基于基址重定位的快速域名壓縮算法①
2020-01-15 06:45:02閆夏莉呂萬波張海闊岳巧麗
計算機系統應用 2020年1期
關鍵詞:資源
閆夏莉,王 騫,呂萬波,張海闊,岳巧麗,曹 爽
1(中國互聯網絡信息中心,北京 100190)
2(國家稅務總局 電子政務管理中心,北京 100053)
DNS (Domain Name System)主要用于承載域名與IP地址之間的轉換,是互聯網的關鍵基礎設施之一.權威域名服務器的性能一直是DNS的研究重點之一.在面向DNS服務器性能的參數中,平均響應時間是重要評價指標,也是用戶感受服務器性能的主要體現.近年來性能測試中又引入了響應時間百分比,即響應時間小于期望時間的概率百分比來進一步度量和表示其性能,以期為用戶帶來更好的體驗[1,2],這也是本文研究的重要性能參數.真實的響應時間包括網絡傳輸時間、服務器處理時間等,用戶的網絡狀況千差萬別,因此本文研究的重點是提升服務器處理時間的百分比.
本文提到的DNS服務器特指權威域名服務器,其查詢請求可分為兩類.一類是針對特定資源記錄RR(Resource Record)的查詢,如A記錄、NS記錄查詢等,查詢結果返回相應的資源記錄,在本文中用“常規查詢”表示.另一類為IXFR[3]/AXFR[4](Incremental Zone Transfer/Authoritative Zone Transfer)查詢,用于主從服務器間的數據同步,查詢結果返回區域數據中變化的資源記錄甚至完整的區域數據,該過程稱為增量/全量區域數據傳送.以根服務器為例,全球共13臺根服務器及其鏡像服務器支撐根區數據解析服務[5].各服務器及其鏡像通過全量區域數據傳送來保障根區數據的一致性[6].
為了提高響應時間百分比,有必要先確定其性能瓶頸,進行針對性的優化.在本文中,為了避免盲目的優化,首先建立了基于排隊論[7]的數據模型,將DNS服務器抽象為一個M/M/c的隨機服務系統,并依據此模型對響應時間百分比進行了分析,確定性能瓶頸之后,對DNS的數據特征進行了分析,并結合基址重定位技術提出改進算法.最后對提出的改進算法進行實驗和性能評測.
1 DNS服務器的數學模型
1.1 模型描述
排隊現象由兩方面構成,一方請求服務,另一方提供服務.顧客通過排隊服務系統要依次經過如下過程:顧客到達、排隊等待、接受服務和離去.DNS服務器的查詢應答過程符合排隊服務系統的規律.服務器收到來自各客戶端的查詢,請求按一定的速率到達,經服務器解析返回應答包.DNS服務器可以是單個服務臺,也可通過SO_REUSEPORT機制,將多個套接字綁定在同一個端口實現多個服務臺.
假設DNS服務器為M/M/c隨機服務系統,模型如圖1所示.該系統具有以下性質:(1)查詢請求為單個到達,到達的時間間隔符合參數λ的泊松分布;(2)每個請求所需的服務時間獨立,服從μ的負指數分布(忽略常規查詢與IXFR/AXFR查詢的應答差異);(3)系統有c(c≥1)個服務臺,服務的順序按照先來先服務FcFs(First come First served)規則;(4)系統容量為N(N>c,緩沖隊列長度為N-c),請求源無限;(5)如果請求到來時隊列已經被占滿,則出現丟包,否則進入隊列等候.
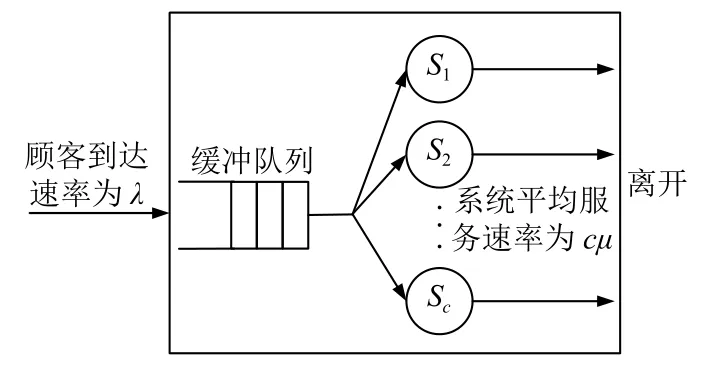
圖1 M/M/c隨機服務系統模型
表1顯示了建模過程用到的數學符號及相關說明.其中系統負荷強度為本文只考慮穩定平衡狀態( ρ<1)的情況.

