基于CNN與雙向LSTM的行為識別算法
2020-03-07 12:47:42吳瀟穎吳勝昔
計算機工程與設計 2020年2期
吳瀟穎,李 銳,吳勝昔
(華東理工大學 化工過程先進控制和優化技術教育部重點實驗室,上海 200237)
0 引 言
傳統行為識別方法普遍基于圖像提取特征,而遮擋、背景雜亂、陰影和不同光照條件以及圖片拍攝角度等問題都會給圖像特征提取帶來困難,且二維圖像只有兩個維度的信息,信息不夠完整準確[1]。而人體三維骨骼可以有效克服以上缺點,基于深度圖像獲取的3D骨骼信息更加準確。特別是微軟推出的Kinect深度攝像機可以自動定位人體關節,使得骨骼信息的獲取更為簡便。
隨著特征工程從2D到3D的演變,基于手工的特征提取復雜性也越來越高,而深度學習的發展也促使行為識別的研究更為深入。Donahue等[2]使用CNN+LSTM架構對視頻序列而非人體骨骼進行識別。Mo等[3]提出了一種基于CNN+MLP模型的行為識別系統,該系統輸入是骨骼的二維數據。Song等[4]提出了一個基于注意力的長短期記憶遞歸神經網絡模型。Ge等[5]在行為識別問題上使用Bi-LSTM網絡,在UCF101數據集上的識別率達到了88.9%。
基于深度學習的行為識別難點在于提取單幀行為局部空間特征的同時捕獲視頻演變的時序特征,基于此,本文提出一個基于人體骨骼的CNN與Bi-LSTM混合模型用于人體行為識別。輸入數據采用人體3D骨骼的關節坐標,三維骨骼數據更加準確且魯棒性更強。CNN提取關節內部的空間關系,Bi-LSTM對時間序列有良好的處理能力。該模型在UTKinect Action3D標準數據和自制Kinect數據集上的結果顯示了網絡較強的識別能力。
1 相關理論方法
1.1 卷積神經網絡
CNN是一種帶有卷積結構的深度神經網絡,最早由Fukushima[6]提出,通常用于深度學習,用于從原始數據中自動提取特征。CNN網絡最底層是特征提取層,接著是池化層,之后可以繼續增加卷積層或池化層,最后是全連接層。
