可學習的硬性滲出病變點標注方法
2020-01-14 09:51:50劉蒙蒙高穎琪
小型微型計算機系統 2019年12期
劉蒙蒙,郭 松,高穎琪,李 濤,2
1(南開大學 計算機學院,天津 300350)2(天津市網絡與數據安全技術重點實驗室,天津 300350)
1 引 言
眼底是眼球內后部的組織,即通常所說的視網膜,眼底圖像是使用眼底相機獲取的視網膜圖像,包括視網膜、視杯、視盤、黃斑以及視網膜動靜脈等.眼底檢查的結果可以反映許多全身性疾病如高血壓、腎病、糖尿病等疾病,眼底圖像是重要的診斷資料.隨著糖尿病、青光眼等多種疾病的發病率不斷增加,對眼底圖像的定期篩查已經成為預防患者失明的重要手段,目前對視網膜圖像的分析篩查主要依靠眼科醫生的肉眼觀察,以此來判斷患者眼部的病變程度,但是日益增加的患者數量對于眼科醫護人員帶來巨大的挑戰[1].
計算機輔助診斷工具為眼底圖像的篩查提供了新的思路,輔助診斷工具可以降低主觀誤診的因素,幫助臨床經驗不足的眼科醫生進行診斷,輔助診斷信息提高了臨床診斷的準確率,減少了診斷決策的時間,大大提高了醫護人員的工作效率.當前計算機輔助診斷的方法研究是基于大量標注眼底病變點的眼底圖像展開的,主要通過對病變點的分割與檢測結果進行評估,獲得診斷結果.目前關于眼底病變點分割的公開數據集包括DDR[2]、IDRiD[3]、e-ophtha_EX[4]、e-ophtha_MA[4]、ROC[5]、HEI-MED[6]等幾個數據集,表1中列出了上述四個數據集的圖片數量和所標注的病變點的種類.
這些對眼底病變點進行像素級標注的數據集,眼底圖片數量共計近千張,但這個數據量相較于深度學習的分割模型或相關診斷工具的研究需求,存在“相當大”數量級的差距.為了打破數據集對病變點分割與檢測研究的局限,必須對大量眼底圖像進行精確的標注,需要耗費大量的人力和時間,且對標注人員的專業素質要求較高.目前,眼底圖像主要用于糖尿病性視網膜病變(diabetic retinopathy,DR)的篩查,而硬性滲出是DR早期階段的顯著特征,因此硬滲是計算機輔助診斷工具的重要檢測對象,是DR篩查的重要環節.眼底病變中的硬性滲出具有數量不定、形狀不規則的特點,且眼底圖像背景復雜,需要一種適應眼底圖像場景的標注方法,能夠快速地標注硬滲區域的不規則輪廓.

表1 眼底病變點分割數據集Table 1 Datasets of fundus lesions segmentation
全自動的分割算法在對眼底圖像進行分割時,難以自動獲取目標,存在提取邊緣不理想的不足[7].因此本文設計了一種可學習的硬性滲出病變點標注方法,加入可學習的分割算法,對眼底圖像中的硬性滲出進行逐像素的標注.在標注過程中,包括人的鑒別過程,將其標注的結果加入分割算法并訓練分類器,使分割算法具有學習能力,標注區域是基于可學習的分割算法獲得的.標注方法的優勢在于由分割算法獲得疑似區域的輪廓,由分類器鑒別疑似區域,減少用戶標注一個硬性滲出區域的點擊時間,最終用戶能快速完成對不規則滲出區域的標注.
2 相關工作
基于眼底圖像的計算機輔助診斷工具主要有兩種評估方法,一是評估視網膜血管的形態學特征,二是檢測各類特異性的眼底損傷并進行分類和計數,后者對糖尿病性視網膜病變的診斷和分期有重要意義,眼底病變的數量和面積為眼科醫生提供有效的輔助診斷信息,換而言之,眼底病變點分割的算法研究與計算機輔助診斷工具的發展息息相關.
