Spark環境下基于子圖的異步迭代更新方法
2020-04-07 10:48:40董新華陳建峽
計算機工程與應用 2020年7期
李 超,董新華,陳建峽
湖北工業大學 計算機學院,武漢430068
1 引言
隨著信息時代的快速發展,基于圖的迭代算法有著廣泛應用[1]。例如,PageRank算法可以對網頁的重要性進行排序,SimRank算法可以對社交網絡中用戶之間的相似度進行分析。由于真實網絡的數據規模較大,通常采取分布式框架對圖數據進行迭代處理,基于全局同步更新機制[2](BSP)的圖處理系統由于實現簡單且易于擴展,為大規模圖數據的分析提供了便利。
受全局同步更新機制的啟發[3],Spark 環境下的Graphx[4]圖處理系統基于子圖對數據進行全局同步迭代更新。通過彈性分布式數據集以分區方式存放頂點和連接邊屬性,Graphx可以利用頂點的局部狀態更新頂點的全局狀態,并且在迭代過程中將中間計算結果放入內存,以此避免頻繁地I/O 訪問。但是,由于Graphx 要求子圖之間的計算任務保持全局同步,因此降低了圖的收斂速度。
針對全局同步機制收斂速度較慢的問題,研究人員提出了異步迭代更新方法[5],Zhang[6]闡述了異步迭代收斂需要滿足的條件。當迭代算法滿足該條件時,頂點的狀態更新能夠繞開同步路障。雖然異步迭代提高了算法的收斂速度,但是以頂點為中心的異步迭代需要鄰居節點頻繁跨連接邊發送消息[7-8],當鄰居節點狀態的變化對頂點狀態更新的作用不大時,會降低網絡的通信效率[9]。
為了解決圖迭代收斂速度較慢以及通信效率較低的問題,本文在Spark 環境下提出一種基于子圖的異步迭代更新方法,總體研究思路如下:首先,對圖的切分、全局同步和異步迭代更新等概念進行簡要介紹;其次,結合Spark 環境下圖數據存儲和更新的特點,推導出基于子圖的異步迭代更新條件,分別從異步消息通信和迭代更新機制等方面給出具體的研究方案,在此基礎上給出研究方案在分布式環境下的具體實現;最后,通過PageRank 算法分別從圖的收斂結果、收斂速度和通信代價等方面驗證了方法有效性,并對實驗結果進行分析。實驗結果表明,本文方法不僅能夠提高算法收斂速度,同時還能降低通信開銷。
2 相關概念
2.1 圖切分
圖數據有較強的關聯性,因此圖的切分對數據的迭代更新有較大影響[10-11]。將圖1中頂點E 切分成4部分后,邊分區可以存放連接邊的完整屬性和頂點的局部狀態,點分區可以存放頂點的全局狀態,計算節點分別對邊分區中頂點的局部狀態和點分區中頂點的全局狀態進行迭代處理。
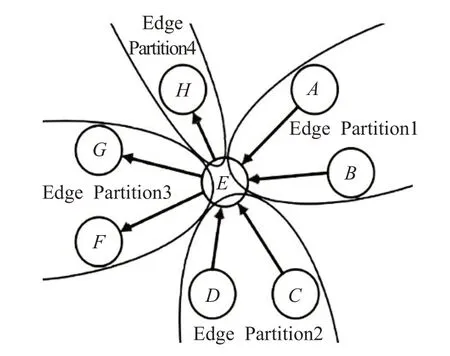
圖1 有向圖的點切分方法
在圖迭代過程中,連接邊上的頂點需要頻繁交互信息。由于圖1中邊分區存放了連接邊兩端的頂點,因此連接邊上的頂點可以直接在本地交互信息。對于連接邊數量多于頂點數量的真實網絡來說,這種切分方式可以顯著減少頂點通過連接邊跨分區發送消息的次數[11]。
2.2 全局同步更新