表1 DNS服務器數學建模符號說明
1.2 性能瓶頸分析
服務器對查詢請求的響應時間Ws為請求等待時間Wq和解析時間之和.響應時間百分比γ %可表示為其中為用戶期望時間.下面將分別針對單服務臺模型和多服務臺模型分析響應時間百分比的分布概率.
1)c=1時,為M/M/1排隊模型.
根據參考文獻[8],有:

或者
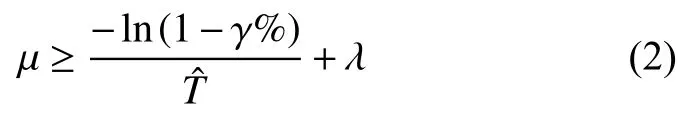
對于DNS服務器,如果不通過流量控制等策略進行人工干預,請求到達速率λ為不可控因素.為了分析的方便,在此假設λ不變,用戶期望時間也不變.根據式(2)可知,響應時間百分比 γ %隨著解析速率μ的增加而增加.
2)c>1時,為M/M/c排隊模型.
查詢請求到達時,如果緩沖隊列已滿,新的請求無法響應,服務器出現丟包,此時的概率稱為損失概率.由參考文獻[8]可知,損失概率與緩沖隊列長度有關,增加緩沖隊列的長度可降低損失概率.為了分析的方便,本文重點討論沒有請求損失的場景.因此,可假設緩沖隊列的長度無限大,推導出響應時間的分布函數[7]為:
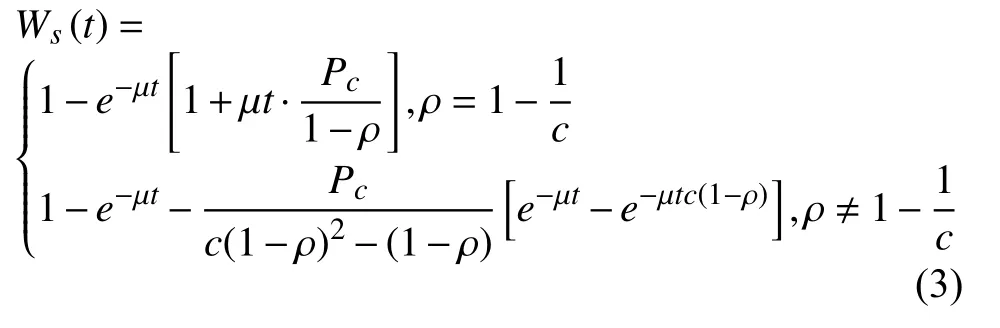
其中,
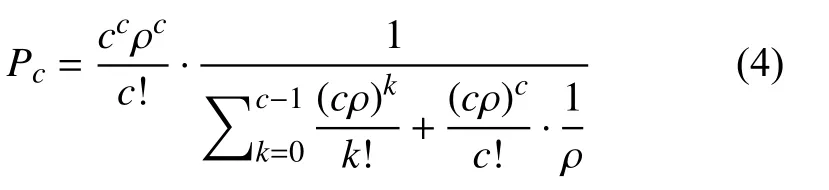
由上述公式可知,在請求到達速率λ不變的情況下,響應時間與服務臺數量c和解析速率μ有關.DNS服務器實現多服務臺處理查詢請求的原理是提高了多核CPU的利用率,多服務臺的數量與CPU數量相關.考慮到運行成本,增加多服務臺數量的方式不作考慮.在服務臺數量固定的情況下,需要通過提高解析速率μ,來優化響應時間百分比.
查詢請求的解析過程依次為:接收請求、解壓縮請求包、查找匹配資源記錄、組裝應答包、域名壓縮和發送應答包.解壓縮請求包和組裝應答包規則簡單,耗時少,在此不做討論.而數據包的接收發送依賴于網絡通信框架,查找匹配資源記錄依賴于數據結構和查找算法,改進這兩個過程成本較高.因此本文將對域名壓縮算法進行針對性優化.