CNN的基本結構包括兩種特殊的神經元層,其一為卷積層,每個神經元的輸入與前一層的局部相連,并提取該局部的特征;其二是池化層,用來求局部敏感性與二次特征提取的計算層。這種兩次特征提取結構減少了特征分辨率,減少了需要優化的參數數目。
卷積層使用“卷積核”進行局部感知,挖掘數據的局部特征,達到特征增強,減少模型計算參數的目的,卷積核的大小定義了卷積操作的感受野,卷積層產生的特征圖Hi[7]計算公式如式(1)
Hi=f(Hi-1?Wi+bi)
(1)
其中,Wi表示卷積核的權值矩陣,?為卷積運算,bi表示偏置,f(·) 表示激活函數。以ReLU函數為例,其計算公式為式(2),則卷積計算過程如圖1所示,陰影部分即為一次卷積計算所對應的值
f(x)=max(0,x)
(2)
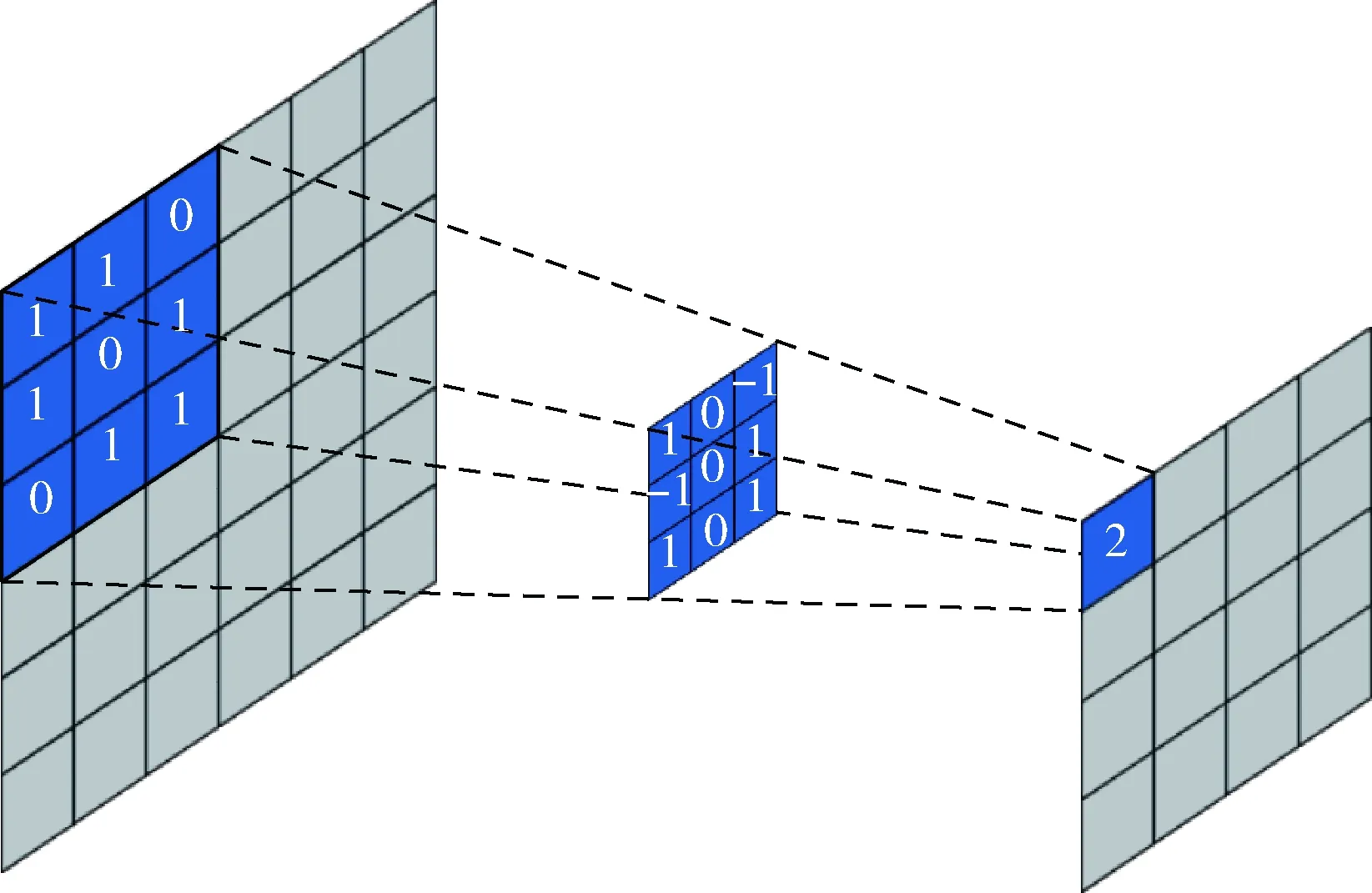
圖1 卷積計算過程
池化層也稱下采樣層,主要用于特征降維、壓縮數據和參數數量,減少過擬合的同時提高模型容錯性。主要分為最大池化層(Max Pooling)和平均池化層(Average Pooling)兩種。最大池化過程如圖2所示。
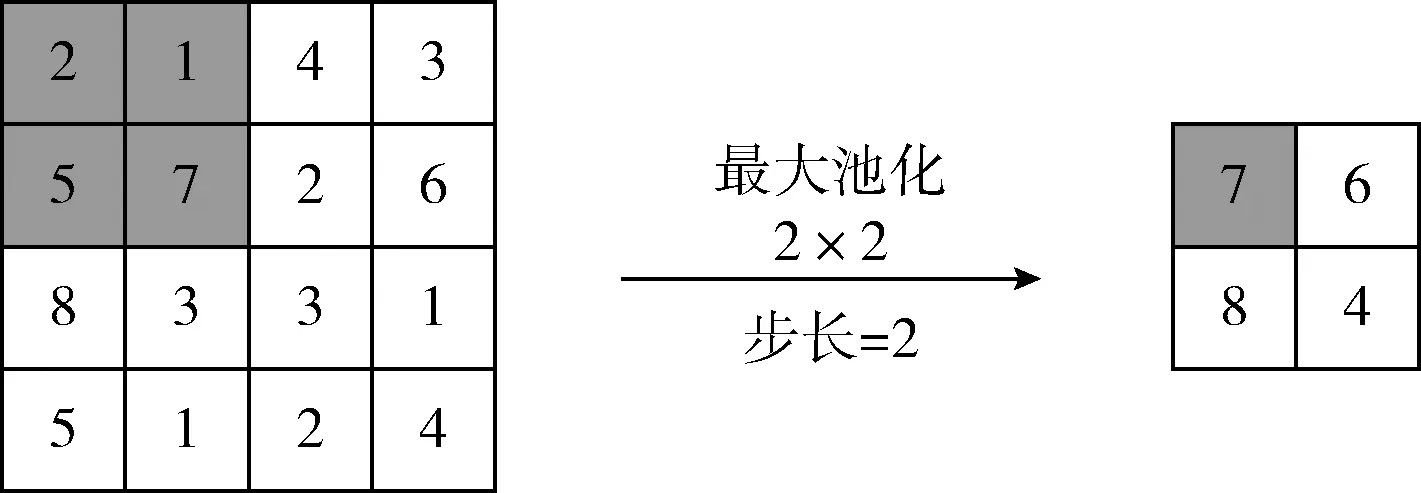
圖2 池化計算過程
全連接層用于多次卷積和池化后的分類任務,在卷積池化處理后仍需要全連接層輸出分類結果。
1.2 長短時記憶網絡及其改進
長短時記憶網絡LSTM是一種RNN的改進算法,RNN可以處理長時間輸入序列但是存在梯度消失或梯度爆炸的問題,而LSTM在RNN的基礎上加入了3個控制門,即遺忘門、輸入門和輸出門,分別用來控制是否遺忘當前狀態、是否獲取當前的輸入信息和是否輸出當前狀態,有效克服了RNN所存在的問題。LSTM結構如圖3所示。
