基于信息熵的粗糙集連續屬性離散檢驗算法
2020-01-16 06:42:18楊海鵬
湖南城市學院學報(自然科學版) 2020年1期
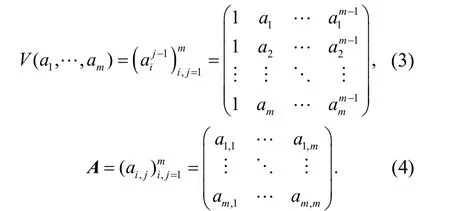
楊海鵬
(吉林工程技術師范學院 信息工程學院,長春 130052)
通過構建大數據挖掘模型,提高對云計算環境下大數據挖掘和查詢的精度,進行大數據特征信息采樣,能實現對大數據的遠程信息探測和自適應調度,為了提高大數據的分類融合和特征識別能力,需要進行大數據的粗糙集挖掘,建立相關粗糙集連續屬性離散數據的特征提取模型,在提高大數據的挖掘和自適應分類能力方面具有重要意義[1].
對粗糙集連續屬性離散數據的特征提取是建立在對數據的聚類屬性分析基礎上,采用自適應特征分類方法,進行粗糙集連續屬性離散數據檢測,采用特征標注方法構建粗糙集連續屬性分布 的特征辨識模型[2],結合關聯規則挖掘方法,實現粗糙集連續屬性離散檢驗.傳統方法中,對粗糙集連續屬性離散檢驗方法主要有關聯規則挖掘方法、模糊特征提取方法和C 均值聚類方法,建立粗糙集連續屬性離散分布模型[3],采用相關均衡控制方法,進行粗糙集連續屬性離散檢驗.文獻[4]中提出一種基于梯度提升回歸樹的粗糙集連續屬性離散數據信息熵離散檢驗模型,構建粗糙集連續屬性離散數據的特征權重分布式檢測模型,采用融合相關性聚類分析方法實現數據回歸分析,提高數據的信息熵離散檢驗識別能力,但該方法的計算開銷較大,對粗糙集連續屬性分布檢驗的實時性不好.文獻[5]中提出基于關聯特征分布檢測的粗糙集連續屬性離散數據離散檢驗方法,提取粗糙集連續屬性離散數據的關聯特征分布集和屬性集,根據粗糙集連續屬性離散數據的屬性分布實現特征提取和離散檢驗,但該方法進行數據特征離散檢驗的模糊度較大,收斂性不太好.
針對上述問題,提出基于信息熵的粗糙集連續屬性離散檢驗算法,采用特征空間重組方法進行粗糙集連續屬性離散數據的模糊特征重構,提取粗糙集連續屬性離散數據的信息熵;并對所提取的信息熵進行聚類分析,建立連續屬性分布數據的信息熵提取模型,采用模糊聚類方法實現對粗糙集連續屬性的離散特征挖掘和聚類分析;最后根據粗糙集連續屬性的融合結果,實現離散檢驗和數據挖掘.
