電力文本挖掘技術(shù)研究綜述
2020-01-16 07:39:38白開峰楊波魏軍
電子技術(shù)與軟件工程 2019年22期
文/白開峰 楊波 魏軍
1 引言
當(dāng)前,大數(shù)據(jù)云計(jì)算研究的成熟與發(fā)展推動(dòng)著電子化自動(dòng)化技術(shù)的產(chǎn)業(yè)應(yīng)用。智能電網(wǎng)的管理、服務(wù)、監(jiān)測(cè)、運(yùn)行、診斷、營(yíng)銷、評(píng)估等方方面面的工作開始獲得一體化聯(lián)網(wǎng)管理模式。信息的高度集中使得大量的非結(jié)構(gòu)化關(guān)鍵性數(shù)據(jù)與內(nèi)容存在于各類形式以及多種來(lái)源的文本文件中。井噴式增長(zhǎng)的電力大數(shù)據(jù)對(duì)于智能電網(wǎng)的研究意義已獲得業(yè)內(nèi)普遍認(rèn)可。它既是智能電網(wǎng)發(fā)展的前沿領(lǐng)域,也是關(guān)鍵技術(shù)基礎(chǔ)。作為資源密集型的電網(wǎng)企業(yè),大數(shù)據(jù)資源的科學(xué)統(tǒng)籌管理與綜合分析是關(guān)鍵任務(wù)之一。
電力文本數(shù)據(jù)具有的數(shù)據(jù)體量大、類型豐富、信息密度低、更新速度快的特征。其中,數(shù)據(jù)體量大,指24 小時(shí)全時(shí)段無(wú)間歇運(yùn)作的電力設(shè)備系統(tǒng)不斷產(chǎn)生數(shù)目龐大的數(shù)據(jù);類型豐富,指電力數(shù)據(jù)描述電力系統(tǒng)運(yùn)行的方方面面包括設(shè)備運(yùn)行監(jiān)測(cè)診斷維護(hù),電網(wǎng)公司運(yùn)營(yíng)評(píng)估,客戶相關(guān)信息報(bào)告,呈現(xiàn)數(shù)據(jù)形式多樣,數(shù)據(jù)來(lái)源多樣,數(shù)據(jù)內(nèi)容多樣的現(xiàn)象;價(jià)值密度低,指異常數(shù)據(jù)占比低,但數(shù)據(jù)價(jià)值高。因此采用文本挖掘技術(shù)挖掘電力文本具有很高的應(yīng)用意義。
目前,文本挖掘技術(shù)主要被應(yīng)用于醫(yī)學(xué)信息、生物學(xué)、社交媒體等領(lǐng)域,而在電力行業(yè)內(nèi)則停留于研究實(shí)驗(yàn)階段。人工智能及其子方向自然語(yǔ)言處理理論與技術(shù)的發(fā)展為電力文本挖掘的實(shí)現(xiàn)提供先決條件。與此同時(shí),電力企業(yè)長(zhǎng)期運(yùn)營(yíng)所積累的大量數(shù)據(jù)為電力文本挖掘的研究提供數(shù)據(jù)保障。電力行業(yè)經(jīng)過(guò)長(zhǎng)期發(fā)展,在數(shù)據(jù)管理分類,規(guī)程規(guī)章,數(shù)據(jù)體制方面有較高的完整性和統(tǒng)一性。上述三點(diǎn)為未來(lái)完全實(shí)現(xiàn)對(duì)電力文本的自動(dòng)化知識(shí)與關(guān)鍵內(nèi)容獲取具有可行性以及技術(shù)保障。