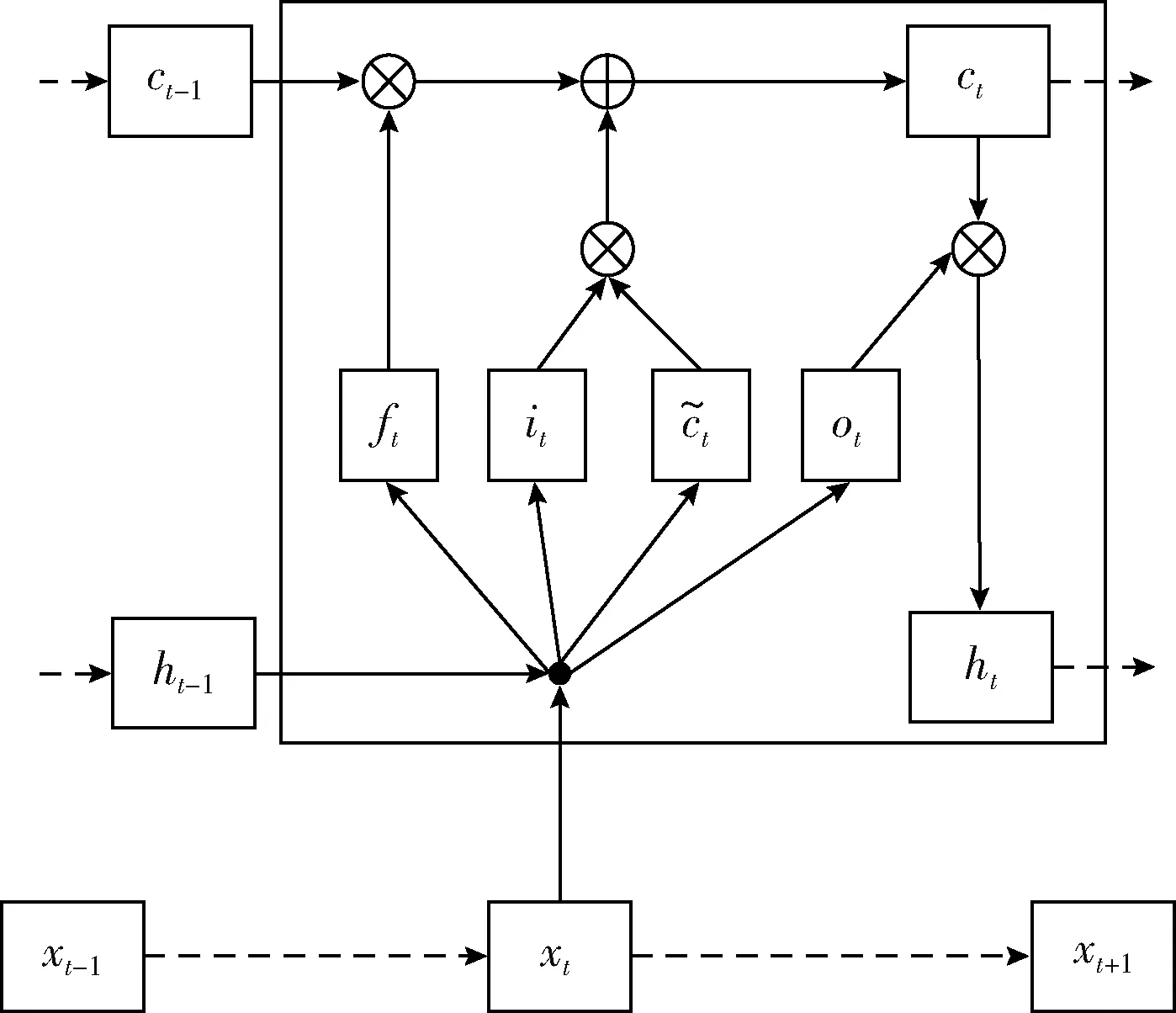
圖3 LSTM結構
輸入門it和輸出門ot控制信息流入和流出網絡,遺忘門ft控制先前序列對當前的影響。每個門的更新公式如下[8]
it=σ(wxixt+whiht-1+bi)
(3)
ft=σ(wxfxt+whfht-1+bf)
(4)
ot=σ(wxoxt+whoht-1+bo)
(5)
(6)
(7)
ht=ot⊙tanhct
(8)
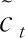
LSTM非常適合處理與時間序列高度相關的問題,因為它可以模擬短時間和長時間信息,但是傳統LSTM忽略了上下文信息即未來信息,只能從單元方向學習。
雙向長短時記憶網絡(Bi-LSTM)[9]對LSTM進行改進從而可以充分考慮過去和未來的信息。Bi-LSTM具有兩個不同方向的LSTM層,前向LSTM層捕獲行為發生時間從前至后的演變特征,后向LSTM層模擬相反方向的演變,對時間序列處理能力更強。
1.3 Kinect
Kinect[10]是2010年由微軟公司推出的基于體感交互的人機交互設備,其最初作為Xbox360游戲機的外設,2012年微軟推出Kinect for windows,使該項技術可以應用于各行各業,改變了人們工作、生活、娛樂的方式。2014年,微軟發布了Kinect v2,在硬件和軟件上均對第一代產品進行了優化。
Kinect v2主要由深度傳感器(Depth sensor)、彩色攝像機(RGB camera)以及4個單元的麥克風陣列(Microphone array)幾部分組成,可以獲取彩色圖像、深度圖像、紅外線圖像等多種信息,在手勢識別、人臉識別、語音識別3D建模等領域皆有應用。它可獲得每幀人體的25個關節點,最多可檢測6個人體。
本文所使用的標準數據集和自制數據集均采用Kinect設備獲取骨骼信息。
