基于圖學習的社會網絡圖像標簽排序算法
2020-03-07 12:47:52王婧
計算機工程與設計 2020年2期
王 婧
(1.中國科學院 計算機網絡信息中心,北京 100190;2.北京電子科技職業學院 電信工程學院,北京 100176)
0 引 言
隨著Web2.0平臺的快速發展,許多社會網絡圖像(Social image)共享網站(例如Flickr,Photosig,以及Instagram)蓬勃發展,此類網站允許用戶上傳并分享自己拍攝的照片[1]。另一方面,由于移動互聯網技術,以及廉價存儲設備和智能手機的普及,人們可以便捷的訪問互聯網。因此,海量的由用戶提供的照片被迅速上傳到各圖像共享網站,并與其他用戶分享[2,3]。圖像共享網站不僅允許用戶上傳照片,還允許用戶為照片提供描述其語義信息的詞語(也稱“標簽”)。
圖像分享網站鼓勵用戶為上傳的照片提供語義標簽,標簽可以看作索引關鍵字,為圖像賦予準確的標簽將顯著提高基于標簽的圖像檢索系統的性能[4,5]。但是,用戶的標注行為具有較高的主觀性和多樣性,部分用戶提供的標簽準確性和完整性都不高,甚至有些用戶會提供和圖像的語義信息毫無關聯的標簽。因此,用戶提供的標簽和圖像的視覺內容之間存在語義鴻溝,這為社會網絡圖像搜索和挖掘帶來了很大的困難[6]。
基于上述分析,本文旨在通過對用戶提供的標簽進行重排序,進而去除與圖像語義信息無關的噪聲標簽,從而有效提高圖像標簽的準確性。本文的創新點主要表現在以下兩個方面:
(1)提出了一種融合圖像視覺相似度和標簽語義相似度的加權投票方法,投票過程綜合了不同用戶的標注行為和標注習慣,使得標簽排序結果更加客觀準確。
(2)利用視覺近鄰圖像的標簽集構造標簽圖模型,并充分利用近鄰投票結果和圖模型中標簽之間的關系,利用迭代計算進行目標圖像的標簽排序。
1 相關工作
圖像共享網站為提高圖像檢索系統的性能開辟了全新的研究思路,吸引了眾多學者的關注。許多學者致力于研究如何為圖像賦予準確的語義標簽。為圖像賦予準確的語義描述信息(標簽)是基于文本的圖像檢索(text-based image retrieval,TBIR)系統的關鍵環節,李錫榮等對圖像標簽指派,圖像標簽優化以及基于標簽的圖像檢索進行了綜述,全面介紹了Web 2.0時代TBIR系統遇到的新問題,以及涉及的新理論和新方法[7]。
Hu等提出一種基于魯棒多視圖半監督學習模型的圖像標注方法。該方法利用基于圖拉普拉斯矩陣的半監督學習挖掘數據的內在結構信息[8]。Jiu等提出一種基于非線性深度核學習的圖像標注方法,利用深度多層網絡重新定義了多核[9]。Li等提出了一種基于弱監督深度矩陣分解算法的圖像標注及優化方法,通過對弱監督標注信息、視覺結構和語義結構的協同分析[10]。Verma等提出一種兩階段K最近鄰算法以及一個度量學習框架,并將其用于圖像標注[11]。Feng等提出一種基于語義概念共現模式的圖像標注和檢索方法[12]。
