基于FCN的多方向自然場景文字檢測方法
2020-01-17 01:44:14楊劍鋒王潤民李秀梅錢盛友
計算機工程與應用 2020年2期
楊劍鋒,王潤民,何 璇,李秀梅,錢盛友
1.湖南師范大學 信息科學與工程學院,長沙410081
2.湖南師范大學 物理與電子科學學院,長沙410081
1 引言
文字相較其他的自然場景內容具有高度的概括性與描述性,自然場景文字檢測技術在圖像/視頻檢索、智能手機或可穿戴式視覺系統等方面具有重要的應用價值,目前自然場景文字檢測已成為計算機視覺與模式識別、文檔分析與識別領域的研究熱點。然而自然場景文字檢測有別于傳統的印刷文檔中的文字檢測,印刷文檔圖像中的文字字體規范且背景簡單,文字與背景之間具有明顯的差異性,從而背景信息對文字難以造成強烈的干擾。然而在自然場景圖像中,受文字本身及其他干擾因素的影響,文字與背景之間很難得到有效地分割,比如:文字與背景對比度低、光照不均勻等。此外,自然場景文字還存在大小尺寸、空間布局、顏色及排列方向的多變性,這些干擾因素均給文字檢測帶來巨大的挑戰。相比成熟的印刷文檔中的文字檢測問題,自然場景文字檢測仍具有較大的提升空間。
基于自然場景文字檢測技術所具有的理論意義與應用價值,該領域受到了研究者的廣泛關注并提出了大量有效的文字檢測方法。現有的文字檢測方法主要采用了手工設計的特征(Handcraft Features)以及深度學習提取的特征來分類文字區域與背景區域。
基于手工設計特征的傳統文字檢測方法[1-9]大致分為三類:基于滑動檢測窗方法、基于連通域分析方法以及混合方法。基于檢測窗的文字檢測方法[1-2]通常采用多尺度滑動窗口的方式對圖像進行掃描以獲得文字候選區域,然后使用分類模型判斷候選區域是否是文字區域。基于連通域分析的文字檢測方法[3-6]主要通過顏色聚類方法(Color Clustering)、文字筆畫寬度變換(Stroke Width Transform,SWT)、最大穩態極值區域(Maximally Stable Extremal Regions,MSERs)等方法提取文字候選連通域,然后使用分類模型對文字候選連通域進行判斷,最后設計一系列后續關聯組合和分詞手段來獲取最終文字區域。混合方法[7]結合了基于滑動檢測窗方法和基于連通域分析方法,利用這兩類方法的優勢來提高文字檢測性能。盡管采用手工設計的特征方法可以取得不錯的表現,但手工設計的特征無法有效地應對復雜的自然場景情形,比如光照不均勻或者部分遮擋等。
