創業板上市公司財務危機的識別與預警
2020-02-03 10:07:41吳慶賀唐曉華林宇
財會月刊·下半月 2020年1期
吳慶賀 唐曉華 林宇



【摘要】以我國創業板上市公司為研究對象,針對公司不同財務狀況構成的非均衡樣本特性,運用Twin-SVM來構建財務危機預警模型。實證結果表明:在Twin-SVM模型的構建過程中,RBF核函數展示出比Linear、Polynomial、Sigmoid、Wavelet核函數更為優異的預測性能;與改進的ODR-ADASYNSVM、BP神經網絡、Bayes分類法和K近鄰法相比,Twin-SVM不僅在預測精度上高于其他模型,而且在預測穩健性上也顯著更為優越,在制造業與信息傳輸、軟件和信息技術服務業兩個分行業的泛化性能也顯著優越于其余模型。
【關鍵詞】財務危機預警;Twin-SVM;創業板;上市公司;非均衡樣本
【中圖分類號】F275【文獻標識碼】A【文章編號】1004-0994(2020)02-0056-9
【基金項目】國家自然科學基金項目(項目編號:71771032);四川省應用基礎研究項目(項目編號:2017JY0158)
一、引言
上市公司作為實體經濟的典型代表,一旦發生財務危機,不僅自身會遭受巨大損失,讓投資者利益嚴重受損,甚至可能對整個平穩發展的經濟社會造成巨大沖擊[1,2]。只有科學地展開對我國上市公司財務危機識別和預警的研究,才能及時發現財務危機的誘因并采取有效的防范措施,避免造成不可挽回的損失。因此,探討并建立一個合理有效的財務危機預警機制,無論是對我國經濟還是對上市公司發展而言,都意義重大。
特別是對我國創業板上市公司而言,創業板是專門向高科技、高成長企業提供融資途徑和成長空間的證券交易市場,但是由于我國創業板存在著上市門檻低、企業股本小、抵御風險能力弱等問題,加上創業板市場成立時間較短,相應的法律法規以及政策制度還不夠完善,公司上市后業績嚴重下滑的現象頻頻發生[3]。基于以上因素,我國創業板上市公司面臨較大的財務風險且較易發生財務危機。為使我國創業板健康穩定地成長并有效地輔助公司經營者及監管層防范和化解風險與危機,建立科學的創業板上市公司財務危機預警模型,是一個值得關注的問題。
財務危機預警長期以來都是學術界關注的焦點與熱點,相關文獻比較多見。有學者運用單變量模型對財務危機預警展開研究[4],但一家企業的財務狀況不是僅用一個指標就可以評判的,因此這類模型逐漸被其他模型所取代;其后有學者引入多元變量模型[5],但多元變量模型的前提條件過于嚴格,要求解釋變量與被解釋變量呈線性關系,各變量間相互獨立,且要求殘差服從正態分布;也有學者采用Logistic回歸模型進行財務危機預警研究[6-8],但Logistic回歸模型一般用于解決二分類問題,也要求解釋變量與被解釋變量存在線性關系;而后有學者采用人工神經網絡模型進行財務危機預警研究[9],該類模型采用的是局部搜索的優化方法,容易造成局部極小的問題。令人欣慰的是,Vapnik[10]提出的支持向量機(Support Vector Machine,SVM)恰好具有解決以上模型存在問題的突出優勢,具有更為優異的學習能力和泛化推廣性能,其一經提出便受到學術界眾多學者青睞并被廣泛運用于風險預警等研究中[11,12]。