1 數據分布模型及特征分析
1.1 粗糙集連續屬性離散數據分布序列特征
為了實現粗糙集連續屬性離散數據信息熵離散檢驗,首先構建粗糙集連續屬性離散數據的分布式存儲結構模型,采用顯著性區域調度方法進行粗糙集連續屬性離散數據的信息融合處理;再構建粗糙集連續屬性離散數據優化調度和特征提取模型,進行粗糙集連續屬性離散數據的自適應離散檢驗[6];分析粗糙集連續屬性離散數據的離散空間調度模型,采用模糊鏈路控制方法,進行粗糙集連續屬性離散數據的融合調度,得到粗糙集連續屬性離散自適應加權權重為
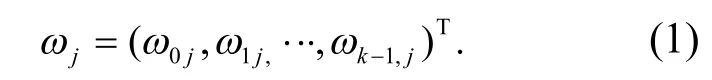
通過對粗糙集連續屬性特征分析,構建粗糙集連續屬性離散數據的統計特征分布樣本集為
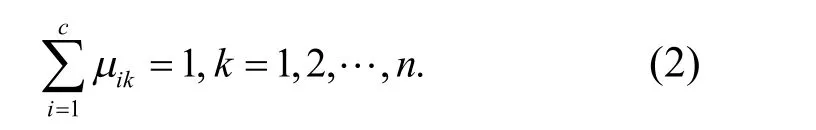
其中,k為粗糙集連續屬性離散數據的灰度空間分布權重.采用離散序列調度方法,構建粗糙集連續屬性離散數據的特征匹配模型[7],根據多分量檢測方法進行粗糙集信息離散檢驗,實現粗糙集連續屬性離散檢測,得到檢測統計量為
根據特征譜的聚類權重進行模糊自適應聚類處理,構建粗糙集連續屬性離散數據分布的有限數據集模型[8],得到粗糙集連續屬性離散調度的關聯特征為
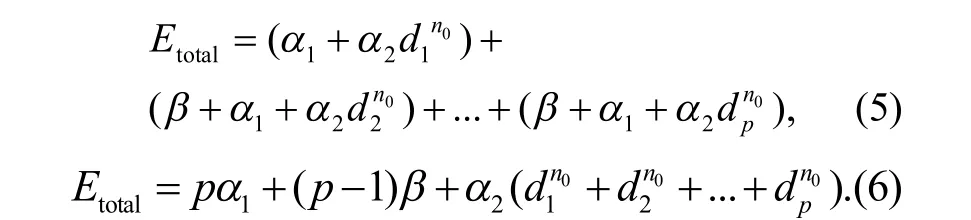
在分散子空間中進行粗糙集連續屬性離散數據的特征重構[9],構建粗糙集連續屬性離散數據的統計分布序列特征矩陣滿足
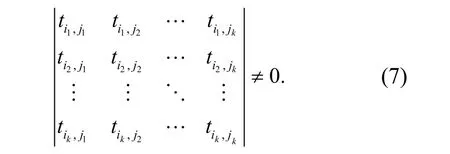
采用決策樹模型,構建粗糙集連續屬性離散數據的空間聚類模型.
根據上述分析,可得到粗糙集連續屬性離散數據分布結構模型如圖1 所示.
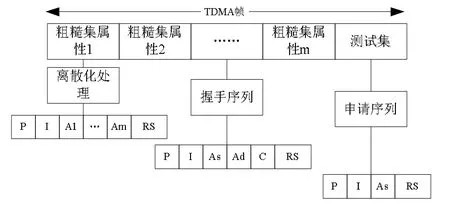
圖1 粗糙集連續屬性離散數據分布結構模型
1.2 離散數據閉繁項關聯分析度量
采用特征空間重組方法進行粗糙集連續屬性離散數據的模糊特征重構,提取粗糙集連續屬性離散數據的信息熵,采用決策樹算法進行粗糙集連續屬性離散數據信息熵離散檢驗,得到量化特征分布集定義為D,D={S i,j(t) ,Ti,j(t) ,U i,j(t)}.其中,S i,j(t)表示粗糙集連續屬性離散數據特征權重的重復因素;Ti,j(t)表示粗糙集連續屬性離散數據信息熵離散檢驗的輸出量因素;U i,j(t)表示相似度(相關性)模型.對粗糙集連續屬性的離散數據特征權重關聯規則特征量進行量化回歸分析,定義為
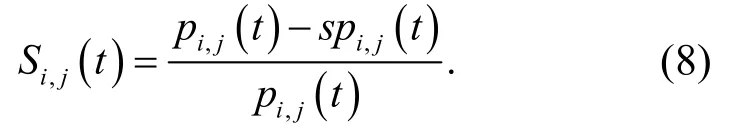

提取粗糙集連續屬性離散數據的信息熵特征量,根據信息熵特征提取結果,進行粗糙集連續屬性大數據挖掘,得到粗糙集連續屬性離散數據的閉繁項關聯分析度量值為
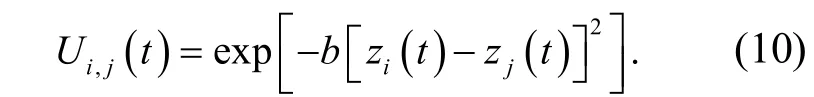
其中,p i,j(t)為粗糙集連續屬性離散數據信息熵離散檢驗的互信息量;sp i,j(t)為粗糙集連續屬性離散數據特征權重檢測的分叉度重復量;Δp(t)為增益系數;z i(t),z j(t)表示為粗糙集連續屬性離散數據特征權重檢測的模糊度函數.