圖的狀態迭代更新可以用公式(1)描述:

公式(1)表明目的節點j 在第k 輪的狀態值根據連接邊上的源節點在第k-1 輪的狀態值計算得到。
在全局同步機制下,頂點的全局狀態依賴于所有邊分區內頂點的局部狀態。當所有邊分區頂點的局部狀態全部計算完畢,頂點的全局狀態更新才能開始。異構環境下如果連接邊分布在多個不同的邊分區,那么本地計算耗時最長的邊分區將直接影響下一輪迭代開始的時間。
2.3 異步更新
為提高算法收斂速度,Zhang[6]認為對公式(1)作適當變形后,可以得到公式(2):
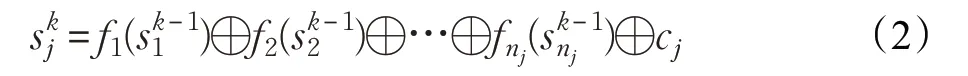
公式(2)表明目的節點j 在第k 輪的狀態可以通過nj個源節點在第k-1 輪的狀態計算得到。如果只考慮源節點在第k 輪與第k-1 輪的狀態變化值,令,那么公式(2)可變為公式(3):
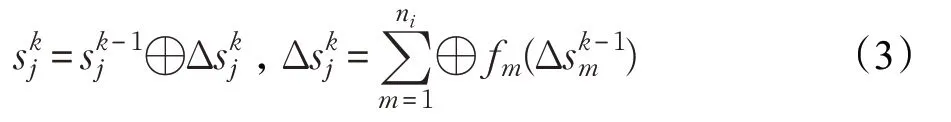
公式(2)和公式(3)表明異步更新能夠減少圖的收斂時間,但是分布式環境下圖的迭代對異步更新條件、消息通信和更新機制有著不同的要求,需要根據實際情況加以具體分析。本文首先給出Spark環境下基于子圖的異步迭代形式,在此基礎上給出消息通信模型和異步處理機制。
3 研究方案
3.1 基于子圖的異步迭代
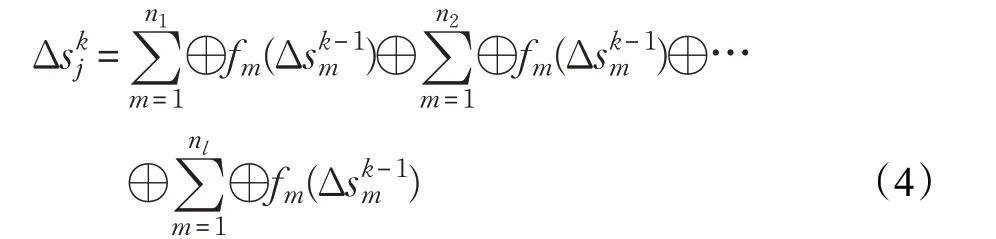
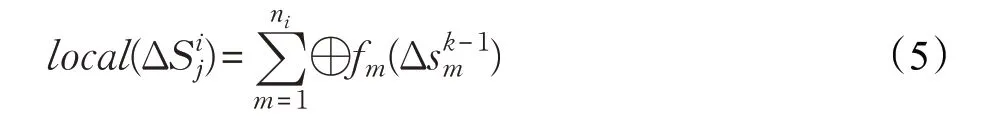
式中的⊕算子定義為局部算子,將公式(5)帶入公式(4),可以得到公式(6):

式中的⊕算子定義為全局算子,公式(6)表明頂點的全局狀態改變值可以根據不同邊分區的局部改變值進行更新。由于不同分區的本地計算任務互不影響,因此全局算子滿足交換律。在函數fm作用下,如果局部算子也滿足交換律和分配律,那么頂點收到任一局部狀態變化值,就能立即更新頂點的全局狀態。
3.2 消息通信
分布式圖處理系統主要采取消息傳遞[12]和共享內存的通信方式。基于共享內存通信的分布式圖處理系統一般采取分布式鎖保證數據的一致性。由于分布式環境下的計算節點有獨立的內存地址,共享內存的通信方式實現起來較為困難。基于消息傳遞的通信方式在計算節點之間發送消息,目前主要有基于Netty 的通信協議[13]、消息傳遞接口協議[14]和遠程過程調用協議。
根據Spark 環境下頂點狀態更新的特點,本文采取遠程過程調用協議實現分區數據集之間的異步消息通信,將每個分區數據集看作基于Actor 模型[15]的通信實體。另外,遠程過程調用不僅能夠實現異步消息通信,底層通信協議還支持數據塊傳輸。由于頂點的局部狀態值分布在不同的邊分區,而頂點唯一的全局狀態值存放在點分區,邊分區m 與點分區n 之間存在交集。當邊分區在本地獲取本地目的節點的局部匯聚值之后,可以將本地局部匯聚的結果以數據塊Blockm->n(local(ΔSID))的形式發送給頂點所在的點分區,數據塊中頂點ID 滿足式(7):