必須指出的是,無論是在醫學領域、信息領域還是金融領域,樣本集往往呈現偏態的特征,即兩類樣本數目往往是不等的。這種非均衡樣本所訓練出的模型得到的分類結果會具有明顯的偏向性,即對多數類樣本預測準確率高,對少數類樣本預測準確率較低。而傳統SVM的良好預測性能往往要求兩類樣本是均衡的[12,13],但是發生財務危機的上市公司畢竟只是少數,財務正常的上市公司占多數,這就必然導致兩類樣本不均衡,從而使得SVM所構建的分類超平面會偏向財務危機樣本一邊,進而導致模型的預測效果不盡人意。
于是,有學者從數據層面和算法層面對非均衡樣本進行了研究。欠采樣(Under-sampling)和過采樣(Over-sampling)是常用的將非均衡樣本處理為均衡樣本的方法,但是欠采樣方法在刪除多數類樣本時可能會將影響分類的有效信息誤刪,最終造成預測效果不理想。過采樣則是通過增加少數類的樣本使兩類樣本數目達到均衡,但增加的樣本可能造成少數類樣本的相互重疊,也未必能進一步提升模型預測結果的準確性[13]。而后有學者將處理非均衡樣本的方法與SVM相結合進行研究,如衣柏衡等[14]提出了改進的SMOTE與SVM相結合的方法,在面對非均衡樣本時,生成一定數量的少數類樣本來進行平衡處理,但令人遺憾的是,利用SMOTE對少數類樣本進行處理,無法消除多數類樣本中的噪聲信息,容易造成新生成樣本重疊的問題[15]。林宇等[12]將自適應合成抽樣方法(ADASYN)和逐級優化遞減欠采樣方法(ODR)與SVM相結合,構建ODRADASYN-SVM模型對極端金融風險進行了預警研究,但這種做法可能會破壞原始數據的結構且違背研究的可重復性原則,特別地,由于該方法的訓練樣本與原始數據有偏,其模型的解釋性也容易受到質疑[16]。
令人驚喜的是,Twin-SVM[17]的提出從根本上解決了非均衡樣本的問題,Twin-SVM不必增加或減少原始樣本,而是為上市公司財務正常樣本與財務危機樣本分別構造一個分類超平面,使每個分類超平面離本類樣本點盡可能近而離另一類樣本點盡可能遠,將一個大的分類問題轉換成求解兩個小的分類問題,從而約束條件數目將減少,模型訓練時間縮短,Twin-SVM的分類靈活性及計算性能將大大提高,從而行之有效地克服了傳統SVM的根本缺陷[11,18]。因此,本文引入Twin-SVM對創業板上市公司財務危機進行預警研究。
從目前所掌握的文獻來看,對于Twin-SVM的研究主要集中在算法的優化改進、圖像識別以及金融風險的預警等方面,并未發現將其應用于財務危機預警的實證研究;在Twin-SVM的核函數選擇上,以往學者大多是選擇RBF,而未對不同核函數下Twin-SVM模型的預測性能進行探討;以往的文獻在對創業板上市公司進行財務預測時,并沒有針對創業板中的分行業進行模型的泛化性能探討。
基于以上分析,本文以我國創業板上市公司為研究對象,基于扣除非經常性損益后的凈利潤和凈資產增長率構建財務危機的識別方法,從而確定了財務正常和財務危機樣本。對所選取的31個財務指標,運用顯著性檢驗、相關性分析、共線性診斷和逐步回歸提取出最具解釋能力的財務指標作為模型的最終輸入變量,以此避免維數災難和過擬合的問題。首先,對不同核函數下的Twin-SVM模型進行預測性能對比來確定最優的核函數;然后采用分類準確率、幾何平均正確率G、少數類的度量值F對在不同樣本劃分比例下的Twin-SVM、ODR-ADASYNSVM、BP神經網絡、Bayes分類法以及K近鄰法的預測精度及穩健性進行對比,運用配對樣本T檢驗對各模型預測精度的差異性進行顯著性檢驗;最后,對制造業與信息傳輸、軟件和信息技術服務業兩個分行業下不同預警模型的泛化性能進行對比研究。希望能為公司經營者以及監管層防范和化解風險與危機提供良好的借鑒,為投資者減小損失提供合適的操作工具。