基于深度學習的文字檢測方法[10-17]相較于手工設計的特征方法在文字檢測性能上取得了很大的突破。在基于深度學習的自然場景文字檢測方法中,基于文字區域建議(Text region proposal)的方法和基于圖像分割的方法使用最為廣泛。基于區域建議的文字檢測方法[10-13]一般先在圖像上提取很多個文字候選區域,然后訓練一個分類器對文字候選區域分類篩選,最后對包含文字的候選區域的位置進行精修。基于文字區域建議的文字檢測方法對復雜的自然場景文字檢測具有很好的魯棒性,但提取多個文字候選區域往往很耗時。基于圖像分割的文字檢測方法[14-16]通常利用全卷積網絡(Fully Convolutional Networks,FCN)等方式來進行像素級別的文字/背景標注,該類方法可以較好地避免文字排列方向以及文字區域長寬比變化的影響,但其后續處理通常比較復雜。Zhang等人在文獻[14]中首次提出采用全卷積網絡從像素層面對圖像進行處理,預測每個像素屬于文字的概率,進而獲得文字顯著圖,最后基于顯著圖得到文字候選區域。
為獲得最終的文字檢測結果,目前主要采用了文字邊界框回歸處理以及直接提取外接文字邊界框的方法。在文獻[15-16]中均采用了全卷積網絡輸出文字區域像素級檢測結果,然后回歸邊界點來確定候選文字邊界框的位置,最后采用非極大值抑制(Non-Maximum Suppression,NMS)去篩選出邊界框作為最終檢測結果。TextBoxes[10]、SegLink[18]、CTPN[11]在獲取文字邊界檢測框時同樣采用位置回歸方法,可以得到精確的文字邊界框,這類方法均取得不錯檢測效果,但往往以犧牲計算量為代價。在文獻[19]中直接通過實例分割處理來獲得文字位置信息而無需進行文字邊界框回歸處理,結合文字與非文字預測和像素連接預測的信息來提取文字邊界框。直接提取外接文字邊界框的方法從整體上處理文字行,充分利用了預測文字候選區域的方向信息檢測多方向排列文字。本文受到文獻[19]方法啟發,利用文字與非文字預測得分圖信息獲取外接文字邊界框,取得了更好的檢測效果。
通常自然場景圖像中的一些文字間距非常近,使得在文字與非文字預測得到的文字候選區域會難以完全分隔開,在獲取外接文字邊界框時會導致多個文字被檢測到一個矩形邊界框中。為解決這個問題,在生成文字標簽時放棄選擇標注的文字區域,而是選擇標注文字區域的縮進區域。因此,在分割的得分圖上得到的邊界框區域會是真實文字的縮進區域,為此本文設計了自適應的加權擴大函數對參考邊界框進行補償擴大處理,使得最終邊界框能完全包圍文字區域。
本文創新點包括以下幾個方面:
(1)全卷積網絡結合多特征層融合,通過像素級分類,取得了更有競爭力的結果。
(2)設計簡單而高效的方法實現了多方向文字檢測。
(3)縮進的標注文字區域生成得分圖,解決了單個邊界框檢測多個文字問題。
2 基于FCN的多方向場景文字檢測方法
