基于深度學習的圖像語義分割技術研究進展
2020-01-17 01:39:44梁新宇權冀川肖鎧鴻高偉嘉
計算機工程與應用 2020年2期
關鍵詞:語義
梁新宇,羅 晨,權冀川,肖鎧鴻,高偉嘉
1.陸軍工程大學 指揮控制工程學院,南京210007
2.陸軍工程大學 通信工程學院,南京210007
3.中國人民解放軍68023部隊
1 引言
圖像分割(image segmentation)技術已經成為計算機視覺領域的重要研究方向,是圖像語義理解的重要環節,也是實現完全場景理解的重要方式之一。圖像分割技術通常用于定位圖像中目標和邊界(線、曲面)的位置,為圖像中的每一個像素打上標簽,擁有相同標簽的像素具有相同的特征,為進一步對圖像進行分類、檢測和內容理解打下良好的基礎。
圖像語義分割是對圖像中的每個像素都劃分出對應的類別,即實現圖像在像素級別上的分類。如圖1所示,根據需求劃分的類別標簽,將圖中的“瓶子”“杯子”“立方體”實現像素級別的分類。

圖1 圖像語義分割
不同于圖像分類和目標檢測技術,在開始圖像分割處理之前,必須明確語義分割的任務要求,即理解語義分割的輸入和輸出。語義分割的重要性在于越來越多的應用需要利用圖像進行理解推斷,包括人機交互[1-2]、自動駕駛[3-5]、醫學影像[6-11]、計算攝影[12-13]、虛擬現實[14-16]、增強現實[17-18]等領域。
近年來,隨著深度學習技術的逐步深入,圖像語義分割技術有了突飛猛進的發展,相繼涌現出了一批經典的語義分割模型和算法。本文從圖像語義分割的技術發展視角,將其劃分為傳統圖像語義分割技術與基于深度學習的圖像語義分割技術兩大類。重點對基于深度學習的典型語義分割網絡架構進行了梳理總結,對于最近兩年內提出的新型網絡架構進行了綜合分析。同時,從圖像語義分割的性能評價需求出發,研究了常用的測試數據集和性能評價方法,對于主流的語義分割網絡架構進行了性能對比分析,可為相關領域的理論研究和應用實踐提供有價值的參考。
2 傳統的圖像語義分割技術
(1)基于閾值的圖像分割技術
基于閾值的圖像分割技術的基本思想是基于圖像的灰度特征來計算一個或多個灰度閾值,并將圖像中每個像素的灰度值與閾值進行比較,最后再根據像素比較的結果劃分到合適的類別中。
閾值分割的優點是計算簡單、運算效率較高且速度快。全局閾值對于灰度相差很大的不同目標和背景能進行有效的分割;局部閾值或動態閾值對于閾值差異不大的目標更為合適。雖然基于閾值的分割技術簡單高效,但也有一定的局限性。這種方法只考慮像素本身的灰度值,一般不考慮空間特征,因而對噪聲很敏感。在實際應用中,閾值法通常要與其他方法結合使用。
(2)基于邊緣的圖像分割技術
所謂邊緣是指圖像中兩個不同區域的邊界線上連續的像素點的集合,是圖像局部特征不連續性的反映,體現了灰度、顏色、紋理等圖像特性的突變。基于邊緣的分割技術是根據灰度值進行邊緣檢測,將圖像分割成不同的部分。它是建立在邊緣灰度值會呈現出階躍型或屋頂型變化這一觀測基礎上的方法。
基于邊緣的分割方法的重點在于邊緣檢測對抗噪性和檢測精度之間的權衡。若提高檢測精度,則噪聲產生的偽邊緣會導致不合理的輪廓;若提高抗噪性,則會產生輪廓漏檢和位置偏差。為此,人們提出各種多尺度邊緣檢測方法,根據實際問題設計多尺度邊緣信息的結合方案,以較好地兼顧抗噪性和檢測精度。該方法的不足之處在于,在劃分復雜圖像時邊緣的連續性和完整性難以保證。
(3)基于區域的圖像分割技術
基于區域的圖像分割技術按照相似性準則將圖像分成不同的區域。其主要利用了圖像的局部空間信息,能夠較好地避免其他算法帶來的分割空間小的缺陷。