2 DNS域名壓縮現狀
2.1 傳統壓縮算法
為了分析域名壓縮,需要對DNS服務器的數據處理流水線進行分析,見圖2.為了分析的完整性,流水線中同時考慮了服務器的數據來源和數據出口.DNS服務器通過動態更新或區域數據傳送對本地區域數據進行更新,收到更新數據后進行解壓縮再存儲到本地.服務器收到查詢請求后在存儲數據中查找匹配資源記錄,然后對查找結果進行組裝、壓縮,最后返回應答包給請求端.對DNS服務器來說,數據更新頻率遠低于查詢請求的頻率,即大部分的查詢使用同一版本的數據進行應答.

圖2 傳統DNS數據處理流程圖
域名壓縮通過減少DNS數據中域名的冗余來降低帶寬占用.不論是常規查詢應答或IXFR/AXFR查詢應答,其出口帶寬大于入口帶寬,尤其是AXFR查詢應答,這種差異更加明顯.以根區的全量區域數據傳送為例,數據包共包含2萬多條資源記錄.而CN、COM等頂級域的資源記錄總數則達到了千萬數量級,域名壓縮的重要性可見一斑.域名壓縮算法直接影響著解析性能.
傳統域名壓縮算法衍生于LZ77[9].該算法基于數據本身包含有重復的字符序列這個特性,使用指針來代替已經出現過的字符序列來達到壓縮的目的.域名壓縮利用指向數據包中已經出現過的域名的指針來代替整個域名或者部分域名[10].該壓縮算法的壓縮比高,但壓縮過程耗時,主要消耗在域名的匹配過程[11].在高查詢量場景下,在解析過程進行實時的域名壓縮非常消耗系統資源.這是制約解析速率的主要原因.
2.2 改進壓縮算法
根據DNS數據的特點,域名壓縮只能采用無信息損失的無損壓縮算法[12–14].本文對無損壓縮算法進行了充分的調研[15–21],結果如表2所示,只有部分LZ77系列算法適用于DNS域名壓縮.統計編碼和字典編碼中的LZ78算法不符合DNS標準協議.
近年來LZ77算法的改進方向可大致分為兩類:一類是嘗試與其他算法結合以獲取更好的壓縮效果,如與霍夫曼編碼結合產生的DEFLATE算法等,這類改進由于結合了統計編碼同樣不符合DNS協議.另一類則通過優化數據結構和算法等方式提高壓縮效率,如LZSS,LZO等,此類算法適用于DNS,但是數據處理流程與傳統壓縮算法相比并未發生實質性變化,因而同樣無法減少資源消耗,提升解析速率.
根據上述分析,為了提高壓縮速率,可以考慮將壓縮模塊前置,將實時壓縮轉為寫時壓縮,即在數據存儲時進行壓縮處理.結合DNS服務器的特征,壓縮前置可以充分利用讀寫操作的不對稱性,提高系統資源的利用率.但是,現有域名壓縮依賴于域名位于數據包中的絕對位置,對于查詢應答,服務器無法提前預知需要回復的資源記錄,因而現有的壓縮算法無法實現壓縮模塊前置.
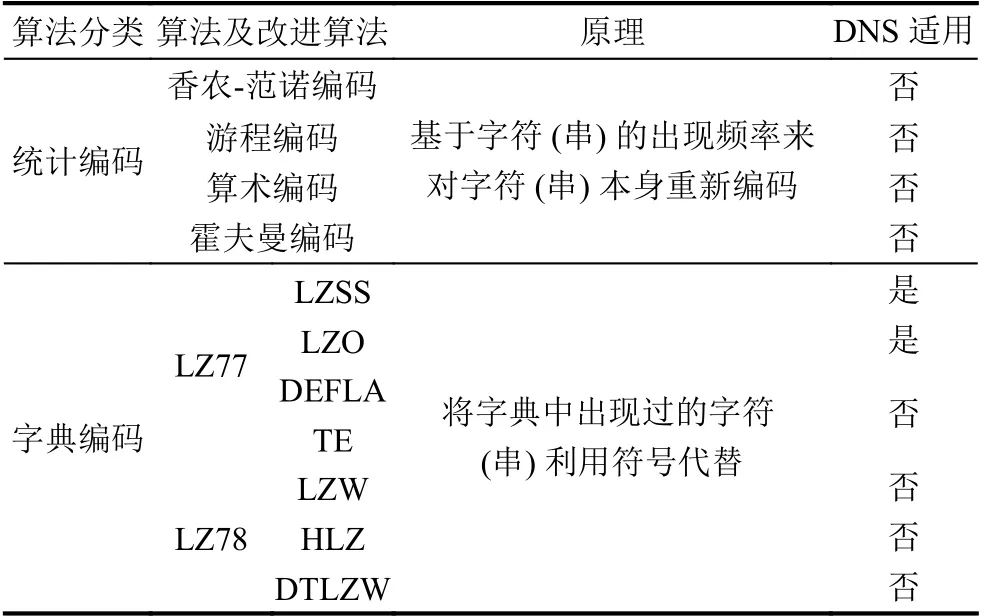
表2 常見無損壓縮算法列表
3 基于基址重定位的快速域名壓縮算法
3.1 DNS數據特征分析
為了改進壓縮算法,需要對DNS域名壓縮的原理進行分析.壓縮是基于數據的冗余度進行的減小數據存儲空間的過程[9].DNS根據域名空間倒置的樹形結構進行區域的劃分.區域數據以資源記錄為最小單位進行存儲,區域內資源記錄的所有者(owner)都是其區域頂點(zone apex)的子域[10],因此區域內的域名具有冗余性,這是域名壓縮實施的基礎.此外,DNS的資源記錄之間還有其他相關性,可以進行進一步的域名壓縮.