二、研究方法
2.財務危機識別方法。構建財務危機預警模型的關鍵之一在于如何識別上市公司是否發生財務危機。從主板和中小板來看,Geng等[19]、Chu等[20]將被ST和非ST作為是否陷入財務危機的識別標志,但是創業板不同于主板和中小板存在“ST”和“ST”這樣的過渡階段,對于存在財務危機的企業直接作暫停上市處理。因此,在對創業板上市公司進行財務危機預警研究時,不能繼續沿用以往的標準。從已有的研究創業板上市公司財務危機預警的文獻來看,岑慧[21]以四種情況作為界定標準:一是凈利潤為負,二是凈資產為負,三是審計報告為非標意見,四是營業利潤增長率為負;宋寶珠[8]以兩種情況作為界定標準:一是連續兩個年度凈利潤為負,二是凈資產在最近一個會計年度為負。
由此,本文發現以往學者在識別創業板上市公司財務危機時往往以凈利潤和凈資產作為標準,但是僅將凈利潤為負作為界定標準,缺少一定合理性。因為一些企業雖然經營困難、陷入財務危機,但是因獲得政府或者銀行補助而得以繼續生存,因此,本文將扣除非經常性損益后的凈利潤作為凈利潤的替代標準。最終本文將陷入財務危機的識別標準界定為:一是最近一個會計年度扣除非經常性損益的凈利潤為負;二是最近一個會計年度期末凈資產增長率為負。
對于一家上市公司,一旦同時達到上述兩個門檻,則被識別為財務危機樣本;反之,則被識別為財務正常樣本。
3.財務危機預警模型的性能評估方法。為了更全面地評估Twin-SVM財務危機預警模型的綜合性能,不僅要評估模型的預測性能是否優越,還要對模型的穩健性進行研究,考察其在樣本劃分比例不同的情況下是否依然能保持優越的預測性能。本文首先運用傳統的分類正確率對總體的分類準確率進行考察,再進一步借鑒相關文獻[15],運用針對非均衡樣本的評估指標對Twin-SVM財務危機預警模型進行預測精度的評估。分類正確率即總的預測正確的樣本數占總體樣本數的比例,針對非均衡樣本分類的評估指標則是幾何平均正確率Gmean和少數類的度量值Fmeasure(以下用G和F分別代替Gmean和Fmeasure)。G和F評估指標的構建過程具體闡述如下:
設TP和TN分別表示將財務危機樣本和財務正常樣本預測正確的數量,FN和FP分別表示將財務危機樣本和財務正常樣本預測錯誤的數量。混淆矩陣表示對測試集進行預測分類的結果(見表1)。
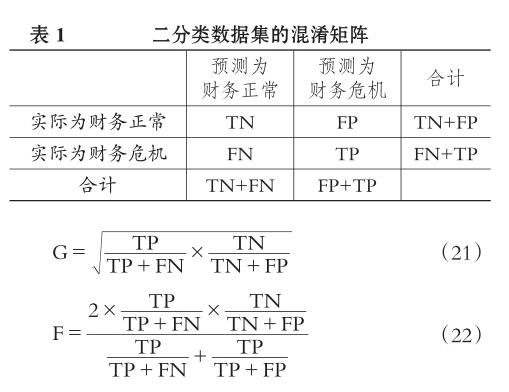
于是,通過計算式(20)、(21)和(22)中的分類準確率、幾何平均正確率G及少數類的度量值F,本文就能對所構建的Twin-SVM模型的預測性能進行準確的評價。G值越大,表示對財務正常和財務危機兩類樣本的綜合預測性能越優異;F值越大,表示對財務危機樣本的預測精度越高,反之亦然。
三、實證結果與分析