然而,這種分割技術在進行大區域分割時速度較慢,抗噪性差,往往會分割出無意義的區域或者造成圖像的過度分割等。一般情況下,會與其他方法結合使用,發揮各自的優勢以獲得更好的分割效果。
(4)基于特定理論的圖像分割技術
基于特定理論、方法的圖像分割技術包括聚類分析、模糊集理論、圖論等,這些理論為圖像分割技術的難點突破和研究拓展了新的方向。
傳統的圖像分割技術在分割精度和分割效率上難以達到實際應用的要求,尤其是在實時場景理解和圖像信息處理方面。而且,語義分割時,單獨使用一種傳統的圖像分割算法,難以獲得良好的分割效果。正確的思路是,不斷將各種新理論和新方法引入圖像分割領域。近年來,基于深度學習的圖像分割技術很好地解決了上述問題。
3 基于深度學習的圖像語義分割技術
深度學習(Deep Learning)[19]是機器學習的一個分支,也是近十年機器學習領域的研究熱點。深度學習是利用多層神經網絡結構,將隱含在高層中的信息進行建模的方法。
基于深度學習的圖像語義分割技術(簡稱深度圖像語義分割)的主要思路是,不需要人為設計特征,直接向深層網絡輸入大量原始圖像數據,根據設計好的深度網絡算法,對圖像數據進行復雜處理,得到高層次的抽象特征;輸出的不再是簡單的分類類別或者目標定位,而是帶有像素類別標簽的與輸入圖像同分辨率的分割圖像。
3.1 語義分割的經典網絡架構
許多語義分割問題可以使用深度學習網絡架構解決,這類網絡架構在準確率和處理效率上都明顯超越了傳統的方法。本節闡述了圖像語義分割處理的經典網絡架構及其實際用例,并對這些架構的特性進行總結和分析。
(1)全卷積網絡
2014年,全卷積網絡(Fully Convolutional Networks,FCN)[20]問世,其網絡架構如圖2所示。它是傳統卷積神經網絡(Convolution Neural Network,CNN)[21]的擴展,主要思想是利用全卷積網絡取代原有架構的全連接層部分,以達到可以輸入任意分辨率圖像的目的。由于傳統CNN的全連接層是針對固定長度的特征向量進行分類的,所以只能接受特定大小的輸入圖像。為了改變這種局限性,FCN 采用卷積和池化層,可以接受任意分辨率的輸入圖像。再利用反卷積層對最后一個卷積層的特征圖進行上采樣,使輸出結果恢復到與輸入圖像相同的尺寸。FCN可對圖像的每個像素產生一個預測,同時保留了原始輸入圖像中的空間信息,并在上采樣的特征圖上逐個像素進行分類和計算分類損失,相當于每個像素對應一個訓練樣本。所以,FCN通過對圖像進行像素級的分類來解決語義級別的圖像分割問題。
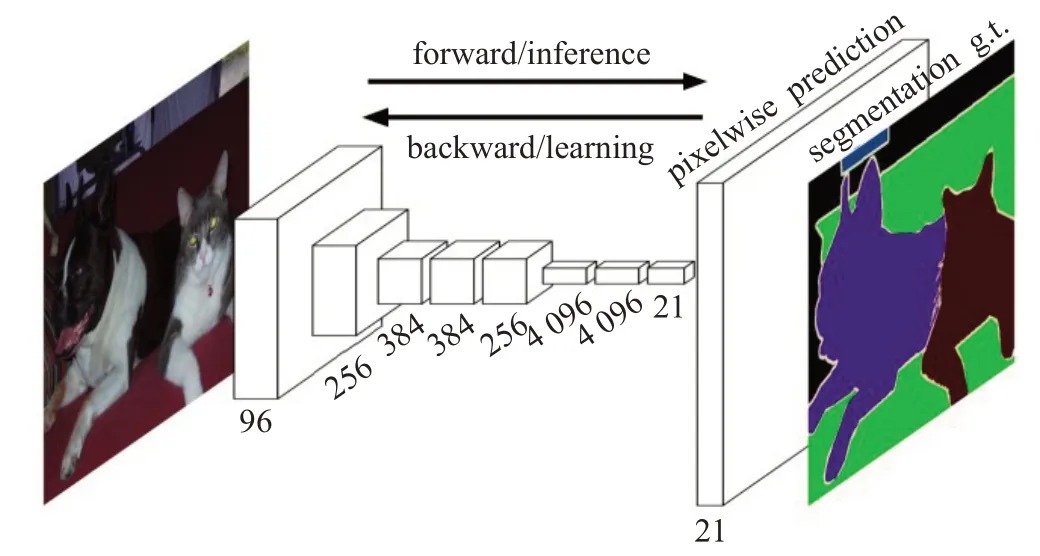
圖2 FCN架構
FCN為語義分割引入了端到端的全卷積網絡,同時重新利用預訓練網絡,結合反卷積層進行上采樣,并引入跳躍連接改善上采樣粗糙的像素定位。
FCN在處理室內場景分割任務中,較好地實現了視覺假體輔助盲人識別的應用[22]。除此之外,FCN在典型紅外目標分割[23]以及輸電線路航拍[24]等工程實踐中取得了良好表現。
(2)SegNet
FCN 和SegNet[25]都是最先出現的編碼-解碼結構。FCN網絡使用了反卷積層和少量跳躍連接,但是產生的分割圖較為粗略。為了提升效果,SegNet引入了更多的跳躍連接。另一方面,SegNet 并沒有復制FCN 中的編碼器特征,而是復制了最大池化指數,這使得在內存使用上SegNet 比FCN 更為高效。因此,SegNet 比FCN 更節省內存。
在農業信息領域,SegNet在高分辨率遙感影像的農村建設用地信息提取任務中,總體的分類分割精度達到96.61%[26],效果明顯。SegNet在工件表面缺陷檢測[27]等工業工程領域中得以應用,并取得不錯的效果。