與頂點為中心的消息發送方式相比,以數據塊為單位將計算結果集中發給點分區,不僅可以批量處理數據塊,同時還能提高通信效率。
3.3 更新機制
當點分區收到數據塊之后,為避免頂點狀態在異步更新過程中產生數據讀寫沖突,本文創建數據塊緩存隊列以及線程池,在頂點狀態表上設置讀寫鎖,保證頂點狀態在異步更新過程中的一致性。
圖2中,線程池分別執行數據塊的接收(receive)、更新(update)和發送(send)任務。receive線程將收到的數據塊放入緩存隊列,update線程從緩存隊列中取出數據塊進行處理,將數據塊中頂點的局部狀態變化delta 寫進狀態表(state table),同時更新頂點的全局狀態。如果更新后的頂點作為源節點指向其他目的節點,則將最新的狀態變化值發送給該點作為源節點的邊分區,以更新其指向的目的節點。另外,update線程通過設定發送閾值,將滿足條件的狀態變化值放入待發送數據塊,當數據塊達到一定規模后喚醒send 線程,由send 線程將數據塊發給邊分區,以更新邊分區中源節點的狀態。當點分區內頂點全局狀態變化值小于閾值時,終止迭代過程。
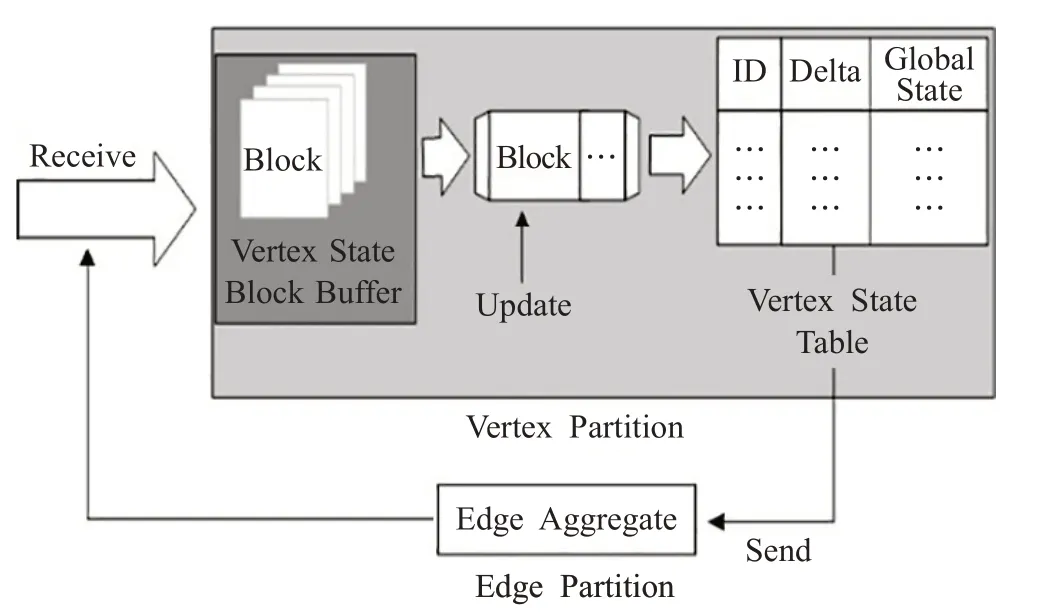
圖2 點分區和邊分區之間異步迭代更新機制
4 方法實現
4.1 PageRank定義
本文以PageRank[16]算法驗證基于子圖的異步迭代更新方法,PageRank的迭代計算公式為:

4.2 PageRank的異步迭代形式
Spark 環境下邊分區以三元組((srcId,srcAttr),(dstId,dstAttr),attr)的格式存儲本地連接邊的狀態值,其中srcId、dstId 是連接邊上源節點的ID 和目的節點的ID,srcAttr 是源節點在分區內當前的狀態值,dstAttr 是目的節點的狀態值,attr是連接邊完整的屬性值,取決于源節點的出度數。
根據圖數據的特點,在連接邊上定義map 函數和reduce函數,頂點的局部狀態可以直接利用數據的本地性計算獲取。與傳統的MapReduce 分布式計算模型[12]不同,由于采用彈性分布式數據集存放圖數據,Spark環境下通過map 函數和reduce 函數實現的消息映射和匯聚結果不需要頻繁寫入外存,每條連接邊上的Map函數定義如下:
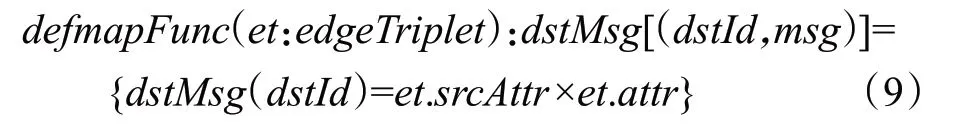
在邊分區內執行map 函數時,源節點src 以并行方式向本地目的節點集合dstIds發送消息,消息度量值是源節點當前的狀態值與該條連接邊屬性的乘積。當目的節點存在多條入度連接邊,目的節點dst 在本地局部聚合的結果是該點所有入度連接邊上消息聚合的總和,通過reduce函數得到:
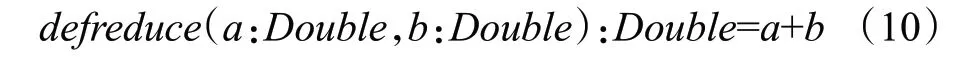