基于深度學習的眼底圖像分割算法近來得到了迅猛發展.在眼底結構和病變點分割方面,深度學習算法也表現出優異的性能.Pavle等人使用深度卷積神經網絡對眼底滲出物進行分割,并結合滲出物位置的高水平解剖學特征,獲得了比傳統方法更優異的分割結果[8].Feng 等人提出的可檢測眼底圖像中視盤和滲出的網絡結構,獲得了較之前方法更準確的分割結果[9].Juan等人利用深度學習網絡分割滲出物的靈敏度達到了0.9227,對比傳統方法在多個評估指標上性能均有很大提高[10].Jen等人提出的10層卷積網絡可以同時分割滲出物,出血和微動脈瘤,其對滲出物的靈敏度達到了0.8758[11].Guo等人設計的小目標分割網絡可以同時分割四種病變,在多個數據集表現優異,對于四種病變的靈敏度均超過了國際眼底競賽的最好成績[12].
關于眼底圖像滲出區域的分割問題研究,Sopharak等人提出了基于模糊C均值(FCM)聚類分割滲出物的方法,獲得了較高的敏感性和準確度[13].Worapan等人改進了迭代圖形分割的算法,由監督學習的方法識別具有高可信度的種子,繼而進行迭代,這種方法具有很強的魯棒性[14].此外也有人使用一些非機器學習的方法對滲出區域進行分割,即通過手動設計特征和分類規則處理眼底圖像.Jaskirat等人提出的動態閾值的分割方法,在多個數據庫上獲得了平均0.8885的特異性,具有泛化能力和較強的候選能力[15].Welfer等人基于形態學在DIARETDB1上敏感度達到了0.7048[16].Imani等人基于形態學成分分析算法和動態閾值,結合血管的分割結果檢測滲出,在多個數據集上達到了優異的效果[17].Li等人利用主成分分析法建立主動形狀模型,區域生長和邊緣檢測的方法達到了100%的靈敏度和0.71的特異性[18].Sinthanayothin等人使用遞歸區域增長分割算法分割滲出靈敏度為0.88,特異性為0.997[19].
結合深度學習的眼底病變點分割算法,需要大量像素級標注的眼底圖像,而當前常用的標注工具如LabelMe[20]、LabelImg等,其標注方法都是依靠人力選擇標注區域并添加標簽,標注形式主要分為矩形標注和多邊形標注.矩形標注速度較快,但是精度不高,多邊形標注提高了精度,但需要用戶進行多次點擊,耗費大量的時間.眼底病變點微小、且多為不規則形狀,矩形標注很難用作語義分割任務,而使用多邊形對病變點進行標注的時間成本過高,因此通用標注工具的標注方法和形式在速度和精度上都難以適應眼底圖像病變點標注的應用場景.
3 可學習的標注方法
可學習的標注方法,顧名思義是一種具有學習能力的方法.標注方法中的分割算法學習用戶的標注,將保存的最終標注結果作為訓練集樣本訓練分類器;用戶只需簡單校正標注結果即可得到滿意的結果.由于分類器的存在,分割算法的性能逐漸提高標注過程中用戶校正的區域會逐漸減少.
標注工具的學習能力源于分割算法中的增量學習分類器,標注工具基于用戶的標注結果獲取新的病變點樣本,通過增加訓練樣本集數量來提高分類器對硬滲的鑒別能力.標注工具包括界面以及可學習的分割算法,本節將重點介紹可學習分割算法的原理,分割算法結合了形態學處理與機器學習,由形態學運算獲得疑似病變點區域,然后使用分類器對疑似區域進行分類,判斷候選區域是否為硬性滲出區域.算法將分割結果返回至界面進行顯示,并從界面獲得新的樣本,用于訓練分類器.