1.樣本選擇及數據處理。由于本文在設計創業板上市公司財務危機預警模型時,選擇滯后狀態指標一個警度時差,且根據創業板股票上市規則,最近連續虧損三年的公司會被進行退市處理,因此早期的預測就能夠保證企業在應對危機時抓住有利時機,采取有效措施,最大限度地減少相關損失。為保證對上市公司財務危機預警的前瞻性與時效性,本文對2018年前三年即2016 ~ 2018年的警度進行研究,從而應選擇2015 ~ 2017年的數據。在剔除了數據存在缺失的樣本后,共得到655家樣本公司。從三年的數據樣本中分別隨機抽取等比例的數據組成訓練集和測試集,經統計發現三年樣本中財務正常樣本和財務危機樣本的比例超過10∶1,構成嚴重的非均衡樣本。本文所有數據都來源于Wind數據庫。
2.特征指標的篩選。對引發財務危機的特征指標進行準確提取,是構建財務危機預警模型的重要步驟。由于在對模型的輸入變量即財務指標的選取上暫未得到定論[22],因此本文借鑒以往研究文獻[19,23]并參考公司業績綜合評價指標體系,從盈利能力、現金流量、營運能力、成長能力和償債能力五個方面挑選出31個財務指標(模型的特征指標見表2)。
為篩選出能顯著區分危機狀態的財務指標,本文借鑒相關文獻[12,23,24],分別對符合正態分布和非正態分布的變量采用T檢驗和U檢驗,將未能通過顯著性檢驗的指標(X12)予以剔除。進一步,為避免指標間的共線性問題對模型的擬合效果產生影響,本文借鑒相關研究[23,25],運用相關性分析和共線性診斷對30個留存變量進行分析,最終剔除了6個指標(X2、X3、X7、X8、X27和X28)。為更近一步提取出對狀態指標變量有更強解釋力的特征變量,借鑒以往學者的研究[22],采用逐步回歸(Stepwise Regression)對數據進行進一步的處理,最終將24個特征指標約簡為7個特征指標,分別為:X1(平均凈資產收益率)、X11(全部資產現金回收率)、X16(非流動資產周轉率)、X17(固定資產周轉率)、X18(應收賬款周轉率)、X21(營業總收入)和X26(流動比率)。至此,已完成對創業板上市公司財務危機預警模型特征指標的篩選。
3.不同核函數下Twin-SVM模型的預測性能對比。基于不同核函數的Twin-SVM財務危機預警模型具有不同的預測性能,倘若無法確定最優的核函數,就無法獲得性能優越的預警模型。本文采用5折交叉驗證法(Cross Validation,CV)下G值、F值以及分類準確率對Twin-SVM創業板上市公司財務危機預警模型的最優核函數進行確定。實驗結果見表3。
從表3可看出,依次將5種核函數與Twin-SVM模型結合后,RBF核函數的G值(0.6681)和F值(0.3586)顯著高于其余4種核函數。雖然RBF核函數的分類準確率(0.8616)略低于其余核函數,但是究其原因是其余核函數所構成的模型將大量財務危機樣本錯誤預測為財務正常樣本,財務危機樣本僅占總體樣本的一小部分。而把財務危機樣本錯誤預測為財務正常樣本所產生的危害是遠大于把財務正常樣本錯誤預測為財務危機樣本的。因此,將RBF核函數與Twin-SVM結合后的預測性能是顯著優于其余核函數的,本文采用RBF作為Twin-SVM的核函數。