Spark 環境下的局部計算可以通過公式(9)和公式(10)實現,⊕算子是乘積算子和加法算子,滿足交換律、結合律。根據公式(6),目的節點dst 的全局狀態值是上一次更新后的全局狀態值與最新的狀態變化值直接求和:
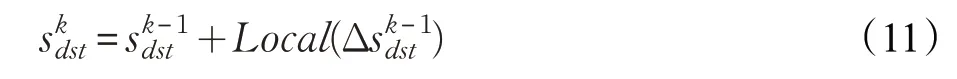
式中,⊕是加法算子,滿足交換律和結合律,因此頂點在第k 輪的全局狀態與不同邊分區中頂點的局部狀態值到達的次序無關,而通過式(9)、(10)計算得到,因此全局狀態值的更新滿足異步迭代條件。本文接下來結合公式(9)、(10)和公式(11)給出PageRank算法異步更新的具體實現。
4.3 分布式環境中的實現
根據公式(9)、(10),Spark 環境下邊分區內部的活躍節點沿其出度連接邊給目的節點發消息,而目的節點對其每條入度連接邊上對收到的消息進行局部聚合,如算法1。
算法1在邊分區內對目的節點的局部狀態聚合
輸入:點分區的活躍源節點集合activeSet,源節點狀態值變化的數據塊newSrcAttrblock
輸出:邊分區內部目的節點的局部狀態信息local_aggregates,并將localBlockForVertexPartition發給點分區vertexPartition
/*遍歷本地的源節點集合*/
1.for each srcId in localSrcIds
/*如果活躍節點集合包含源節點sccId*/
2.if activeSet.contains(srcId)
/*更新邊分區三元組上活躍源節點srcId的狀態值*/
3. newSrcAttr=update(srcId,newSrcAttrblock)
4. newedgeTriplet=updateEdgeTriple(tsrcId,news rcAttr)
/*在源節點srcId的出度連接邊上給目的節點發送消息*/
5. mapFunc(newedgeTriplet=>dstMsg([dstId,msg)])
/*在目的節點dstId入度連接邊上作本地局部聚合*/
6. for each dstId,msg in dstMsg([dstId,msg)]
7. reduceFunc(local_aggregates(dstId),msg)
/*根據目的節點所在的點分區對局部聚合結果進行切分*/
8.dstBlockToVertexPartition=split(dstVidsInVertexPartition,local_aggregates)
/*將分區后的數據塊依次發送至所在的點分區*/
9.for each vertexRef in vertexPartitionRefs
10.vertexPartitionRef.send(dstBlockToVertexPartition)