針對已有的社會網絡圖像標簽進行排序,提高圖像語義信息描述的準確性,對于TBIR系統具有十分重要的意義。Li等提出基于近鄰投票(neighbor voting,NV)的標簽排序方法[13],該方法利用目標圖像的視覺近鄰為其標簽進行投票,并利用投票分值進行標簽排序。Liu等提出基于概率密度估計(probability density estimation,PDE)和隨機漫步(random walk,RW)的標簽排序方法(簡稱PDE-RW)[14],該方法利用概率密度估計得到標簽的初始相關度,然后利用隨機漫步算法對標簽相關度進行優化。Zhang等提出基于壓縮域視覺詞語(visual words in compressed domain,VWCD)的標簽排序方法[15],該方法利用SIFT特征描述子從低分辨率圖像中抽取視覺詞語,并在此基礎上利用近鄰投票策略進行標簽排序。Guo等提出基于顯著性檢測(saliency detection,SD)的標簽排序方法[16],該方法充分利用圖像顯著性檢測結果進行標簽排序,從計算機視覺的角度為圖像標簽排序提出了新的解決思路。
上述方法利用不同的機器學習模型和算法針對圖像的語義挖掘和語義標注問題展開了研究,獲得了較好的實驗結果。通過對上述研究工作的深入分析,對上述研究工作存在的不足之處總結如下:
不足之處1:上述方法主要采用人工設定的圖像特征描述方法(例如,SIFT特征描述子),雖然獲得了較好的性能,但是與利用深度學習得到的圖像特征尚有一定的差距。如果能利用深度學習框架得到更加準確的圖像特征描述,對于提升圖像的語義挖掘準確性具有積極意義。
不足之處2:社會網絡中的圖像標簽是圖像上傳者人為設定的,存在較高的主觀性以及較高的噪聲。而利用上述方法進行圖像的語義挖掘時對圖像的初始標簽有較高的依賴性,這在一定程度上限制了圖像語義挖掘的準確性。
本文針對已有研究工作的不足之處展開深入研究,針對不足之處1,將SIFT特征、卷積神經網絡特征以及視覺詞袋模型相結合,提出了一種圖像視覺特征描述方法;針對不足之處2,采用近鄰投票策略以及聯合多社會圖像的標簽圖模型,將相關圖像的語義信息傳播至目標圖像,可以較好地解決目標圖像的初始語義標簽不準確的問題。
2 問題描述
本文將通過研究標簽排序算法解決兩個主要問題:①去除噪聲標簽;②根據標簽的語義信息與圖像的視覺特征之間的相關度進行標簽排序。
2.1 社會網絡圖像標簽排序
假設社會網絡圖像數據集表示為Θ,標簽字典表示為T。對于社會網絡圖像I∈Θ以及標簽t∈T,將計算標簽相關度的函數定義為H(t,I), 該函數應滿足如下兩個條件:
條件1:假設兩幅社會網絡圖像I1,I2∈Θ以及標簽t∈T, 如果標簽t與圖像I1的相關度高于圖像I2, 則滿足下述條件
H(t,I1)>H(t,I2)
(1)
條件2:假設兩幅社會網絡圖像的標簽t1,t2∈T以及社會網絡圖像I∈Θ, 如果標簽t1比標簽t2更適合描述圖像I的語義信息,則滿足下述條件
H(t1,I)>H(t2,I)
(2)
圖1給出了社會圖像標簽相關度計算流程。首先,構建社會圖像數據集,從該數據集中獲取目標圖像的視覺近鄰。然后,所有視覺近鄰都投票給目標圖像的標簽。此外,為了提高重要視覺近鄰的投票權值,投票分值由視覺相似度和標簽相關性加權計算得到。接下來,利用近鄰投票結果,在標簽圖上進行隨機漫步,從而計算出標簽相關度。
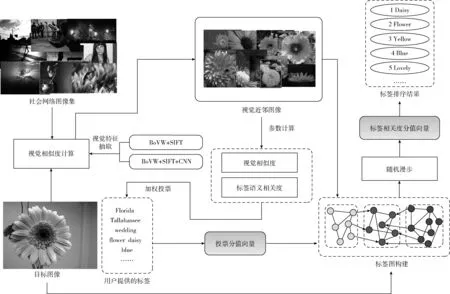
圖1 社會圖像標簽排序流程
2.2 圖像視覺相似度計算
本文將對兩種圖像特征描述方法進行對比分析:①視覺詞袋模型(bag of visual words,BoVW)+尺度不變特征變換(scale-invariant feature transform,SIFT),②BoVW+SIFT+CNN(convolutional neural network)。
從圖像訓練集中抽取SIFT特征描述子,并將其進行聚類,從而學習出由256個視覺詞匯構成的視覺詞典。利用視覺詞典,本文將一幅圖像表示為256維的特征向量(簡稱BoVW+SIFT特征),該特征向量中的每一維對應于一個視覺詞,其取值為該視覺詞出現在該幅圖像中的次數。本文將充分融合CNN特征與BoVW+SIFT特征,獲得更為有效的圖像視覺特征描述。
從圖像訓練集中學習出的碼書(Codebook)表示為CB=(cb1,cb2,…cbk), 其中cbi表示碼書中的第i個視覺詞。本文將一組特征描述符表示為固定維度的向量,并將描述SIFT特征的向量s分配給與其距離最近的視覺詞 (cbi=Nb(s))
(3)
對于視覺詞cbi, 將其與距離最近的視覺詞之間的差異進行累加,計算方法如下
(4)
式(4)的主要任務是計算視覺近鄰為視覺詞cbi的所有SIFT特征描述子與cbi的距離之和,并將其作為向量fv的第i個維度fvi。 在此基礎上,構造128×k維向量fv
fv=[fv1,fv2,…,fvi,…,fvk],fvi∈R128
(5)
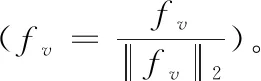
本文從GoogLeNet的pool5層中抽取1024維的CNN特征(表示為fp)。
利用式(6)對向量fv和fp進行融合
f=[fv,fp]
(6)
特征向量f的維度為2048維,利用PCA白化進行降維處理
