改進MobileNetV2網絡在遙感影像場景分類中的應用
2020-04-01 01:00:36楊國亮李放朱晨許楠
遙感信息 2020年1期
關鍵詞:分類
楊國亮,李放,朱晨,許楠
(江西理工大學 電氣工程與自動化學院,江西 贛州 341000)
0 引言
遙感場景分類是根據遙感圖像的內容進行特征提取,使用分類器對抽象出來的特征進行分類,從而對遙感場景進行分類和識別的過程。精準而快速的場景分類可以降低如地理目標檢測、土地利用分析、土地覆蓋分析、城市規劃等遙感解譯任務的難度,并提高解譯精度。
傳統場景分類算法多數是基于人工特征提取的,這些算法依賴大量的專業知識以及專家經驗來設計針對不同任務的特征描述子,此種基于人工特征提取的場景分類方法難以取得較好的泛化效果。近年來,隨著卷積神經網絡的快速發展,遙感圖像場景分類的準確率和泛化能力得到了極大提升[1-2]。Krizhevsky等[3]于2012年憑借AlexNet取得了ImageNet大規模視覺識別挑戰賽圖像分類和目標定位任務的冠軍,展現了卷積神經網絡在圖像領域上的巨大潛力。在此之后,vgg-16[4]、GoogLeNet[5]、ResNet[6]等網絡的提出及發展[7-8]大大提高了分類任務的分類準確度的同時應用領域也逐漸多元[9-10]。但是這些網絡性能得到提高的同時也使得模型的深度與參數的數量快速增加,這會導致模型訓練困難,存儲空間占用大,訓練、預測時間長等問題,對于集成卷積網絡的方法更是如此。近年來,越來越多的研究都聚焦在了網絡模型的效率問題。2017年發表在ICLR上的利用fire module的SqueezeNet,同年發表在CVPR上的利用深度可分離卷積的MobileNet,以及之后發表的ShuffleNet[11]、Xception[12]和MobileNetv2[13],這些網絡在保持相似精度的同時大量縮減網絡參數數量,通過減少網絡的參數與計算量來解決網絡的效率問題。
本文在MobileNetv2的基礎上,結合了Densenet的密集連接思想,通過引入密集連接,調整瓶頸擴張系數等方式構建了一個新的改進網絡。新的網絡有效降低了網絡的參數量和計算量,網絡更加輕量和有效,同時具有與原始網絡相似的分類準確率。
1 MobileNetv2及DenseNet網絡概述
1.1 MobileNetv2
現代先進網絡需要的高計算資源遠遠超出了移動和嵌入式設備的能力。Mobilenetv2網絡[13]是針對此種限制設計出來的一種新型的網絡結構。該網絡可以在保持相似準確度的情況下有效減少網絡中的參數量與計算量。
MobileNetv2的主要貢獻來自Linear Bottlenecks和Inverted Residual block[13]。Linear Bottlenecks即去除網絡中輸出維度較小的層后的激活函數Relu,將其改為線性激活。這種改進降低了使用Relu函數造成的信息損失。Inverted Residual block的設計采用了先升維、后降維的結構,與傳統的Residual block先降維、后升維的結構相反,減少了信息的損失。同時網絡設計了擴張系數t以控制網絡的大小。MobileNetv2的瓶頸結構如圖1所示,其中每層的輸入與輸出如表1所示。表1中,k表示輸入通道數;h表示輸入的高;w表示輸入的寬;t表示擴張系數;s表示步長;k’表示輸出通道數。

圖1 MobileNetv2瓶頸圖(左圖步長為1,右圖步長為2)

表1 瓶頸各層的輸入輸出
1.2 DenseNet
DenseNet[14]的設計不同于ResNet,在一個Dense塊中,層的輸入為之前所有層輸出的拼接。對于殘差網絡來說,第l層的輸出等于第l-1層的輸出加上對l-1層的非線性變換,即:xl=Hl(xl-1)+xl-1;而對于Densenet來說,[x0,x1,…,xl-1]表示將第0層到第l-1層的輸出特征圖拼接,故此時第l層的輸出為xl=Hl([x0,x1,…,xl-1])。Dense塊結構[14]如圖2所示。