由此建立粗糙集連續屬性離散數據的特征提取和信息融合處理方法,并采用模糊C 均值聚類分析方法構建粗糙集連續屬性的離散特征分析模型,利用隨機數檢測方法進行粗糙集連續屬性的離散檢驗[10].
2 粗糙集連續屬性離散檢驗優化
在云計算環境下進行粗糙集連續屬性大數據挖掘,采用特征空間重組方法進行粗糙集連續屬性離散數據的模糊特征重構,對粗糙集連續屬性離散檢驗優化,主要分為2 個步驟:1)采用粗糙集連續屬性關聯挖掘方法,進行離散數據特征權重的回歸分析,對粗糙集解結構重組;2)提取粗糙集連續屬性離散數據的信息熵,對所提取信息熵進行聚類分析,得到粗糙集連續屬性離散數據的信息熵特征提取結果,構建粗糙集連續屬性離散數據集的特征匹配函數,在數據聚類中心得到優化的粗糙集連續屬性離散數據檢驗輸出.
2.1 粗糙集連續屬性離散數據空間重組
采用相空間重構方法進行模糊特征重構.用一個四元組(Ei,E j,d,t)來表示粗糙集連續屬性離散數據特征權重的統計分布特征量,其中:Ei,Ej是粗糙集連續屬性離散數據特征權重的實體集(即節點i和j);d為粗糙集連續屬性離散數據特征權重的交互性統計數據;t為粗糙集連續屬性離散數據信息熵離散檢驗的時間延遲.采用粗糙集特征重構方法[11],進行統計時間序列分析,得到粗糙集連續屬性離散數據特征權重的決策樹分布特征量化集為
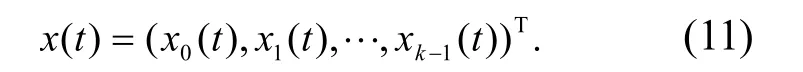
采用一個1×N的矩陣進行粗糙集連續屬性離散數據特征權重分類,用離散檢驗分析方法確定粗糙集連續屬性離散數據特征權重的離散檢驗時間窗口值N,構建多維熵矩陣.在相空間重構模型中,建立粗糙集連續屬性離散數據的特征權重分析模型[12],建立窄時域窗TLX和TLY,得到粗糙集連續屬性離散數據特征權重的模糊特征提取模型為

設粗糙集連續屬性離散數據特征權重的分布為m,先用信息熵特征分析方法得到粗糙集屬性集為 *jN,再采用粗糙集連續屬性關聯挖掘方法進行離散數據特征權重的回歸分析,得到粗糙集連續屬性離散數據空間重組為
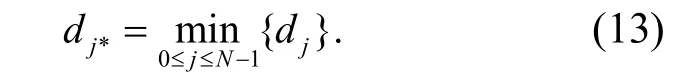
根據粗糙集連續屬性挖掘結果,進行離散數據特征分類檢測,構建粗糙集連續屬性離散調度模型,進行粗糙集解結構重組[13].