對權威域名服務器來說,無論是常規查詢還是IXFR/AXFR查詢,其應答包大部分情況下包含多條相關的資源記錄.這些資源記錄可能是查詢的特定類型的資源記錄,也可能是幫助請求端進一步獲取最終信息的相關記錄.AXFR查詢則為特殊情況,其應答返回了區域內的所有資源記錄.分析查詢應答結果后,發現DNS數據具有以下相關性.圖3是域名相關性示意圖.
(1)I類:相同域名,相同類型的資源記錄
DNS查詢應答包中,域名和類型都相同的資源記錄從不單獨出現,稱為RRset[10](資源記錄集合).AXFR查詢應答時也同樣如此.因而,域名和類型都相同的資源記錄具有最基本的相關性,稱為I類相關記錄.該類記錄可以進行域名壓縮.
(2)II類:相同域名,不同類型的資源記錄
IXFR/AXFR查詢應答常常包含域名相同但類型不同的資源記錄.常規查詢應答時,A記錄/AAAA記錄也常作為glue記錄[10]一同返回.部署DNSSEC[22]后,RRSIG記錄與其相關記錄也會同時返回給請求端.這些相關記錄包含相同的域名,同樣可以進行域名壓縮,稱為II類相關記錄.
(3)III類:NS記錄及其glue記錄
對大部分查詢請求來說,獲取IP地址才是其最終目的.因此,返回NS記錄時,A記錄/AAAA記錄常作為附加信息同時返回給請求端.此時,NS記錄中的授權服務器的域名(NSNAME[23])與A記錄/AAAA記錄的所有者是相同的,同樣可以進行域名壓縮.這種相關記錄稱為III類相關記錄.
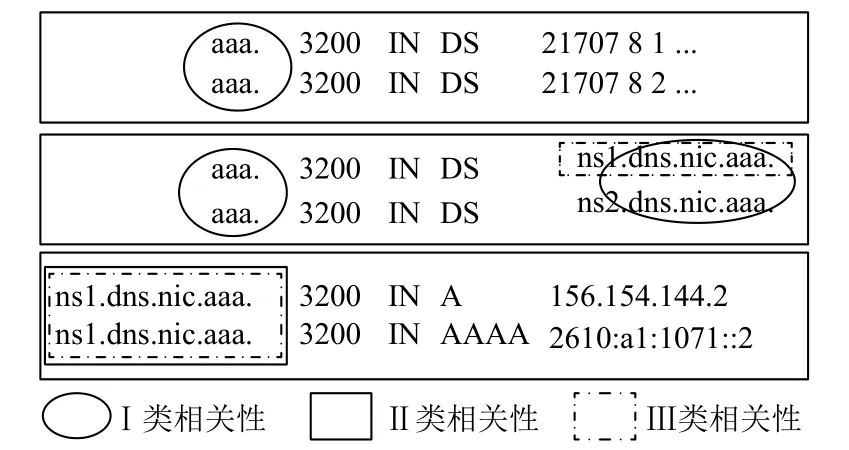
圖3 域名相關性示意圖
上述3類相關記錄中的域名是域名壓縮的主要對象.以根區數據為例,其資源記錄類型多為 NS記錄、DS記錄、A記錄/AAAA記錄.全量區域數據傳送時有82%的域名進行了壓縮,其中根據上述3類相關性進行壓縮的域名占總壓縮域名中的95%(I類、II類、III類分別占36.4%、31.6%、27%).除了上述3類相關性外,根區數據還利用了NSEC記錄中的next owner[22]進行域名壓縮,但此類壓縮不具備通用性.NSEC記錄在其他區域的數據中并不常見,通常DNSSEC部署更傾向于采用NSEC3機制[22].常規查詢應答時,利用NSEC記錄的next owner進行壓縮的可能性也很小.因此該相關性在此不做考慮.類似MX、SRV等類型的資源記錄可參考NS記錄及其glue記錄的方式實現域名壓縮,在此不再贅述.