本文所提出的文字檢測框架如圖1(a)所示,輸入待檢測圖像送入到已訓練好的卷積神經網絡模型中,提取圖像中的文字特征,結合全卷積網絡上采樣并逐層融合多層特征圖進行像素分割,輸出得到每個像素的預測得分圖。預測得分圖采用雙線性插值擴大和二值化處理后,直接獲取預測文字候選區域的外接文字邊界框作為參考文字邊界框,然后進行加權補償處理來修正參考文字邊界框,最后通過篩選條件過濾掉非文字邊界框得到最終的文字檢測框。如圖1所示,本文算法僅僅由兩個步驟組成,全卷積網絡FCN 多尺度特征融合部分和生成并補償文字邊界框部分,相比文獻[11,14,20]中的算法更為簡單,去除了很多中間步驟,省略了多個處理環節,避免了多個處理環節和組成部分可能局部最優但整體未必最優以及耗時的問題,任何環節的處理結果都將會影響系統的檢測性能。在圖1中,(b)為文獻[11]中提出方法,通過CTPN實現水平方向文字檢測;(c)為Yao等人在文獻[20]中提出的方法;(d)為文獻[14]中提出的方法。
2.1 網絡結構
本文方法所提出的基于全卷積網絡的文字檢測模型如圖2 所示,該模型主要由三個部分組成:特征提取網絡,特征融合部分和文字與非文字預測。首先把自然場景文字圖像送入模型中,使用特征提取網絡來提取圖像中的文字特征,然后結合全卷積網絡(FCN)語義分割的方法對圖像進行像素級分類,預測每一個像素是否為文字區域,從而分割出文字區域提取出自然場景圖像中可能出現的文字位置。該模型采用U-Net[21]的思想融合淺層網絡與深層網絡的多層特征圖,綜合了精細信息及其高度抽象信息,用于檢測不同尺度的文字。
2.1.1 特征提取網絡
自然場景文字檢測作為一種典型的模式識別問題,文字描述特征分類性能的好壞將直接影響到最終的檢測結果。本文方法所采用的網絡結構參數如表1所示,特征提取網絡使用ResNet-50[22]作為基礎網絡來提取文字特征,其中Conv1,Res2,Res3,Res4,Res5均為ResNet-50中的操作,每一次操作后分別輸出的該層的特征圖,其尺寸大小分別為輸入圖像的1/2,1/4,1/8,1/16,1/32。
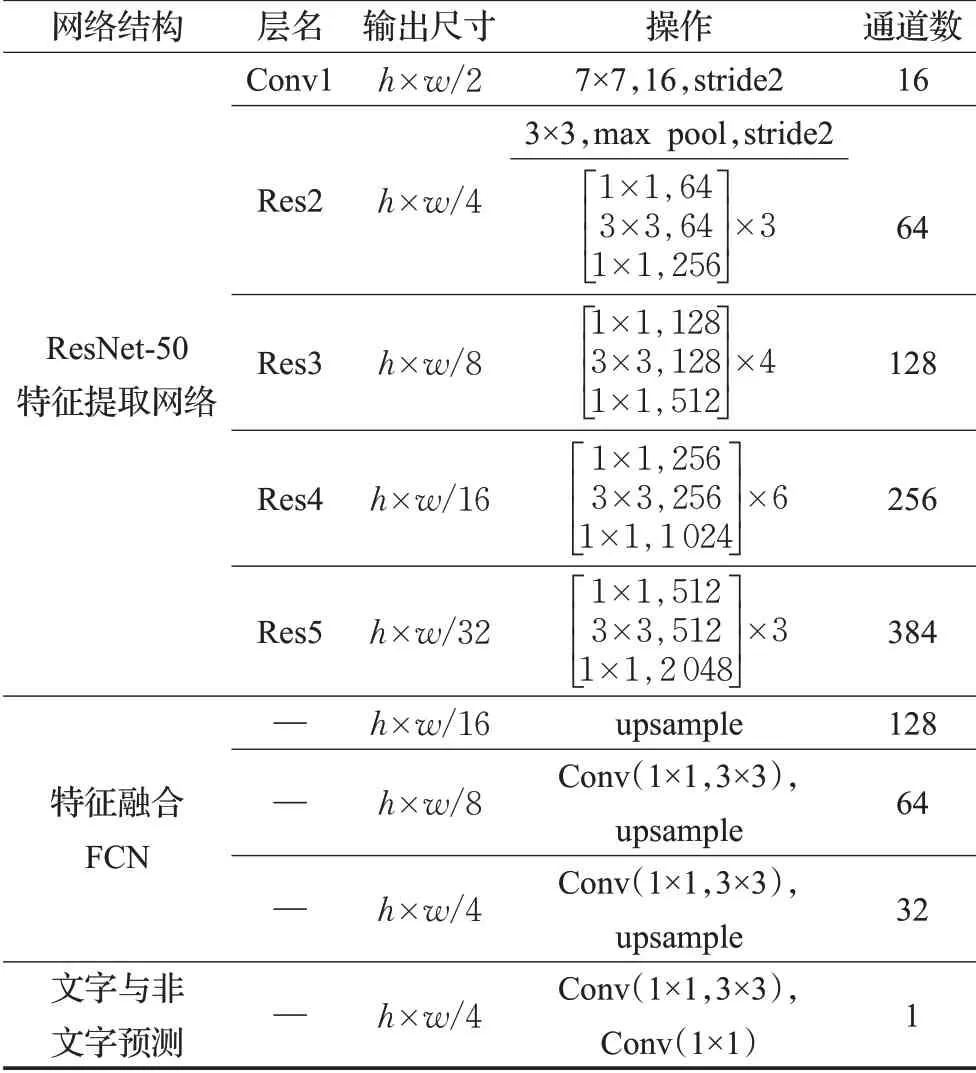
表1 網絡結構參數
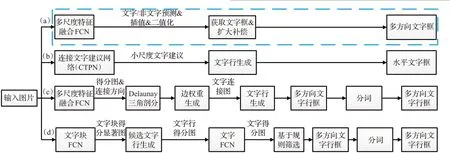
圖1 本文文字檢測框架及其與其他算法的比較

圖2 文字檢測網絡結構圖
2.1.2 特征融合網絡
在特征融合部分,首先對Res5 操作后提取的特征圖進行上采樣處理使得大小擴大為輸入圖像的1/16,然后與Res4 操作提取的特征圖合并,特征圖合并后進行1×1,3×3 不同尺度卷積核的卷積操作來融合特征圖和降低通道數,本文中選擇依此方式逐層往上融合特征層,經過多層的特征融合后的特征圖大小為輸入圖像的1/4。最后經過卷積核為1×1 大小的卷積操作后輸出得到文字與非文字的預測得分圖。