(7)
其中,MPCA表示主成分分析(principal component analysis,PCA)變換矩陣,參數h表示降維處理后保留的特征維數,svi表示第ith個奇異值。接下來,使用L2范數歸一化獲取1024維的稠密向量。
在上述過程基礎上,利用K-means算法學習出由1000個視覺詞語構成的視覺詞典,利用該詞典,每幅圖像都可以表示為1000維的特征向量(稱為BoVW+SIFT+CNN)。
圖像Ii和Ij的視覺相似度計算方法如下
(8)
其中,fi,fj分別表示圖像Ii和Ij的特征向量。
3 基于圖學習的標簽排序算法
標簽相關度是指圖像的視覺特征與標簽的語義信息之間的相關程度。對于目標圖像Ij, 其視覺鄰居Ik對標簽ti的投票分數可以通過對圖像視覺相似度和標簽語義相似度的線性加權計算而得
Vote(ti,Ij,Ik)=λ·Simv(Ij,Ik)+(1-λ)·Sims(ti,T(Ik))
(9)
其中,λ為權值參數,Sims(ti,T(Ik)) 表示標簽ti和圖像Ik的標簽集合T(Ik)之間的語義相似度,計算方法如下
(10)
其中,Sims(ti,tj) 表示標簽ti和tj之間的語義相似度。由式(10)可知,Sims(ti,T(Ik)) 計算標簽ti與標簽集合T(Ik) 中各標簽的語義相似度的平均值。標簽ti與標簽tj之間的語義距離d(ti,tj) 定義為
(11)
其中,參數N(ti) 和N(tj) 分別表示被標簽ti和tj所標注的圖像的數量,參數N(ti,tj) 表示同時被標簽ti和tj所標注的圖像的數量。參數Γ表示Google圖像搜索引擎中所有圖像的數量,標簽ti和tj之間的語義相似度Sims(ti,tj) 可以通過如下公式計算
(12)
參數σt表示經驗集。
文本構造基于標簽圖和隨機漫步的標簽相關度挖掘模型。在標簽圖中,標簽從目標圖像及其視覺鄰居中過去,并將用戶提供的標簽視作圖的頂點,標簽相關性作為邊權值。為降低計算開銷,將低于閾值的邊從標簽圖中去掉。有一幅目標圖像及其兩個視覺鄰居的標簽如圖2所示。
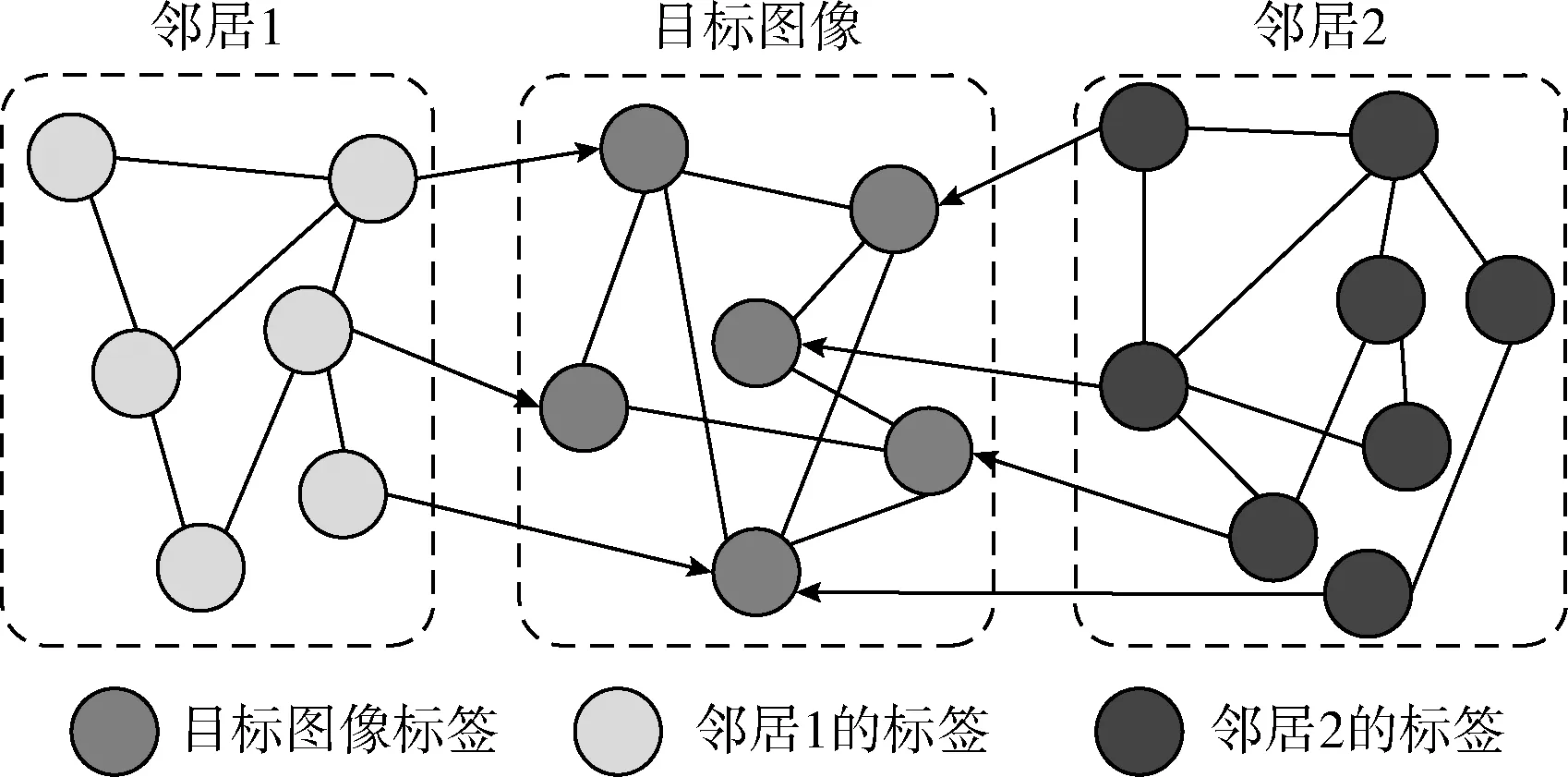
圖2 標簽圖示例
假設標簽圖表示為G=(V,E), 其中V,E分別表示標簽圖的頂點和邊,并且滿足V=VS+VN。 其中,VS,VN分別表示目標圖像及其視覺鄰居的標簽。為了防止目標圖像反向影響其視覺鄰居圖像,目標圖像和其視覺鄰居之間的邊是有向的,其它邊是無向的。標簽圖G的轉移概率矩陣表示為M, 該矩陣的元素mij表示由標簽ti轉移至tj的概率,mij的計算方法如下
(13)
概率轉移矩陣M的定義如下
(14)
其中,MS和MN分別表示描述VS和VN轉移概率的方陣,MSN表示存儲由VN至VS的轉移概率的矩陣。