3.1 形態學處理
眼底圖像的背景復雜,眼底圖像存在光照不均勻、對比度小的問題,造成眼底圖像的細節丟失,這些噪聲顯著影響了分割結果的準確性.通過比較眼底圖像的三個顏色通道如圖1所示,綠色通道保留了最多的細節,選取綠色通道進行算法分割可以獲得更好的分割結果.對眼底圖像進行圖像增強可以增強局部對比度并突出滲出區域,從而獲得更好的分割結果,本文采用的是限制局部對比度的CLAHE方法[21].
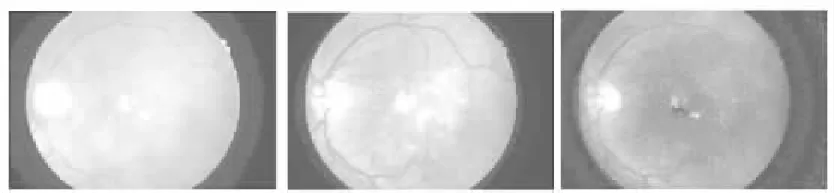
圖1 RGB三通道對比圖Fig.1 Contrast between three RGB channels
形態學處理中的開運算是一個基于幾何運算的濾波器,是用于去除圖像噪點的圖像處理方法,開運算實際上就是一個先腐蝕后膨脹的過程[22].公式如下:
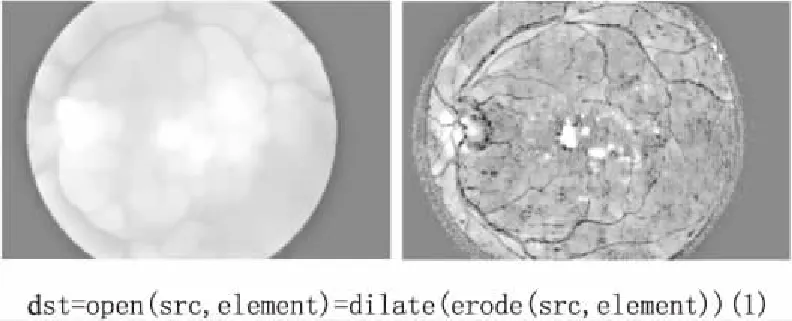
圖2 眼底圖像的背景圖(左)和較亮區域(右)Fig.2 Background(left)and bright area(right)of fundus image
開運算可以移除圖像中的小斑點,平滑較大區域的邊界,同時不會明顯改變各個區域的面積,而滲出區域一般是眼底圖像中的小斑點,開運算可以有效地移除滲出區域,對分割滲出區域有較為滿意的效果.如圖2所示,對眼底圖像作開運算處理,移除眼底圖像中的斑點,即獲得圖像的背景圖.將綠色通道圖與背景相減,獲得兩幅圖像的不同之處,即比周圍背景亮度更高的區域,也就是可能為滲出的區域.對結果進行閾值分割,獲取可能的滲出候選區域.

圖3 不同尺寸結構元素的分割結果Fig.3 Segmentation results of different size structural elements
在上述處理過程中,開運算過程中結構元素的選取會顯著影響分割結果.要獲得較好的分割結果,須選取合適大小和形狀的結構元素.選取各向同性的圓形作為結構元素,可以排除滲出區域的方向因素的干擾;結構元素的尺寸影響檢測出的滲出區域的效果,結構元素偏小時,分割較大的滲出區域會造成丟失,結構元素偏大對距離較小的滲出區域造成粘連的效果.如圖3所示,從左到右是選取合適的結構元素、結構元素偏小、結構元素偏大時的分割結果.
3.2 連通區域檢測
經過形態學處理,算法獲得硬性滲出的候選區域.眼底的硬性滲出是眼底圖像中較為明亮的形狀不規則的斑點,不同的硬滲區域不存在連通性且較為獨立,而通常一個連通區域中的像素點的類型相同,沒有必要對這個區域內的像素點進行逐像素分類.為了加快對整幅圖像的分類速度,本文棄用了對圖像中所有的候選區域做逐像素分類的方案,而是選擇將每一個連通區域作為分類的一條數據可以有效加快對候選區域的分類速度.如圖4所示,展示了對步驟①結果圖像檢測出的部分連通區域,一些十分微小的區域未舉例.