2.2 粗糙集連續屬性離散檢驗輸出
建立粗糙集連續屬性離散數據的信息融合模型,采用大數據挖掘方法進行粗糙集連續屬性離散數據空間重組的信息融合,其輸出為
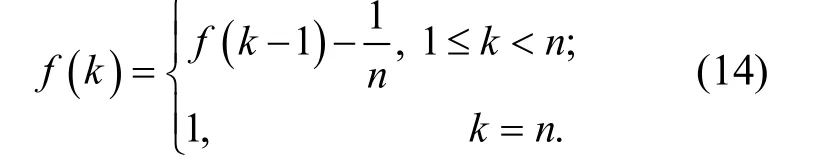
大數據集在節點si處的能量譜密度,采用主成分分析方法構建粗糙集連續屬性離散數據特征權重的回歸分析模型,采用特征空間重組方法進行粗糙集連續屬性離散數據的模糊特征重構和聚類處理,待檢驗的粗糙集連續屬性離散數據按照五元組離散檢驗,得到粗糙集連續屬性離散數據信息熵的分布概率密度特征為
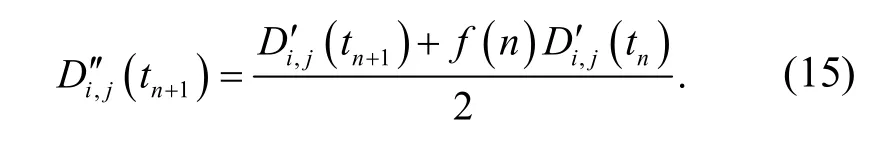
根據粗糙集連續屬性離散數據的屬性分布構建統計分布量化函數,粗糙集連續屬性離散數據特征權重分布的互信息量為
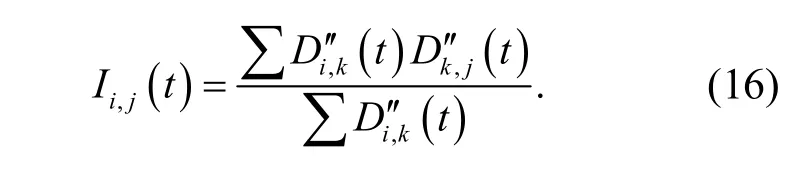
采用關聯規則分層調度方法,進行粗糙集連續屬性離散數據的信息熵離散檢驗和可靠性評估,得到可靠性評價函數表述為
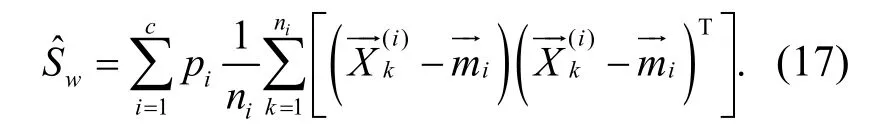
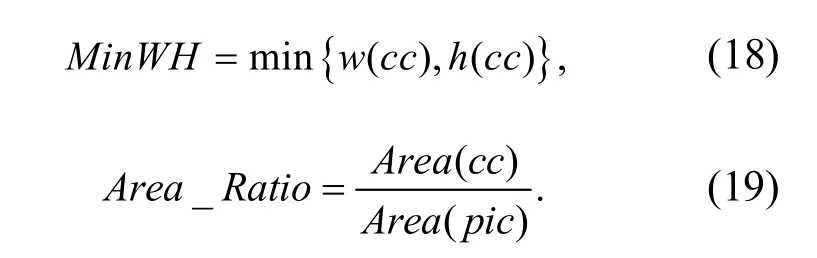
建立核函數,采用自適應加權控制方法進行粗糙集連續屬性離散數據的信息熵特征提取,采用離散檢驗分析方法進行模糊聚類,可得到聚類中心表示為
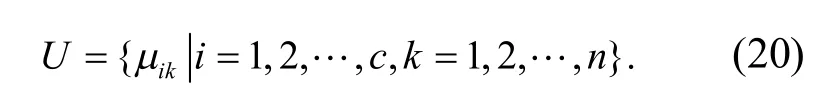
對粗糙集連續屬性離散檢驗的調度函數為
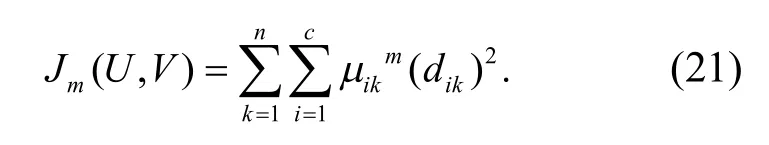
構建粗糙集連續屬性離散數據集的特征匹配函數,在數據聚類中心,得到優化的粗糙集連續屬性離散數據檢驗輸出為
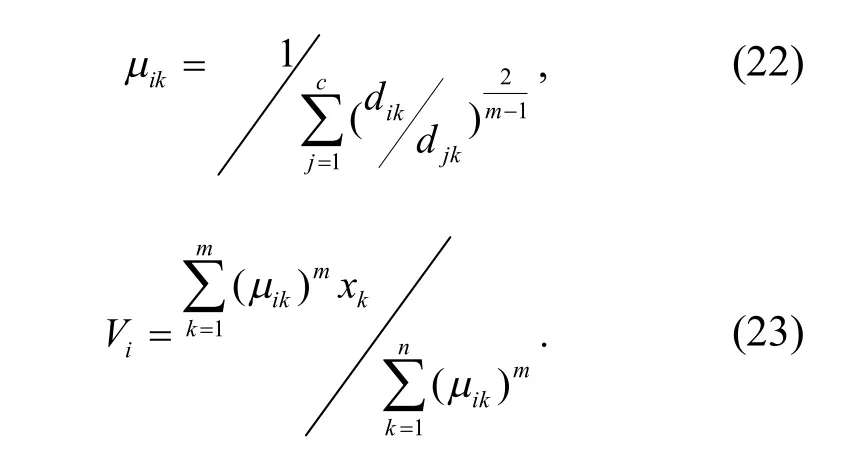
其中,m為粗糙集連續屬性離散數據信息熵離散檢驗的適應度函數;(dik)2為樣本xk與特征聚類中心與樣本Vi的測度距離.