算法1:基于圖學習的標簽排序
輸入:目標圖像I以及用戶提供的標簽集T={t1,t2,…,tN}, 視覺鄰居 {I1,I2,…,IK}。
輸出:標簽排序結果T*。
(1)將用戶提供的標簽輸入到維基百科,刪除沒有匹配項的標簽,將剩余標簽構成的集合表示為 {t1,t2,…,tM}。
(2)將所有視覺鄰居圖像的投票分值求和
(15)
其中,Votei表示所有視覺鄰居對標簽ti的投票權。
(3)構建投票分值向量Vote=(Vote1,Vote2,…,VoteM)。
(4)標簽相關度分值向量定義為R={r1,r2,…,rM}, 其中ri表示標簽ti的相關度分值。
(5)標簽相關度分值向量的初始狀態設置為R(0)=(1,1,…,1)。
(6)利用隨機漫步算法,標簽相關度分值的第lth次迭代可以通過如下公式計算得到
R(l)=(φM)lR(0)+(1-φ)(I-φM)-1(I-(φM)l)Vote
(16)
(7)標簽相關度分值向量的計算方法如下
(17)
(8)根據標簽相關度分值向量R對標簽集{t1,t2,…,tM} 進行降序排序,排序后的標簽序列表示為T*。
算法1中的參數φ(參見式(16))表示投票分數的初始狀態和轉移矩陣對標簽相關度計算產生的影響,該算法的時間復雜度為O(n3)。
4 實驗結果及分析
為驗證算法的有效性,本文利用MIRFlickr25k數據集[17]進行實驗,該數據集包括25 000幅Flickr圖像。本文選取MIRFlickr25k數據集中常用的10個圖像標簽,根據這10個標簽進行圖像的分類和標簽排序的性能評測。這10個標簽為:①sky,②flower,③dog,④sea,⑤girl,⑥bird,⑦snow,⑧lake,⑨beach,⑩street。
4.1 性能評價指標
本實驗采用均值平均精度(mean average precision,MAP)以及歸一化折損累積增益(normalized discounted cumulative gain,NDCG)作為性能度量方法。MAP的定義中使用了平均準確性(average precision,AP),MAP表示查詢集中所有查詢詞檢索結果的平均準確性。假設q和Q分別表示查詢詞以及查詢詞集合,MAP的計算方法如下
(18)
本文實驗為每個社會網絡圖像標簽設置5個相關度等級:①非常相關(5分),②相關(4分),③一般相關(3分),④弱相關(2分)以及⑤不相關(1分)。假設一幅社會網絡圖像排序后的標簽集為 {t1,t2,…,tn}, 則其NDCG值計算方法如下
(19)
其中,r(i) 表示標簽ti的相關度,τn表示歸一化常數。
4.2 參數設置
本小節實驗中視覺特征統一采用BoVW+SIFT特征。