算法1中,邊分區中源節點是否對其出度連接邊上的目的節點發送消息,取決于源節點是否處于活躍狀態(active)。因此,邊分區首先接收來自點分區的活躍節點集(activeSet)以及包含源節點變化值的數據塊newSrcAttrblock,并且檢查本地源節點是否在活躍節點集中。對于活躍的源節點,更新其狀態變化值得到最新的以該點為中心的三元組集合newedgeTriplet。此后,mapFunc 并行作用于更新后的以srcId 為源節點的三元組上,同時reduceFunc 對目的節點dstId 入度連接邊上的消息進行聚合,得到目的節點在本地局部聚合的結果local_aggregates。由于邊分區中的目的節點分布在不同的點分區中,按照式(7)對本地聚合結果進行切分,將切分后的結果dstBlockToVertexPartition 通過每個點分區地址引用vertexPartitionRef發送給對應的點分區。
另一方面,點分區收到不同邊分區的數據塊,按照圖2更新節點的狀態信息,如算法2。
算法2點分區對收到的數據塊后進行處理,將更新后的源節點狀態變化值以數據塊的形式發送到所在的邊分區
輸入:點分區從邊分區收到的局部匯聚結果dstBlockTo-VertexPartition
輸出:更新后的源節點狀態變化值數據塊newSrcAttrblock
/*receive線程將邊分區發送的數據塊dstBlockToVertex-Partition放入阻塞隊列blockingQueue*/
1.blockingQueue.pu(tdstBlockToVertexPartition)
/*update線程池從阻塞隊列取出數據塊curBlock*/
2.curBlock=blockingQueue.take()
/*update 線程池遍歷數據塊中的節點vid 及其變化值delta*/
3.for each vid,delta in curBlock
/*將節點和狀態變化值寫入狀態信息表stateTable*/
4.stateTable.write(vid,delta)
/*將滿足條件的源節點放入狀態更新數據集srcDelta-ToEdgePartition,活躍節點集activeSet中*/
5.if(delta>DELTA_THRESHHOLD)
6.srcDeltaToEdgePartition.append(vid,delta)
7.activeSet.add(vid)
/*根據源節點所在的邊分區srcVidToEdgePartition 對狀態更新數據集srcDeltaToEdgePartition進行切分*/
8.newSrcAttrblock=split(srcVidToEdgePartition,srcDelta-ToEdgePartition)
/*send線程將切分后的數據塊newSrcAttrblock依次發送至所在的邊分區*/
9.for each edgePartitionRef in edgePartitionRefs
10.edgePartitionRef.send(newSrcAttrblock)