(3)DeepLab v1
基于CNN模型架構的圖像分割技術是根據分類這種高層語義改進的,但CNN 具有的不變性特點會導致丟失位置信息,無法對像素點精確定位語義。如圖3所示,DeepLab v1[28]是CNN 和概率圖模型(Probabilistic Graphical Model,PGM)[29]的結合,利用空洞卷積(Atrous Convolution)增加卷積操作過程的感受野,保持分辨率。同時,對CNN最后一層增加全連接條件隨機場(Conditional Random Filed,CRF)[28],使分割結果更精確。
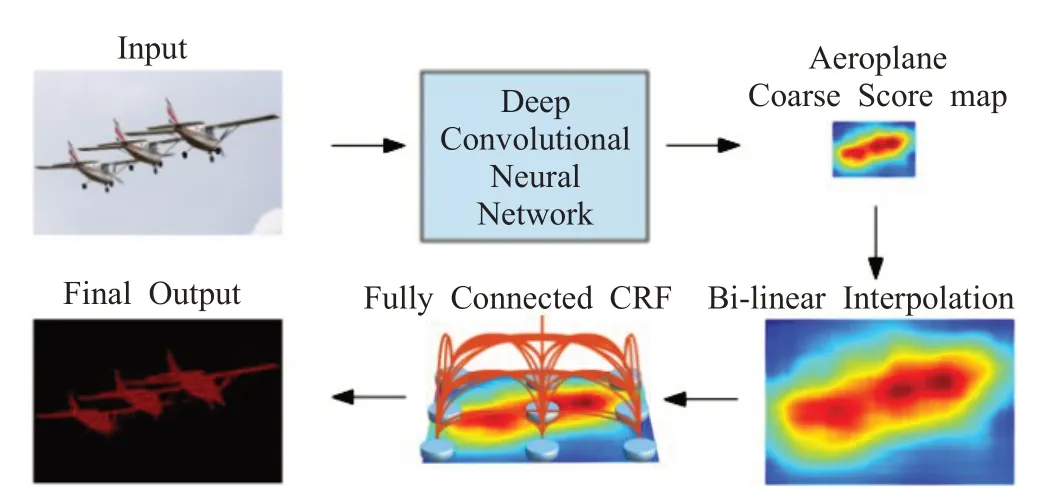
圖3 DeepLab v1架構
(4)DeepLab v2
DeepLab v2[30]在DeepLabv1的基礎上進行了改進,引入了空間金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)結構,以融合不同級別的語義信息,改進Deep-Labv1未融合不同層信息的不足。具體的處理方法是,選擇不同擴張率的空洞卷積處理特征圖,由于感受野不同,得到信息的層級也不同。ASPP 層把這些不同層級的特征圖連接到一起,進行信息融合,如圖4。
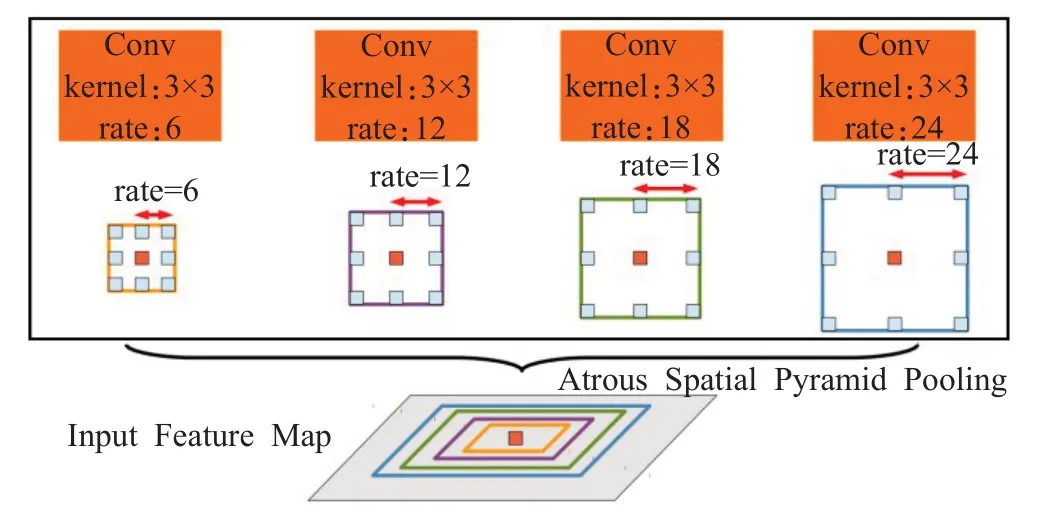
圖4 ASPP結構
作為DeepLab系列中的經典網絡架構,DeepLab v1和DeepLab v2已經在遙感影像處理[31]、城市街景解析[32]以及室內場景分析等實際場景中應用。
(5)RefineNet
在前述的幾種語義分割架構中,為了提取更復雜的特征、構建更深的神經網絡,許多算法往往會以犧牲空間分辨率的方式,在盡量少地增加計算量的前提下,換取特征通道數的增加。雖然這種方式有諸多優點,但是空間分辨率的下降是其明顯的缺陷。
為了解決這一問題,同時更好地優化語義分割結果,RefineNet[33]提供了一個能夠良好融合高分辨率語義特征和低分辨率語義特征的模塊來生成高分辨率的分割圖。RefineNet模型的整體架構如圖5所示,RefineNet包括三大模塊:殘差卷積模塊(Residual Convolution Unit,RCU)、多分辨率融合模塊(Multi-Resolution Fusion)鏈式殘差池化模塊(Chained Residual Pooling)。
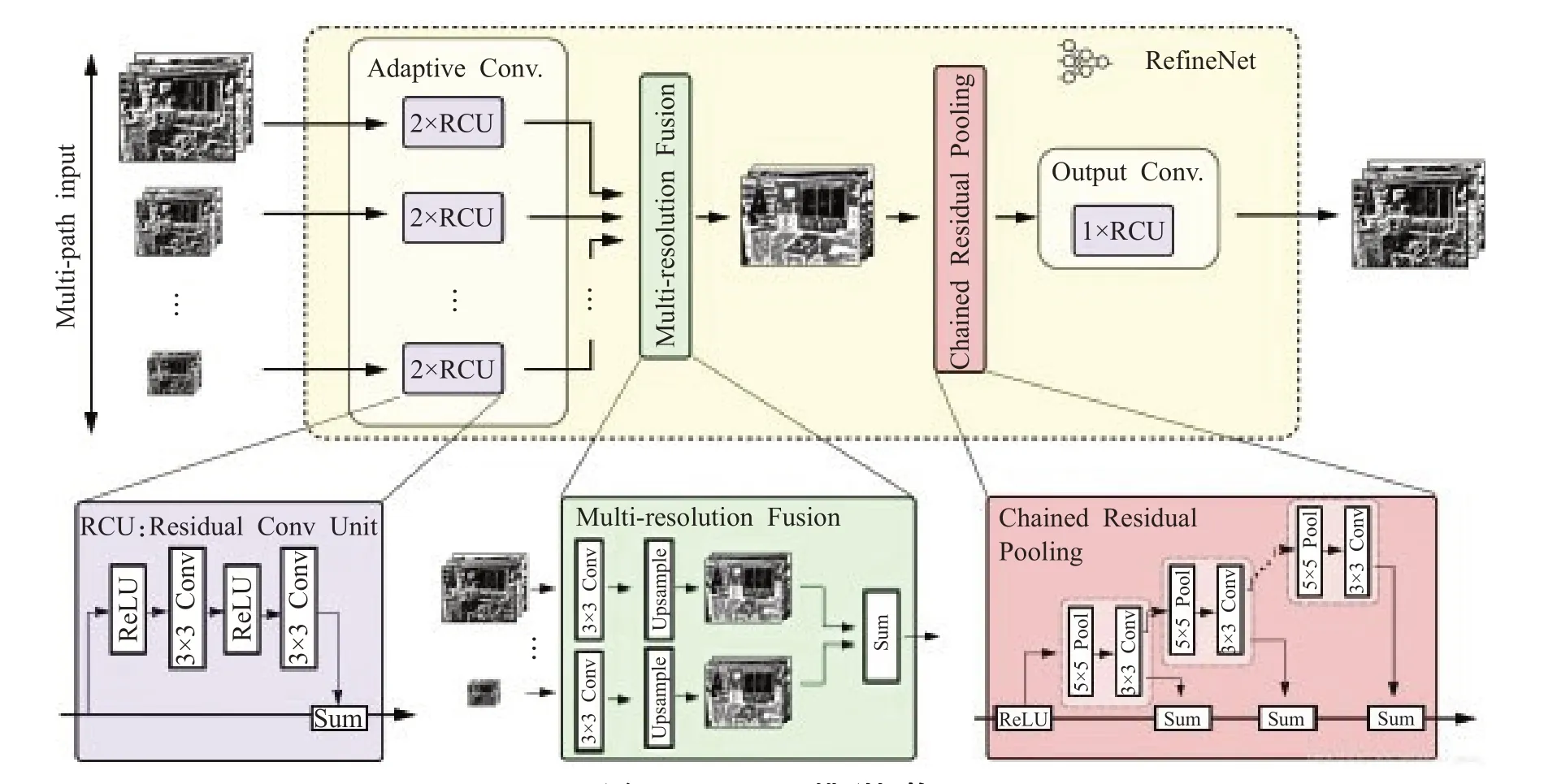
圖5 RefineNet模型架構
殘差卷積模塊從不同尺度的圖像中抽取底層特征;多分辨率融合模塊,抽取中間層特征對多尺度的特征進行融合,以解決因為下采樣導致的信息丟失問題;鏈式殘差池化模塊,抽取高層特征,不同池化相當于不同大小的窗口,在整合不同尺度特征后通過卷積加權在一起,從而捕獲背景上下文信息。
(6)PSPNet
語義分割過程中,對圖像語義場景的解析或理解極為關鍵。然而,早期的多數架構都是基于FCN的,沒有引入足夠的上下文信息及不同感受野下的全局信息,容易導致錯誤的分割結果。PSPNet[34]提出了一個具有層次全局優先級、包含不同子區域之間不同尺度信息的模塊,稱為金字塔池化模塊(Pyramid Pooling Module),如圖6 所示。它充分利用全局特征層次的先驗知識對不同場景進行理解,聚合不同區域的上下文信息以獲取全局上下文的內容。同時,PSPNet 還提出了一個適度監督損失的優化策略,在多個數據集上表現優異。與全局金字塔池化不同的是,可以通過PSPNet 對不同區域信息的融合來實現全局上下文信息的融合。
