基于集成學習的金融反欺詐模型
2020-03-30 03:19:04黃鏡霖
電腦知識與技術 2020年1期
關鍵詞:機器學習
黃鏡霖

摘要:近年來,網上銀行在金融交易中變得越來越流行。但是欺詐行為也隨之急劇增加,給銀行造成了很大的損失。針對這種情況,提出了一種新的基于集成學習的數據挖掘技術。集成模型包括一組單獨的分類器,它們的預測被組合以預測新的傳入實例。我們主要考慮了三個最新的單個組件分類器:隨機森林,XGBoost和CNN卷積神經網絡。提出了一種創新的集成學習方法,通過多個模型的集成,并考慮了數據本身的特征,來提升模型的性能。實證結果表明,與單個組件分類器相比,這種集成學習的方法在真實的金融欺詐數據上具有優越的性能。
關鍵詞:金融反欺詐;集成學習;機器學習
中圖分類號:TP311 文獻標識碼:A
文章編號:1009-3044(2020)01-0216-04
1概述
隨著經濟的高速發展,金融在線交易也持續增加,隨之帶來了金融欺詐行為。相對于合法交易,欺詐交易的數量很少,但是我們每天數百萬計的巨大交易量中包含的欺詐交易會給銀行造成巨大的經濟損失。欺詐檢測涉及監視用戶群體的行為,以便估計、檢測或避免不合法行為。不合法行為是一個廣義術語,包括違法,欺詐,入侵和賬戶拖欠。機器學習技術用于數據分析和模式識別,因此可以在數據挖掘應用程序的開發中發揮關鍵作用。越來越多的研究人員也在使用機器學習來檢測欺詐行為。
在機器學習的有監督學習算法中,我們的目標是學習一個在各個方面都表現良好的穩定模型,但是實際情況通常并不理想,有時我們只能獲得具有偏好的單個弱模型。集成學習是在這里結合多個弱監督模型,以獲得更好,更全面的強監督模型。集成學習的潛在思想是,即使一個弱分類器得到錯誤的預測,其他弱分類器也可以糾正此錯誤。
Stacking是用于構造集成模型的常見集成學習方法。分類器集合是指一組分類器,其各個決策以某種方式組合在一起以對新實例進行分類。Stacking將多個分類器組合在一起,得到新的集成學習模型。基分類器通常會產生不同的分類錯誤。因此,集成模型成功學會了何時信任單個基分類器的結果來提高整體的性能。
在本文中,我們主要考慮了三個基分類器:隨機森林,XGBoost和卷積神經網絡(cNN)。然后我們提出了一種創新的集成學習方法,即基于邏輯組合的集成方法。為了展示該方法的性能,我們與傳統的機器學習方法做對比,我們的集成模型在檢測欺詐行為的F1-score和G-means兩項指標都優于傳統的機器學習分類器。
2研究現狀
目前,已經有學者提出了相關機器學習方法來克服這些挑戰。Kokkinakit61提出了決策樹和布爾邏輯函數來表征正常交易模式,以檢測欺詐性交易。但是,無法識別某些類似于合法交易模式的欺詐交易。因此,神經網絡和貝葉斯網絡”被提出。Ghosh使用神經網絡來檢測信用卡欺詐。貝葉斯信任網絡和人工神經網絡也已被引入以解決該問題。但是這些模型用于檢測欺詐行為過于復雜,并且極有可能過度擬合。為了揭示欺詐交易的潛在模式并避免模型過度擬合,Kang Fu使用卷積神經網絡有效地減少了特征冗余。
2.1CNN卷積神經網絡
因為CNN模型適合訓練大量數據,并且具有避免模型過度擬合的機制。卷積神經網絡已成功應用于某些領域,例如圖像分類和語音信號處理。但是,并非所有類型的數據都適用于CNN模型。針對這點,提出了特征變換的方法來適應CNN模型。信用卡交易的功能可以分為幾個組。每個組在不同的時間窗口具有不同的特征。不同時間窗口的相同特征類型的兩個特征具有很強的關聯性。因此,在特征矩陣中,這兩個特征設置在靠近的位置。原始特征是一維的,我們需要將它們重塑為特征矩陣,其中行代表不同的特征類型,列代表不同的時間窗口,如圖1。
2.2集成學習
Stacking是一種集成學習技術,其中將子模型集合的預測作為第二級學習算法的輸入。該第二級算法經過訓練,可以最佳地組合子模型來預測最終的預測集。許多機器學習從業者已經成功使用Stacking和相關集成學習技術來將預測準確性提高到任何單個模型都到達不了的水平。建模人員也已經成功地將Stacking其應用于各種問題,包括化學計量學,垃圾郵件過濾和從UCI機器學習存儲庫提取的大量數據集。Neff-lix Prize競賽是模型集成功能的最新杰出代表。約瑟夫·西爾(Joseph Sill)提出了特征加權線性Stacking(FWLS),與標準線性Stacking相比,其準確性顯著提高。