圖2 Dense block圖
這種設計提升了信息和梯度在網絡中的傳輸效率,Dense塊中的每層都能直接從損失函數獲得梯度信息,并且直接得到輸入信號。除此之外,這種網絡結構同時還具有正則化的效果,對于過擬合現象有一定的抑制作用。
2 網絡結構及設計思路
2.1 深度可分離卷積
對于目前很多高效的神經網絡結構來說,深度可分離卷積[12](depthwise separable convolution)都是非常重要的一個設計。在改進網絡中將繼續沿用這一設計。深度可分離卷積的設計思想是將一個標準卷積分成兩個部分,第一部分為深度卷積(depthwise convolutions),depthwise convolution將3×3的卷積核應用在每一個輸入通道上,產生與輸入通道數個數相同的結果;第二部分逐點卷積(pointwise convolutions)為普通的1×1卷積,它被用來將depthwise convolution的輸出進行線性組合。過程如圖3所示[12]。
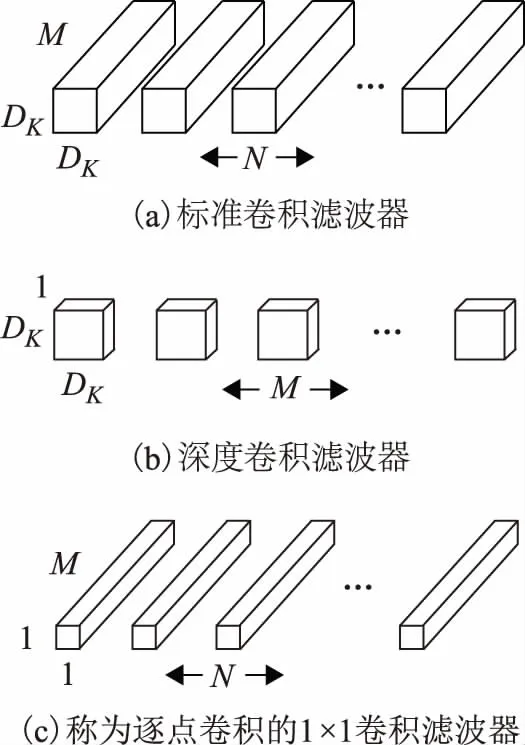
圖3 深度可分離卷積
深度可分離卷積的計算量與標準卷積計算量的比值如公式(1)所示。

(1)
式中:DK為卷積核的尺寸;M為輸入通道數;N為輸出通道數;DF為特征圖的大小。從公式中可以看出使用3×3大小的卷積核可以將計算量減小為標準卷積的九分之一。
2.2 瓶頸設計
在設計瓶頸的時候采用先升維后降維的策略并在降維后使用線性激活來避免激活函數Relu對信息的損失,與原網絡不同的是,本文去除了殘差連接,在輸出特征圖大小一致的瓶頸之間使用密集連接代替殘差,借助特征復用來提升信息和梯度在網絡中的傳輸效率,同時密集連接使用的是拼接而不是求和,這會造成瓶頸的輸出通道數的快速增加,從而導致網絡參數和計算量的增加。所以這里沒有和原始網絡一樣將擴張系數t設定為默認值6,而是對擴張系數進行了適當的調整,控制網絡的規模。擴張系數的調整范圍限制在1到6。在設計網絡時使用了擴張系數為1的瓶頸,但是在設計瓶頸的時候并沒有刪除最初的1×1卷積層,因為1×1卷積不僅可以提高網絡的表現能力,更重要的是1×1的卷積層可以將多個特征圖線性組合,從而實現了跨通道的信息整合。因為網絡引入了密集連接,所以認為初始的1×1卷積即使擴張系數為1也同樣對網絡性能的提高有著積極的作用。文中設計的瓶頸結構如圖4所示。