4.2.1 近鄰數量的選取
近鄰投票是本文方法的關鍵問題,而近鄰數量的選取對投票結果有著至關重要的影響。因此,本文將討論如何選取合適的近鄰數量。由式(9)的投票權值計算方法可知,投票分值有兩種類型的因素構成:①視覺相似度;②標簽相關度。接下來,將本文方法與其它3種投票方法利用MAP值進行性能對比,具體包括:①只使用視覺相似度的加權投票;②只使用標簽相關度的加權投票;③無加權投票(作為性能評測的基準)。實驗結果如圖3所示。
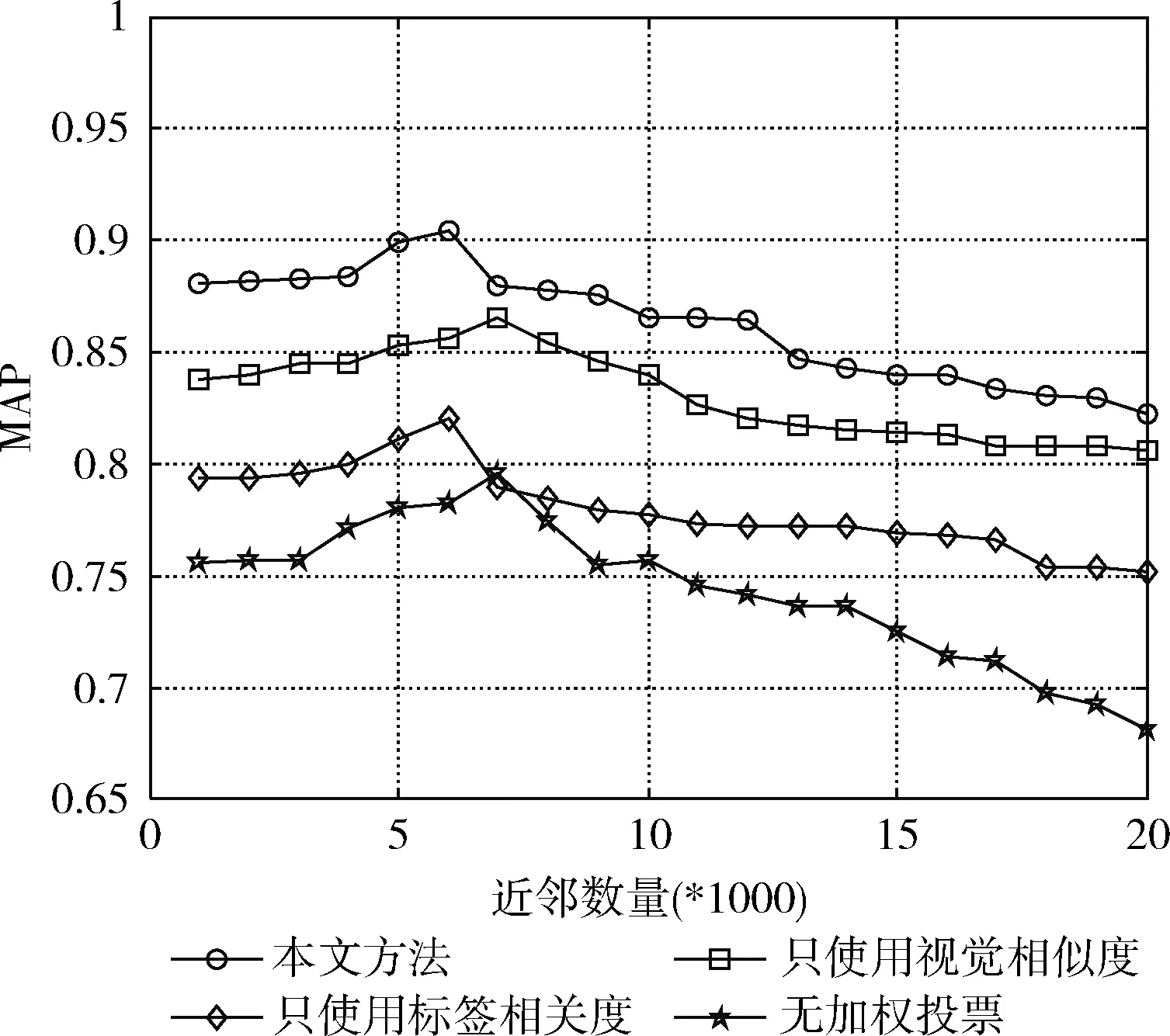
圖3 不同方法的MAP值對比
如圖4所示,利用本文提出的圖像標簽相關度計算方法,可以顯著提高圖像標簽排序的準確性,從而有效提高MAP值。原因在于,本文提出的方法充分利用了圖像的視覺特征和標簽的語義信息進行加權投票,使得與目標圖像具有較高相關度的近鄰圖像具有更高的投票權。此外,還可觀察出,相比標簽相關度,視覺相似度對近鄰投票過程更加重要。從圖4還可以看出本文提出的方法在近鄰數量取6000時,MAP達到最大值。因此,在接下來的實驗中,將本文方法的近鄰數量設置為6000。通過分析可知,視覺近鄰數量太少和太多都無法獲得最優的MAP值。原因在于,視覺近鄰數量過少將導致投票過程對標簽語義信息的覆蓋度降低;而視覺近鄰數量過多將使得投票過程包含過多的噪聲信息,從而降低投票的有效性。
與性能評測基準相比,包括本文方法在內的3種不同方法獲得的性能提升如圖4所示。
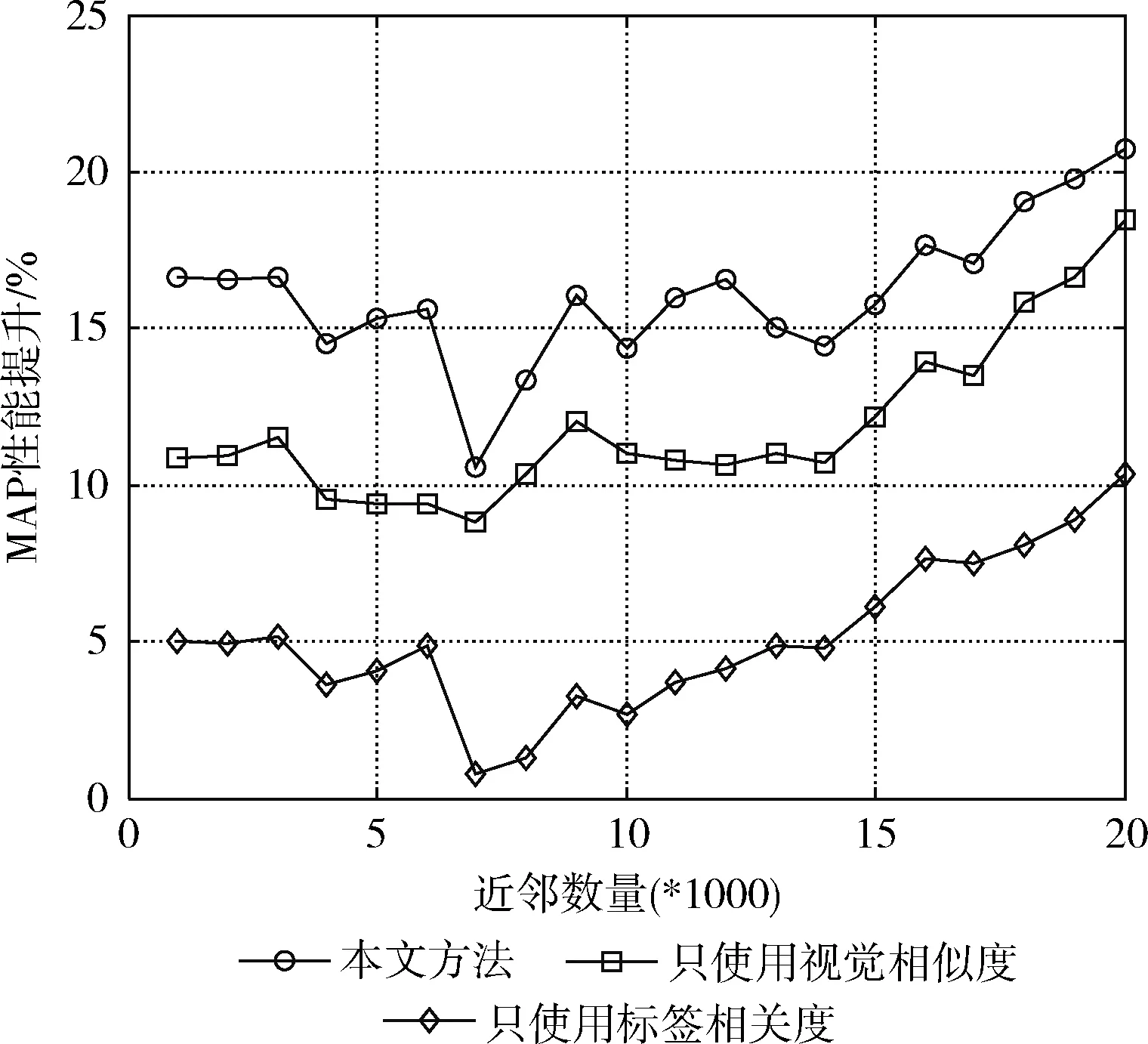
圖4 MAP性能提升分析
從圖4可以看出,本文提出的方法與其它加權投票策略相比,能夠獲得更高的MAP性能提升。當近鄰數量高于9000時,基本上可以保證約20%以上的MAP性能提升。
綜上,本文方法可以得到比其它方法更高的MAP值,并且對近鄰數量的變化并不敏感,具有較高的魯棒性。
4.2.2 參數λ的選取
如式(9)所示,通過對圖像視覺相似度和標簽語義相似度的線性加權可以計算出目標圖像的投票分數。參數λ決定著圖像視覺相似度和標簽語義相似度對投票分值計算產生的影響。因此,λ的選取直接影響著標簽相關度計算的準確性。圖5中給出了近鄰數量以及參數λ的取值對MAP值的影響。
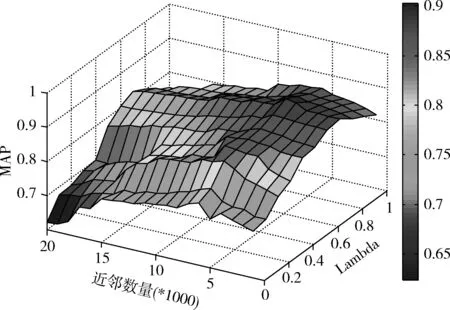
圖5 參數λ的選取
由圖5可知,當參數λ取0.7,近鄰數量取6000時,本文方法能夠得到最大MAP值。這也說明,相比標簽的語義信息,圖像的視覺特征對加權投票過程更加重要。
4.2.3 參數φ的選取
如式(16)所示,參數φ表示投票分數的初始狀態和轉移矩陣對標簽相關度計算產生的影響,該參數的選取也是本文方法的關鍵問題之一。根據上述實驗結果,將λ設置為0.7,近鄰數量設置為6000,測試φ的不同取值對MAP的影響,實驗結果如圖6所示。
