基于微博熱點發現的改進SSDKmeans算法
2020-01-16 07:39:36陳來
電子技術與軟件工程 2019年22期
文/陳來
在當前的微博平臺上,部分人認為該平臺上的數據繁多,并且存在大量雜亂無章的內容,通過對其中的關鍵資料進行整理分析,可以有效提取其中的熱點話題數據,保證了信息數據的利用率。
1 對改進SSDKmeans算法的分析
1.1 對Kmeans算法的認識
Kmeans 算法又被稱為K-均值算法,是目前信息數據處理過程中一種最為常見的劃分聚類算法,在該方法中,需要給定一個K 值作為基礎數據,在隨機從數據集中提取K 個點作為算法執行的初始中心后,再計算其他數據點與這個K 初始中心的相似度,并將其歸納到相似度最大的類簇中,并在此計算中心點。在整個數據處理環節,工作人員通過持續的迭代上述計算過程,最終會獲得一個新的聚類中心點,該聚類中心點不會變化。在這個過程中,Kmeans 算法的計算過程為:
(1)輸入若干個數據對象,將其定義為K 值。
(2)輸出K 個聚類結果;
(3)算法的步驟為:
①從若干個數據中隨機選K 個初始類簇中心點;
②對數據的歸納處理;
④再重新計算每個類的質心,計算公式為:
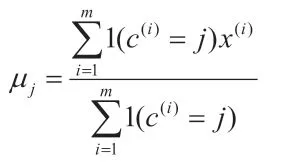
⑤聚類中心不再變化。
在上述計算公式中,K 代表事先給定的聚類數量;c(i)代表與數據點i 之間距離最近的類,取值范圍為:1-K;μj代表質心,屬于類簇的中心。
在整個數據處理過程中,Kmeans 算法獲得的聚類結果手初始值的影響,若在數據處理過程中沒有選擇到理想的初始值,或者初始值的選擇與原始聚類之間的分布存在較大的差異,這種情況將會造成算法迭代的次數快速增多,造成算法所能獲得的聚類結果存在差異,甚至出現局部最優的情況,無法滿足當前海量數據下的數據抓取要求。
1.2 改進SSDKmeans算法的技術分析
通過上述分析可以發現,在傳統Kmeans算法中的時間復雜程度不高,對于大部分的數據集合處理而言都具有良好的適應性,但是在微博熱點話題等相對復雜的數據抓取處理環節,該方法還存在一定的不足,主要表現為:
(1)在數據處理環節需要優先確定K 值。該方法在執行過程中需要先隨機選擇K 個點作為聚類劃分的標準,因此在很多的數據處理過程中可以快速的確定K 值,但是針對無法精準獲得原始簇數量的聚類問題,所選擇的K值會直接影響數據的聚類結果,甚至少部分不合理的選值會影響整個數據處理過程。
(2)在傳統的數據處理算法中,終止條件的目標函數一般為類簇中心的誤差平方和,在數據處理過程中若發現原始的數據對象之間存在明顯的區別,并且各類數據點的分布相對密集,則在數據過程中通過誤差平方就可以獲得相對滿意的聚類結果。但是在實際上類簇之間存在差異,尤其是在計算誤差平方和期間,為了能夠將誤差控制在最小,往往需要對大聚類進行分隔,并隨機選擇質心。在這種數據處理過程中,若選擇的目標函數局部極值小,那么聚類結果有可能不是全部最優解。
針對傳統數據處理方法中存在的問題,本文認為數據流在實際上屬于一種基于時間排序的特殊序列,目前淘寶、京東知名平臺在數據處理過程中都采用了數據流技術。而在這個技術下會出現一個特殊情況,即數據處理過程的頻繁項,這是指在數據集合中項的出現的次數達到特定指標的一個閾值,假設在一個數據集中存在N 個數據項,并且將支持度設定在S∈{0,1}的集合見,則這些數據項頻數達到SN 的情況下就可以歸結為頻繁項。在當前數據抓取技術中,頻繁項技術已經得到了充分的應用,尤其是結合頻繁項挖掘的SS算法,所以本文就基于這一要求提出了改進SSDKmeans 算法,該算法中通過SS 算法來完成數據流計算過程,其中的核心表達含義為:在N 個數據中若添加一個新的數據項在N 中,則對應的計數為1;若不在則可以判斷空間已經滿了,若滿了則可以替換計數最小值,否則可以將數據直接添加到數據集合D 中。