3.2 本文改進算法
為了實現壓縮模塊前置,需要取消域名壓縮時對數據包的依賴,因此,本文在新的算法中引入了基址重定位技術.基址重定位[24]是把程序的邏輯地址空間變換成內存中的實際物理地址空間的過程.重定位表(Relocation Table)用于記錄重定位時需要修改的地址的位置(重定位入口的偏移),以便進行內存地址的修正.類似地,在域名壓縮時,可以先進行域名的相對壓縮,再利用重定位表,修正偏移量,最終完成傳統域名壓縮.
結合DNS數據特征的分析結果,本文改進算法只需聚焦于I類、II類、III類相關記錄的域名壓縮,即可保障原始壓縮比.首先,在數據更新時完成I類相關記錄中域名的相對壓縮,稱為分組壓縮.之后,在應答時無需查找,直接利用重定位表實現I類相關記錄中壓縮域名的壓縮偏移量修正以及II類相關記錄中域名的壓縮.最后實現III類相關記錄的快速壓縮,稱為關聯壓縮.運用本文改進算法后,數據處理流程圖見圖4.

圖4 本文改進算法的數據處理流程圖
本文改進算法的具體步驟如下,
(1)分組壓縮
將區域數據根據RRset、域名進行分組.對RRset中的域名進行相對壓縮,偏移量以RRset首字節為基準,并為同一域名下的所有RRset建立重定位表.重定位表在系統啟動后即可建立,并在數據更新時進行同步更新.相對壓縮結果如圖5所示.重定位表如表3所示.
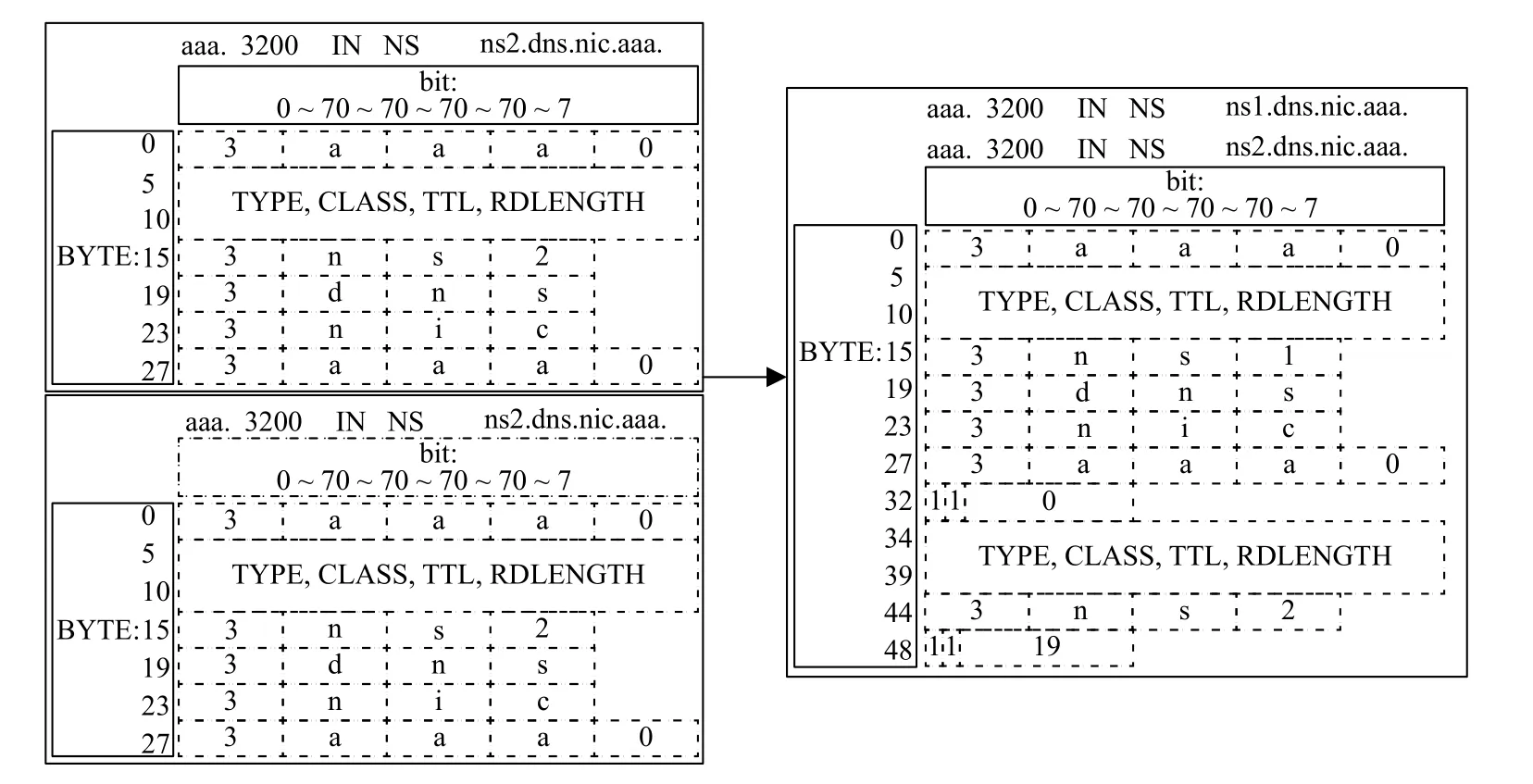