根據(jù)電力文本挖掘技術(shù)目前的研究探索與實(shí)驗(yàn),本文將就電力文本挖掘技術(shù)的研究成果與初期應(yīng)用探索展開討論。重點(diǎn)就文本挖掘技術(shù)及其電力領(lǐng)域應(yīng)用、研究現(xiàn)狀、未來(lái)工作與挑戰(zhàn)做簡(jiǎn)要分析。
2 文本挖掘技術(shù)
文本挖掘作為自然語(yǔ)言處理與數(shù)據(jù)挖掘的交叉應(yīng)用,該概念于20世紀(jì)80年代中期被正式提出,至今以經(jīng)過(guò)30 多年的發(fā)展。隨著大數(shù)據(jù)時(shí)代的到來(lái),該項(xiàng)技術(shù)重新受到關(guān)注與應(yīng)用。文本挖掘的主要任務(wù)是從大量現(xiàn)有非結(jié)構(gòu)化文本數(shù)據(jù)中挖掘未知的、價(jià)值高的、高可用的結(jié)構(gòu)化知識(shí),并應(yīng)用于信息管理、組織、歸納、二次利用。文本挖掘技術(shù)主要涉及三方面的內(nèi)容。
如圖1所示,文本挖掘的發(fā)展主要基于深度學(xué)習(xí)、機(jī)器學(xué)習(xí)、自然語(yǔ)言處理、概率統(tǒng)計(jì)為理論依據(jù)。換言之,文本挖掘是上述理論的具體任務(wù)。技術(shù)基礎(chǔ)部分主要包含文本信息抽取、文本分類、文本聚類、文本數(shù)據(jù)壓縮、文本數(shù)據(jù)處理。在此基礎(chǔ)之上主要應(yīng)用信息訪問(wèn)和知識(shí)發(fā)現(xiàn),其中信息訪問(wèn)具體涉及信息檢索、信息瀏覽、信息過(guò)濾、信息報(bào)告,知識(shí)發(fā)現(xiàn)則涉及數(shù)據(jù)分析、數(shù)據(jù)預(yù)測(cè)。具體應(yīng)用領(lǐng)域主要覆蓋于醫(yī)學(xué)生物以及社交媒體信息的研究,如醫(yī)學(xué)知識(shí)圖譜構(gòu)建,電子病歷自動(dòng)處理,文獻(xiàn)自動(dòng)閱讀、用戶行為分析、情感分析、話題熱度監(jiān)測(cè)及分析等方面的工作。
3 文本挖掘
3.1 文本挖掘難點(diǎn)
文本挖掘的難點(diǎn)主要來(lái)源于兩個(gè)方面——文本數(shù)據(jù)和應(yīng)用領(lǐng)域。文本作為一種非結(jié)構(gòu)數(shù)據(jù),本身存在諸多難點(diǎn)需要克服。文本作為語(yǔ)言的一種表示形式以及種類多樣,不同語(yǔ)種的語(yǔ)法不同,無(wú)統(tǒng)一且機(jī)器可理解的形式與規(guī)則。第二,從語(yǔ)言學(xué)的角度看,文本本身存在諸多語(yǔ)言學(xué)現(xiàn)象,使得理解過(guò)程中容易出現(xiàn)歧義和模糊,為機(jī)器理解增添難度。第三,缺乏高可用且評(píng)估性能高的數(shù)據(jù)集。
除了針對(duì)社交類、新聞?lì)惖乳_放性文本以外,文本挖掘技術(shù)的價(jià)值更是應(yīng)用于生物醫(yī)學(xué)、教育教學(xué)、電力電網(wǎng)等社會(huì)或生產(chǎn)領(lǐng)域中。無(wú)論是開放性文本或是領(lǐng)域性文本,都需要結(jié)合應(yīng)用場(chǎng)景和所用語(yǔ)言做出針對(duì)性的、準(zhǔn)確的、高效的文本挖掘工具。從宏觀上看,這類工具的魯棒性較差,效果欠佳,目前尚無(wú)解決方案。