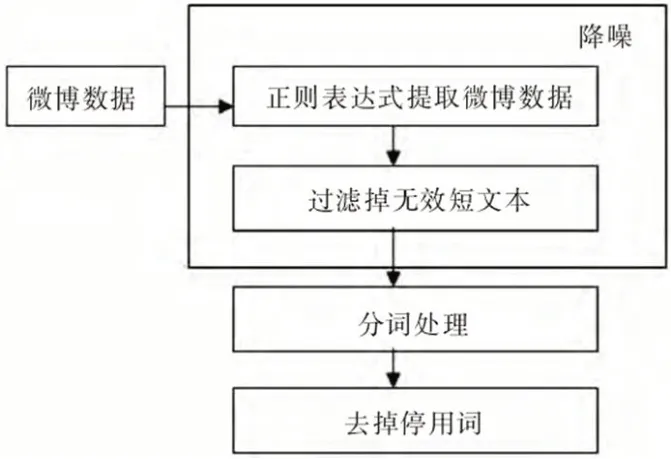
圖1:微博數據處理思路
通過上述介紹,可以判斷改進SSDKmeans算法的數據描述過程為:
(1)將數據集D 中的N 條微博記錄詞條進行采集,每個詞條的技術為ci,并輸入微博詞條。
(2)判斷替換的最小計數值e 是否在D中,若在則將f=f1+ci作為e 的統計頻數;若不在,則判斷D 空間是否已經滿了;若發現D空間沒有滿,則將<e 且大于ci的數據加入到D 中;或者查找D 中計數值f 是否滿足最小數據項em,并將其替換掉。
(3)對上一步驟中的數據集做建模,形成VSM 模型。
(4)針對最大最小距離初始m 的中心點數量,此時記錄每一條微博的內容,并將其與m 個聚類中心距離進行比較,形成基于余弦距離的(i,m)。
(5)再次識別每一條微博內容,計算獲得聚類的中心數據,保證(i)=m。
(6)評判每一條微博,若發現所有的微博文本集屬于最近的near(i)類別則終止運算,若不屬于則繼續執行。
(7)強near(i)中的i 歸納到m 中,重新計算各個中心的平均值。
2 基于改進SSDKmeans算法的微博熱點發現要求
2.1 文本聚類
在微博熱點的文本信息分析中,可以通過文本聚類的方法,將不同組別中的文檔類型進行判斷,在了解文檔類型的劃分后,選擇其中具有較高相似度的內容將其歸結到一起,這是文本聚類的主要依據。在這個過程中,文本聚類具有良好的可伸縮性,在改進SSDKmeans算法中,可以通過文本聚類的方法來保證文本信息識別的拓展性,并且這個聚類過程不需要人工干預,保證了數據處理能力。
在這種情況下,通過改進SSDKmeans 算法能夠對采集到的微博數據進行預處理,通常做法是講數學矩陣技術納入到文本中并進行整合,通過數字化的改進方法來獲得目標微博文本信息的特征項表征。在此基礎上,利用文本信息構建的VSM 模型(向量空間模型)能夠更好的識微博中各種詞條的空間向量特征,其中的表達方式為:
在上述公式中,f 代表了微博文本,t 代表特征詞條,w 為特征詞條的權重值。在這個過程中,結合微博本身的信息文本特征進行判斷,大部分微博中所包含的文本內容不多,所以在這種情況下可以判斷單個詞條會出現多次的0 或1,這樣可以有效的篩選出頻繁出現的詞條,達到了識別微博熱點的目的。
2.2 計算簡化思路
在改進SSDKmeans 算法中,為了可以更好的識別微博熱點,整個聚類所得到的關鍵詞還是基于微博本身的,因此在該方法在應用過程中可以結合不同的文本數據識別進行調整。而根據微博本身的熱點特征進行判斷后,發現熱點話題本身的微博轉發、評論量很多,并且發布微博用戶本身的影響力也會對最終結果產生影響。在這個過程中可以發現,影響微博熱點的影響因素主要包括:
(1)擁有大量關注者意見領袖的參與。活躍的微博用戶所發布的微博更容易被熱門發現,而擁有大量粉絲的意見領袖所發布的內容容易被大量粉絲閱讀,因此成為微博熱點的概率更大。但是此時需要注意的是,并不是所有的意見領袖所發布的微博可以得到粉絲的認可,也不是所有的粉絲都可以即時看到微博。
(2)微博的點贊數與轉發數等。一條備受關注的微博,其轉發量、點贊量必然很大,當用戶對某條微博產生強烈的認同感時,會采用“轉發+評論”的方法,而隨著微博轉發數量越來越高,微博成為熱點的概率越高。
