改進YOLOv3在航拍目標檢測中的應用
2020-04-07 10:48:24魏瑋,蒲瑋,劉依
計算機工程與應用 2020年7期
魏 瑋,蒲 瑋,劉 依
河北工業大學 人工智能與數據科學學院,天津300401
1 引言
航拍目標檢測在車輛檢測、遠程目標追蹤、無人駕駛等領域有著十分重要的應用[1]。隨著計算機視覺、人工智能技術的迅速發展,在眾多的目標檢測算法中,基于深度學習的方法因其無需特征工程,適應性強,易于轉換等特點得到了較為廣泛的應用[2]。目前通過深度學習來解決目標檢測問題的方法主要有兩種:兩階段(two-stage)檢測模型與單階段(one-stage)檢測模型[3]。兩階段模型因其對圖片的兩階段處理過程得名,也稱為基于區域的檢測方法,主要包括R-CNN[4]、Fast R-CNN[5]、Faster R-CNN[6]、R-FCN[7]等。兩階段方法的檢測精度雖然很高,但耗時過長,難以達到實時檢測的效果。為了平衡檢測速度與精度,單階段檢測模型被提出。拋棄了粗檢測與精檢測結合的思想,經過單個階段的檢測即可直接得到最終檢測結果,因此有著更快的檢測速度。單階段檢測方法也稱為基于回歸的方法,無需區域提取過程,直接從圖片獲得預測結果,實現了端到端的目標檢測。主要包括YOLO[8]、SSD[9]、YOLOv2[10]、YOLOv3[11]等系列方法。
目前來看,YOLOv3方法維持了檢測速度與精度間的較好平衡。國內外很多研究學者將其應用到目標檢測領域,并針對具體問題提出了不同的改進方案。Benjdira 等[12]使用航拍汽車數據集對YOLOv3 和FasterRCNN 進行對比,證明了在精度相當的情況下,YOLOv3在靈敏度和處理時間上均優于FasterR-CNN 算法。Kharchenko 等[13]將YOLOv3 算法應用到無人機或衛星拍攝圖像的地面目標檢測問題中,實現了較高的檢測能力和實時檢測速度。李耀龍等[14]將簡化的Tiny-YOLO[15]算法應用到飛機目標檢測中,提高了檢測速度。戴偉聰等[16]將YOLOv3算法應用于遙感圖像中的飛機檢測,加入密集相連模塊,并結合多尺度特征檢測,提高了飛機檢測的精度和召回率。
本文將YOLOv3 算法應用于無人機航拍圖像的目標檢測領域,為提高算法的適用性和準確性,對YOLOv3算法進行改進。使用K-Means[17]方法對航拍數據集標簽進行維度聚類,計算最優的寬高值并由此對YOLOv3中的anchor 進行修改。針對航拍數據集中檢測目標大小不一,以及小目標分布過于密集的情況,對YOLOv3 算法的網絡結構進行改進,在保證檢測速度的前提下,使算法的檢測精度得到了較大提升,加快收斂速度并減少了參數計算量。