同時,為了直觀地展現在創業板上市公司財務危機預警研究中最優核函數RBF下Twin-SVM預警模型的參數效果圖,本文在將RBF核參數設定為0.8的基礎上,讓Twin-SVM模型本身的參數c1在{0.001,0.01,0.1,1,10}區間取值、c2在{0.005,0.05,0.5,5,50}區間取值,來研究不同參數下預警模型的預測性能。實驗結果如圖1所示。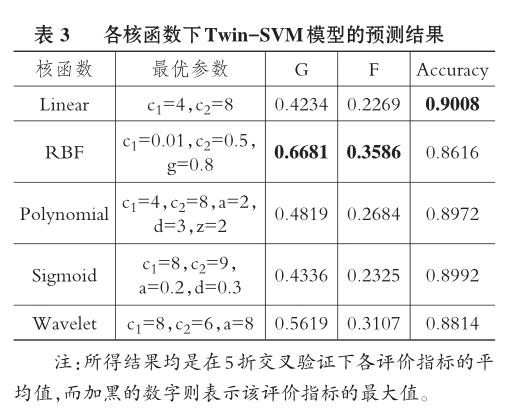
從圖1中可看出,RBF核函數下Twin-SVM預警模型在不同的參數下取得了差異較大的預測效果。從更為綜合的評價指標G值和F值來看,大多數情況下,Twin-SVM模型的預測效果隨c1和c2的變動呈現同增或同減的變動趨勢;而從分類準確率來看,大多數情況下,c1取值較小且c2取值較大時,整體的分類準確率都較低,這是因為當c1取值較小時,對財務危機樣本進行預測的容錯率較低,會將大量的財務正常樣本錯誤劃分,導致對財務危機樣本預測準確率較高,而整體的分類準確率都較低。倘若c1取值較大而c2取值較小時,分類準確率提高,但是此時G值和F值較低,即將大量財務危機樣本錯誤劃分。因此,在參數選取上不僅要考慮財務危機樣本的分類準確率,也要關注整體樣本的分類準確率。進一步發現,在c1和c2分別取0.01和0.5時,無論是G值、F值還是分類準確率都取得了較好的效果。由此,本文所使用的RBF核函數下Twin-SVM模型的參數設置是準確且可靠的。
4.不同預警模型的預測性能對比。在確定了Twin-SVM預警模型的最優核函數以及模型參數之后,就要對模型的預測性能進行評估。為了避免數據的隨機選取造成偶然性結果,也為了避免模型過擬合和欠擬合的問題,本文借鑒相關文獻[19],采用不同劃分比例(6∶4、7∶3、8∶2、9∶1)的訓練集和測試集分別進行訓練和預測。在將經篩選后的特征指標作為輸入指標后,首先對Twin-SVM預警模型的分類準確率進行計算,進一步計算在最優參數下Twin-SVM預警模型的幾何平均正確率G和少數類的度量值F。為了展示Twin-SVM模型優越的預測性能,將其與改進的ODR-ADASYN-SVM模型、BP神經網絡、Bayes分類法(Bayes模型)和K近鄰法(KNN模型)進行比較,結果如表4所示。
從表4中可以看出,無論是在6∶4、7∶3、8∶2還是9∶1的數據劃分比例下,Twin-SVM模型的分類準確率都略低于BP神經網絡和K近鄰法,但是略高于改進的ODR-ADASYN-SVM模型且顯著高于Bayes分類法。究其原因,是BP神經網絡和K近鄰法沒有考慮到財務正常和財務危機公司構成的嚴重非均衡樣本的特性,將大量財務危機公司錯誤預判為財務正常公司,而財務正常樣本的數量僅占總體樣本很小的比例,所以最后導致BP神經網絡和K近鄰法的總體分類準確率會略高于Twin-SVM模型。而ODR-ADASYN-SVM和Bayes分類法的分類準確率較低的原因可能在于,這兩個模型對兩類樣本的擬合效果和預測性能不及Twin-SVM模型優異。

值得注意的是,將財務危機公司預測為財務正常公司所帶來的危害是遠遠大于將財務正常公司預測為財務危機公司的。因此,為了進一步體現TwinSVM模型對少數類的財務危機樣本的優越預測性能,將針對非均衡樣本的評價指標幾何平均正確率G和少數類的度量值F進一步用于Twin-SVM與其他模型的對比研究。為更直觀地展現預測結果,將結果繪制在折線圖中,見圖2。