本文算法中獲取的文字與非文字預測得分圖為單一通道,相比文獻[13,16,19]等中所提出的算法,減少了通道數與計算量。
2.2 生成得分圖
本文方法中用于訓練的文字區域得分圖的生成如圖3 所示,放棄選擇標注的真實文字框來生成得分圖,而是選擇標注的真實文字框的縮進框,其目的有以下兩點:(1)真實文字框包圍了文字區域的同時也會包圍一些非文字區域,而縮進標注真實文字框以保證全部包圍的為文字區域;(2)在文字與非文字預測時,如圖4所示獲取的得分圖中的候選文字區域間的間隔會變大,解決了得分圖中候選文字區域連接在一起從而被一個矩形框檢測的問題。

圖3 得分圖的生成
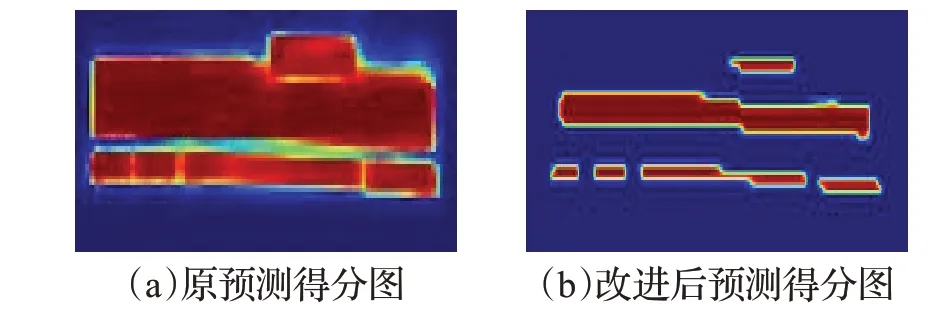
圖4 得分圖對比
對于標注的文字框四邊形Q(如圖3(a)黃色框所示),其中di(i=1,2,3,4)是四邊形左上頂點起順時針順序的頂點。為了縮小Q,首先計算每個頂點di的參考長度li,參考長度li,計算如下:
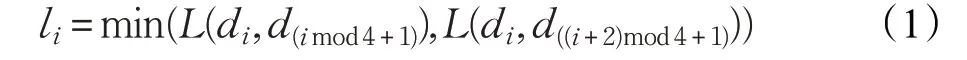
其中L(di,dj)是頂點di與dj的L2 范數,首先收縮一個四邊形Q 的兩個較長的邊。對于四邊形的兩對邊,通過比較它們的長度的平均值來確定較長的一對邊,然后收縮兩個較短的邊。對于每個邊,通過將它的兩個端點分別向內移動0.3li和0.3l(imod4)+1來收縮文字框得到文字框四邊形Q′(如圖3(a)綠色框所示)。如圖3(a)所示,文字框四邊形Q 的頂點由di收縮到d′i生成四邊形Q′,然后由文字框四邊形Q′生成得分圖如圖3(b)所示。
2.3 文字與非文字分類
在經過全卷積網絡后,輸出文字與非文字預測結果,對每一個像素進行預測,每個像素預測產生一個預測值,代表該像素為文字區域的置信度,該值在0到1之間。像素預測置信度值越大則表示該像素越有可能為文字區域像素,置信度值越小,則代表該像素更可能位于非文字區域。考慮到輸出的文字與非文字預測得分圖為輸入圖像大小的1/4,為了使預測得分圖與輸入圖像的每一個像素有一一對應的關系,本文將得分圖雙線性插值處理將其放大到與輸入圖像同樣大小。本文對測試集圖像中的文字置信度值的分布范圍進行了統計,在實驗中發現,在生成文字與非文字預測得分圖中的像素預測值呈現典型雙峰特點,像素預測值絕大部分在0.8 至1 和0 至0.2 的區間內,特別時絕大部分的文字區域像素預測值明顯大于其周圍區域非文字區域的像素預測值。基于上述特點本文采用了自適應閾值最大類間方差法(OTSU)對預測圖進行二值化處理,通過OTSU二值化后的文字與非文字預測分類圖如圖5 所示。當文字與非文字預測的像素預測值大于或等于該閾值則該像素值置為1,將其判定為文字區域,否則該像素值置為0,并將判定為非文字區域。