2 行為識別的CNN與Bi-LSTM混合模型
2.1 總體框架
本文將卷積神經網絡(CNN)與雙向長短期記憶網絡(Bi-LSTM)相結合。CNN用于檢測骨架關節位置間的空間關系,充分利用三維骨骼信息提取特征。Bi-LSTM可以捕獲隨著時間演變的時間關系。模型總體框架如圖4所示。
模型思路是:利用Kinect設備獲取人體關節三維坐標,分為訓練數據和測試數據兩部分。訓練數據用于模型構建和參數調整,訓練完成后利用測試數據集測試模型性能。
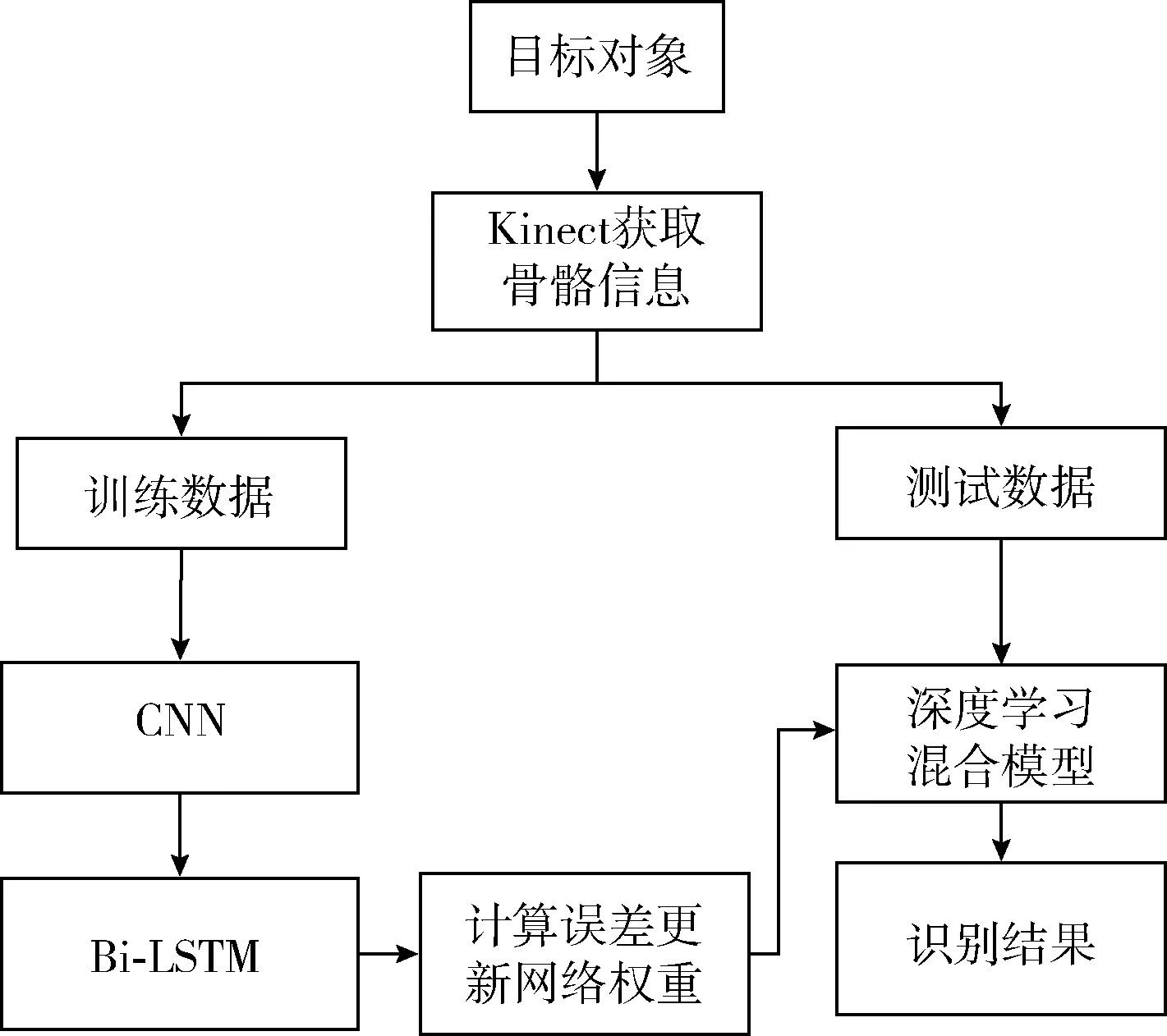
圖4 模型框架
2.2 混合網絡模型
2.2.1 卷積神經網絡層
CNN通常用來探索圖像中的局部特征,本文使用CNN提取三維骨骼數據間的局部位置特征。CNN特征提取網絡結構如圖5所示,包含4個卷積層及3個池化層,多次采用小卷積核提取骨骼數據的深層特征。第一個卷積層卷積核大小為3×3,卷積核數量為20,對骨骼數據3個維度進行特征提取及融合;第二個卷積層使用50個大小為2×2的卷積核;第三個卷積層,使用50個1×1的卷積核提取深層特征;第四個卷積層使用100個大小為3×3的卷積核。池化層均使用尺寸為2×2的最大池化層,步長均取1。

圖5 卷積神經網絡層
2.2.2 雙向長短期記憶網絡層
LSTM通常用來處理依賴時間的序列問題,但LSTM的記憶能力也是有限的,Bi-LSTM處理時間序列的能力更強。Bi-LSTM使用兩層不同方向的LSTM相連,用于捕獲三維骨骼坐標隨時間演變的深層時空特征。在CNN最后一層池化層后連接Bi-LSTM,兩層LSTM均包含100個隱層單元,Bi-LSTM網絡結構如圖6所示。
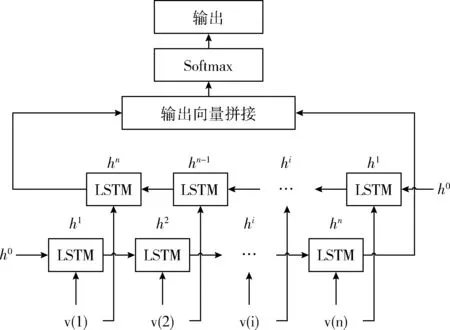
圖6 雙向長短期記憶網絡層
Bi-LSTM將兩層LSTM的最后一個輸出通過式(9)拼接后連接Softmax層輸出識別結果yt