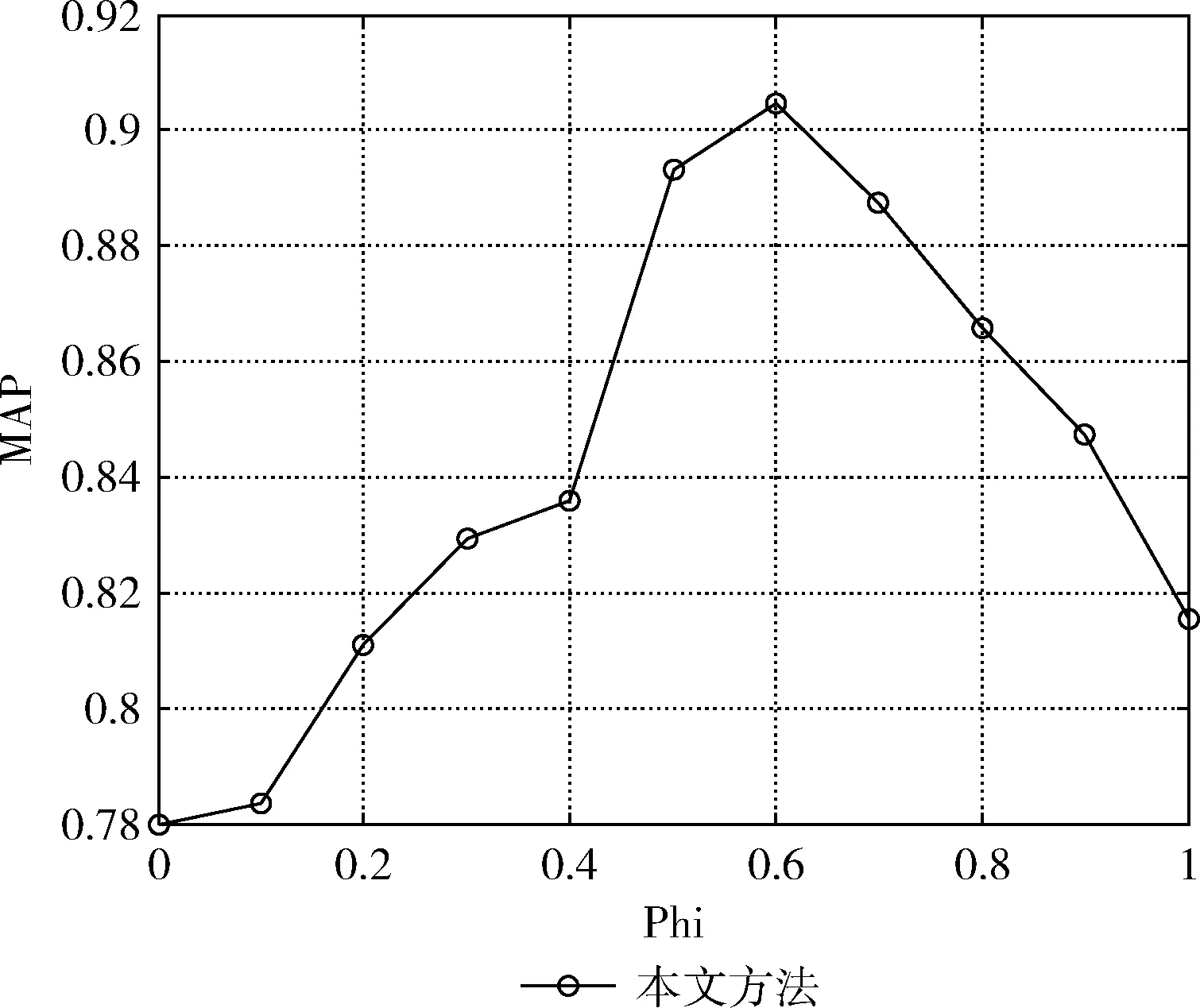
圖6 參數φ的選取
由圖6可知參數φ取0.6時MAP取得最大值,并且投票分數的初始狀態比轉移矩陣對標簽相關度的影響更大。
4.3 性能評測及分析
4.3.1 標簽排序
圖像標簽相似度計算常用于標簽排序,因此本部分通過標簽排序結果對標簽相關度計算的準確性進行評價。為了使得性能評價結果更加準確、客觀,使用NDCG將本文方法與經典的標簽排序方法進行性能對比,標簽排序性能對比分析所選用的方法包括:NV[13],PDE-RW[14],VWCD[15],SD[16],SR[18],MMRIM[19],以及TW-TV[20]。
接下來,利用NDCG對上述方法與本文方法進行性能對比,為了驗證兩種視覺特征BoVW+SIFT以及BoVW+SIFT+CNN的有效性,本文分別采用這兩種視覺特征進行各種排序方法的性能評測(如圖7所示)。
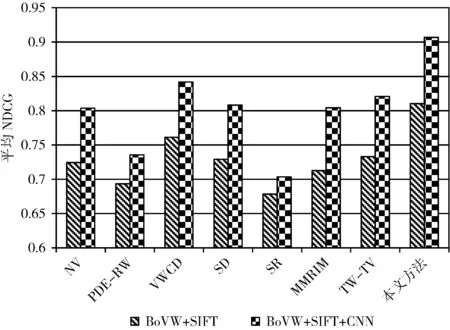
圖7 平均NDCG值
由圖7可知,本文方法的平均NDCG值高于其它方法;并且BoVW+SIFT+CNN特征比BoVW+SIFT特征具有更好的圖像語義描述能力,從而能夠有效提高標簽排序的準確性。下面的實驗中都將采用BoVW+SIFT+CNN視覺特征。
為進一步說明本文方法在不同圖像類別上的標簽排序性能,分別給出各排序方法在不同圖像類別上的平均 NDCG 值,實驗結果如圖8所示。
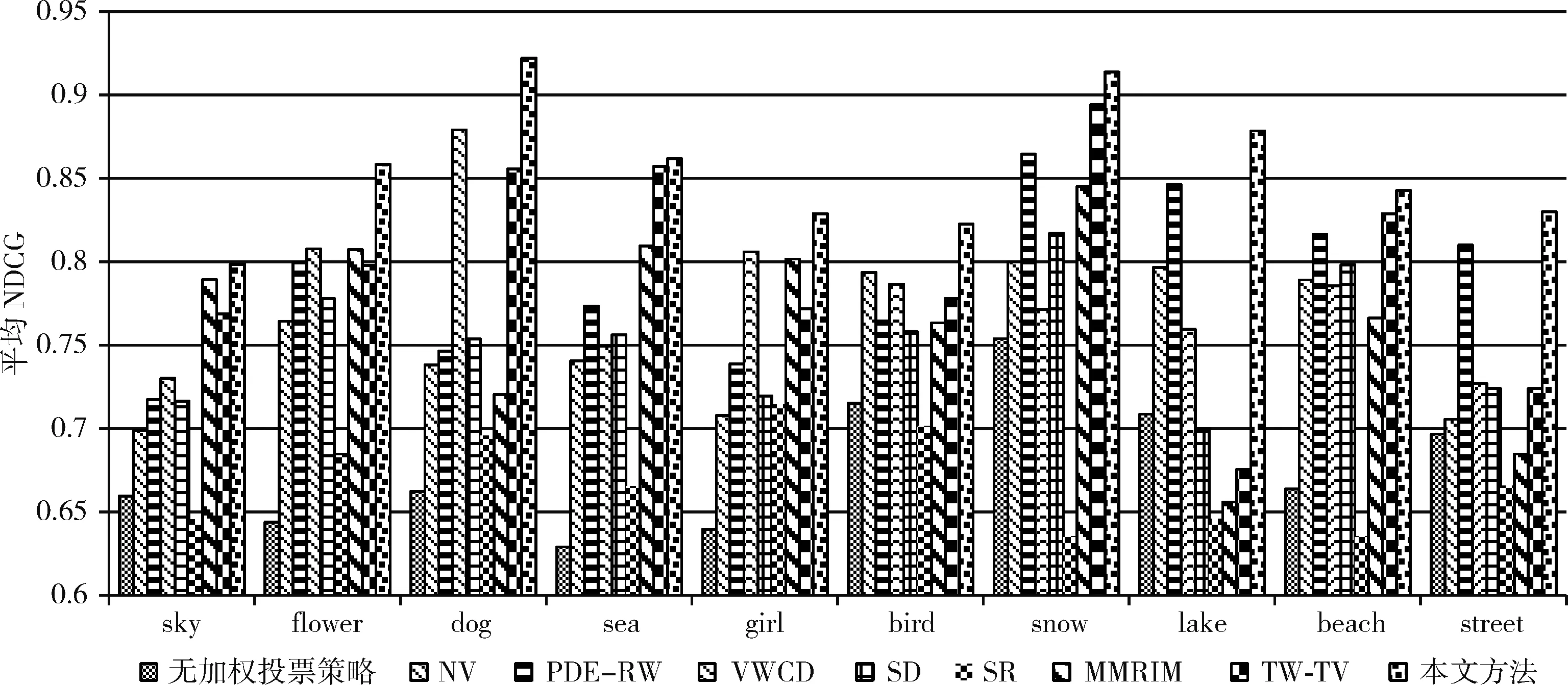
圖8 不同類別圖像的標簽排序結果
由圖8可知,本文方法在所有類別的圖像標簽排序上都獲得了優于其它方法的性能,而其它方法在不同圖像類別上的標簽排序性能不夠穩定。
本文方法的標簽排序性能優于其它方法的主要原因在于:①本文方法充分挖掘圖像的視覺相似度以及標簽的語義相似度,從而進行近鄰加權投票;此外,本文方法通過構建標簽圖模型,將近鄰圖像標簽的語義信息傳播給目標圖像,能夠有效提高標簽相關度計算的準確性。②本文方法利用對視覺近鄰圖像及其標簽進行加權投票,通過對圖像低層視覺特征和標簽高層語義信息的充分融合,有利于跨越“語義鴻溝”。③NV采用近鄰投票策略進行標簽排序,但是未對不同的視覺近鄰和不同的標簽進行加權處理,導致最終排序結果不夠準確。④PDE-RW通過對標簽圖的隨機漫步進行標簽排序,但是該方法需要具有準確語義標簽的訓練圖像集,當訓練圖像集的語義標簽不夠準確時,該方法的性能會大幅下降。⑤VWCD利用近鄰投票策略進行標簽排序,投票過程并未對視覺鄰居進行加權處理,也沒有充分考慮標簽間的關系。