圖4 本文瓶頸
2.3 網絡整體結構
改進網絡的結構如圖5所示,圖中的c表示瓶頸的輸出通道數。

圖5 改進網絡的結構圖
本文采用了密集連接來代替原網絡中的殘差連接,使得梯度與信息可以在網絡中得到更好的傳遞。同時為了解決在多個輸出拼接作為下一個瓶頸的輸入時所產生的通道數過大的問題,在設計網絡的時候放棄了原網絡在多個輸出通道數相同的瓶頸堆疊,之后對下一個瓶頸的輸出通道數進行放大,最終使得網絡的通道數逐步增加。首先對輸出通道數進行縮小,之后堆疊數個步長為1的瓶頸,借助密集連接來對輸出通道數進行拼接,最終使得網絡的通道數得到放大的設計,此種設計可以有效減少網絡的參數量與計算量。同時,為了保證網絡的復雜度與表現力,使用了一個T=1,S=1的瓶頸和一個T=1,S=2的瓶頸的組合來完成輸出通道數縮小的過程,如圖5 bottleneck4和bottleneck5、bottleneck8和bottleneck9的使用。本文的網絡在網絡較深的位置僅使用一個步長為2的瓶頸進行通道數的縮減,主要原因是基于網絡參數與計算量的考慮,如bottleneck15的使用。同時,網絡在bottleneck13、bottleneck14、bottleneck17和bottleneck18的位置減小了擴張系數t,主要想法是這些瓶頸的輸入經過數次拼接,通道數已經增加到了一定程度。而拼接導致的通道數增加在一定程度上可以代替或者部分代替擴張系數對于通道數的擴張作用。每個瓶頸的輸入與輸出大小與表1中給出的值相同。擴張系數t的調整范圍為大于等于1、小于6的整數。
2.4 參數量與計算量分析
瓶頸的參數量計算方法見公式(2)。
P=t×Cin×Cin+9×t×Cin+t×Cin×Cout
(2)
式中:P表示參數量;t表示擴張系數;Cin表示輸入通道數;Cout表示輸出通道數。
瓶頸的計算量如公式(3)、公式(4)所示。公式(3)、公式(4)中采用的步長分別為1、2,其中h表示輸入的高;w表示輸入的寬;t表示擴張系數;Cin表示輸入通道數;Cout表示輸出通道數;s表示步長的大小。
M=h×w×Cin×(Cin+9+Cout)
(3)
(4)
文中設計的網絡結構所對應的參數和計算量見表2。改進網絡的參數個數共計2 852 496,較原網絡減少約16%,計算量減少了約13%。經過改進之后的網絡的計算量與參數量都取得了不錯的壓縮程度。參數與計算量的減少主要原因是因為步長為2的瓶頸的輸出通道是減小的而后通過多個瓶頸的輸出拼接使得之后瓶頸的輸入得以放大,此種操作會使得最初的幾個瓶頸的輸入通道數較少,即這些瓶頸內的參數與計算量也較少。而拼接本身并不會產生多余的參數與計算量。與此設計不同的是,在原始網絡中,步長為2的瓶頸會對通道數進行放大,再將這些輸出作為輸入傳入到下一個瓶頸時必然會產生更多的參數與計算量。

表2 網絡參數及計算量
3 實驗及分析
3.1 實驗環境及數據集
本文的實驗環境為Ubuntu14.04系統,Intel core i7-4790CPU,內存為8 GB,顯卡為GTX 1080 8 G GDDR5,搭配tensorflow-1.4.0,cuda8.0,cudnn6.5,使用的數據集為遙感圖像場景分類數據集NWPU-RESISC45[15]。該數據集是由西北工業大學(NWPU)創建的REmote傳感圖像場景分類(RESISC)的公開可用基準。該數據集包含31 500個圖像,涵蓋飛機場、棒球場等45個場景類,每個類有700個圖像,示例如圖6所示。