由圖2可直觀看出,從幾何平均正確率G來看,四種數據劃分比例下Twin-SVM模型的G值都在0.7上下波動,顯著大于ODR-ADASYN-SVM模型(0.6左右)、BP神經網絡(0.3左右)、Baye分類法(0.5左右)和K近鄰法(0.3左右)。表明無論是對財務正常還是財務危機樣本,ODR-ADASYN-SVM模型、BP神經網絡、Bayes分類法和K近鄰法的預測效果都不如Twin-SVM模型;從少數類的度量值F來看,ODR-ADASYN-SVM模型(0.3左右)、BP神經網絡(0.15左右)、Bayes分類法(0.18左右)和K近鄰法(0.2左右)也是遠小于Twin-SVM模型(0.38左右),表明非均衡樣本數據集對其他四種模型的預測能力都有較為嚴重的影響。進一步從不同數據劃分比例下預測精度的G值或者F值的標準差來看,除Twin-SVM模型預測精度G值和F值的標準差(0.0218,0.0112)大于Bayes分類法(0.0215,0.006)以外,Twin-SVM模型預測精度G值和F值的標準差均小于其余模型。由此,綜合來看,Twin-SVM模型的預測性能和穩健性都是顯著優于ODRADASYN-SVM模型、BP神經網絡、Baye分類法和K近鄰法的。
進一步地,如果僅將結論建立在評價指標數值上,則缺少了類似數理統計上的嚴謹性與可靠性。因此,為增強所得結果的科學性與客觀性,本文繼續采用配對樣本T檢驗對預測結果進行顯著性檢驗以判斷不同模型的預測性能是否存在顯著性差異。檢驗結果如表5所示。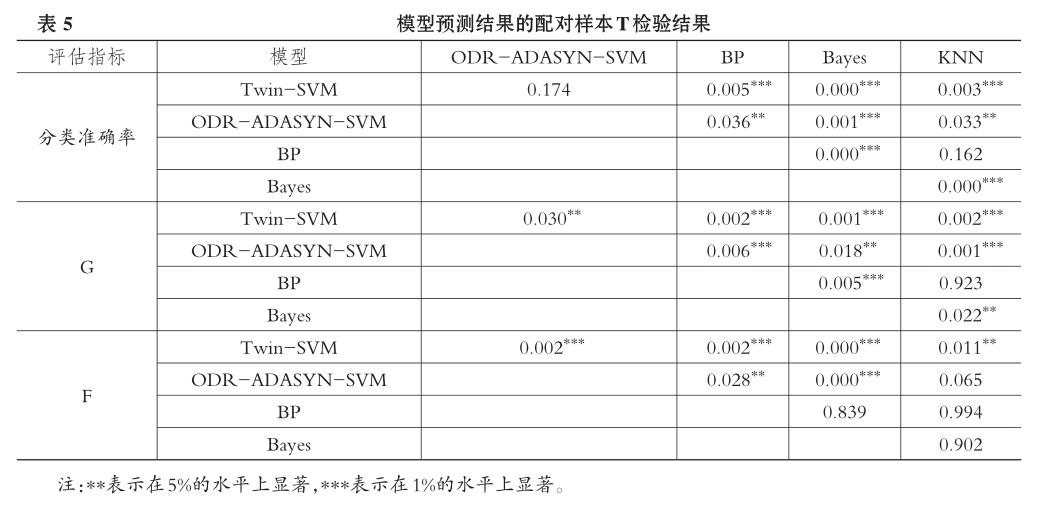
從表5可以看出,Twin-SVM模型與BP神經網絡、Bayes分類法和K近鄰法在分類準確率上的配對樣本T檢驗統計量在1%的顯著性水平上拒絕零假設(null hypothesis),即Twin-SVM模型與其他三個模型的預測效果有顯著性差異,Twin-SVM模型在分類準確率上顯著優于Bayes分類法,但略低于BP神經網絡和K近鄰法,這與前文的結論一致。進一步地,從更為綜合的針對非均衡樣本的評價指標幾何平均正確率G及少數類的度量值F來看,在5%的顯著性水平上,Twin-SVM模型與ODR-ADASYNSVM模型、BP神經網絡、Bayes分類法和K近鄰法的G值和F值有顯著性差異。由此,從預測精度上來看,Twin-SVM模型是顯著優越于其他四個模型的。
5.分行業下Twin-SVM預警模型的預測結果。評價模型的預測性能不僅要基于整體行業進行實證研究,而且應在不同行業不同特點下論證模型的泛化性能。本文在實驗過程中發現創業板發生財務危機的公司大多數集中在制造業與信息傳輸、軟件和信息技術服務業兩個行業,2015年發生財務危機的公司共15家,其中12家屬于制造業與信息傳輸、軟件和信息技術服務業;2016年發生財務危機的公司共38家,其中30家集中在上述兩個行業;2017年發生財務危機的公司共98家,其中81家集中在上述兩個行業。而制造業是創業板板塊中規模最大的行業,也是我國經濟社會發展的支柱性產業。在當今信息高速發展以及大數據時代下,信息傳輸、軟件和信息技術服務業對于國家經濟發展的重要性不言而喻。由此,本文進一步在這兩大行業中對Twin-SVM模型與其余模型展開預測精度對比,以考察該模型的泛化性能。實驗結果見表6。