總之,PSPNet 為像素級場景解析提供了有效的全局上下文先驗,金字塔池化模塊可以收集具有層級的信息,比全局池化更有代表性。并且,PSPNet和帶空洞卷積的FCN 相比,并沒有增加多少計算量。在端到端的學習中,全局金字塔池化模塊和局部FCN 功能可以同時訓練和優化。可以說,PSPNet 同時利用局部和全局信息,更好地提取全局上下文信息,使得場景識別更加可靠。
RefineNet 和PSPNet 已經應用在醫療影像[8]、農業信息[35-36]、遙感圖像[37]等領域,通過特征融合的思想,對圖像上下文語義進行捕獲,實現不同尺度信息整合,獲得了良好的性能表現。
3.2 語義分割的前沿網絡架構
2017 年以來,在技術的推動下,經典網絡架構有新的突破;同時,新的設計思想和觀點又催生出新的網絡架構。這些網絡架構代表了語義分割的前沿方向。
(1)DeepLab v3
如圖7 所示,DeepLab v3[38]在DeepLabv2 模型的基礎上,作了以下改進:①放棄了CRF 操作;②改進了ASPP 模塊,加入了批規范化(Batch Norm,BN)操作;③為了防止空洞卷積感受野的擴張率過大導致的“權值退化”現象,增加了全局平均池化結構,利用全局信息,以強調和加強全局特征。
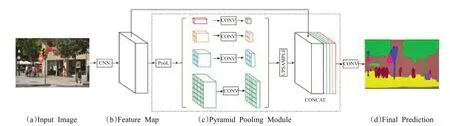
圖6 PSPNet模型架構
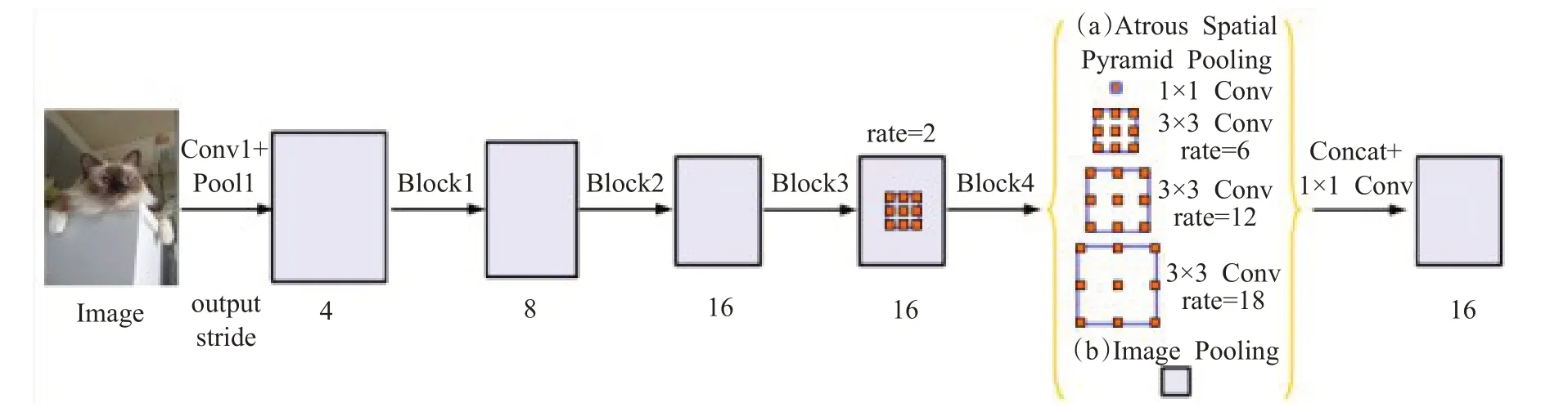
圖7 DeepLab v3模型架構
DeepLab v3 通過編碼多尺度信息,增強圖像級的特征,獲得了比DeppLab v1、DeppLab v2 更加良好的實驗效果,并取得了與其他先進模型相當的性能。
(2)DeepLab v3+
DeepLabv3+[39]提出了一個全新的編碼-解碼結構,如圖8 所示。該模型使用DeepLab v3 作為編碼器模塊,并增加了一個簡單卻有效的解碼模塊,逐漸恢復空間信息以捕捉清晰的目標邊界;并且在解碼過程中對不同層級特征進行融合,進行多尺度上下文信息的探索。此外,對編碼模塊進行了優化處理,加入了Xception[40]結構以減少參數量,提高運行速度。
DeepLab v3+在提出的編碼-解碼架構中,通過空洞卷積直接控制提取編碼特征的分辨率,在精度和運行時間之間尋找平衡點。將Xception結構應用于分割任務,在編碼模塊中的ASPP部分和解碼模塊分別加入深度可分卷積,在減少計算消耗和參數量的同時維持了相似的性能表現,得到了強大又快速的模型。
(3)Auto-DeepLab
Auto-DeepLab[41]是近期由李飛飛帶領的團隊提出的自動搜索圖像語義分割架構的算法。該架構首次將神經架構搜索(Neural Architecture Search,NAS)引入到語義分割領域,自動搜索網絡架構。利用研究提出的分層神經架構搜索方法確定最優網絡架構和單元架構,完成圖像語義分割任務,性能超越了很多業內主流的模型,甚至可以在未經過預訓練的情況下達到預訓練模型的水平。Auto-DeepLab 開發出與分層架構搜索空間完全匹配的離散架構的連續松弛結構,顯著提高架構搜索的效率,降低計算需求。
(4)DANet
DANet[42]是一種新型的場景語義分割網絡,利用“自注意力機制”捕獲豐富的語義信息。如圖9 所示,DANet在帶有空洞卷積的ResNet[43]架構的尾部添加兩個并行的注意力模塊:位置注意力模塊(Position Attention Module)和通道注意力模塊(Channel Attention Module)。在位置注意力模塊中,任一位置的特征更新是通過圖像所有位置特征的加權聚合實現的,權重是由兩個位置上特征的相似性決定的,即無論兩個位置的距離多遠,只要特征相似就能得到更高的權重。