2 YOLOv3算法
YOLOv3 算法是Redmon 等于2018 年在YOLOv2的基礎上提出的,使用全卷積網絡(Fully Convolutional Network,FCN)[18],結合了殘差網絡ResNet[19]中的跳躍連接和特征金字塔網絡(Feature Pyramid Networks,FPN)[20]等算法思想,用步幅為2的卷積層替代池化層完成對特征圖的下采樣,同時在每個卷積層后增加批量歸一化操作(Batch Normalization,BN)[21]并使用激活函數LeakyRelu[22]來避免梯度消失及過擬合,通過殘差結構加深網絡層數,形成了53層的骨干網絡DarkNet-53。針對YOLOv2中由于下采樣造成的細粒度特征丟失問題,仿照FPN設計了多尺度預測網絡,采用3個不同尺度的特征圖來進行位置與類別預測,有效提高了目標檢測的準確率。YOLOv3的網絡結構如圖1所示。
首先,YOLOv3將輸入圖像縮放至416×416,把圖像劃分為S×S 個網格。每個網格負責預測中心落入該網格的目標,并計算出3個預測框。每個預測框對應5+C個值,C 表示數據集中的類別總數,5 代表預測邊界框的屬性信息:中心點坐標(x,y)、框的寬高尺寸(w,h)和置信度(confidence)。網格預測的類別置信度得分為:
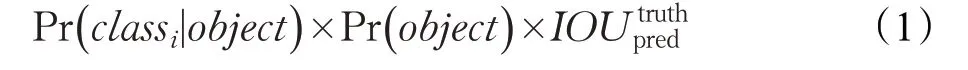
其中,若有目標中心落入該網格,則Pr( obj ect )=1,否則Pr( obj ect )=0。Pr( cla ssi|object )為網格預測第i 類目標的置信概率。IOU truthpred 為預測邊界框與真實框的交并比(Intersection Over Union,IOU)[23]。
最后,使用非極大值抑制(Non-Maximum Suppression,NMS)[23]算法篩選出置信得分較高的預測框,即為檢測框。
在損失函數中,YOLOv3算法將方差損失改為交叉熵損失。在置信度和類別預測中,考慮到某一目標可能屬于多個類別,YOLOv3 對檢測目標執行多標記分類,舍棄softmax 分類方法,采用多個獨立的邏輯分類器來預測類別分數,并設置閾值預測目標的多個標簽。
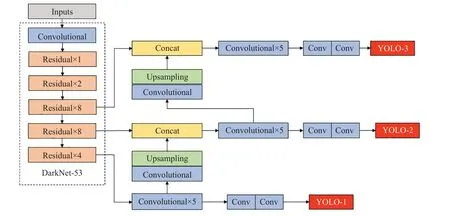
圖1 YOLOv3網絡結構
YOLOv3與其他常用目標檢測框架效果對比如表1所示,可以看出YOLOv3能夠在檢測精度和速度上取得較好的平衡。
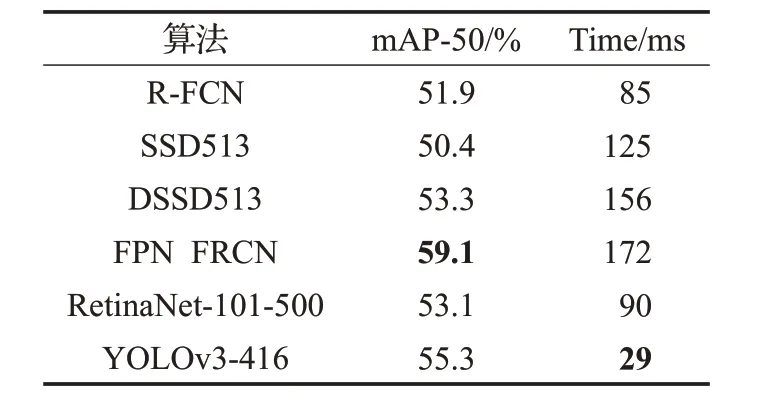
表1 YOLOv3與其他框架效果對比
3 改進YOLOv3算法