圖5 RRset相對壓縮示意圖
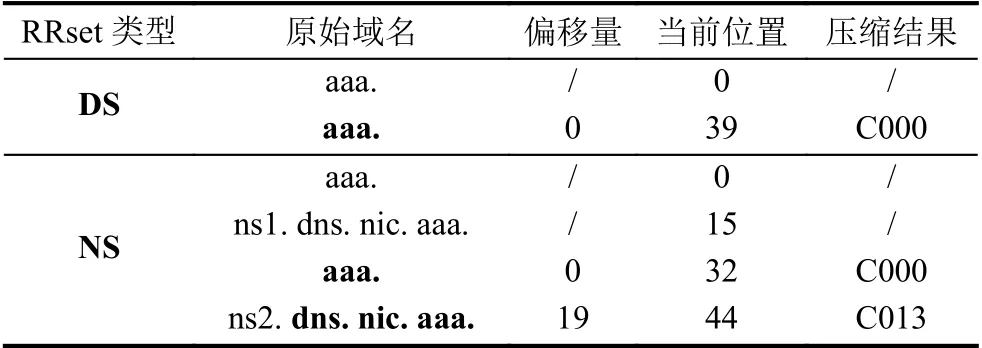
表3 重定位表
(2)利用重定位表修正壓縮偏移量
在組裝應答包的過程中,利用重定位表修正相對壓縮的偏移量.同時,完成II類資源記錄的域名壓縮.上述過程支持零查找.
(3)關聯壓縮
對于III類資源記錄,在存儲時如果不做特殊處理,無法提前完成關聯壓縮.在不改變解析軟件數據結構的前提下,可以在應答時通過動態字典實現關聯壓縮.動態字典只在應答過程建立,保存已添加的NS記錄的相關信息.在添加NS記錄或A/AAAA記錄時,通過搜索動態字典,即可完成III類資源記錄的域名壓縮.傳統壓縮算法會對應答的資源記錄中的所有域名,甚至其父域名建立字典,進行匹配域名的查找,字典量大,搜索速率低.而用于關聯壓縮的編碼字典只有少量數據,搜索速率很高.表4和表5分別是相同域名資源記錄的壓縮結果和最終壓縮結果.
4 實驗結果與分析
為了驗證本文改進算法的性能,本文使用一臺Linux服務器作為測試平臺,CPU為Intel Xeon,2*16核,單核主頻2.00 GHz.測試軟件采用BIND,上文已經闡述適合于DNS的改進算法是LZO與LZSS,LZO與LZSS相比算法復雜度更低,本文選擇LZO算法進行對比實驗.分別采用傳統算法,改進算法(LZO)及本文算法實現壓縮過程,并以根區數據為樣本進行測試.