(9)
yt=σ(ht)
(10)
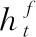
2.2.3 CNN與Bi-LSTM混合模型
將2.2.1節和2.2.2節所述網絡連接后得到本文的CNN+Bi-LSTM混合模型。模型輸入為一段時間序列的三維關節坐標,CNN網絡對數據進行多次卷積、池化操作提取局部深層特征,輸出提取到的多個特征向量,Bi-LSTM網絡提取數據依賴于時間的時間特征,雙向網絡的輸出連接到Softmax層進行分類得到結果。模型結構如圖7所示。

圖7 CNN+Bi-LSTM混合模型
以MSR Action3D標準數據集為例,模型輸入數據可以看作三維數據塊,每幀采集對象的20個關節三維坐標。數據結構如圖8所示。輸入數據的3個維度分別是人體20個關節、3個空間坐標 (x,y,z) 和動作持續的幀數T。骨骼數據的3個維度類比于RGB圖像的3個通道,三維數據塊可以看成20*T的三通道圖像。
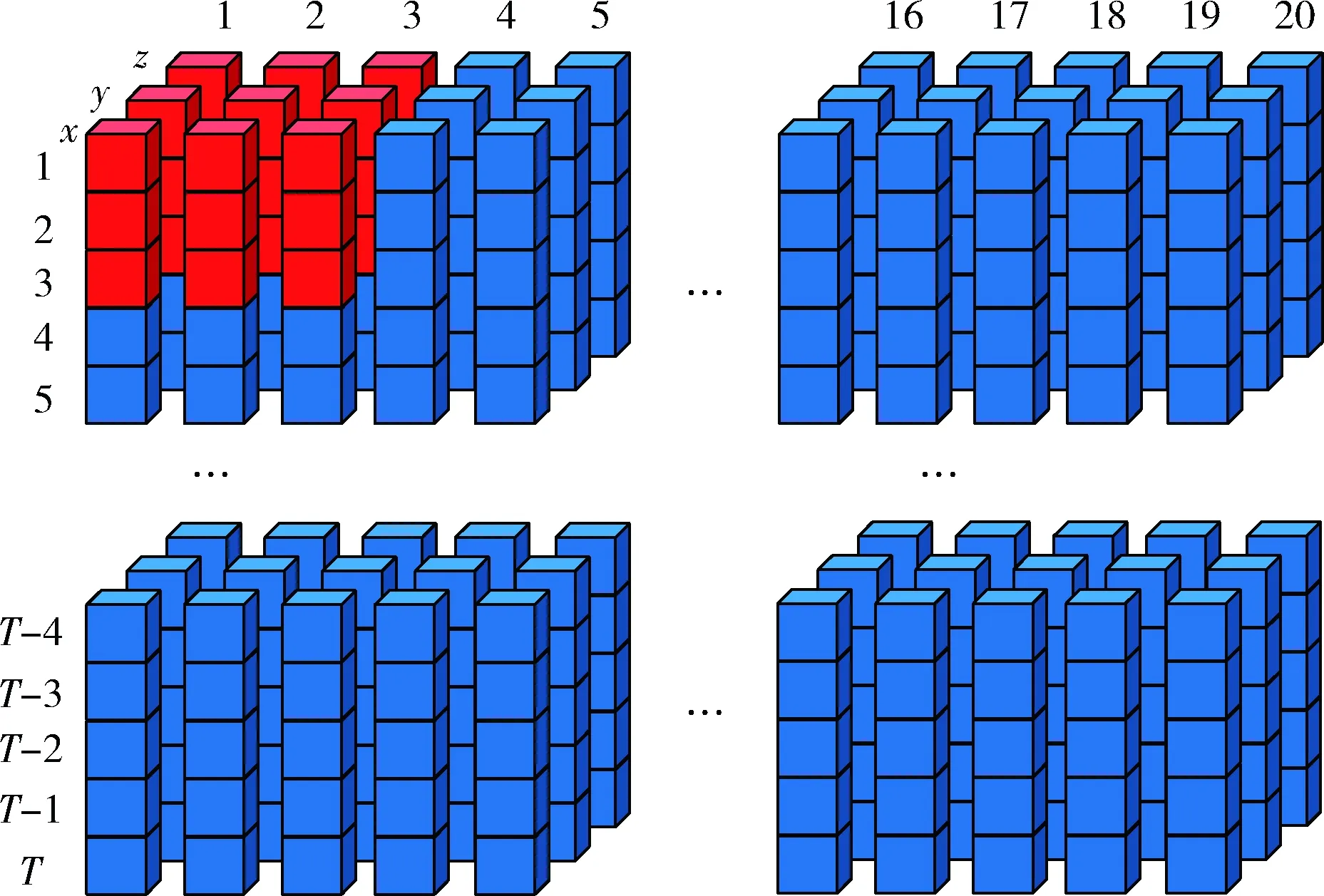
圖8 網絡輸入數據結構
數據在混合模型的計算過程是:數據塊通過第一卷積層處理后變為20個 (T-2)*18*1的數據塊,在通過其對應的池化層,時間步長和骨架關節數量的原始維度減半,即 (T-2)/2*9*1。 數據經過第二、三層卷積層和池化層過濾降維后尺寸變為 (T-4)/4*4*50。 再通過第四層卷積層和池化層過濾降維后得到 (T-12)/8*1*100的數據塊。經CNN處理后的數據繼續作為Bi-LSTM網絡的輸入,每個隱層單元輸入數據為 (T-12)/8*1的一維向量,反向LSTM的輸入是正向LSTM的逆序,兩個LSTM網絡的輸出拼接后連接Softmax得到最終輸出。
3 實驗與分析
3.1 數據集