3組合式集成學習模型
3.1問題分析
集成學習方法(stacking)旨在通過混合來自多個機器學習模型的預測結果來提高模型的性能。來自每個單個模型的預測結果是元特征,這些元特征作為第二層分類器的輸入。但是僅考慮元特征是不夠的。數據本身的特征也很重要。在這里,我們提出一種組合方法,使用多個模型的組合來重建訓練數據。同時考慮了元特征和數據本身的特征。組合方式代表了不同模型之間的互補性。
3.2方法
表1顯示了我們所使用特征的詳細信息。所有這些特征都是從原始交易數據中提取的。我們使用3個最先進的分類器作為基本分類器:隨機森林,XGBoost和CNN卷積神經網絡。CNN卷積神經網絡使用圖1中特征矩陣作為模型的輸入,特征可以分為幾組。每個小組在不同的時間范圍內具有不同的功能:30分鐘,1小時,2小時,1天,3天,1周,2周和1個月。在訓練卷積神經網絡的過程中,所有原始交易特征都將轉換為9x9特征矩陣。
3.3集成模型
3.3.1離線訓練
3.3.2在線測試
如圖3所示,說明了我們系統的測試部分。我們使用預先訓練的分類器來生成交易類標簽。此標簽的值是1到18,表示組合的類型。然后,選擇器將通過這種組合類型選擇基本分類器。例如,一個交易的多類結果為10,如表2所示,我們將此交易放入c1,c2和C3(Ci代表第i個基分類器預測結果1,邏輯組合結果c1或c2或c3的值是最終的預測結果。
3.3.3重構訓練數據
在訓練的第二部分中,我們將交易數據重構為多個交易數據。對于每個重構的交易數據,我們保留其特征,但更改其標簽。交易數據的新標簽為ny(I<=ny<=18),表示三個基本分類器的第ny組合可以正確識別此交易數據。一個示例如圖4所示。
3.3.4調度優化
對于一個實時在線交易欺詐檢測系統,時延是一個非常重要的指標,為了降低系統運行時間,我們提出了一種調度優化方法。如圖5所示。選擇器同時維護三個進程隊列,隊列中的每一列代表同一條交易,數字1,2,3,...代表唯一的一條交易id,x代表當前基分類器沒有被選擇。一條新到來的交易數據無須等待上一條交易數據預測完成,因此,所有的交易都會被很快的發送給選擇器。不僅如此,基學習器c1,c2,c3也不需要等待別的基學習器完成預測。它們持續執行分類操作直到在它們的隊列中不再有新的交易數據傳入。
4實驗結果
我們的實驗基于真實的交易數據。我們在基分類器和集成分類器之間進行了對比實驗。
4.1數據集
為了評估所提出的方法,我們使用了來自某銀行的真實在線交易數據。所有交易于2017年4月至6月進行。如表3所示。
4.2評價指標
我們主要采用打擾率、召回率、F1-Score和G-mean作為欺詐檢測效果的評價指標。表4為混淆矩陣,代表分類正確和分類錯誤的交易,通過混淆矩陣,我們給出了打擾率、召回率、F1-Score以及G-mean的計算公式。
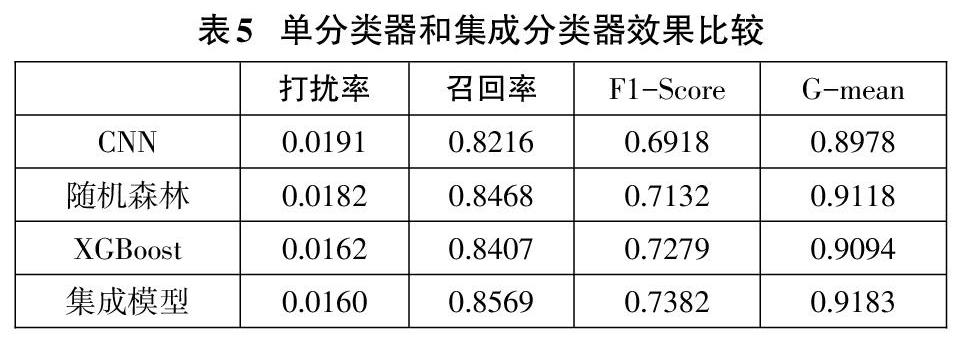
我們使用訓練集訓練基分類器(隨機森林,XGBoost,CNN),然后將測試集分為兩部分,即測試集的前四分之三和后四分之一,并將基分類器測試結果作為集成模型訓練的基分類器。測試集的最后四分之一作為集成模型分類器的測試集。結果如表5所示,從結果來看,我們的集成學習模型優于所有當前的單獨分類器。在真實金融數據集上十分有效。
5結束語
本文介紹了一種新的基于集成學習的金融反欺詐模型,我們使用集成學習的方法,挖掘用戶行為關聯特征,設計和選擇子機器學習模型,使用更具有現實意義的線上方法構建欺詐檢測系統。我們主要創新在于利用多個模型融合的方法,并且綜合利用了原始數據的多元特征,實現面向數據各個特性的維度的融合。這種新穎的線上欺詐檢測方法具有很好應用價值與潛在經濟效益。
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