YOLOv3 算法在MSCOCO、PASCAL VOC 等數據集上表現良好,但本文所使用的航拍數據集,實例種類眾多,且實例間的分布十分密集,這給檢測任務帶來了較大挑戰。因此要針對航拍數據集進行目標檢測任務,就需要對YOLOv3 算法做出相應改進,以適應特定的需求。
3.1 對錨點進行參數優化
受Faster R-CNN 算法中提出的錨點機制啟發,YOLOv3 算法中也引入了anchor 機制。早期的anchor值由經驗確定,而Redmon 在YOLO 系列算法中提出使用K-Means 聚類方法來獲取anchor 值。在目標檢測任務中,合適的anchor取值能夠提高檢測任務的精度與速度。YOLOv3 算法中使用的anchor 是根據COCO 和VOC數據集訓練所得,這9組anchor值分別是(10,13)、(16,30)、(33,23)、(30,61)、(62,45)、(59,119)、(116,90),(156,198),(373,326)。但如圖2 所示,對于本文使用的航拍數據集來說,COCO 與VOC 數據集中的實例尺寸過大,對應anchor值也偏大,不適用于本數據集,因此需要重新進行維度聚類,選取合適的anchor 參數,對航拍數據集進行更好的預測。
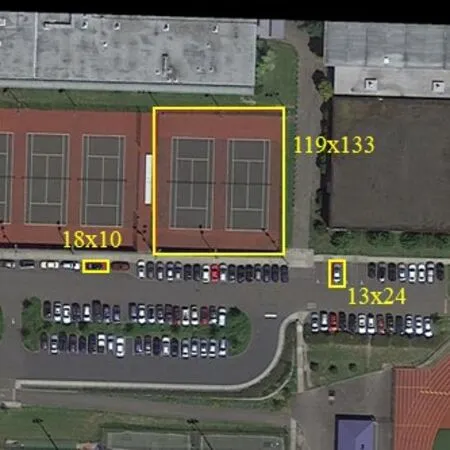
圖2 目標檢測框的尺寸
考慮到在目標檢測任務中,聚類的目的是使先驗框(anchor box)與正確標注(ground truth)的IOU 值盡量大,因此距離度量的目標函數不使用歐氏距離,而是采用IOU作為衡量標準,度量函數的公式如下:
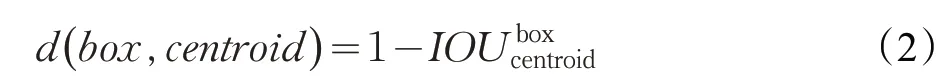
其中,box 為樣本標簽的目標框,centroid 為聚類中心。IOU 越大,距離越小。
按照上述方法,在航拍數據集中使用K-Means 算法重新對實例的標簽信息進行聚類分析,得到的9 組anchor值為:(10,14)、(26,13)、(21,26)、(51,34)、(31,58)、(63,190)、(76,77)、(148,128)、(275,282)。將這些anchor 按照面積從小到大的順序分配給3 種尺度的特征圖,尺度較大的特征圖使用較小的anchor 框,每個網格需計算3個預測框。
預測時采用直接預測相對位置的方法,如圖3 所示,公式如下:

其中,cx和cy表示的是每個網格的左上角坐標。pw和ph表示anchor映射到特征圖中的寬高值。tx、ty、tw、th是網絡需要學習的目標。
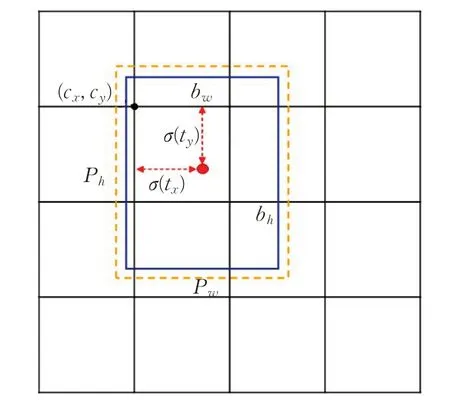
圖3 邊框預測
3.2 網絡結構改進