通過表6可看出,在制造業與信息傳輸、軟件和信息技術服務業兩個分行業中Twin-SVM模型均獲得了最為優異的預測效果。在制造業中,TwinSVM模型明顯優于BP神經網絡和K近鄰法,雖然ODR-ADASYN-SVM模型和Bayes分類法的G值略大于Twin-SVM模型,但是綜合分類準確率和F值來看,ODR-ADASYN-SVM模型和Bayes分類法總體分類準確率較低,且對財務危機樣本的預測精度也低,因此在制造業的預測中,Twin-SVM模型是優于其他模型的。而從信息傳輸、軟件和信息技術服務業來看,Twin-SVM模型的G值(0.6298)和F值(0.2920)明顯大于其他模型,表明Twin-SVM模型無論是對財務正常樣本還是財務危機樣本都有著優越的預測能力。
綜合以上分析,無論是從預測精度來說,還是從預測穩健性來說,就整個創業板來看,Twin-SVM模型都是顯著優越于其他預警模型的。而在制造業與信息傳輸、軟件和信息技術服務業兩個分行業中,Twin-SVM模型也具有更為優異的學習能力和推廣泛化能力。因此,Twin-SVM模型有著更為優越的綜合性能,能有效地識別并預測我國創業板上市公司的財務危機,為公司經營者和監管層防范與化解風險、投資者減少投資損失提供合適的操作工具。
四、結論
本文將篩選后的我國創業板655家上市公司作為研究樣本,基于扣除非經常性損益后的凈利潤和凈資產增長率構建財務危機的識別方法,從而確定了財務正常和財務危機樣本。在Twin-SVM模型的構建過程中,運用5折交叉驗證法下的三個評價指標即分類準確率、幾何平均正確率G和少數類的度量值F來確定最優的Twin-SVM核函數。然后對在不同樣本劃分比例下的Twin-SVM模型與ODRADASYN-SVM模型、BP神經網絡、Bayes分類法以及K近鄰法的預測精度和穩健性進行對比,運用配對T檢驗對各模型預測精度的差異性進行顯著性檢驗。最后在制造業與信息傳輸、軟件和信息技術服務業兩個分行業中對Twin-SVM模型與其余模型的泛化性能進行了對比。
實證結果表明:在Twin-SVM模型的構建過程中,RBF核函數展示出比Linear、Polynomial、Sigmoid、Wavelet核函數更為優異的預測性能;與改進的ODR-ADASYN-SVM模型、BP神經網絡、Bayes分類法和K近鄰法相比,Twin-SVM模型不僅在預測精度上高于其他模型,而且在預測穩健性上顯著更為優越,在制造業與信息傳輸、軟件和信息技術服務業兩個分行業的泛化性能也顯著優越于其余幾個模型。
根據以上實證研究結果,基于Twin-SVM的財務危機預警模型能夠有效地識別并預測我國創業板上市公司是否會發生財務危機。對政府管理決策部門而言,能根據預測結果及時準確地評估上市公司發生財務危機的可能性,并制定和實施相應的措施,避免對經濟社會的平穩運行產生大的影響;對公司經營者來說,可審時度勢,及時調整經營戰略,積極防范和化解風險與危機;對投資者而言,可及時掌握上市公司的經營狀況和盈利狀況,進而調整投資策略,優化投資組合,減少相關投資損失。
【主要參考文獻】
[1]John Nkwoma Inekwe,Yi Jin,Ma. Rebecca Valenzuela. The effects of financial distress:Evidence from US GDP growth[J].Economic Modelling,2018(72):8~21.