在通道注意力模塊中,也應用了類似的自注意力機制來學習任意兩個通道映射之間的關系,同樣通過所有通道的加權和來更新某一個通道。
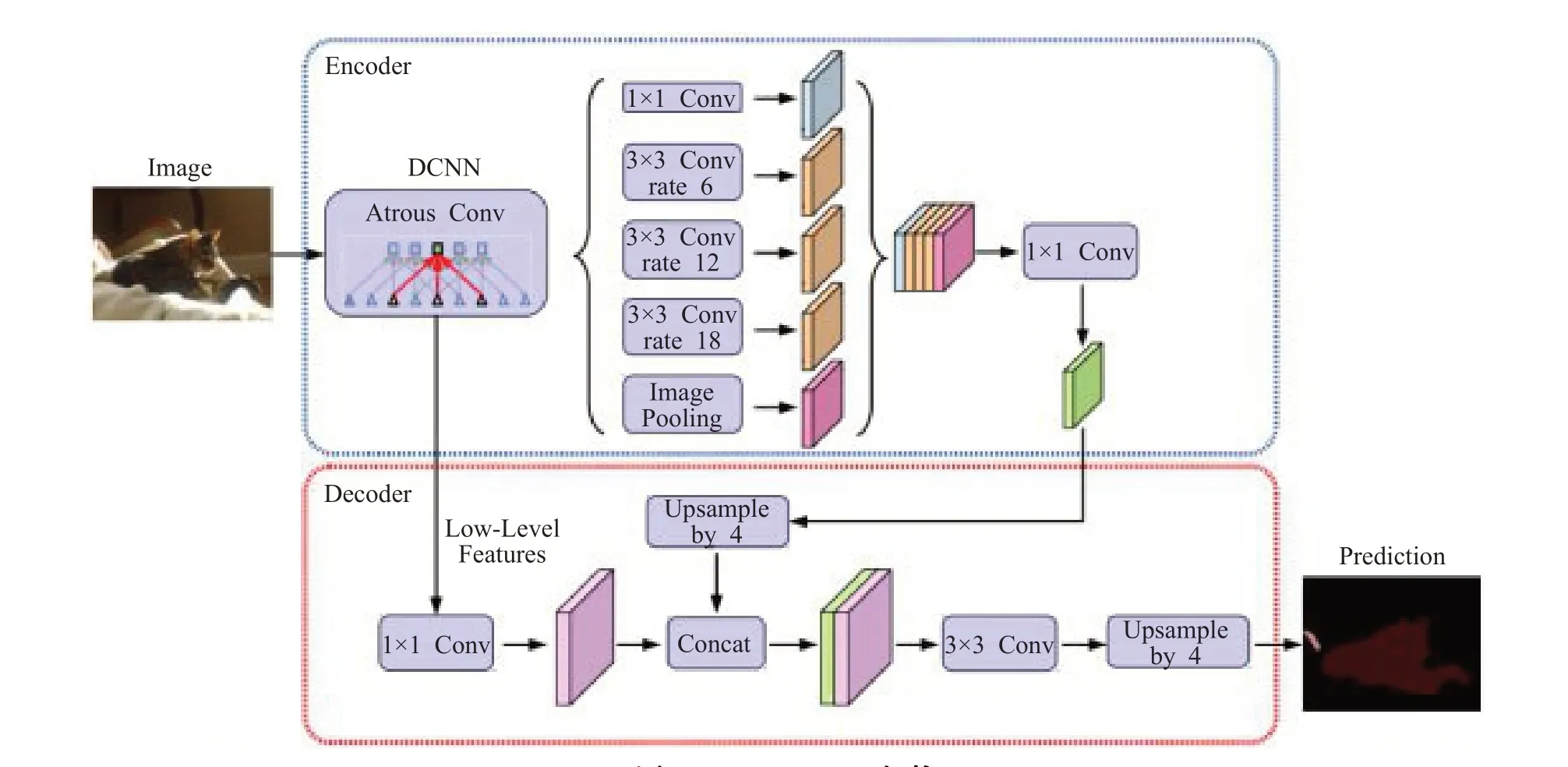
圖8 DeepLab v3+架構

圖9 DANet模型架構
為了更好地利用兩個注意力模塊的全局語義信息,將模塊的輸出經過一個卷積層后進行逐元素的加和實現特征融合,最后通過一個卷積層得到最終的預測結果。
DANet在PASCAL Context[44]、MS COCO[45]和Cityscapes[46]數據集上取得的顯著效果說明,該架構在處理圖像語義的復雜場景方面更加高效靈活。該架構選擇性地聚合了顯著和不顯著對象的相似語義特征,并從全局視角自適應地集成各種尺度的相似空間關系,將通道關系和空間關系有效結合,進一步增強了特征表示能力。
3.3 綜合分析
語義分割的網絡架構從FCN 開始,不斷融入CRF、ASSP等行之有效的技術,在語義分割速度、準確度等方面不斷提升。現階段,語義分割的架構旨在優化分割結果的精確度和提高分割效率,以便在圖像語義實時處理領域進行應用。對上述網絡架構進行了綜合分析,并從主要思想、優缺點、關鍵技術和主要功能等幾個方面進行了對比總結,如表1所示。
4 常用數據集
在深度圖像語義分割領域的實踐中,收集并創建一個足夠大且具有代表性的應用場景數據集,對于任何基于深度學習的語義分割架構都是極為重要的。這需要大量的時間、專業領域的知識,同時也需要相關的軟硬件設施使得架構可以正確理解與學習捕捉到的數據。而且,使用一個現有的、有足夠代表性的標準數據集可以保證架構之間的性能對比更加公平[47]。
下面介紹圖像分割領域目前最受歡迎的大規模數據集,表2從數據集的應用場景、類別數目、發布時間以及訓練集、驗證集、測試集等方面進行了劃分整理。
(1)Cambridge- driving Labeled Video Database(CamVid)[48-49]。是由Brostow 等人在2009 年建立的道路、駕駛場景理解數據集,從車載攝相機拍攝的5 個視頻流中采樣出了701 幅圖像,共32 類物體,如建筑、墻、樹、植被等。
(2)Semantic Boundaries Dataset(SBD)[50]。是PASCAL數據集的擴展,包含21類,共11 355張標注圖像。數據集所提供的標注中除了有每個物體的邊界信息外,還有種類級別及實例級別的信息。
(3)PASCAL VOC 2012[51]。是為圖像分類和語義分割等任務發布的一套數據集。其中的圖像主要是常見生活物體,共劃分為21類,包括人、動物、植物和交通工具等。2014年,Mottaghi R等人在此基礎上重新標注了約10 000 幅圖像,將訓練圖像的數量提升到10 582個,稱為PASCAL VOC 2012+[52]。
(4)NYU Depth Dataset v2(NYUDv2)[53]。是由微軟Kinect 設備采集的室內的RGB-D 圖像,由一系列表示各種室內場景的視頻序列組成,共包含40 個類別的1 449張像素級標注的圖像數據。但該數據集相對于其他數據集規模偏小,限制了其在深度網絡中的應用。
(5)PASCAL Context[44]。由PASCAL VOC 2010數據集改進和擴展而來,數據集中增加了更多物體像素級別的標注和場景信息,共包含540個語義類別。雖然種類繁多,但是在算法評估時,一般選取前59類作為分割評判標準,其他類別標記為背景。