圖5 原圖(上)和對應文字與非文字預測分類圖(下)
2.4 文字框提取及補償函數設計
在文字與非文字分類的結果上,語義分割包含了文字的位置信息和邊緣信息,因此本文直接采用最小外接矩形邊界框粗糙地檢測出文字區域。文字與非文字預測得分圖在插值放大和二值化處理后利用OpenCV 中的minAreaRect()函數直接獲取圖像分割文字的檢測矩形框,該矩形框包含了預測文字區域的方向信息,可以檢測任意方向的文字。但由于在生成得分圖中,文字的得分圖由標注四邊形的縮進四邊形生成,所以在文字與非文字預測時,得分圖中的預測文字區域都是實際文字區域的縮小區域,所以提取到的文字檢測矩形框均小于實際文字區域包圍矩形框,文字區域不能完全被檢測框包圍住。因此在本文中設計了加權補償函數來對檢測框補償放大,使得檢測框能更好地檢測文字區域,增大檢測框與真實文字框的交并比(Intersection Over Union,IOU),來提升文字檢測性能。
檢測矩形框做加權補償擴大處理如圖6所示,檢測矩形框R′加權補償后得到矩形框R,加權補償擴大函數設計如下。
常數補償系數:把標注文字四邊形的縮進的四邊形作為訓練的真實文字區域,縮進的長度為kli和k=0.3,同理,把矩形框R′放大到R,放大的長度為rl′i和rl′(imod4)+1,r 是補償系數,其可按照公式(2)計算:

假設p′i是檢測矩形框R′自左上頂點起順時針順序的矩形頂點。為了擴大R′,為每個頂點p′i的參考長度,l′i的計算參考公式(1),k′為常數補償系數,補償規則如下:
(1)擴大檢測矩形框R′的較短的對邊,如圖6中的h 與其對邊的各個頂點沿著h 方向向外延伸長度rl′i和。
(2)擴大檢測矩形框R′的較長的對邊,如圖6中的w 與其對邊的各個頂點沿著h 方向向外延伸長度rl′i和

圖6 矩形邊界框做加權補償擴大處理示意圖
實驗發現,如果所有候選檢測矩形框均采用常數補償來擴大矩形框,則小字符檢測矩形框不能完全包圍住文字區域,所以候選檢測矩形框min(w,h)越小,在擴大補償處理時補償系數r 越大,由得分圖預測文字區域的特征和檢測矩形框的特點設計并對比了以下幾種自適應加權補償函數。
(1)線性補償函數,其計算公式為:
其中,hthreshold為檢測矩形框較短邊的閾值,hmin=min(w,h)。
(2)三角非線性補償函數,其計算公式為:
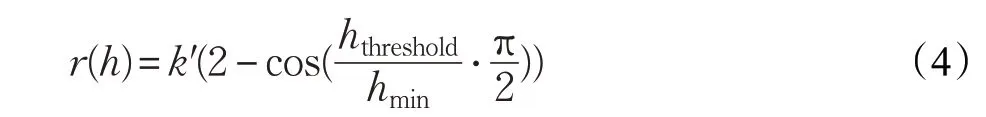

(3)高斯非線性補償函數,其計算公式為:

2.5 矩形框過濾