本文數據集使用標準數據集UTKinect-Action3D[11]。該數據集拍攝視角不同并存在遮擋,同種動作間也存在明顯差異,動作持續時間變化大,使得識別工作更具挑戰性。
UTKinect-Action3D數據集在室內環境下使用Kinect設備收集了10種動作類型,包括:走路、坐下、站起、撿起、抬起、扔、推、拉、揮手和拍手。每個動作由10個不同實驗對象執行兩次,總共由199個序列組成。
3.2 實驗環境、參數配置及評價指標
本實驗使用基于Python的深度學習框架Keras實現,平臺參數:CPU,Intel i3-2370U;6 G內存;GPU,NVIDIA GeForce GT 720M,Win10 64位操作系統。
深度學習模型參數設置直接影響識別結果,CNN參數設置見表1,CNN每批數據量大小為200,最多訓練100個epoch,初始學習率設置為0.1,使用ReLU作為激活函數,采用最大池化法。
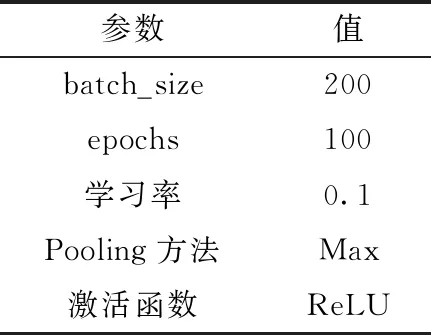
表1 CNN模型參數
Bi-LSTM參數設置見表2,Bi-LSTM的批數據尺寸和epoch設置為500和16,學習率為0.001,隱藏層設置為100時訓練效果最好。其余參數均為默認。
評價指標為行為識別分類結果的準確率,計算方法為式(11)
(11)
其中,p代表模型將測試集中的行為正確識別出來的數量,q代表測試集中所有行為的數量。
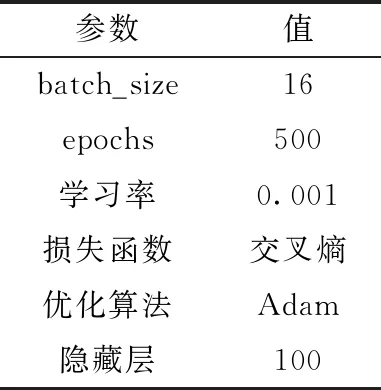
表2 Bi-LSTM模型參數
3.3 實驗結果及分析
由于輸入數據涉及幀數,在UTKinect-Action3D數據集上取不同的幀數進行第一個實驗,分別取T=10, 20, 30得到實驗結果見表3。

表3 不同幀數對比實驗
發現T=20時,識別準確率最高,識別效果最好,所以下文實驗統一采用T=20。
第二個實驗是將改進后的Bi-LSTM與LSTM進行比較,結果見表4。