圖6 NWPU-RESISC45示例圖
首先將數據集圖片大小統一為224×224。本文實驗均未使用預訓練參數,為避免訓練集圖像過少造成的不利影響,尤其是參數較多的大型網絡,故從每一類場景中隨機抽取500張作為訓練集,即訓練集的數目為500×45;剩余的作為測試集,數目為200×45。在訓練之前,對數據集進行數據增強。對每張訓練集圖片進行2次隨機旋轉、1次左右翻轉、3次隨機亮度處理、3次隨機對比度處理,使得數據集更加多樣。最終的數據集規模為5 000×45張圖片,預處理效果見圖7。為了驗證原始和旋轉等操作后的測試圖片分類效果,對于測試集的每張圖片進行了1次隨機旋轉、1次左右翻轉、2次隨機亮度處理和2次隨機對比度處理,最終測試集規模為1 400×45張圖片。

圖7 訓練集預處理(左上角的圖像為原始圖像)
3.2 網絡的訓練與分析
為了說明改進網絡的有效性來自網絡設計而不是超參數調整或者訓練策略的不同,在訓練2種網絡時采用一致的設定。在訓練MobileNetv2和改進網絡時設定每個批(batch)包含32張圖片。在訓練的過程中,使用了RMSprop優化方法來加速訓練,訓練開始時設置的初始學習率為0.045,訓練的過程中使用tensorboard對loss值進行可視化監控,當損失下降困難時,暫停訓練并且調低學習率的大小。在本次實驗中學習率下降了3次,分別下降為0.022 5、0.012 5、0.005。隨著學習率的下降,loss值會繼續減小,說明調低學習率的做法的確對于網絡的訓練可以起到積極作用。在實驗結束后,使用tensorboard對遙感場景的分類準確率、召回率和訓練過程中的loss值變化曲線進行可視化顯示,方便對2種網絡進行對比。在訓練的過程中,原始網絡完成一步訓練的時間大約為0.350 s,而改進網絡完成一步訓練只需要大約0.250 s,完成每步訓練的時間縮短了大約28%,改進的網絡在縮短訓練時長方面有著較好的效果。
圖8為訓練過程中的loss值曲線。從圖8可以看出2條loss曲線差別不大,在訓練之初原始網絡loss值下降速度略快于改進網絡,而后二者的loss值基本相近,原始網絡稍低于改進網絡,這說明在對原始網絡的規模進行縮減時并沒有使網絡的訓練變得困難。