算法2中,receive線程首先將來自邊分區的數據塊放入緩存隊列,update線程從緩存隊列取出數據塊處理目的節點的變化值。為了避免對狀態表中同一頂點同時寫入狀態變化值,update線程在寫入數據之前需要首先獲取狀態表的寫鎖,在寫入數據之后檢查該頂點的狀態變化值是否超過頂點狀態變化的閾值,并將滿足條件的頂點放入待發送數據塊以及活躍頂點集activeSet中。另外,由于點分區中更新后的源節點分布在不同的邊分區中,需要對點分區內更新后的結果進行切分,并將切分后的結果newSrcAttrblock 通過每個邊分區地址引用edgePartitionRef 依次發送給對應的邊分區。當邊分區收到點分區的數據塊之后再次執行算法1,并繼續執行新一輪的局部聚合任務,當邊分區內所有源節點為非活躍狀態時,終止算法1和算法2。
5 實驗和結果分析
5.1 實驗準備
本文選取真實網絡樣本數據集wiki-topcats[17],該數據集共包含1 791 489個頂點,28 511 807條連接邊。為實現負載均衡,以哈希方式對圖數據作點切分,頂點和連接邊的狀態值分別存放在4 個點分區和4 個邊分區。通過兩組實驗驗證方法有效性:第一組實驗統計PageRank 在全局同步和異步更新的收斂結果;第二組實驗給出不同迭代方式下的收斂時間和通信開銷。
5.2 初始化和結束條件
在執行迭代算法之前,首先對圖中頂點狀態進行初始化。根據公式(11),在迭代過程中需要保證第k+1輪狀態值是第k 輪狀態值與下一輪狀態變化值求和的結果,因此設定點分區內頂點的初始值為0,邊分區內頂點初始值1-d,邊分區內所有頂點的狀態為激活狀態。另外,PageRank 算法中頂點狀態值在迭代過程中呈單調增長趨勢,因此采用頂點全局狀態值的總和作為收斂程度的度量值,頂點的狀態初始值以及整個圖中活躍節點的個數將影響整個圖的最終收斂結果。當d 值越小,頂點的初始狀態值越大,并且圖中活躍頂點個數越多時,圖中頂點狀態值的收斂總和越大。根據PageRank 算法的迭代公式,通常情況下設定d 值為0.8,使得孤立頁面隨機跳轉到其他頁面的概率為0.2。在異步迭代方式下,不同點分區內頂點的全局狀態相互獨立,只要點分區內頂點全局狀態總和的增長區間小于設定的閾值,即認為該分區的頂點達到全局收斂。當設定閾值越大,圖越容易達到收斂狀態,當所有分區的頂點全部收斂,結束整個迭代過程。
5.3 收斂結果
首先,按照全局同步方式對圖數據迭代。Spark 環境下的全局同步通過reduce 算子觸發邊分區內部的局部消息聚合任務,再將聚合后的結果發送給點分區作全局同步,圖中所有頂點的狀態總和與迭代次數之間的關系如圖3所示。
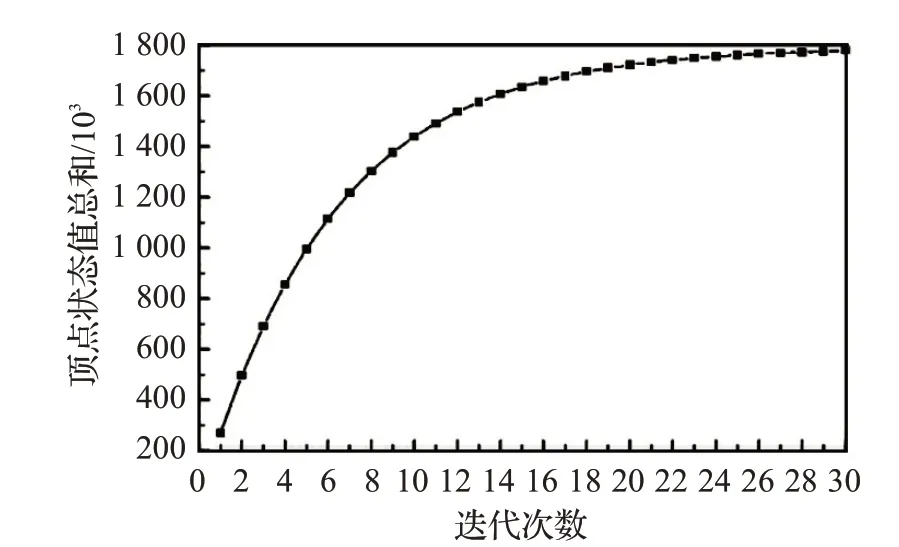
圖3 全局同步迭代下頂點狀態總和
在圖3中,頂點狀態值的總和隨著迭代次數增長不斷增大。迭代前10 輪頂點狀態總和的增長速度較快,隨后增長速度減緩,迭代到22輪時,頂點狀態值的總和接近收斂狀態。