表4 CNN+Bi-LSTM與CNN+LSTM在 UTKinect-Acition3D數據集上的結果比較
結果顯示CNN+Bi-LSTM在UTKinect-Action3D上的識別準確率比CNN+LSTM提高了2.2%,說明雙向LSTM對長時間序列處理能力稍優于LSTM。
由于UTKinect-Acition3D數據集規模較小,所以實驗采用留一法交叉驗證,采用CNN+Bi-LSTM混合模型對數據集進行測試,實驗結果見表5。
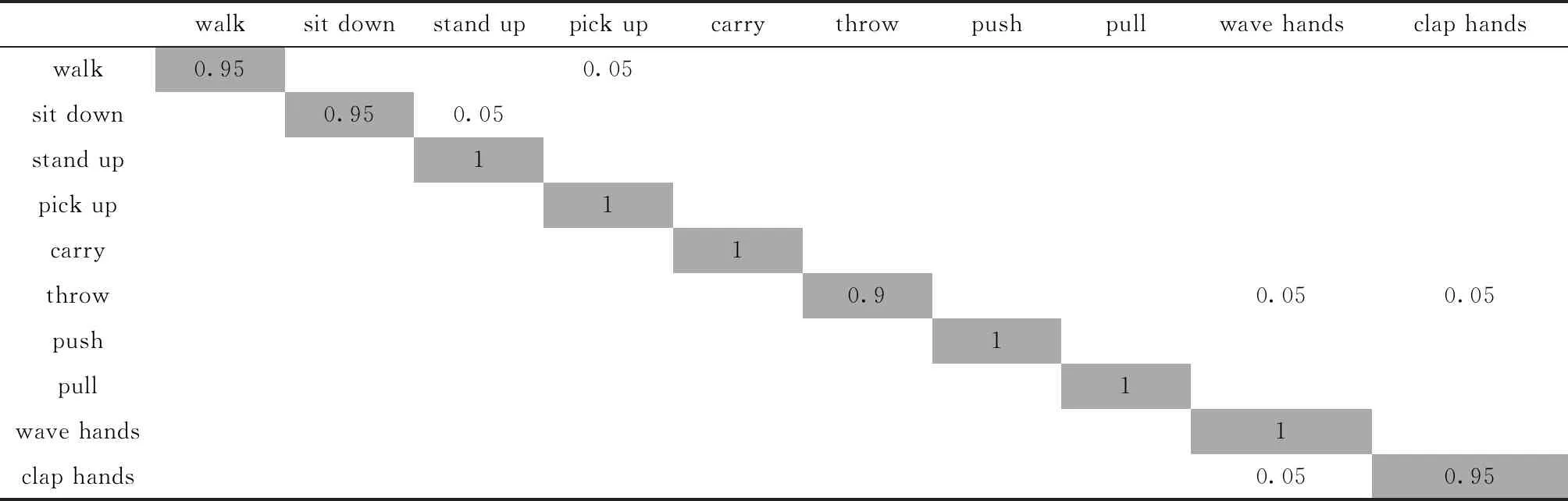
表5 UTKinect-Acition3D數據集混淆矩陣
CNN+Bi-LSTM在UTKinect-Acition3D數據集上識別準確率最高達到了100%,最低也達到90%。結果顯示本文模型對不同動作的誤判現象較少,每種動作的識別率均與平均識別率也較接近,識別準確率高。
為驗證本文算法的識別效果,將本文模型與國內外相關模型進行對比。文獻[12]提出一個ST-LSTM的樹狀結構模型,輸入數據是骨骼數據,該模型驗證實驗同樣采用留一法交叉驗證;文獻[13]先使用CNN提取特征后直接連接一個Softmax層分類。該模型只處理深度圖像。文獻[14]基于深度圖像使用三流CNN提取特征并使用LSTM分類。本文方法與以上幾種模型在UTKinect-Acition3D數據集上的實驗結果進行對比見表6。

表6 CNN+Bi-LSTM與其它文獻方法比較
CNN+Bi-LSTM模型在UTKinect-Acition3D數據集上識別準確率整體優于其它文獻,比文獻[12]中的最高準確率提高了0.5%,比文獻[13]提高了15.5%,相對于文獻[14]的模型提高16.4%。結果表明基于骨骼的CNN+Bi-LSTM模型具有較強的識別能力,有效提高了識別準確率。
4 應用驗證
4.1 自制數據集