圖8 Loss值(smooth=0.6)
為了更好地說明問題,本文使用相同的訓練策略和數據集訓練了幾種應用廣泛的網絡結構。使用這些網絡對測試集的圖片進行評估,測試時批的大小設置為50,測試集共計63 000張圖片,即1 260個批。
圖9為網絡在測試集準確率變化曲線。從圖9可以看出在訓練的過程中改進網絡和原始MobileNetv2網絡在遙感圖像場景分類任務上有著較高的準確率,訓練結束時本文網絡的準確率為92.54%,MobileNetv2為93.49%,二者相差不足1%。Inceptionv3為91.44%,Res50為89.60%,而在ImageNet大規模數據集上表現出色的Inceptionv4網絡在遙感圖像場景分類數據集上的表現不夠理想,準確率為84.9%。實驗結果顯示Inceptionv4網絡不適合遙感圖像的場景分類任務。
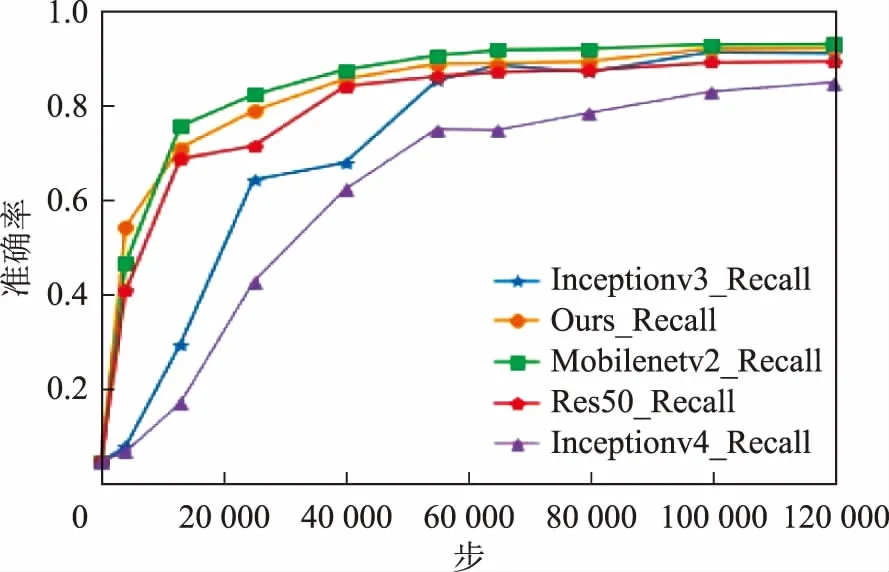
圖9 測試集準確率
圖10為召回率變化曲線。可以看出,5種網絡在召回率方面都有不錯的效果,除了Inceptionv4的96.65%和res50的97.96%以外,其余網絡的召回率都可以達到99%以上。幾種網絡的詳細對比見表3。

圖10 測試集召回率

表3 幾種網絡性能的對比
結合圖9、圖10和表3的實驗結果綜合分析這5種網絡在遙感圖像分類任務上的表現。Inceptionv4網絡的場景分類效果是這5種網絡中最差的一個,不足85%的場景分類準確率說明此網絡并不適合遙感圖像場景分類任務。Inceptionv3雖然可以達到91%的分類精度,但是在訓練次數較少時準確率大幅低于剩下的3個網絡,而且Inceptionv3的參數量也更多。Res50的各項結果均不如改進網絡和MobileNetv2。在改進網絡與原MobileNetv2的對比中,改進網絡參數量減少了55萬,計算量減少了3 800萬,完成一步訓練的耗時減少了28%左右,完成一次測試集評估用時減少了20%左右,分類準確率只下降了0.9%,召回率下降了0.3%,改進網絡在基本保持了遙感圖像場景分類任務的分類準確率的同時,減少了網絡的參數量和計算量,提高了網絡的訓練速度與預測評估速度。網絡較原始MobileNetv2更加輕量高效,在遙感圖像場景分類任務上取得了較好的效果,網絡瓶頸的輸出特征圖的部分顯示如圖11所示。測試集中每個分類的準確度如圖12所示。根據圖12可以看出在絕大多數的情況下網絡有著不錯的性能。

注:最左側為第一個卷積層的特征圖,從左至右分別對應文中圖5所示結構的瓶頸1至瓶頸18。特征圖尺寸對應文中表2輸出所示。圖11 網絡部分特征圖

圖12 每個分類的準確率
4 結束語
為了可以使用卷積神經網絡對遙感場景圖像進行分類時既保證分類準確率又減小網絡的參數量與計算量,使得網絡輕量高效,將DenseNet中的密集連接引入到MobileNetv2中,借助特征圖的復用提高網絡性能。利用一個擴張系數為1,步長為1的瓶頸與一個擴張系數為1,步長為2的瓶頸的組合壓縮特征圖的通道數。并將部分瓶頸的擴張系數減小以控制網絡的整體規模。最后,在遙感圖像場景分類數據集NWPU-RESISC45上進行實驗。實驗結果表明,改進的網絡在基本保持場景分類精度的同時,完成每步訓練的時間、前饋計算消耗時長、網絡參數數量、網絡計算量都得到了一定程度的減小,說明了模型對于遙感圖像場景分類任務的可行性與實用性。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