(6)PASCAL Part[54]。是PASCAL-VOC 2010 識別競賽的擴展,在原有數據集基礎上對圖像中每個物體的部分提供了一個像素級別的分割標注,能夠提供豐富的細節信息,可為物體解析和圖像分割任務提供詳細標注的樣本。
(7)Microsoft Common Objects in Context(MS COCO)[45]。最初來自于微軟圖像測試的一個大型數據庫,數據集規模巨大,內容豐富,共包含81種類別(包括背景)、328 000張圖像、2 500 000個物體實例和100 000個人體關鍵部位標注,圖像從復雜的日常場景中獲取,圖像中的物體具有精確的位置標注。
(8)Cityscapes[46]。是一個城市街道場景解析的大規模數據集,主要提供無人駕駛環境下的圖像分割數據,用于評估算法在城區場景語義理解方面的性能。該數據集提供約5 000張精細標注的圖片和20 000張粗略標注的圖片,涵蓋了30種語義、實例以及密集像素標注的類別,包括平坦表面、人、車輛、建筑等。數據是從50個
城市中持續數月采集而來,涵蓋不同環境、不同背景、不同季節的街道場景,具有動態信息豐富、場景布局多樣和街道背景復雜等特點。
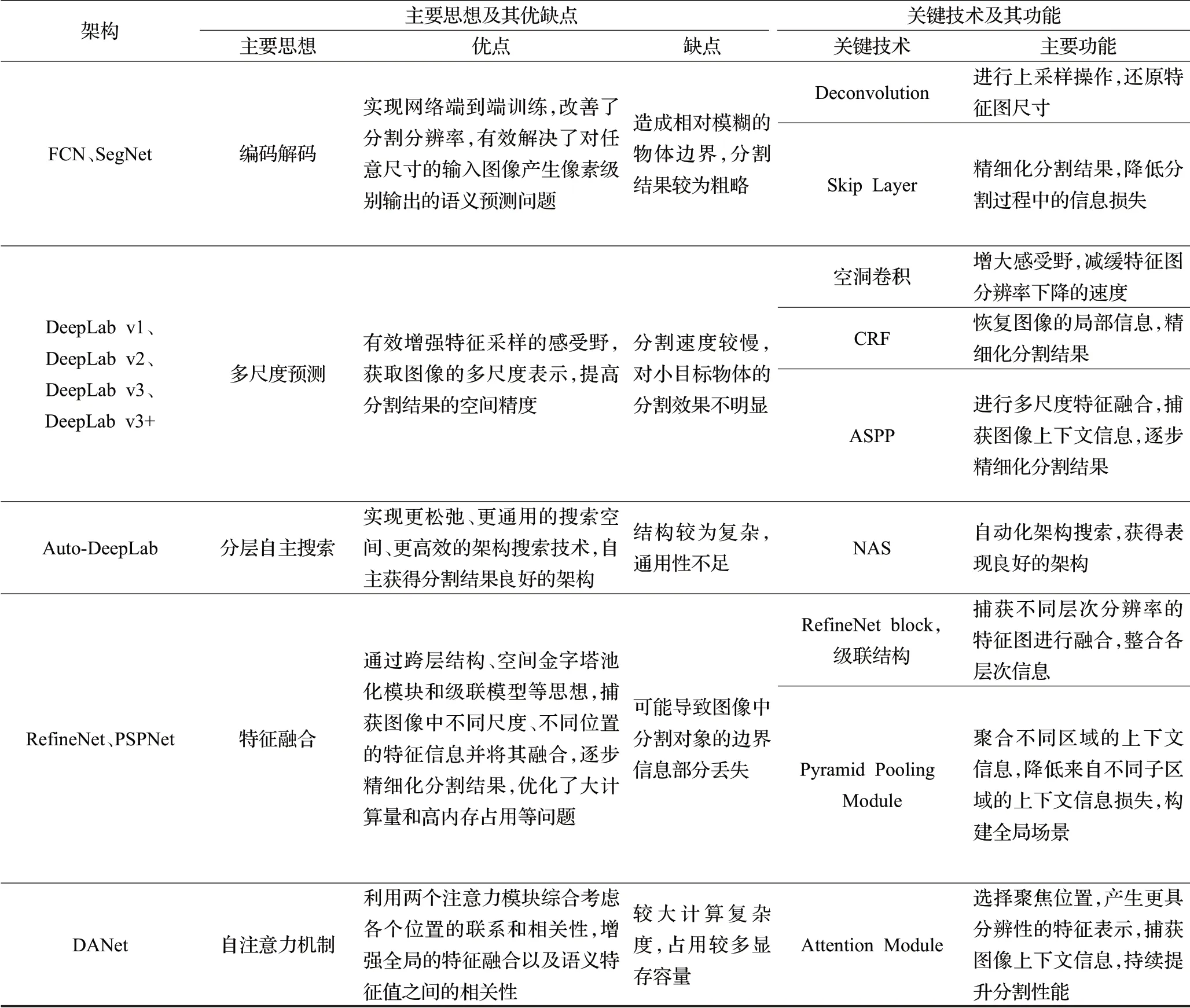
表1 語義分割典型網絡架構的對比總結
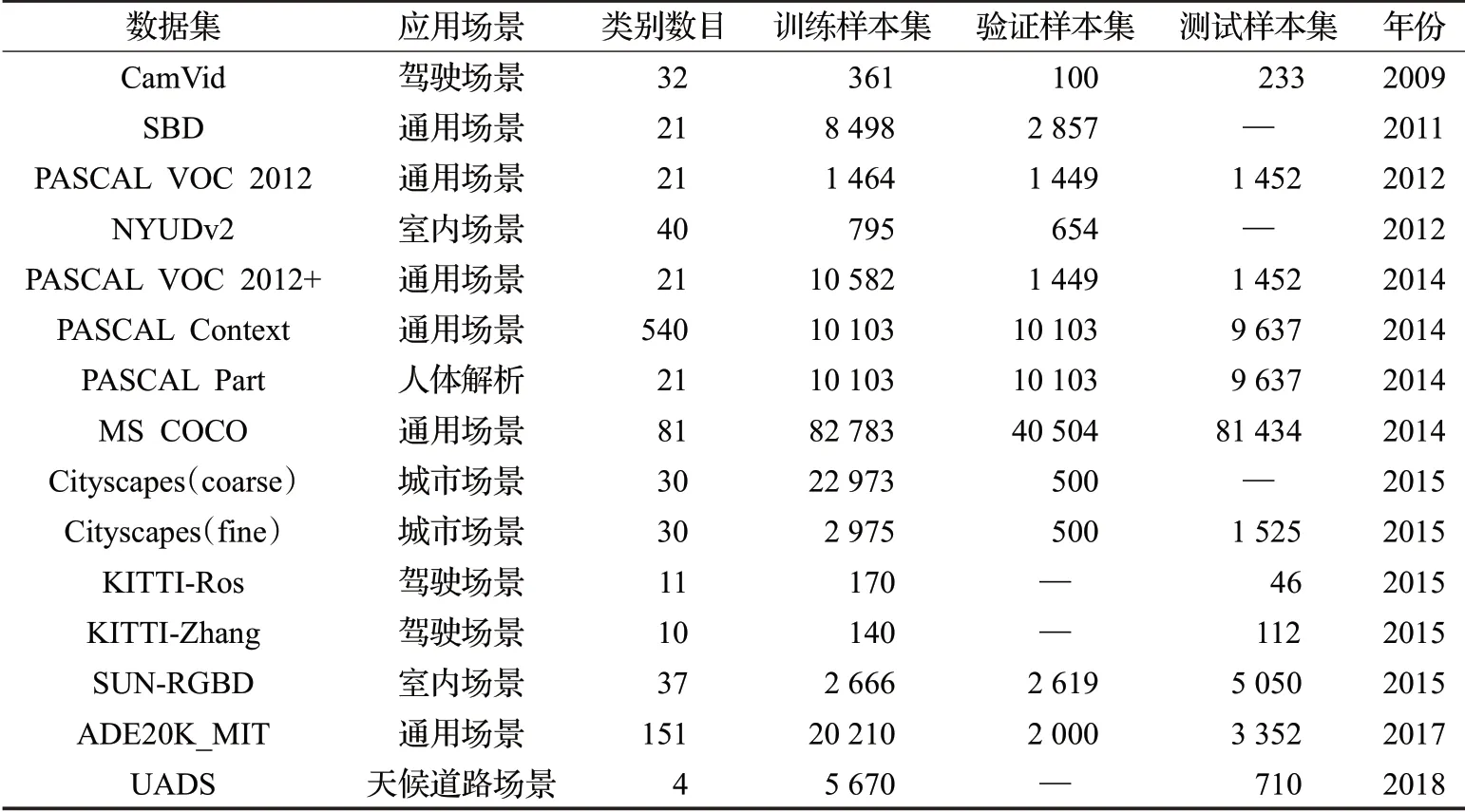
表2 深度圖像分割常用數據集
(9)Karlsruhe Institute of Technology and Toyota Technological Institute(KITTI)[55]。包含市區、鄉村和高速公路等真實場景圖像,是近幾年在智能機器人和無人駕駛領域廣受歡迎的數據集之一。研究者使用高分辨率RGB、灰度立體攝像機和三維激光掃描儀等多種類型傳感器采集交通場景數據,用于評測車載環境下路面分割、目標檢測、目標跟蹤等技術。該數據集并沒有提供完整的語義標注,先后由Alvarez 等人[56-57]、Zhang 等人[58]、Ros 等人[59]為該數據集的部分數據手工添加語義標注以滿足其問題的需求。
(10)SUN-RGBD[60]。圖像由四個RGB-D 傳感器得來,尺寸與PASCAL VOC一致,整個數據集均為密集標注,包括多邊形、帶方向的邊界框以及三維空間,共包含10 000張RGB-D圖像、146 617個多邊形標注、58 657個邊界框標注以及大量的空間布局信息和種類信息,適合于場景理解任務。
(11)ADE20K[61]。是一個場景理解的新的數據集,由151個類別(包括背景)、20 210張場景圖片組成,包括各種物體(如人、汽車等)、場景(天空、路面等)。
(12)UESTC All-Day Scenery(UADS)[62]。旨在提供全天候道路圖片以及對應的二值標簽用以標識圖像中的可行區域與不可行區域。整個數據集包含四種天候(黃昏天候,夜間天候,下雨天候和艷陽天候)共計6 380張圖像。
5 圖像語義分割的性能評價
5.1 性能評價指標
為使分割架構能夠在特定領域發揮實際作用并產生重大貢獻,必須對其性能進行嚴格評估。同時,為了對架構性能進行公平比較,必須使用標準的、被所屬領域認可的指標進行評估[63]。評估的維度必須多樣化,以證明架構的有效性和有用性。在實際應用中會根據需求或目的對相關指標進行取舍,如在實時應用場景中,更加關注處理速度,在一定程度上需要犧牲精度。然而,為了保證科學的嚴謹性,需要為架構方法提供所有可能的評價指標。下文從執行時間、內存占用和準確性三個方面對分割架構的性能指標進行闡述。