表4 相同域名的資源記錄壓縮結果

表5 最終壓縮結果
4.1 壓縮比
壓縮比是衡量域名壓縮的重要參數.本文對常規查詢和AXFR查詢分別做了測試,分析壓縮比變化.
對于常規查詢場景,測試結果如表6所示.表中(+ED)代表DNSSEC查詢.結果表明,對于常規查詢3種算法的壓縮比相同.
對于AXFR查詢,利用根區數據進行了對比測試.采用傳統算法和改進算法,根區的全量數據共79個數據包,1341 181字節;采用本文算法時,根區的全量數據共79個數據包,1350 026字節.本文算法在全量區域數據傳送場景下,與另外兩種算法相比僅增加了0.6%的數據量.測試結果說明本文算法完全滿足DNS服務器的壓縮比實際需求.
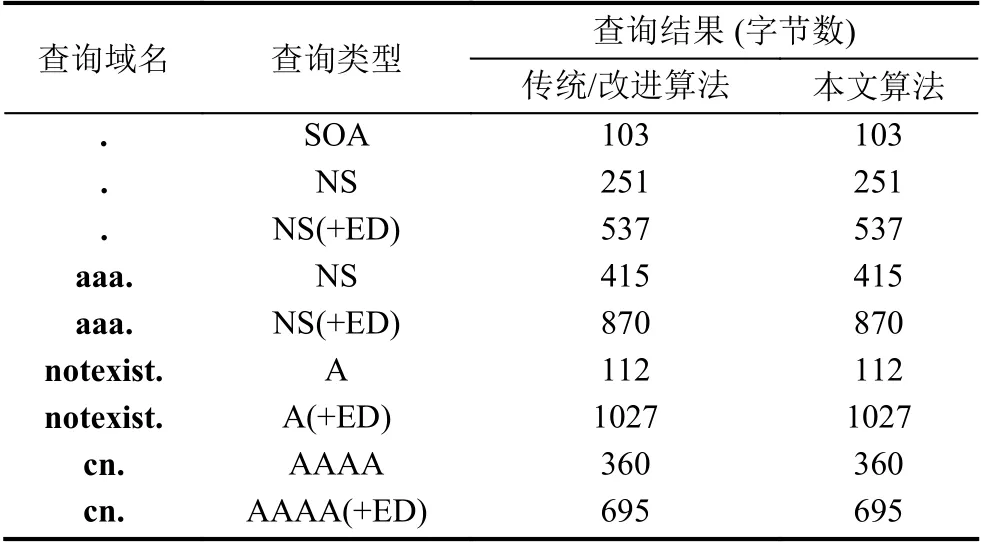
表6 壓縮比對比結果
4.2 ASL
域名查找算法對域名壓縮性能有重要影響.ASL(Average Search Length)[25]是衡量查找速率的主要標準.ASL指平均查找長度,其中查找成功的ASL指找到已有元素的平均探測次數,查找失敗的ASL指找到元素插入位置的平均探測次數.本文對4.1節常規查詢的相同場景做了ASL對比分析,結果如表7所示(“/”代表無壓縮,0代表不需要查找).
采用傳統算法和改進算法時,其字典保存了應答數據包中的所有域名及其子域名.采用本文算法時,其字典中只包含需要關聯壓縮的域名,保存的域名數要遠小于另兩種算法.由結果可知,本文改進算法減少了壓縮時查找算法的ASL,有效提高了壓縮速率.