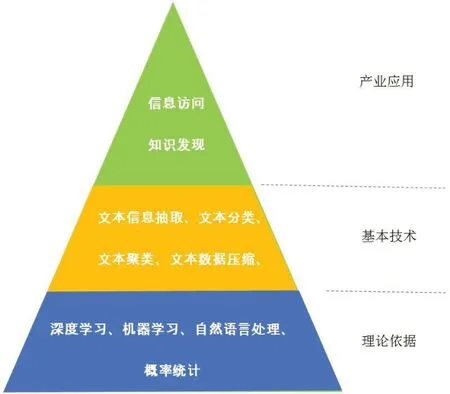
圖1:文本挖掘三部分結(jié)構(gòu)
由于電力行業(yè)的文本一般是人工書寫完成,存在一定數(shù)量的書寫錯(cuò)誤,語(yǔ)法錯(cuò)誤、歧義錯(cuò)誤等。因此,在文本挖掘過(guò)程中,容錯(cuò)性以及錯(cuò)誤理解性也是數(shù)據(jù)處理人員需要優(yōu)化解決的一項(xiàng)挑戰(zhàn)。除此之外,領(lǐng)域性文本也包含了大量表格型數(shù)據(jù)。因此,針對(duì)這類數(shù)據(jù)的挖掘也是文本挖掘中的一項(xiàng)重要子任務(wù)。
3.2 電力文本挖掘方法
3.2.1 電力文本挖掘預(yù)處理
與一般的文本挖掘不同,電力文本挖掘在考慮確定問(wèn)題需求的初始階段時(shí),需要就文本類型做基于電力專業(yè)知識(shí)的內(nèi)容分析。電力行業(yè)涉及的文本類型豐富,來(lái)自不同部門、不同崗位、不同設(shè)備、不同領(lǐng)導(dǎo)層次等等,且這一特點(diǎn)具體體現(xiàn)在文本挖掘的各項(xiàng)子任務(wù)中。如命名實(shí)體識(shí)別(Named Entity Recognition,NER),是實(shí)現(xiàn)文本分類,自動(dòng)評(píng)估、自動(dòng)篩檢的基礎(chǔ)任務(wù)。其具體目標(biāo)是從電力數(shù)據(jù)文本中識(shí)別出關(guān)鍵的指定性內(nèi)容,如工程屬性,設(shè)備名稱、運(yùn)行數(shù)據(jù)等,從電力專業(yè)的角度實(shí)現(xiàn)關(guān)鍵信息的抽取和分類。
電力文本常以非結(jié)構(gòu)化的自由數(shù)據(jù)形式存在,因此在進(jìn)行文本挖掘的初始準(zhǔn)備階段,需要完成文本數(shù)據(jù)預(yù)處理以及文本表示的工作,之后才能進(jìn)行文本挖掘工作。文本預(yù)處理的具體工作一般包含中文分詞、取停用詞、詞性標(biāo)注等。除此之外,預(yù)處理工作中一項(xiàng)重要子任務(wù)是構(gòu)建電力文本問(wèn)題語(yǔ)料庫(kù)并在此基礎(chǔ)之上建立領(lǐng)域性字典。其中在語(yǔ)料庫(kù)數(shù)據(jù)采集上,需要盡可能保證數(shù)據(jù)集的平衡性和多樣性。換言之,我們需要盡量從電力部門現(xiàn)有的各類文本數(shù)據(jù)中選取,如電力設(shè)備的運(yùn)行、維護(hù)、測(cè)試報(bào)告或日志,供電局現(xiàn)場(chǎng)維修記錄單、工單,電力行業(yè)工作守則、指南、標(biāo)準(zhǔn)等等。在此基礎(chǔ)之上,結(jié)合現(xiàn)有的通用字典,在優(yōu)先完成去除停用詞的前提下,采用基于統(tǒng)計(jì)的分詞方法,如隱馬爾科夫鏈或是條件隨機(jī)場(chǎng)模型等對(duì)文本做分詞處理,并根據(jù)詞頻做排序,之后還需要電力專業(yè)人員做人工校正并進(jìn)行補(bǔ)充更新,以保證字典的科學(xué)性、準(zhǔn)確性和及時(shí)性,為之后的工作提供數(shù)據(jù)保障和資源支持。