3.2.1 DarkNet-53網絡
YOLOv3 中使用的特征提取網絡是DarkNet-53,網絡結構如圖4所示。該網絡在DarkNet-19的基礎上,融合了ResNet 殘差網絡跳躍連接的思想,去掉池化層和全連接層,使用卷積層完成池化和上采樣操作。Dark-Net-53 中主要用到的是大小為3×3 與1×1 的卷積核,其中3×3卷積核主要負責增加通道數,而1×1卷積核用于壓縮3×3 卷積后的特征表示,加深網絡深度的同時,提高了網絡的性能。
3.2.2 改進YOLOv3
在DarkNet-53 中,雖然加深網絡深度使特征提取能力得到了提高,但過多的下采樣及卷積操作會出現較小實例特征消失的情況。此外對于航拍數據集來說,實例間的尺寸大小相差懸殊,難以平衡檢測精度與特征大小。針對上述問題,增大圖像輸入尺寸,減少卷積層數并加入跳躍連接,降低小目標漏檢率,并提高不同尺寸實例的檢測精度。改進YOLOv3 網絡結構如圖5(a)所示。
圖4 DarkNet-53網絡結構圖
首先修改輸入圖像的尺寸,將原尺寸為416×416的三通道輸入圖像增大至608×608,確保多次下采樣操作后,較小尺寸的實例不會出現特征消失的情況,降低復雜場景下小目標的漏檢率。然后使用修改的DarkNet-53作為特征提取網絡,經過5 次下采樣后,特征圖大小依次變為304×304、152×152、76×76、38×38、19×19。沿用特征金字塔的思想,分別使用3個尺度的特征圖進行預測,即先對74 層處19×19 的特征圖進行處理后,送入檢測較大尺度的YOLO層,同時將該尺度特征圖上采樣后與61層處38×38的特征圖進行拼接操作,送入檢測中間尺度的YOLO 層。最后對當前尺度的特征圖進行上采樣,與36層處76×76的特征圖拼接后送入檢測小尺度的YOLO 層。多尺度特征檢測能夠較好的平衡不同尺寸實例的檢測情況。其中,如圖5(b)所示,在每個YOLO層進行位置和類別預測之前,減少相連卷積層數量,使用3×3與1×1的卷積進行特征維度轉換,并引入殘差網絡跳躍連接的思想進行連接,緩解隨網絡層數加深而引起的效果退化問題。
4 實驗與分析
4.1 數據預處理
本文使用的航拍圖像數據主要來源于DOTA[24]數據集,包含15 類目標:飛機、船只、儲蓄罐、棒球場、網球場、籃球場、田徑場、海港、橋、大型車輛、小型車輛、直升飛機、英式足球場、環形路線和游泳池。
本文實驗的數據預處理過程主要包括兩個部分:圖像預處理與標簽格式轉換。