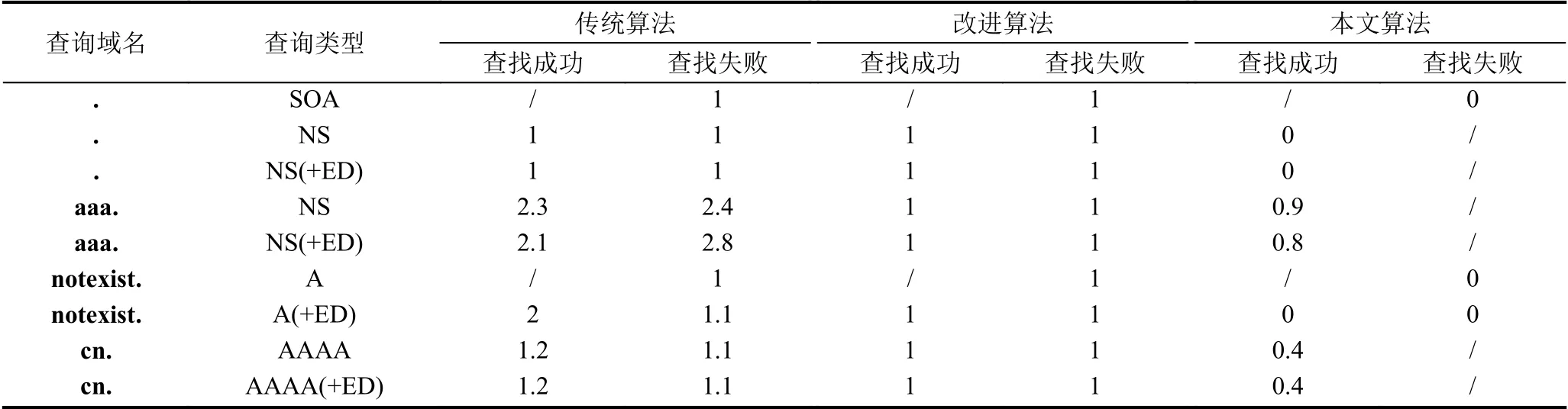
表7 ASL對比
4.3 響應時間百分比
圖6顯示了各不同查詢響應時間的百分比的測試結果對比.
與傳統算法和改進算法相比,本文的算法可以有效縮短響應時間,將90%以上的耗時控制在0.5 ms以下,而傳統與改進算法只能將90%以上的耗時控制在0.65 ms以下,只有20%的耗時分布在0.5 ms以下.采用本文算法后DNS服務器的查詢響應性能有明顯提升,達到了預期目標.
5 結論
本文基于排隊模型的分析結果,提出了一種基于基址重定位的快速域名壓縮算法.新算法充分利用了DNS服務器的數據特征,在不改變原有數據結構的前提下,通過重定位表和動態編碼字典實現快速壓縮,提高了壓縮速率.相比于傳統算法和改進算法,本文算法提高了響應時間百分比,可以為用戶帶來更好的體驗.
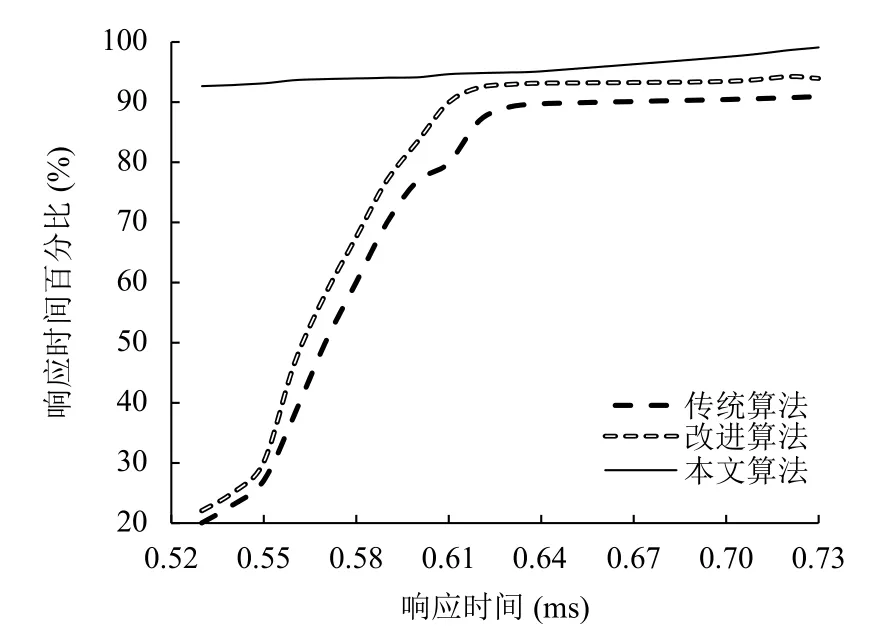
圖6 響應時間百分比對比圖
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
資源節約與環保(2022年8期)2022-09-20 02:25:22
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
藝術品鑒(2020年7期)2020-09-11 08:04:44
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
當代貴州(2018年28期)2018-09-19 06:39:04
資源再生(2017年3期)2017-06-01 12:20:59
決策(2015年9期)2015-09-10 07:22:44