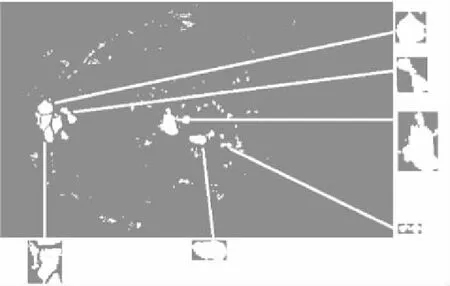
圖4 連通區域檢測結果Fig.4 Connected area detection results
3.3 增量學習分類器
形態學處理獲得的候選區域是灰度值高于周圍像素點的區域.視盤是一個近似圓盤的明亮區域,血管是眼底圖像中的較暗區域,因此視盤或相距很短的兩條血管之間的區域都是疑似硬滲的區域.在分割算法中加入分類器完成對候選區域的鑒別,得到新的滲出候選區域,分類器可以提高分割算法的準確率.滲出的形狀和大小均不統一,因此選擇眼底圖像綠色通道的灰度均值和候選區域所有像素點的紅綠藍通道的三個平均值作為分類特征.
增量學習是一個不斷引入增量訓練集的學習過程[23],KNN算法是一種思想簡單且準確度高的算法,在訓練集較大時具有良好的分類能力,本文選擇了KNN算法作為分類器.KNN的分類過程是選取與當前數據最相似的K個樣本,由K個樣本共同決定這條數據的類別,每一個連通區域都是一條待分類的數據,將滲出區域的特征送入KNN分類器,判斷該區域是否為滲出.標注工具獲得自動分割算法的候選滲出區域向用戶展示,用戶可以對分割結果進行校正,用戶接受的分割結果產生新的樣本,擴充分類器的訓練集,新樣本對下一次的分類結果產生影響.
分類器的訓練樣本由用戶的標注產生,這意味著隨著用戶標注的眼底圖像的增加,分類器的訓練集將逐漸增加,眼底圖像標注場景的特殊性在于,眼底圖像的質量彼此之間差別較大,會受到拍攝相機、光照分布、拍攝距離和角度的影響,因此分類器的分類效果與訓練集數量密切相關,增量數據集具有在一定范圍內提升分類器的準確率的能力.
3.4 算法概述
可學習的分割算法的流程圖如圖5所示,前幾節已經介紹了分割算法中的每個處理過程,本節對分割算法的流程做簡要總結.
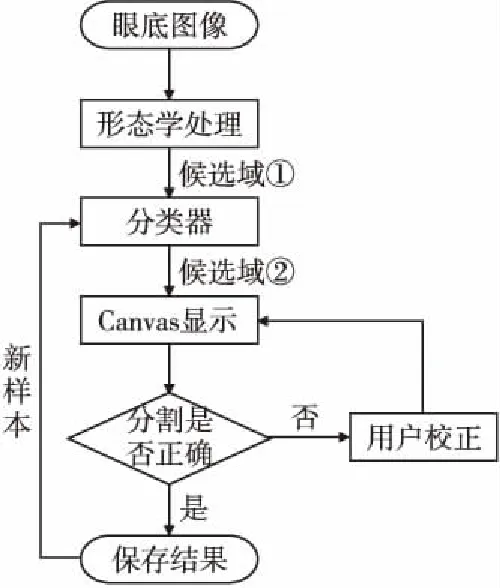
圖5 分割算法的流程圖Fig.5 Flow chart of the segmentation algorithm
分割算法中的輸入是待標注的眼底圖像,第一步取眼底圖像的綠色通道經過形態學處理獲得硬滲區域的候選域①,第二步提取候選域①中的連通區域的特征送入分類器,根據分類器的分類結果獲得候選域②.用戶對候選域②中的滲出區域進行鑒別,標注過的圖片生成新的正負樣本更新分類器.