[2]Geng R.,Bose I.,Chen X. Prediction of financial distress:An empirical study of listed Chinese companies using data mining[J].European Journal of Operational Research,2015(1):236~247.
[3]逯東,萬麗梅,楊丹.創業板公司上市后為何業績變臉?[J].經濟研究,2015(2):132~144.
[4]William H. Beaver. Financial ratios as predictors of failure[J].Journal of Accounting Research,1964(1):71~111.
[5]Edward I. Altman. Financial ratios,discriminant analysis and the prediction of corporate bankruptcy[J].Journal of Finance,1968(4):189~209.
[6]Hanmei Sun,Thuan Nguyen,Yihui Luan,et al. Classified mixed logistic model prediction[J].Journal of Multivariate Analysis,2018(168):63~74.
[7]James A. Ohlson. Financial ratios and the probabilistic prediction of bankruptcy[J].Journal of Accounting Research,1980(1):109~131.
[8]宋寶珠.創業板上市公司財務預警模型研究[D].北京:首都經濟貿易大學,2014.
[9]Le H. H.,Viviani J. L. Predicting bank failure:An improvement by implementing machine learning approach on classical financial ratios[J]. Post-Print,2017(44):16~25.
[10]Vapnik V. N. The nature of Statistical Learning Theory[M].New York:Springer-Verlag,1995:100~200.
[11]Huang H.,Wei X.,Zhou Y. Twin support vector machines:A survey[J].Neurocomputing,2018(300):34~43.
[12]林宇,黃迅,淳偉德等.基于ODR-ADASYN-SVM的極端金融風險預警研究[J].管理科學學報,2016(5):87~101.
[13]Jian C.,Gao J.,Ao Y. A new sampling method for classifying imbalanced data based on support vector machine ensemble[J].Neurocomputing,2016(193):115~122.
[14]衣柏衡,朱建軍,李杰.基于改進SMOTE的小額貸款公司客戶信用風險非均衡SVM分類[J].中國管理科學,2016(3):24~30.
[15]Beyan C.,Fisher R. Classifying imbalanced data sets using similarity based hierarchical decomposition[J].Pattern Recognition,2015(5):1653~1672.
[16]李揚,李竟翔,馬雙鴿.不平衡數據的企業財務預警模型研究[J].數理統計與管理,2016(5):893~906.
[17]R. K. Javadeva,R. Khemchandani,S. Chandra. Twin support vector machine for pattern classification[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2007(5):905~910.
[18]王鵬,黃迅.基于Twin-SVM的多分形金融市場風險的智能預警研究[J].統計研究,2018(2):3~13.
[19]Geng R.,Bose I.,Chen X. Prediction of financial distress:An empirical study of listed Chinese companies using data mining[J].European Journal of Operational Research,2015(1):236~247.
[20]Chu Y.,Wang G.,Chen G. A new random subspace method incorporating sentiment and textual information for financial distress prediction[J].Electronic Commerce Research & Applications,2018(29):30~49.
[21]岑慧.創業板上市公司財務危機預警模型研究[D].廈門:集美大學,2018.
[22]Liang D.,Tsai C. F.,Wu H. T. The effect of feature selection on financial distress prediction[J].Knowledge-Based Systems,2014(1):289
~297.
[23]Mselmi N.,Lahiani A.,Hamza T. Financial distress prediction:The case of French small and medium-sized firms[J].International Review of Financial Analysis,2017(50):67~80.
[24]Hosaka T. Bankruptcy prediction using imaged financial ratios and convolutional neural networks[J].Expert Systems with Applications,2019(117):287~299.
[25]Binh P. V. N.,Trung D. T.,Duc V. H. Financial distress and bankruptcy prediction:An appropriate model for listed firms in Vietnam[J]. Economic Systems,2018(42):616~624.