其次,異步迭代不受全局同步的限制,因此異步更新沒有迭代次數的概念,不能通過迭代次數判斷圖的收斂狀態。考慮到頂點的全局狀態更新取決于邊分區數據塊到達的時間,并且不同分區內頂點的全局狀態之間相互獨立,因此可以統計不同點分區內頂點的全局狀態總和判斷圖數據的收斂狀態。圖4 給出不同點分區內頂點狀態總和隨著數據塊處理的變化關系。
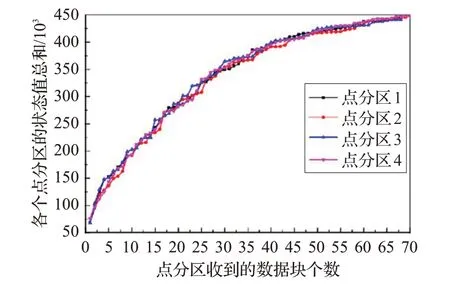
圖4 異步迭代下各個點分區的頂點狀態總和
在異步迭代初始階段,邊分區內所有源節點的初始狀態都為激活狀態,因此邊分區內所有源節點都能向目的節點發送消息,使得初始階段各個點分區內頂點的全局狀態總和增長較快。另外,異步更新并不要求所有邊分區的數據塊同時到達,只要點分區收到數據塊就能立即更新部分頂點的狀態,因此各個點分區的頂點狀態總和在收斂過程中出現不同幅度的震蕩。當4 個點分區處理完65~70個數據塊后,頂點狀態總和與全局同步迭代到22輪的狀態值接近,認為異步迭代接近收斂。
5.4 收斂速度
為比較全局同步和異步迭代的收斂速度,以圖3和圖4 的收斂值統計全局同步和異步迭代的收斂時間。圖5給出全局同步下reduce和collect算子在每輪迭代過程中的平均運行時間。
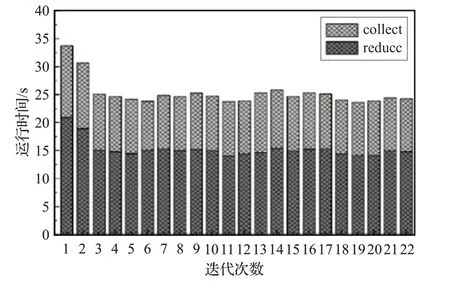
圖5 全局同步每輪迭代的運行時間
從圖5 可以看到,全局同步迭代輪數較少,但是由于存在路障限制,全局同步迭代需要等到所有邊分區的結果全部到達才能對頂點的狀態進行更新。每輪迭代過程中reduce 算子平均運行時間為12~18 s,collect算子平均運行時間在8~10 s。在已知圖數據收斂狀態情況下,僅考慮每輪迭代過程中reduce 算子運行的時間,并且只在最后收斂階段使用collect算子將頂點狀態匯總至driver 計算收斂結果,全局同步的平均收斂時間為335.7 s。
由于初始階段點分區需要等待邊分區局部聚合的結果,導致點分區發送數據塊的時間變長,因此圖6 中前后兩個階段消耗的時間比其他階段長。在對圖數據處理多次后,4個點分區的平均收斂時間分別為112.4 s、114.5 s、117.2 s、119.7 s,相同數據集下以頂點為中心異步更新的收斂時間為102.7 s。
圖6 給出4 個點分區處理數據塊的時間,起始點設為點分區收到數據塊的時間,結束點為點分區將處理后的頂點狀態變化值以數據塊的形式發送給邊分區的時間,圖中每個點分區對數據塊的接收、更新到發送時間集中在0.5~2.5 s。
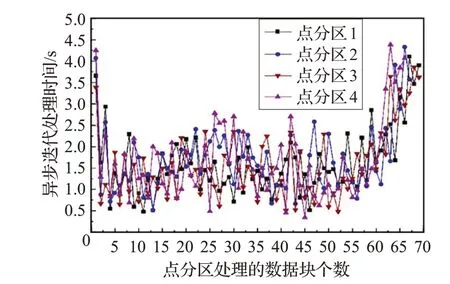
圖6 異步更新下點分區對數據塊的處理時間
5.5 通信代價
全局同步的通信開銷主要由每輪迭代過程中的reduce算子產生,當邊分區在本地的局部聚合全部結束之后,需要對所有邊分區中具有相同索引頂點的局部狀態作全局聚合,并將結果發送給點分區。統計發現全局同步迭代方式下每輪迭代的通信開銷在125~132 MB。對圖數據進行多次全局同步迭代后,通信量均值為2 850 MB。