表2 分割算法的偽代碼Table 2 Pseudocode of segmentation algorithm
分割算法的偽代碼說明了算法的流程,如表2所示.
4 實驗與結果分析
本節對實驗結果進行綜合測評與分析,實驗中采用的平臺為:Intel? Xeon? W-2102,CPU @2.90GHz,操作系統為Microsoft Windows10(64位),使用Python 3.7解釋執行.此標注工具的界面是基于Python語言GUI編程解決方案PyQt[24]實現的.
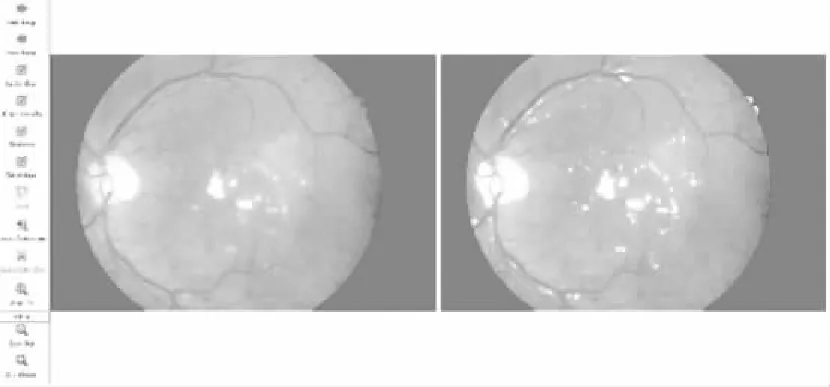
圖6 分割結果的界面展示Fig.6 Segmentation result showedon GUI
用戶可以通過工具界面選擇標注的眼底圖像,校正自動分割結果.標注工具提供讀取、展示眼底圖像及分割結果的功能,將用戶的分割結果保存生成標注文件.標注工具的界面如圖6所示,左側為工具欄,右側是兩個顯示區域分別顯示原圖和自動分割算法給出的滲出候選區域.
4.1 數據集
為了測試分割算法的性能,本文選取了一個對滲出區域進行逐像素標注的數據集.IDRiD(IndianDiabeticRetinopathyimageDataset),這個公開數據集是由印度糖尿病視網膜病變圖像構成的,是印度人的第一個典型數據庫,它是在像素水平上對構成典型糖尿病視網膜病變的病變點和正常視網膜結構進行標注的數據集.該數據集提供了關于糖尿病性視網膜病的疾病嚴重性和每個圖像的糖尿病性黃斑水腫的信息,這使其非常適合用于早期檢測糖尿病視網膜病變的圖像分析算法的開發和評估.本文使用IDRiD數據集中的54張圖片及其滲出區域的真值標注結果作為實驗樣本的評估標準.
4.2 分割算法的性能評估
根據形態學分割結果,數據集中的54張圖片共有5708個候選域,其中正樣本的數量為1220個,其余為負樣本.從數據集中選取8張圖片作為測試集,在剩余圖片中選取不同數量的圖片作為訓練集,對分割算法的分割結果做評估.
如圖7所示,增加訓練集圖片,分割算法對同一張圖片的分割結果與Label的直觀對比:

圖7 分割算法結果對比Fig.7 Comparison of the segmentation algorithm result
對硬性滲出做分割時,眼底圖像分為滲出區域和背景區域,為了定量比較算法的分割結果與滲出的真值之間的差異,引入四個量化統計的指標:①真陽性(true positive,TP)表示預測為滲出且預測正確的像素點;②真陰性(true negative,TN)預測為背景且預測正確的像素點;③假陽性(false positive,FP)預測為滲出但預測錯誤的像素點;④假陰性(false negative,FN)預測為背景但預測錯誤的像素點.表2列出了訓練集圖片數量不同時,分類器對測試集圖片的分割結果,本文使用了召回率(Recall)、特異性(Specificity)、準確率(Accuracy)和精度(Precision)評估分割算法的結果[25].計算公式如表3所示.