3.2.2 電力文本的表示方法
除了高效準(zhǔn)確平衡的數(shù)據(jù)集之外,在被廣泛應(yīng)用的深度學(xué)習(xí)模型算法中,文本數(shù)據(jù)的計(jì)算機(jī)可理解化表示是電力文本數(shù)據(jù)挖掘過(guò)程中需要解決的另一個(gè)問(wèn)題。常用的表示方法有空間向量模型、嵌入式向量模型、正則表達(dá)式、樹結(jié)構(gòu)模型等。不同模型的側(cè)重點(diǎn)有區(qū)別,需要基于任務(wù)目標(biāo)合理選擇。如前文所提到的,常用的兩類向量表示方法中空間向量模型主要關(guān)注句子的整體內(nèi)容而忽略句中詞語(yǔ)的順序;嵌入式向量模型則關(guān)注于句子中的關(guān)鍵信息的內(nèi)涵以及優(yōu)先級(jí)排序。目前,處理這類問(wèn)題的主流方法是詞袋方法以及Word2Vec 方法。基于向量空間模型的詞袋方法簡(jiǎn)單且可操作性強(qiáng),但是以升高維度和忽略上下文內(nèi)容為代價(jià)。而Word2Vec 則是由目前被廣泛應(yīng)用的神經(jīng)網(wǎng)絡(luò)訓(xùn)練獲得的,因此,相較于詞袋方法,具有詞向量緯度的特點(diǎn),且通過(guò)計(jì)算向量相似度的手段在訓(xùn)練階段即考慮上下文對(duì)模型以及最終預(yù)測(cè)結(jié)果的影響。Doc2Vec 則是基于Word2Vec 發(fā)展起來(lái)的方法,旨在實(shí)現(xiàn)抽取主要內(nèi)容實(shí)現(xiàn)文本摘要的工作。
3.3 命名實(shí)體識(shí)別以及關(guān)系抽取
廣譜型的命名實(shí)體識(shí)別旨在識(shí)別出現(xiàn)在文本數(shù)據(jù)中的人名、地名、機(jī)構(gòu)名、時(shí)間、日期、貨幣和百分比,而領(lǐng)域型的命名實(shí)體識(shí)別則更加注重研究、設(shè)備運(yùn)營(yíng)以及生產(chǎn)領(lǐng)域文本數(shù)據(jù)的類別性的關(guān)鍵實(shí)體內(nèi)容抽取工作,也是實(shí)現(xiàn)構(gòu)建電力系統(tǒng)知識(shí)圖譜電力文本數(shù)據(jù)分類、關(guān)系抽取、文本摘要的首要任務(wù)之一,包括前文提及的文本數(shù)據(jù)預(yù)處理,基于專業(yè)知識(shí)的文本數(shù)據(jù)分析、模型訓(xùn)練、測(cè)試等子任務(wù)。針對(duì)電力文本的數(shù)目多、體量大、內(nèi)容雜的特點(diǎn),命名實(shí)體識(shí)別方法有利于快速有效的實(shí)現(xiàn)句子關(guān)鍵信息的識(shí)別以及分類,為之后的命名實(shí)體間的關(guān)系抽取提供前提保障。
如圖2所示,命名實(shí)體識(shí)別的步驟主要包括數(shù)據(jù)清洗、預(yù)處理、模型訓(xùn)練以及實(shí)體識(shí)別,其中還包含非常重要的一步,數(shù)據(jù)標(biāo)注。數(shù)據(jù)標(biāo)注的質(zhì)量一定程度上影響著實(shí)體識(shí)別結(jié)果的準(zhǔn)確性。常用的命名實(shí)體識(shí)別工作是使用條件隨機(jī)場(chǎng)以及深度學(xué)習(xí)的方法。