工廠駕駛員操作行為直接影響人身安全和設備安全。某廠駕駛員的違規操作直接導致吊車上的物體觸碰高壓線,整個車間斷電停機,嚴重時還會造成人員傷亡,所以駕駛員的操作行為檢測至關重要。本文以駕駛員行為識別為背景,自制人體行為識別數據集,驗證本文所提算法的有效性。
本文調研了該廠駕駛員監控錄像,發現幾種常見行為,該實驗旨在對幾種行為進行識別。本文使用Kinect v2設備獲取人體3D關節坐標數據,以.txt格式存儲。為避免遮擋Kinect v2設備放置在1.5 m高,距離實驗者2 m位置處。本數據集招募10名實驗對象,每個動作重復做5次。每一個動作均手工制作行為標簽,包括坐下、站起、雙臂上舉、玩手機4種動作,圖9為自制數據集繪制出骨架的人體動作裁剪樣例。共包含200個動作序列。

圖9 動作類型
4.2 實驗結果與分析
在自制數據集上對CNN+Bi-LSTM進行評估,由于本數據集大小與UTKinect-Action3D較為相似,實驗也采用留一法交叉驗證,得到幾種動作的識別結果見表7。
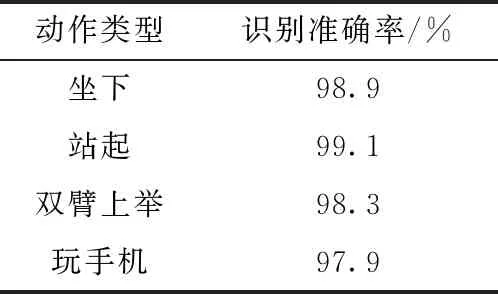
表7 自制數據集識別結果
在自制數據集上的4種動作識別率均達到了97%以上,平均識別率達98.6%,該模型對不同動作混淆現象較少,動作識別準確,效果顯著,驗證了模型的可用性。
5 結束語
本文提出了基于骨骼的CNN和Bi-LSTM混合模型應用在人體行為識別中,在UTKinect Action3D數據集上的識別準確率達到了97.5%,在自制數據集上的實際驗證也達到了98.6%的準確率,相比傳統行為識別,骨骼數據相比圖像包含更多維度的信息,深度學習網絡能夠自動提取復雜的空間時間特征,識別率顯著提升。但目前的行為識別仍在研究階段,未來將繼續研究將行為識別應用到具體應用場景中去。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
