藏文數詞自動檢錯研究
2020-01-16 06:51:38冷本杰高定國
電子技術與軟件工程 2019年21期
文/冷本杰 高定國
1 引言
文本校對是自然語言處理領域重要的研究課題,在計算機自動生成語料、機器翻譯、文本檢索、版面分析、手寫體識別等研究領域和后期的文本編輯中有著廣闊的應用前景。藏文數詞檢錯是藏文詞校對的一部分,也是錯誤出現頻率較高,且相對于藏文音節(jié)檢錯而言,檢錯需要觀察前后出現的字節(jié),根據音位環(huán)境的變形情況而檢錯的局部校對,所以藏文數詞檢錯實現難度較大。
藏文文本校對研究開始于20世紀90年代,目前文本校對方面的研究內容有通過采用字典匹配法和根據藏文字母的構建規(guī)則,應用規(guī)則完成音節(jié)字拼寫檢錯;根據傳統(tǒng)文法中的藏文虛詞添接規(guī)則,生成一定規(guī)模的規(guī)則庫來檢查藏文虛詞(自由虛詞)的接續(xù)關系;再用以上藏文音節(jié)字和接續(xù)關系的檢查外,進行分詞,完成梵文轉寫藏文拼寫檢查、詞語錯誤檢查以及綜合校對的框架設計及實現等研究。藏文詞校對方面的研究成果大多屬于理論性研究,具體實現中所使用方法的是詞典匹配法,這就需要龐大的詞典作為校對系統(tǒng)的基礎。詞典中通常收錄的數詞有基礎的(一)到(十)、(百)、(千)、(萬)、(十萬)、(百萬)、(千萬)、(億)等數詞、特殊的變形詞以及有特殊含義或和其它詞性搭配的數詞。藏文數詞的組詞功能強大,變化多,導致詞典無法收錄文本中可能產生的所有數詞。
2 藏文數詞檢錯的理論依據
2.1 藏文數詞的詞法規(guī)范研究
2.1.1 文本表示藏文數詞
數詞顧名思義,就是表示數目的詞語,屬于語法概念。不同語言中對數字有特殊簡易的表示符號。比如常用的世界通用阿拉伯數字,羅馬數字等。藏文中也有特定的數字符號,如表1所示。如果在常用文本中都使用這些數字符號,數詞的詞法規(guī)范問題就很簡單,但是正規(guī)文檔和大多數傳統(tǒng)文本書籍中絕大多數都是以文本表示數詞。比如:
2.1.2 藏文數位表示
藏文數詞通常主要分為計數詞和序列詞。序列詞是表示次序的詞,在具體語言中通常會前面出現(第)、(數)等詞,或后面會出現、等詞綴[9]。傳統(tǒng)的藏族天文歷算中計數詞可以列到六十位(),其中基礎的藏文計數詞有(一)、(二)、(三)、(四)、(五)、(六)、(七)、(八)、(九)、(十)、(百)、(千)、(萬)、(十萬)、(百萬)、(千萬)、(億)等,其余的很少使用,所以不在贅述。

表1:數字符號

表2:數詞變形規(guī)則表
2.1.3 藏文數詞和數位詞發(fā)生形變