(1)運行時間
運行時間或處理速度是一個非常有價值的度量標準,因為絕大多數方法架構必須滿足處理數據過程中花費時間的嚴格要求。但是,該評價指標非常依賴于硬件和后端實現,在某些情況下,為這些方法架構提供精確的時間的比較是毫無意義的[20]。
大多數情況下,運行時間可以用于評估架構對實際應用是否有用,并在相同條件下進行公平比較,以檢查哪種方法最快。
(2)內存占用
內存占用是評估分割方法架構的另一個重要指標。盡管在條件允許的情況下可以通過擴展內存容量的方式使內存占用不像運行時間那樣受限,但在某些特定情況下它也可能成為一個限制因素。實際應用場景中,內存配置是固定的,一般不會因為算法要求而動態調整,而且即使是普通的用于加速深度網絡的高端圖形處理單元(GPU)也不會搭載大容量內存。因此,詳細記錄方法架構在實驗中占用的最大及平均存儲空間是非常有用的。
(3)準確度
在語義分割領域中,有幾項經典的用于評估方法架構準確度的標準。評估語義分割結果時,一般來說選取像素準確度(Pixel Accuracy,PA)[20]、平均準確度(Mean Accuracy,MA)[20]、交并比(Intersection over Union,IoU)[20]以及平均交并比(mean Intersection over Union,mIoU)[20]等幾項評價指標進行綜合分析。為方便理解,對以下公式中的相關符號做如下說明:K 表示圖像像素的類別的數量;ti表示第i 類的像素的總數;nii表示實際類型為i、預測類型為i 的像素總數;nji表示實際類型為i、預測類型為j 的像素總數[63]。
像素準確度PA表示正確分割圖像的像素數量與像素總數之間的比率:

交并比IoU 表示分割結果與原始圖像真值的重合程度,在目標檢測中可以理解為系統預測的檢測框與原圖片中標記檢測框的重合程度,取值范圍在[0,1]區間:
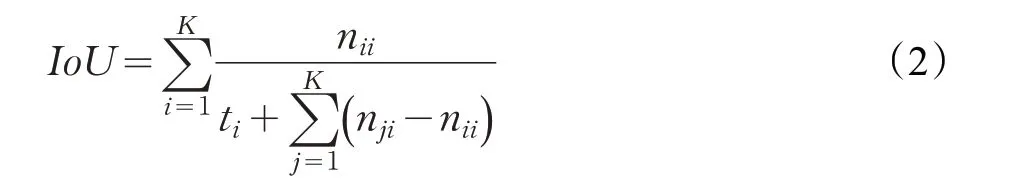
平均交并比mIoU表示圖像像素的IoU在所有類別上的平均值:
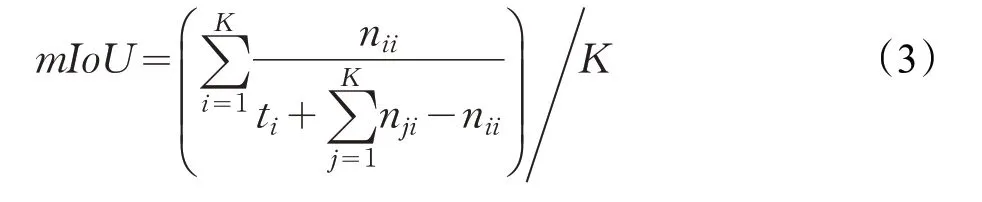
其中,mIoU指標的代表性和簡單性非常突出,是目前圖像語義分割領域使用頻率最高和最常見的準確度評價指標,大多數研究人員都利用這個指標來評判他們的語義分割結果。
5.2 實驗分析與性能對比
由于各個架構在功能側重、改進技術和應用場景等方面都不相同,無法利用運行時間和內存占用指標進行統一衡量,但可以采用準確度評價指標橫向對比不同架構的性能。下文以提升架構的分割準確度為研究重點,利用mIoU 評價指標,對上述語義分割典型網絡架構在相應數據集上進行了測試實驗和性能對比。
表3 是對各主流語義分割典型架構在PASCAL CONTEXT、MS COCO、Cityscapes 等數據集上的實驗結果數據。
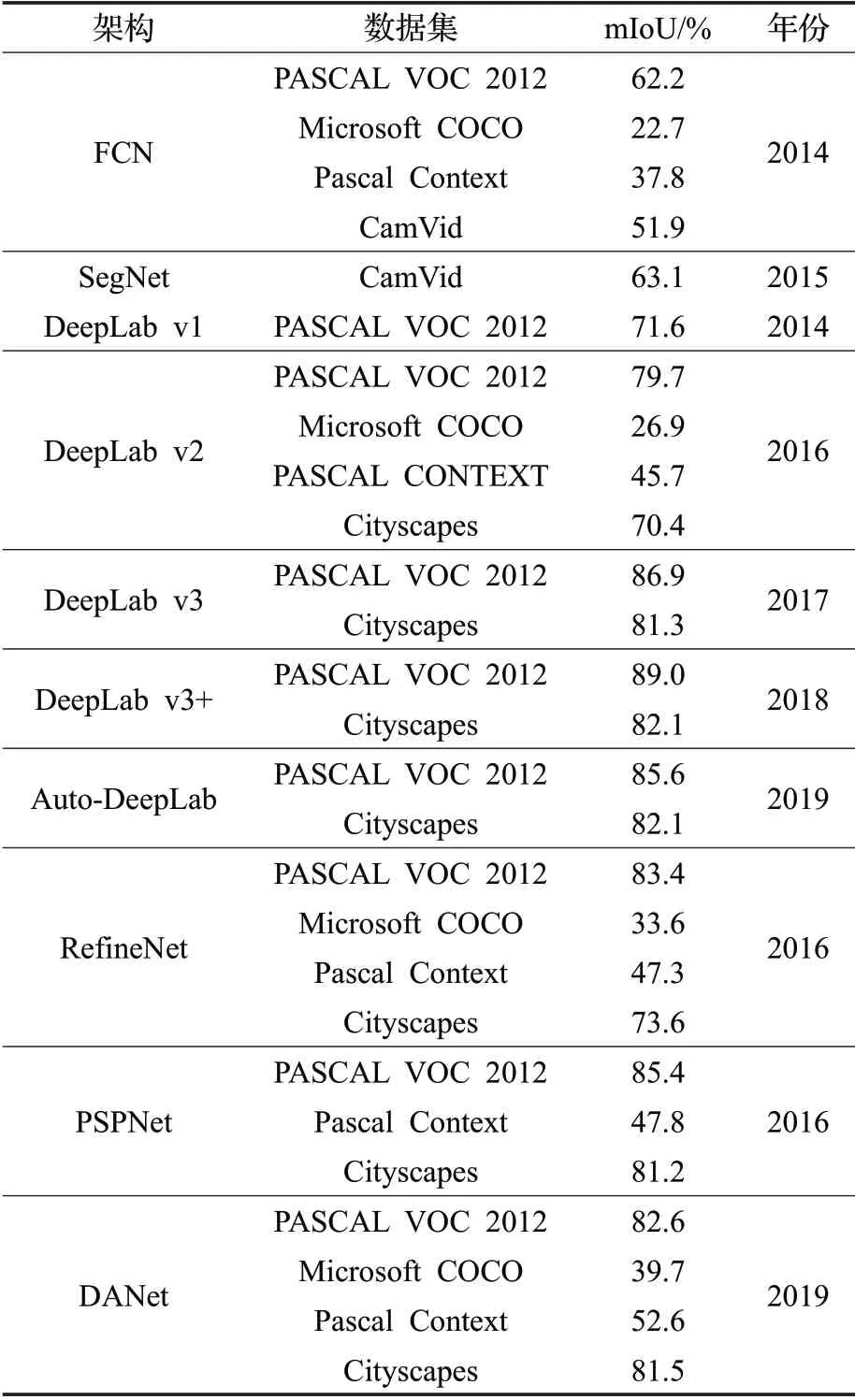
表3 深度圖像語義分割網絡架構的實驗結果
從表3 可以看到,在數據集方面,不同的語義分割架構根據應用場景和分割特點的不同,選用的數據集也不同。PASCAL VOC 2012 作為靜態圖像進行語義分割的測試數據集,相較于其他數據集,語義分割架構在該數據集上的實驗結果表現最佳;當進行實時圖像語義理解或動態場景解析時,大多選用CityScapes作為測試數據集;多數分割架構在MS COCO數據集上的表現并不理想,一方面因為該數據集中圖片的背景更復雜,每張圖片上的實例目標個數多,小目標更多;另一方面,MS COCO評估標準比其他數據集更加嚴格。