由于采用語義分割的方法得到文字與非文字預測得分圖時,將不可避免地出現少數非文字區域會獲得較高的預測值,從而導致在文字與非文字分類時會將這些非文字區域誤判定成文字區域,最終導致錯誤的檢測結果。為盡可能地減少錯誤檢測,有必要設計相應的后處理算法以進一步提高檢測準確率。本文算法主要設計了如下兩種后處理算法:
(1)在實驗測試圖像中的文字區域大小絕大部分超過10 個像素和面積不低于300 個像素,所以將hmin<hthreshold=10 或者w×h <300 的候選檢測框濾除掉。
(2)定義矩形框置信度,矩形框置信度為非線性插值得分預測圖中矩形框內的所有像素預測值的均值,如果矩形框置信度小于某一閾值則被判斷為無效矩形框。
2.6 損失函數
本文方法中訓練損失函數為Dice's 系數,也稱作Dice 系數,是一種集合相似度度量函數,對于信息檢索中的關鍵字集合X 和Y ,系數可以定義為:

Dice 系數和Jaccard 指數的方法相似,所以在本文中設計的損失函數計算公式如下:

Sscore_map為得分圖,即文字非文字分類的語義分割區域,
Sground_truth為標注文字區域。
3 實驗結果與分析
為了驗證本文方法的有效性,在ICDAR 2013 與ICDAR 2015 自然場景文字檢測競賽數據集進行了實驗,ICDAR 2015自然場景文字檢測競賽數據集共包含1 500張圖像(其中訓練集1 000張,測試集500張),該數據集中的場景文字其排列方向是任意的,且包括了運動模糊和低分辨率的問題。ICDAR 2013 自然場景文字檢測數據集包含了229 張訓練圖像和233 張測試圖像,共462張圖像,該數據集圖像中的文字以水平方向排列為主,且涵蓋了復雜光照、模糊和低分辨率等各種極端情況。上述數據集作為基準數據集在各類文字檢測算法的評估中被廣泛地使用。
本文方法使用的模型采用自適應矩估計(Adaptive Moment Eestimation,ADAM)優化器進行訓練,為了加速學習過程,訓練樣本均調整為512×512 大小,每執行一步使用的batch數量為24。ADAM的學習率從0.000 1開始,衰減速率為0.94,最大執行步數為100 000,每10 000執行步數更新一次學習率,當性能不再提高而停止訓練。本文所采用的ResNet-50 與FCN 網絡都是基于深度學習框架TensorFlow并均為python實現。
本文在ICDAR 2013 與ICDAR 2015 測試數據集中所獲得的檢測結果如圖7所示,可以看出本文方法能有效地應對復雜的場景圖像中的多方向排列的文字檢測問題。
3.1 實驗結果與對比

圖7 本文方法在ICDAR數據集的檢測效果

圖8 一些檢測失敗的結果
