented LDA for web service clustering[C].Proceedings of? Service-Oriented Computing,2013:162-176.
[15] 李征, 王健, 張能, 等.一種面向主題的領域服務聚類方法[J].計算機研究與發展, 2014, 51(2):408-419.
[16] CHENG X,YAN X, LAN Y, et al. BTM: topic modeling over short texts[J]. IEEE Transactions on Knowledge and Data Engineering, 2014,26(12):2928-2941.
[17] ROSEN-ZVI, GRIFFITHS T, STEYVERS M, et al. The author-topic model for authors and documents[C]. Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence,2004:487-494.
[18] ZHANG N, WANG J, HE K, et al. Mining and clustering service goals for RESTful service discovery[J]. Knowledge and Information Systems, 2019, 58(3):669-700.
[19] 陳婷, 劉建勛, 曹步清. 基于BTM主題模型的Web服務聚類方法研究[J].計算機工程與科學, 2018, 40(10): 25-33.
[20] HE Q, ZHOU R, ZHANG X, et al. Keyword search for building service-based systems[J]. IEEE Transactions on Software Engineering, 2017(b):658-674.
[21] ZHANG N, WANG J, HE K, et al. Mining and clustering service goals for RESTful service discovery[J]. Knowledge and Information Systems, 2018, 58(5):1-32.
[22] DING F, WEN T, REN S, et al. Performance analysis of a clustering model for QoS-aware service recommendation[J]. Electronics, 2020, 9(5):740.
(責任編輯:孫 娟)
收稿日期:2020-09-20
基金項目:湖北省自然科學基金面上項目(2020CFB807);湖北省教育廳科學技術研究計劃重點項目(D20201402);湖北工業大學高層次人才科技啟動基金項目(337396)
作者簡介:胡文生(1975-),男,博士,湖北工業大學計算機學院講師,研究方向為人工智能與大數據;謝芳(1981-),女,博士,湖北工業大學計算機學院講師,研究方向為智能計算與軟件工程。本文通訊作者:謝芳。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
今日農業(2019年12期)2019-08-15 00:56:32
當代陜西(2019年10期)2019-06-03 10:12:04
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商周刊(2017年9期)2017-08-22 02:57:56
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