綜上分析,根據粗糙集連續屬性的融合結果,可以實現離散檢驗和數據挖掘.
3 仿真實驗與結果分析
為了驗證本文方法在實現粗糙集連續屬性離散檢驗中的性能,進行軟件仿真實驗.采用Matlab 和C++進行算法設計,粗糙集連續屬性的大數據采樣樣本為1 200,粗糙集連續屬性離散數據采樣樣本個數為2 000,特征分布的權重系數為0.34,對粗糙集連續屬性離散數據信息采樣周期T=0.45 s,粗糙集屬性信息干擾強度SNR=(-20~0) dB.根據上述仿真環境和參數設定,進行粗糙集連續屬性離散數據檢驗,得到粗糙集連續屬性離散數據的大數據集采樣時域分布如圖2 所示.
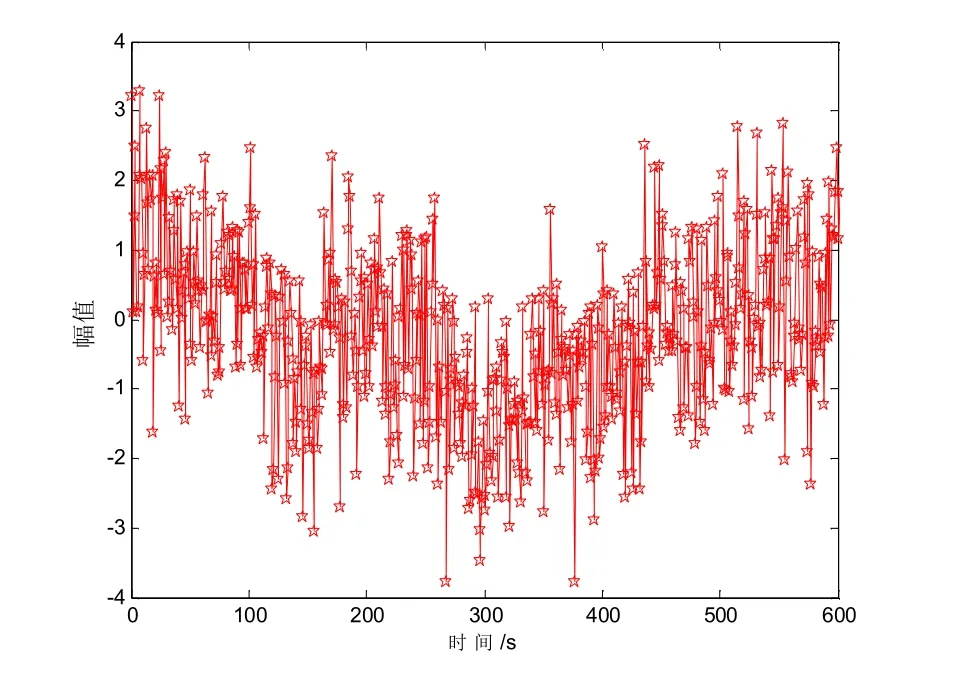
圖2 粗糙集連續屬性離散數據采樣
以圖2 的數據為研究對象,提取粗糙集連續屬性離散數據的信息熵特征,結果如圖3 所示.