基于上述分析,為了可以更好的發現微博熱點,在改進SSDKmeans 算法中可以根據不同影響因子對話題熱度的影響進行判斷,在了解微博單位時間內的評論量、點贊量以及意見領袖的參與情況后,對微博本身的數據信息進行判斷,這樣可以進一步提高數據處理質量。
3 改進SSDKmeans算法的實驗驗證
3.1 實驗環境
本次實驗中利用JAVA 語言編寫,實驗環境為:
操作系統為Windows7 系統,64 位;處理器Intel(R)i5;安裝內存4.00GB。
3.2 實驗數據與處理

表2:本文研究結果與新浪微博熱門話題的實時對比表
考慮到微博平臺中包含大量且廣泛的數據,無法像傳統的文本處理那樣形成大量有權威的數據庫,因此在本次研究中將以微博平臺的具體內容用戶內容,采用數據采集器直接從微博上抓取本次實驗中的44182 條微博數據。
在這個數據處理過程中發現,由于在微博平臺上每一個用戶都具有發布信息的能力,其中一些微博內容只是用戶對日常瑣事的記錄,也有一些微博文本內容是單純的抒情,這些數據對形成熱點沒有任何幫助,因此數據處理的一部就是通過手工處理的方法對文本進行初步篩選,過濾掉不滿足本次研究條件的微博文本;之后再對微博文本做進一步的處理,去除其中鏈接地址、特殊符號等微博,并通過系統排序,剔除意見領袖以及平常用戶中一些評論、轉發量較低的微博數據后,最終獲得了涉及影視劇集、娛樂圈事件、民生資料等多個類型的微博數據。最后對上述文本做最終處理(見圖1)。
在獲得文本詞集合后,采用Gibbs 抽樣方法對VSM 模型的LDA 模型參數進行估計,并將處理后的文本詞進行建模。在改進SSDKmeans 算法中,VSM 模型的參數與說明的詳細資料如表1所示。
在參數設定結束后,通過運行程序獲得“文檔-主題”的矩陣文件,此時矩陣中的每個元素代表了某個文本中形成的主題概率。
3.3 實驗方法
針對微博短文本聚類相似結果采用精準率與召回率判斷,其中召回率代表改進SSDKmeans 算法中找到頻繁項與微博文本中實際存在的頻繁項之間的比例,常見的計算方法:文本中的主題概率÷微博文本中實際頻繁項=召回率。精準率指改進SSDKmeans 算法中樣本采集頻繁項與找到的頻繁項之間的比值。
3.4 實驗結果與分析
按照上述方法對本文所提取的微博樣本進行處理后,依照改進SSDKmeans 算法中所得到的數據集初始類簇,計算類簇中心點為聚類算法的初始中心點,在通過改進SSDKmeans算法中對聚類效果進行多次修正,在經過上述處理后,獲得的微博熱點與新浪微博實時熱點話題對比結果如表2所示。
根據表2的相關資料,本文通過改進SSDKmeans 算法所提取到的熱門話題特征詞與新浪微博當時實際的特征話題之間存在一定的差異,特征詞沒有完全體現熱點話題內容,但是特征詞卻沒有偏離實時熱點話題的范疇,進而證明本文所介紹的方法具有科學性。而造成兩者之間出現的差異原因可能為:在本文所提取的數據中,只能根據微博所提供的數據資料進行分析,本身存在一定的滯后性,并且在相關話題閱讀量問題的識別過程中,無法實時監測轉發數、評論數的變化;再加之本次研究中所構建的VSM 模型無法像新浪微博官方那樣講詞條內容具體化,只能提供一個大題的話題詞條范圍,因此這種問題在一定程度上造成本次熱門話題詞匯與具體熱點出現差異,但是這種差異也是可以解決的。
4 結束語
基于改進SSDKmeans 算法滿足微博熱點發現的要求,本文所介紹的實踐經驗證明該方法具有明顯的先進性,值得推廣。
猜你喜歡
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
語文知識(2014年1期)2014-02-28 21:59:13