⑥SD采用計算機視覺的方法通過顯著性檢測進行標簽排序,該方法能夠有效檢測圖像中的顯著物體,但是,對于顯著物體以外的其它語義概念的排序性能不夠理想。⑦SR使用線性SVM分類器將圖像分為有顯著物體和沒有顯著物體兩類,然后對這兩類圖像分別進行處理從而得到標簽排序結果。但是該方法對于有顯著物體的圖像標簽排序結果較好(例如:Flower,Dog,Girl,Bird),而且其它類別圖像標簽排序的結果都不夠理想。⑧MMRIM模型和TW-TV模型雖然都考慮了圖像與標簽之間的關系,并對模型進行了優化,但是沒有充分考慮同類別圖像之間的語義關聯,當初始標簽噪聲較大時,排序結果不夠理想。
為了更加清晰地描述本文方法的標簽排序性能,表1中給出了本文方法對MIRFlickr25k數據集中的5幅圖像的標簽排序結果。

表1 社會網絡圖像標簽排序實例
由表1可知,本文方法可以有效地進行圖像標簽排序,排在前五位的標簽都與圖像的視覺特征有較高的語義相關度。
4.3.2 基于標簽的圖像檢索
為了更加全面評價本文方法的有效性,本文利用基于標簽的圖像檢索系統進一步驗證提出的標簽排序方法的有效性。本文將基于標簽排序方法的圖像檢索與其它3種圖像檢索策略進行對比分析:①基于興趣度的圖像檢索(策略1);②基于上傳時間的圖像檢索(策略2);③基于初始標簽順序的圖像檢索(策略3)。其中,策略1和策略2是Flickr為用戶提供的兩種圖像檢索策略。使用本文方法進行圖像檢索時,檢索詞在圖像標簽序列中排序越高,則該圖像在檢索結果中的排序也越高。
由圖9可知,基于本文標簽排序方法的圖像檢索系統能夠獲得比其它圖像檢索策略更好的性能,這也從側面說明本文提出的標簽排序方法對于提高圖像檢索系統的性能具有重要意義。

圖9 圖像檢索性能對比
5 結束語
本文提出了一種社會網絡圖像標簽排序算法。利用目標圖像的視覺近鄰圖像為其進行標簽加權投票,并在投票過程中充分考慮圖像間的視覺相似度和標簽間的語義相似度。此外,利用目標圖像及其視覺近鄰圖像的標簽構造標簽圖,在標簽圖上進行隨機漫步計算出標簽與圖像的相關度,從而完成標簽排序。實驗結果驗證了本文方法的有效性。
在下一步研究工作中,我們將對本文尚未解決的問題展開深入研究,主要包括:①如何在標簽排序時充分考慮用戶的興趣偏好,進行個性化標簽排序;②如何在標簽排序時充分考慮標簽的語義多樣性,從而為圖像檢索結果的多樣化表示提供思路。
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
開放教育研究(2020年2期)2020-03-31 01:54:14
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