航拍圖像的尺寸很大,通常在800×800~4 000×4 000 像素之間,基于卷積神經網絡的特征提取網絡無法直接使用,因此將原始圖像統一按照512的步幅裁剪為1 024×1 024 大小。考慮到裁剪過程中目標可能會被切分成兩部分,故對切分后的目標與原目標求面積比,比值小于0.8 的部分定義為新目標。裁剪處理后共計12 260 張圖像,其中8 582 張作為訓練集,3 678 張作為測試集。訓練集中各類別目標的圖像數量分布如圖6所示。
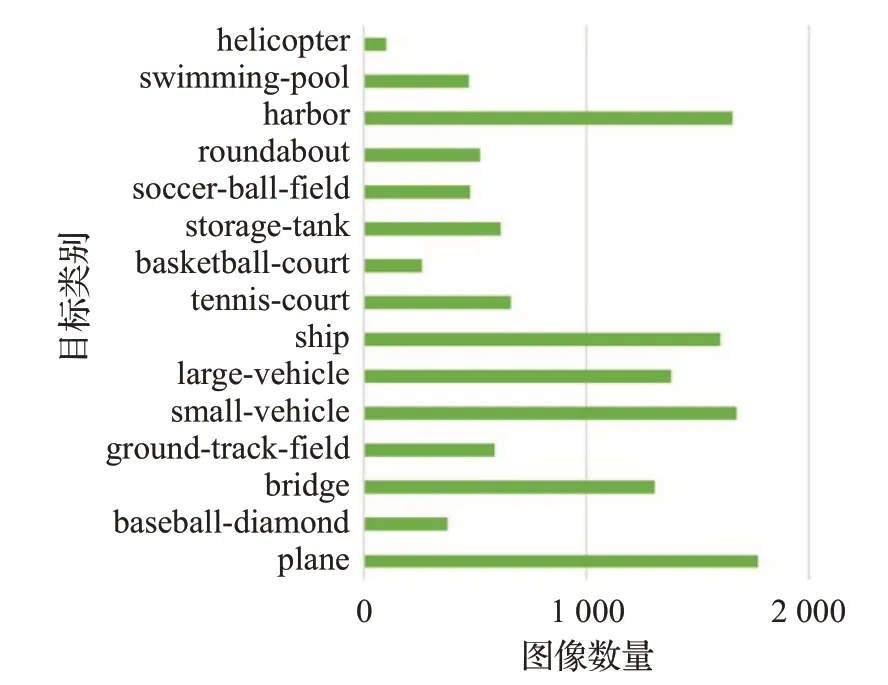
圖6 訓練集中各類別目標圖像的數量
DOTA數據集中使用的是任意四邊形邊界框,標簽為順時針排列的邊界框的四個頂點坐標。但本文改進YOLOv3 方法需要的數據標簽格式為x、y、width、height,其中x、y 為原任意四邊形的外接矩形邊界框的中心點坐標,width、height 為此邊界框的長和寬。因此對原數據格式進行如下變換:

其中,xmax、xmin分別為x 坐標中的最大、最小值,ymax、ymin分別為y 坐標中的最大、最小值。使用時需要對這4個值進行歸一化處理。
4.2 網絡訓練
本文使用DOTA數據集的航拍圖像進行訓練。實驗基于Pytorch 深度學習框架,使用方法為改進YOLOv3算法,訓練與測試均在NVIDIA 1070Ti 顯卡、CUDA9.0上進行。經實驗驗證,在此數據集上使用遷移學習進行訓練的效果較差,因此使用YOLOv3的官方權重作為網絡訓練初始化參數。本文改進方法的部分實驗參數設置如表2所示。
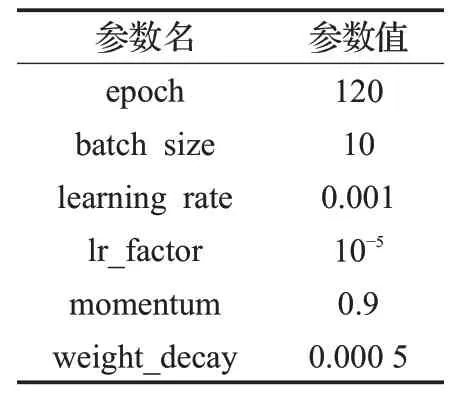
表2 部分實驗參數
4.3 實驗結果及分析
隨著訓練epoch數量的增加,對比的loss曲線如圖7所示,橙色線條代表原算法曲線,藍色線條為本文改進方法曲線。橫坐標表示訓練輪數,縱坐標為訓練過程中的loss值,其中,loss值為坐標損失、邊界框長寬損失、置信度損失和類別損失值的總和。

圖7 loss曲線
由圖7 可以看出,原算法的初始損失值較大,約為7.86,而改進算法的初始損失函數值較小,在3.24 左右。前期二者的損失值均下降較快,隨著訓練輪數的增加,loss 曲線逐漸降低,趨于平穩。當epoch 達到120 左右時,改進方法的損失值在前幾個epoch 就已經降至1以下,最終穩定在0.294左右,而原算法的值約為0.536。可以明顯看出,相比原算法,改進方法的效果更佳,顯著提高了收斂速度并降低了損失值。
圖8 為120 輪左右的mAP 和F1,其中橙色線代表YOLOv3 算法的效果,藍色線表示本文的改進算法。YOLOv3 的mAP 在51%左右,而本文改進算法的mAP可達65%左右。因此相比原方法,本文改進方法在檢測精度及檢測效果方面均得到了較大提升。
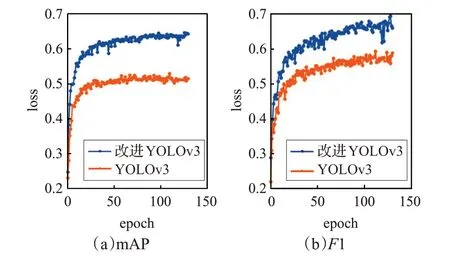
圖8 實驗結果圖