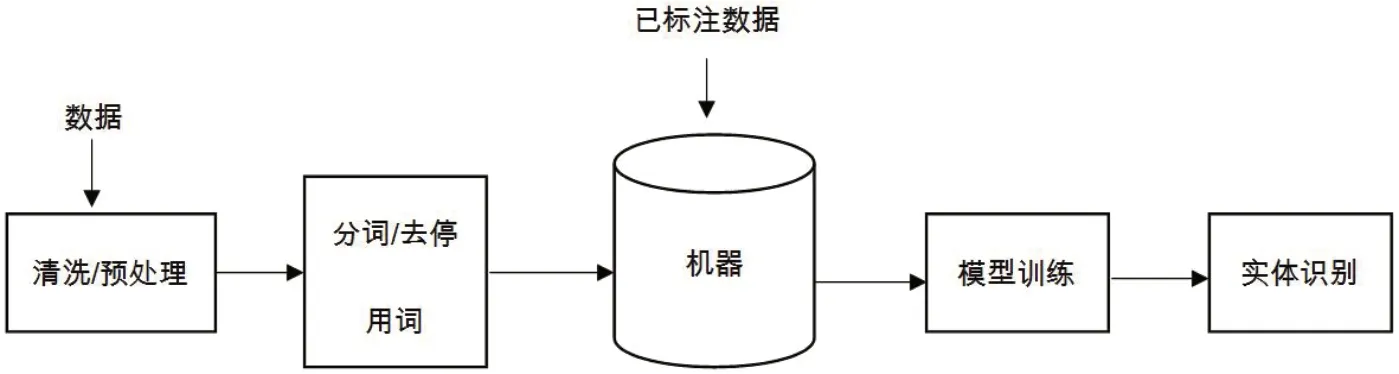
圖2:命名實(shí)體識(shí)別流程
關(guān)系抽取一般使用基于規(guī)則、監(jiān)督學(xué)習(xí)、半監(jiān)督以及無(wú)監(jiān)督學(xué)習(xí)。基于規(guī)則的方法是從語(yǔ)法規(guī)則以及語(yǔ)法現(xiàn)象的角度尋找主謂賓、suchas、including 等語(yǔ)言結(jié)構(gòu)。此類方法準(zhǔn)確度高,適合垂直場(chǎng)景,但其缺點(diǎn)也很明顯,信息覆蓋率低、人力成本高、設(shè)計(jì)難度高使得這類方法無(wú)法在電力文本數(shù)據(jù)這類領(lǐng)域性文本中推廣。而監(jiān)督學(xué)習(xí)提高了模型的魯棒性,但前期的準(zhǔn)備工作需要專業(yè)性知識(shí)的介入,如定義關(guān)系和實(shí)體類型,并準(zhǔn)備好已標(biāo)注實(shí)體以及關(guān)系的訓(xùn)練數(shù)據(jù)。接下來(lái)則是提取特征,并對(duì)特征做分類。特征包括此特征和位置特征。上述方法中的數(shù)據(jù)標(biāo)注需要耗費(fèi)大量的人力物力,且對(duì)標(biāo)注人員的專業(yè)性要求高。但由于其較好的預(yù)測(cè)效果使之依然被應(yīng)用在很多工作中。而半監(jiān)督學(xué)習(xí)一定程度上解決了監(jiān)督學(xué)習(xí)的這一缺點(diǎn),它只需要少量的標(biāo)注語(yǔ)料以及大量未被標(biāo)注的預(yù)料數(shù)據(jù),逐漸獲得在生產(chǎn)中獲得應(yīng)用。
4 結(jié)語(yǔ)
文本挖掘是集統(tǒng)計(jì)學(xué)、數(shù)據(jù)分析處理、機(jī)器學(xué)習(xí)、深度學(xué)習(xí)、語(yǔ)言學(xué)、數(shù)據(jù)庫(kù)技術(shù)等多學(xué)科于一體的新興手段。該項(xiàng)技術(shù)的發(fā)展使大量隱藏于文本數(shù)據(jù)背后的關(guān)鍵信息和知識(shí)被人們快速獲取。未來(lái)的研究方向中也將朝著電力運(yùn)維中文知識(shí)圖譜的構(gòu)建工作中,幫助快速高效的做出設(shè)備診斷。在電力生產(chǎn)中的應(yīng)用將有利于高效準(zhǔn)確地獲取文本數(shù)據(jù)中的關(guān)鍵信息,尤其在電力設(shè)備運(yùn)營(yíng)維護(hù)以及現(xiàn)場(chǎng)作業(yè)方面發(fā)揮重要作用,也有利于推動(dòng)電力企業(yè)信息電子化的進(jìn)程以及智能電網(wǎng)的發(fā)展,具有極大的應(yīng)用和研究?jī)r(jià)值。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
中外會(huì)展(2014年4期)2014-11-27 07:46:46
語(yǔ)文知識(shí)(2014年1期)2014-02-28 21:59:13
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