表3 分割指標計算公式Table 3 Formula for calculating variables
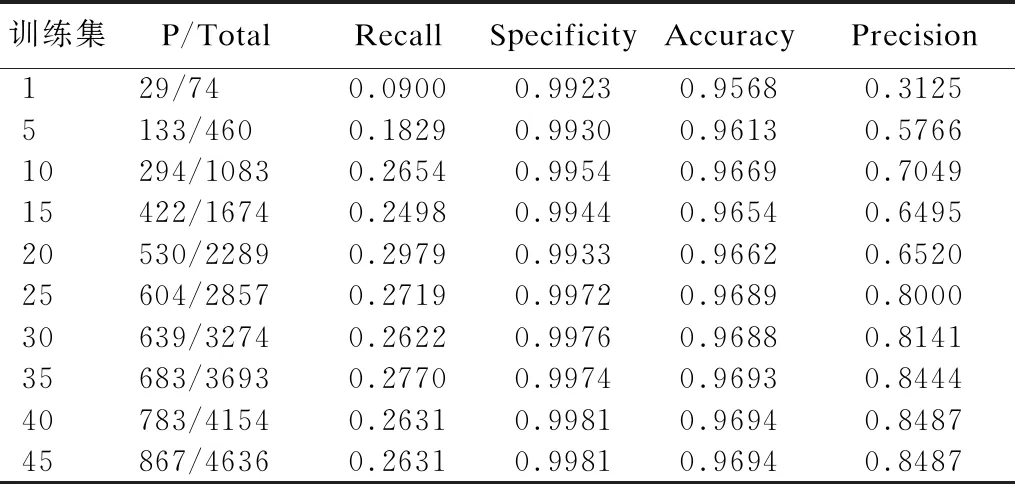
表4 不同尺寸訓練集的分割結果評估Table 4 Evaluation of segmentation result with different size dataset
召回率表示分割算法檢測出的正確硬性滲出區域占實際硬滲區域的比例,精度表示檢測出的滲出區域中正確預測的比例.表4列出了訓練集數量不斷增加時的分割結果評估,實驗結果顯示了在標注圖片數量增加的情況下,分割結果的召回率逐漸增加并趨于穩定,精度不斷增加并逐漸趨于穩定,這表示分類器的分類能力隨訓練集的數量增加而提高,分割算法的性能隨之增加,這個過程體現了分割算法的可學習能力.
由于開運算的結構元素的尺寸的限制,形態學處理獲得的滲出候選域①,對于區域面積超過視盤的滲出區域的檢測效果并不理想,該滲出區域較為明顯易于人工標注,且這種情況在眼底圖像中并不常見,因此本文忽略了該種情況.
5 結束語
本文通過分析眼底圖像標注場景中的特點,提出了一種基于分割結果的標注方法,分割算法是由形態學處理和機器學習結合的分割算法獲得的結果,可以快速獲得硬性滲出區域,用戶僅需簡單的點擊就能校正并完成高精度的標注操作.這種分割算法通過硬滲的亮度特征獲得不規則的邊界,跳過用戶創建多邊形的標注過程,節省了多次鼠標點擊操作,提高了標注速度;而分割算法中的分類器進一步提高了分割算法的正確率,減少用戶的校正操作,進一步減少用戶標注的時間.實驗結果表明,分割算法隨著增量訓練集的增加提高預標注結果的準確率,這一算法獲得較高準確率的同時,用戶只需判斷區域內分割結果的正確性就能完成一個不規則區域的標注,提高了標注效率.進一步的研究工作可以使用更復雜的分類器替換本文選擇的KNN算法,獲得更高的準確率.
猜你喜歡
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
創業家(2015年5期)2015-02-27 07:53:25