相比全局同步要求4 個邊分區將數據塊匯總后同時發送到點分區,以子圖為中心的異步迭代不需要等待其他分區的局部聚合結果,能夠直接將邊分區聚合后的數據塊發送給點分區。分別對邊分區和點分區發送的消息量進行統計,結果表明邊分區給點分區發送的數據塊大小在3~4 MB,點分區給邊分區發送的數據塊大小在2~3 MB。當各個點分區接近收斂狀態,產生的網絡通信量共1 950 MB。基于頂點為中心的異步迭代通過頂點更新次數統計網絡通信開銷,統計發現以頂點為中心的異步迭代方式下每個頂點平均更新9 次達到收斂狀態。對圖數據進行多次異步迭代后,網絡通信量均值為2 520 MB。
根據以上分析,圖7給出了不同迭代方式下的圖迭代的收斂時間和通信開銷。從圖7可以看到,與全局同步迭代方式相比,以子圖為中心的異步迭代不僅能有效降低收斂速度同時能提高通信效率。與頂點為中心的異步迭代方式相比,基于子圖為中心的異步更新方式在收斂時間上雖略有增長,但是能夠顯著降低通信開銷。
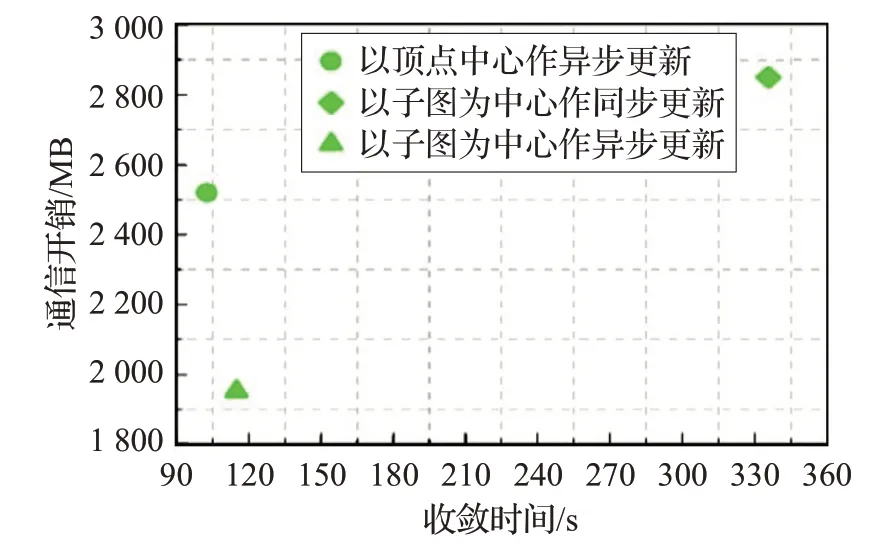
圖7 不同迭代方式下的收斂時間和通信開銷
5.6 原因分析
圖3 表明全局同步迭代輪數較少,但是由于存在路障限制,全局同步迭代需要等到所有邊分區的結果全部到達才能對頂點的狀態進行更新。圖4 中異步更新處理的數據塊個數雖然較多,但只要迭代算法滿足異步更新條件,點分區收到任一邊分區的局部聚合結果,就能夠立即從緩存隊列中取出數據塊進行處理,因此基于子圖的異步更新方式能極大縮短圖的收斂時間。由于整個迭代過程時間較短,這也使得異步迭代產生的通信量遠少于全局同步產生的通信量。
另外,以頂點為中心的異步迭代以頂點為單位更新頂點狀態,以子圖為中心的異步迭代以數據塊為單位更新頂點狀態,因此以頂點為單位進行異步更新能夠更快地加速圖狀態收斂。相比較于以頂點的異步迭代在收斂時間上略有增長,基于子圖的異步迭代可以通過以下方式極大提高通信效率:
(1)大部分網絡拓撲服從冪律分布,網絡中連接邊的數量遠遠超過頂點的個數,因此以頂點為對象發送消息的次數遠少于跨連接邊發送消息的次數[18]。
(2)基于子圖的劃分方式將大量頂點連接邊存放在同一分區,少部分頂點的連接邊分布在不同的邊分區,這種存儲方式不僅減小了消息發送的次數,基于子圖為中心的異步迭代通過在邊分區內通過聚合機制獲取頂點的局部狀態后,以批量方式集中將分區的局部聚合結果發送給點分區。
(3)單個頂點在同一邊分區中存在多條連接邊,更新后的頂點狀態發往同一邊分區后在很大程度上能夠對頂點狀態信息重用,因此進一步減少了同一頂點跨越計算節點發送消息的次數。
6 結束語
Spark 環境下的Graphx 圖處理系統要求子圖之間的計算任務保持全局同步,因此限制了圖迭代的收斂速度[19]。根據Spark 環境下圖切分和數據存儲的特點,本文提出了一種基于子圖的異步迭代更新方法。實驗結果表明,該方法能夠有效提高圖迭代的收斂速度,同時降低網絡通信開銷。未來,將對方法的擴展性[20]作進一步研究。