藏文基本的計數詞合成形成其余數詞時,不能像漢語那樣直接搭配,而會根據具體的音位環(huán)境變形。比如:(十五)、(二十)、(二 十 一)、(三 十 三)、(七十六)。藏文數詞變形規(guī)則如表2所示。
藏文數詞的變形有如下規(guī)律:
(1)藏文數詞中表達個位數時,不論計數還是序數都會使用數詞原形。比如:(一束花)、(吉祥八寶)、(第二名);
(3)個位和十位數合成出現時,個位數的數詞會出現變形現象,會用(二)、(三)、(四)、(五)、(六)、(七)、(八)、(九)來代替數詞原形。比如:(二十一)、(三十三)、(四十五)、(五十六)、(六十七)、(八十九)、(九十一);
(5)藏文日期中通常表達二十至二十九號時,中間不會加變形體(二);而表示人的年齡、金錢余額等物質數量時中間的(二)用來代替。比如:(今天是二十三號)(二十五歲男兒)。
2.2 藏文數詞的特性分析
藏文數詞出現在文本除了單純的數字表示之外大多數是在修飾名詞。修飾名詞時通常名詞出現在數詞前面,所修飾的名詞有所有復數可數名詞和方位詞或處所名詞,修飾方式有直接修飾和間接修飾名詞。直接修飾可數名詞例如:(五個人)、(六公里)、(17m2)、(一 千 斤)、(兩百畝)、(三天)、(兩個任務);直接修飾方位詞或處所名詞例如:兩方)、(四方)、(兩面)、(兩岸);間接修飾名詞時通常名詞和數詞中間出現一些量詞(種)、(次)、(部)和其他特殊詞(數)、(倍)、(各種)、(總共)、(一共)。
另外也有數詞和動詞組合在一起,形成一種語義獨立的詞匯來修飾名詞,這時數詞通常不會實指具體的數目,而是泛指多或少,統(tǒng)一或部分、連續(xù)或擴散等和數量有關的含義。比 如:(統(tǒng) 一)、(集 中) 、(專心致志)、(集中力量)、(連續(xù)不斷)、(九煞畢集)。數詞和動詞組合一起時也可以中間添加虛詞來連接一起。比如:(連接)、(集中)。
2.3 藏文數詞的常見詞法錯誤分析
通過遍歷大小為176MB的藏文新聞語料,抽取數詞的前后共五個字節(jié),分析詞法錯誤情況,發(fā)現藏文數詞的詞法應用錯誤主要是原形與變體混用導致錯誤。數詞中(一)、(二)、(三)和變形詞(一)、(二)、(三)的具體用法混淆,例如:(兩千年)寫成(兩千年)。數詞和變形詞在數詞合成中需要查看前一個音節(jié),而具體的應用中常出現用法混淆現象。例如:(六十),(四十)。
3 藏文數詞自動檢錯算法設計
3.1 藏文數詞自動檢錯算法設計
藏文中基礎的數詞很少,但出現頻率較高,這些基礎數詞會通過內部合成或和其它詞性搭配形成更多的詞。文本中出現的藏文數詞搭配錯誤種類少、有規(guī)則可循,所以按照一定規(guī)則可以完成常見錯誤的檢錯。
按照藏文數詞的規(guī)范、特征、設計的藏文數詞檢錯算法如下:
(1)讀取待檢錯的藏文文本內容,以藏文音節(jié)點作為分隔符,將文本切分成音節(jié)字序列,然后每個字符存儲在字符串數組String[] str中,字符串str數組如T=Z1+Z2+……Zn-1+Zn來表示,其中Zn是一個藏文音節(jié)字。
(3)如果Zn與藏文基礎數詞匹配成功,則執(zhí)行(4),否則繼續(xù)匹配。
(4)判斷基礎數詞前后出現以下字符串數組時按變形規(guī)律檢錯。
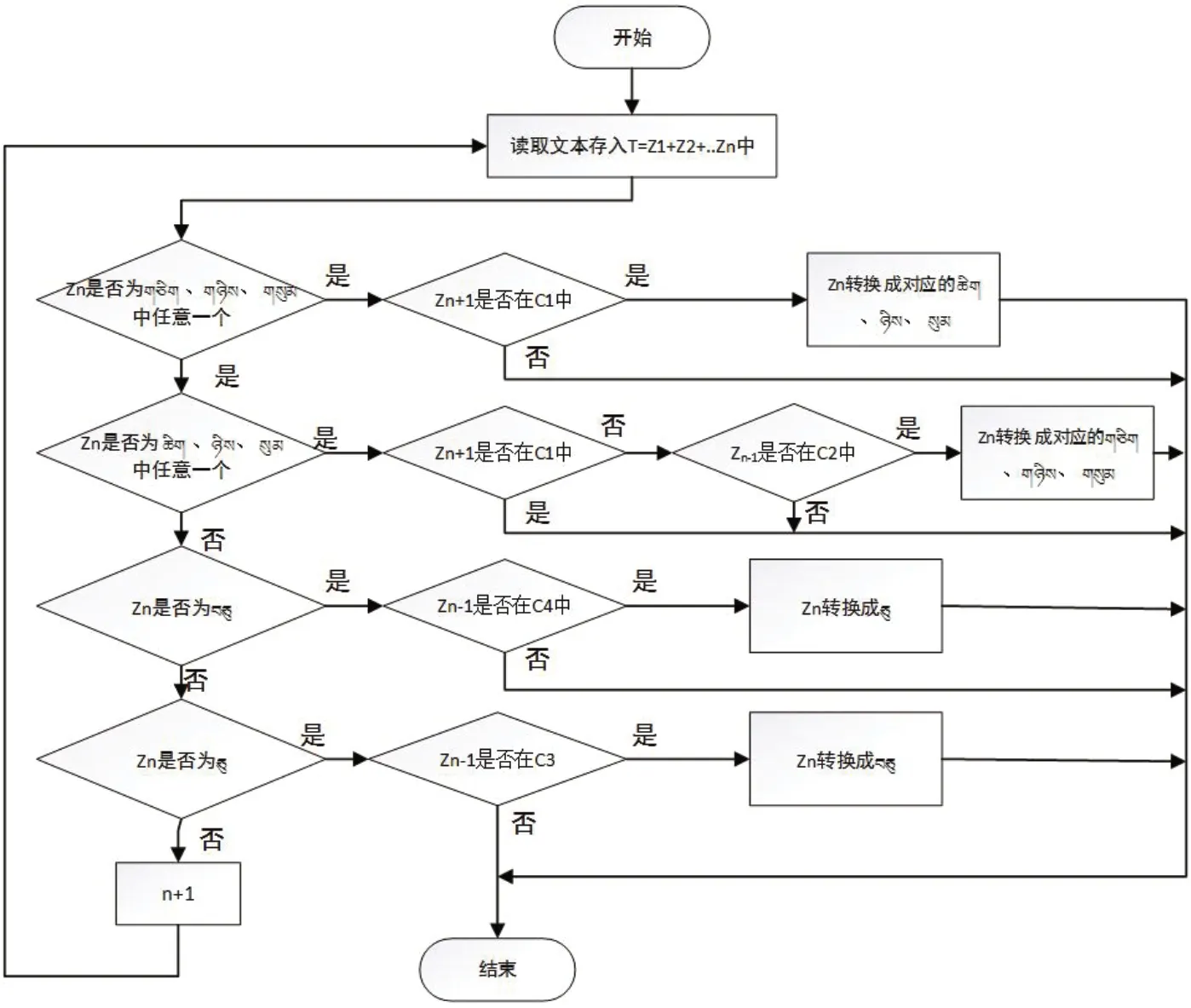
圖1:藏文數詞檢錯流程
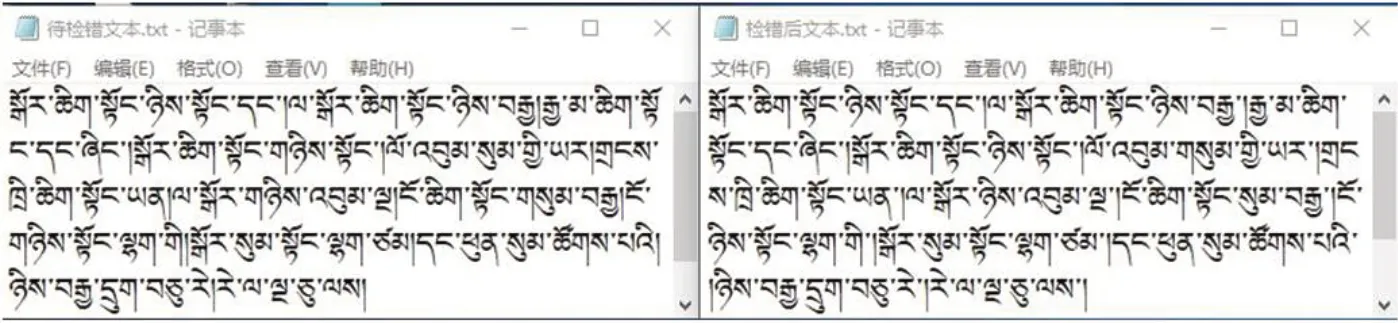
圖2:藏文數詞檢錯測試結果
按以上設計的算法和流程圖實現藏文檢錯過程如下:
3.2 藏文數詞自動檢錯算法測試
本次測試,為了體現檢錯算法的實際效果,測試文本主要選用詞法錯誤統(tǒng)計處理后的語料,內容是基礎數詞以及前后共五個音節(jié)字符,每五個字節(jié)有單垂符隔開。將測試文本進行自動檢錯,檢錯完成的結果保存到一個新文本中,結果如圖2所示。
雖然以上算法可以完成簡單的常見藏文數詞詞法上的錯誤檢錯,但也有以下兩點缺陷:
(1)藏文基礎數詞的音節(jié)拼寫錯誤以及和音節(jié)錯誤合成的詞法錯誤無法檢錯,如(一)、(三千)等。
(2)藏文數詞中有兼類詞,這些兼類詞有時恰好和數詞連續(xù)出現,雖然數量極少,但也有出現如(兩層寶座)、(空屋三頂)的可能,這時檢錯算法會檢錯失誤,出現錯誤糾正的現象。
4 結束語
藏文文本中數詞有嚴格的詞法合成規(guī)范,卻詞法錯誤出現頻繁。本文詳細分析了藏文數詞的變形情況、語法特征、搭配規(guī)律等知識,通過統(tǒng)計分析常見的詞法錯誤,提出了基于規(guī)則的數詞合成檢錯算法,利用該方法檢錯成功率達到100%。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中華詩詞(2020年1期)2020-09-21 09:24:52
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
小學生作文(中高年級適用)(2018年5期)2018-06-11 01:22:56
Coco薇(2017年11期)2018-01-03 20:59:57
中學生數理化·七年級數學人教版(2017年11期)2017-04-23 07:18:00
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
數學大王·中高年級(2016年12期)2016-12-26 21:37:36