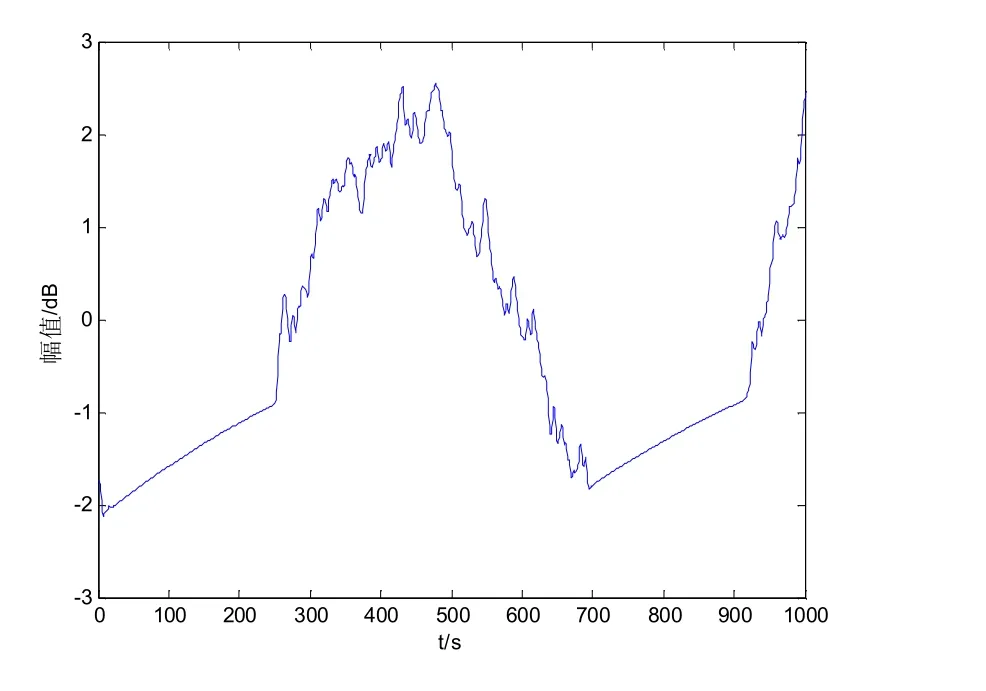
圖3 粗糙集連續屬性離散數據的信息熵特征
分析圖3 得知,采用本文方法進行粗糙集連續屬性離散數據特征提取的聚集性較好.測試不同方法下進行的粗糙集連續屬性離散數據離散性檢驗,所得結果如圖4 所示.
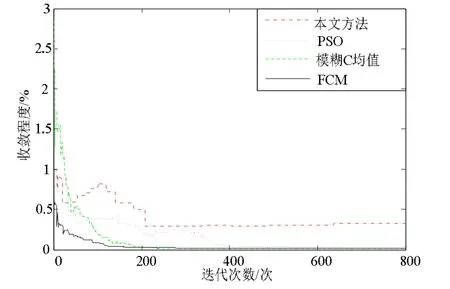
圖4 不同方法下粗糙集連續屬性離散數據檢驗
由圖4 可知,按本文方法進行粗糙集連續屬性離散數據信息熵離散檢驗的收斂能力較好.為進一步分析不同檢驗方法的收斂性,整理出實驗數據結果如表1 所示.

表1 不同檢驗方法的收斂度對比 %
根據表1 可知,隨著迭代次數的增加,4 種方法的收斂程度均有所下降,但本文所提方法收斂程度最高;在迭代次數為400 時,本文方法離散檢驗的收斂程度為0.265%,遠高于其它方法,證明本文方法進行粗糙集連續屬性離散數據檢驗的誤分類率較低,收斂性較好.
4 結語
通過提取粗糙集連續屬性離散數據的信息熵,得到粗糙集連續屬性離散數據所分布的序列特征,對其進行模糊聚類分析,獲取離散數據閉繁項關聯分析度量;再對粗糙集連續屬性離散數據進行空間重組和信息融合,優化離散檢驗輸出,以提高大數據粗糙集的分類融合和特征識別能力.仿真結果表明,采用本文方法進行粗糙集連續屬性離散檢驗的數據聚類性較好,其收斂程度優于常見的3 種聚類算法,且在迭代次數為400 時,收斂程度仍高達0.265%.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