為進一步驗證本文方法的有效性,本文與最近的其他文字檢測方法進行了對比,在ICDAR 2015 測試集實驗結果的對比如表2 所示,本文方法利用設計的高斯補償函數在ICDAR 2015數據集上的Precision與Fmeasure 指標上相對于其他補償函數取得了更好的效果,其中Precision 為0.803,F-measure 指標為0.773。本文方法在Precision 指標均高于表2 中其他方法,Fmeasure指標結果高于表2中絕大多數的方法,如SegLink[18]與CTPN[11]等。然而與方法RRPN[13]比較,本文方法在Recall、F-measure 指標上還有進一步提升的空間。本文方法利用設計的高斯補償函數與其他文字檢測方法在ICDAR 2013 測試集實驗結果的對比如表3 所示,相對于I2R NUS[25]、Text[26]、Faster-RCNN[27]等方法,本文方法取得了更有競爭力的結果。
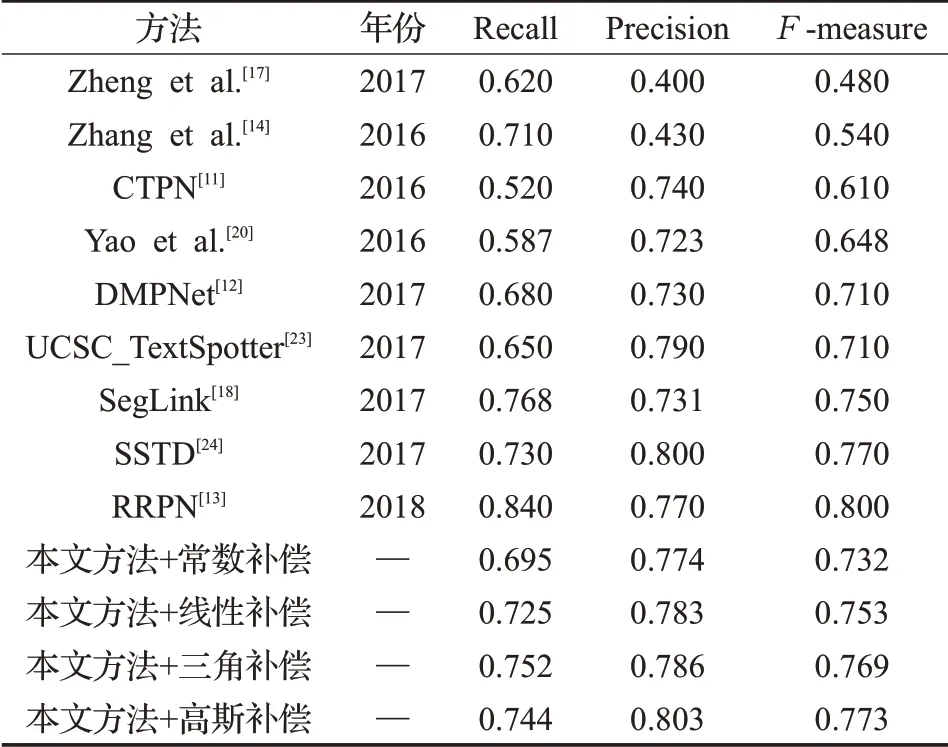
表2 ICDAR 2015場景文字檢測競賽測試集實驗結果
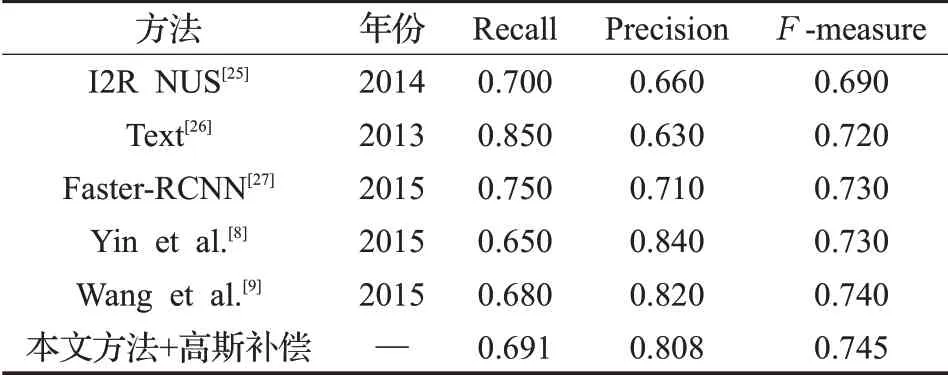
表3 ICDAR 2013場景文字檢測競賽測試集實驗結果
3.2 算法存在的不足
盡管本文方法取得了令人滿意的結果,但在實驗中依然發現本文方法對如下一些特殊場景或者特殊文字的檢測效果有待進一步改善:(1)對弧形排列的文字檢測效果不佳,這些文字只能被矩形邊界框檢測(如圖8(a)所示),原因在于本文選擇帶有方向信息的矩形框去提取文字區域,適用于文字單個方向的排列;(2)另外會錯誤地檢測一些和文字相類似的物體,如條紋狀圖形(如欄桿)、窗戶、符號等(如圖8(b)、(c)所示),這些物體與文字在紋理或形狀上都極為相似,以至于很難被區分開來;(3)一些文字尺寸太大導致無法被檢測(如圖8(d)所示)。
4 結語
本文提出一種基于全卷積網絡的多方向自然場景文字檢測方法,該方法利用深度卷積網絡提取文字特征,融合多層文字特征并采用語義分割方法分割文字區域,然后直接提取對應文字區域的包含方向信息的外接矩形框。在生成得分圖時選擇了標注文字區域的縮進區域,進行文字與非文字預測處理時,對外接矩形邊界框擴大補償處理得到最后的文字邊界框。與其他一些最新方法相比,本文算法在ICDAR 13 和ICDAR 15 標準數據集上均取得了更具競爭力的結果。在實驗中發現盡管本文所提出的自然場景文字檢測方法取得了不錯的性能,但仍然有不足之處,以下幾個方面是未來研究工作中所需要進一步考慮的問題:(1)弧形方向排列的文字檢測;(2)多語種共存的文字檢測。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