在語義分割架構方面,PASCAL VOC 2012數據集上有相當一部分架構的mIoU 指標都超過了80%,如DeepLab v3+、RefineNet 等,這些架構對圖像中不同尺度的物體有較好的識別效果,實驗所得分割結果的邊界比較接近真實分割邊界,是最具代表性的圖像語義分割架構。其中,DeepLab v2 由于性能穩定和分割準確率較高等優點,被廣泛用于分割靜態圖像;DeepLab v3+架構因為集成了FCN、DeepLab v2等眾多網絡的優點,其mIoU 指標目前排名最高;PSPNet 與RefineNet 通過多尺度、多路徑的技術對圖像進行高效特征提取和融合,有效捕捉圖像中豐富的上下文信息,分割效果良好,mIoU 指標得分也十分靠前。作為最新研究的架構,DANet 在Pascal Context 數據集上獲得的mIoU 指標得分超過50%,這是之前的架構所達不到的;Auto-DeepLab作為語義分割架構的搜索架構,在PASCAL VOC 2012和CityScapes 數據集的上實驗表現相當出色,mIoU 指標均達到了80%以上,效果甚至超越許多成熟架構,這也為語義分割架構的研究提供了新的思路。
6 結束語
隨著計算機性能的提升和語義分割算法架構的不斷優化,基于深度學習的圖像語義分割技術在計算機視覺領域將發揮越來越大的作用,同時也面臨著諸多挑戰:
(1)輕量化的網絡架構。隨著移動端、嵌入式設備對語義分割技術的需求不斷擴展,如何在簡化架構、壓縮和復用計算需求上生成更加輕量化的網絡架構同時又能保證準確率,將是今后深度圖像語義分割技術的重要發展方向。
(2)小數據集下的架構設計。在實際工程應用尤其是專有領域中,如醫療影像等,絕大多數情況下會面臨目標數據來源少、規模小的情況。在沒有大規模訓練數據集的前提下,設計合理的網絡架構以適應小規模數據集的現實情況尤為重要,這是技術與實際場景結合的重要環節。
(3)提升小目標圖像分割的效率。目前,針對小目標圖像語義分割的算法架構還不能完全滿足實際場景應用的要求,依舊存在漏檢測、分割邊界模糊等問題。如何對小目標圖像進行精確、高效分割是目前深度圖像語義分割領域的重要研究方向。
(4)實現超大尺寸圖像的分割[64]。隨著圖像采集技術的發展,圖像分辨率將大幅提升,今后4K圖像將成為主流。但目前的大部分深度圖像語義分割框架還不能滿足這一實際需要,在超大尺寸圖像的處理方法與處理效率方面還存在很大的挑戰。從技術的發展趨勢來看,針對超大尺寸圖像的分割也是深度圖像語義分割領域未來的發展方向。
圖像語義分割作為計算機視覺領域的重要技術,面對未來應用場景更加豐富、需求更加嚴苛的形勢,也將面臨更多的挑戰。因此,對基于深度學習的圖像語義分割技術的研究和探索任重道遠。
猜你喜歡
小學時代·科學小問號(2024年10期)2024-10-31 00:00:00
開放教育研究(2020年2期)2020-03-31 01:54:14
中國社會歷史評論(2016年2期)2016-06-27 07:11:52
現代語文(2016年21期)2016-05-25 13:13:44
長江學術(2016年4期)2016-03-11 15:11:31
中學語文·大語文論壇(2015年1期)2015-05-30 22:02:35
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語言與翻譯(2014年2期)2014-07-12 15:49:25
語文知識(2014年2期)2014-02-28 21:59:18
當代修辭學(2011年6期)2011-01-29 02:49:50