表3為使用本文改進YOLOv3算法時,測試集中各類別目標的mAP與F1 值,其中過長的類別名稱用單詞首字母簡寫表示。表3顯示,本文改進方法在航拍數據集上的mAP 可達65.5%,F1 為0.257。其中尺寸較大、分布稀疏的目標,如網球場(tennis-court)、飛機(plane)的檢測效果較好。而尺寸較小且分布過于密集的實例,如船只(ship)的檢測效果仍相對較低。

表3 本文算法檢測效果
圖9 為算法改進前后的檢測效果對比圖。使用同一組測試圖片,第一行使用的是YOLOv3 算法,第二行是本文改進方法。可以看出,圖9(a)組圖片中,改進方法比原算法多檢測出了外圈環形跑道。圖9(b)組圖片中目標尺寸較大且分布稀疏,YOLOv3 只檢測出了2個港口harbor,而本文改進方法檢測出了4個,其中較小的目標船只(ship)也沒有發生漏檢情況。圖9(c)組圖片,由于圖中的目標主要是尺寸較小且分布過于密集的船只,因此檢測效果相對來說都不是很好。YOLOv3方法檢測出98 個船只和11 個港口,改進方法檢測出112 個船只和11 個港口,在圖片右下角的位置密集分布了很多尺寸更小的實例,原算法沒有檢測出任何目標,但本文的改進方法檢測出了部分船只。
使用SSD、Faster R-CNN、YOLOv3、Tiny-YOLOv3以及本文改進算法進行對比,結果如表4所示。
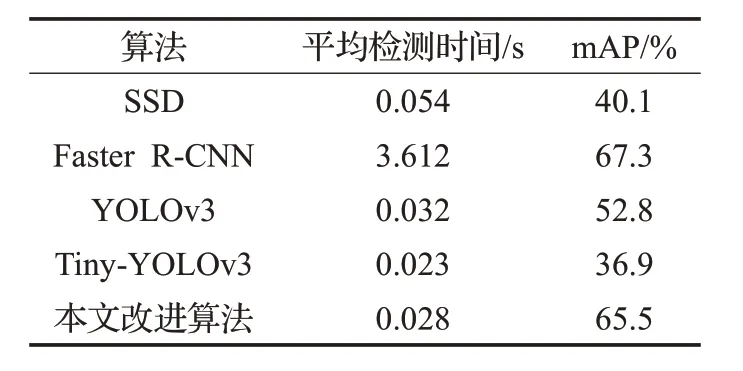
表4 不同算法檢測結果對比
由圖9和表4可見,改進的YOLOv3算法與原YOLOv3相比,平均檢測時間減少了37 ms,mAP提高了12.7%,且在一定程度上緩解了小目標的漏檢情況。Tiny-YOLOv3算法的檢測速度較快,但精度很差。YOLOv3的檢測準確率比Faster R-CNN 稍差,但檢測速度約為其129 倍。而SSD 算法無論在檢測精度還是檢測速度上都較差。因此,本文改進的YOLOv3算法在實時性及檢測精度上達到了較好的平衡,效果更佳。
5 結束語
本文將YOLOv3 算法應用到航拍圖像的目標檢測中,針對航拍圖像中目標尺寸大小不一且分布不均的問題,使用K-Means 聚類方法優化參數,并提出了改進YOLOv3 算法,在保證實時檢測速度的前提下,提高了航拍圖像的目標檢測效果。改進方法比原方法的mAP提高了12.7%,在加快了收斂速度并降低了漏檢率的同時提高了檢測準確性。
由于本文改進方法對航拍圖像中尺寸較小、分布過于密集的目標仍存在檢測上的局限性,因此下一步將結合旋轉邊界框的思路進行進一步的深入研究。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
