防止暴露位置攻擊的軌跡隱私保護
2020-04-09 14:49:08劉向宇陳金梅夏秀峰ManishSingh宗傳玉
計算機應用 2020年2期
劉向宇,陳金梅,夏秀峰,Manish Singh,宗傳玉,朱 睿
(1.沈陽航空航天大學計算機學院,沈陽110136;2.惠靈頓理工學院信息與商科學院,新西蘭下哈特5010)
0 引言
近年來,隨著定位技術和位置感知設備的發展,移動用戶的位置和軌跡信息被大量地收集和發布。對于軌跡信息的挖掘和分析,產生了許多新型的應用。例如,通過分析特定區域中用戶的軌跡信息可以幫助投資者進行商業決策,比如在哪里建立商場;同時,政府機構可以通過分析城市中的車輛軌跡來優化交通管理系統和交通路線的設計,發現不合理的道路規劃。雖然發布軌跡信息在與其相關的決策和應用中發揮了極大的作用,但是也存在著嚴重的個人隱私泄露威脅,如果惡意攻擊者獲取到軌跡信息,就可以通過數據挖掘技術獲取到用戶軌跡數據中的隱私信息:家庭住址、工作單位、興趣愛好、生活習慣和健康狀況等,將給用戶帶來嚴重后果[1-2]。因此,對軌跡信息的隱私保護受到了國內外學者的廣泛關注。
目前軌跡隱私保護技術大致分為三類:假軌跡、軌跡泛化和軌跡抑制。其中,假軌跡隱私保護方法具有機制簡單、計算量小、不需要可信的第三方實體,且能保留完整的軌跡信息等特點,在實際研究中得到了廣泛的應用。但是現有的假軌跡保護方法在生成假軌跡時沒有考慮用戶的暴露位置,可能會降低軌跡的隱私保護程度甚至直接泄露用戶的真實軌跡。
圖1(a)為用戶的真實軌跡tr,其中l2為用戶t2時通過微博發布動態顯示的位置,攻擊者可以獲取此信息。當用戶發布軌跡時,使用現有的假軌跡隱私保護方法來隱匿該軌跡,軌跡匿名要求是3-匿名,即識別真實軌跡的概率不大于1/3。例如圖1(b)中的d1和d2為采用文獻[3]中的隨機法生成的兩條假軌跡,和真實軌跡tr組成軌跡集來進行軌跡匿名。然而,由于攻擊者知道用戶t2時出現在位置l2,而軌跡d2在t2時沒有經過位置l2,故攻擊者可識別出其為假軌跡,從而識別真實軌跡的概率變為1/2,大于軌跡隱私要求的1/3,導致軌跡隱私泄露。本文將這種攻擊方式定義為暴露位置攻擊(具體定義后文給出)。
針對此問題,本文提出了一種假軌跡隱私保護算法,其基本思想是構建k-1 條與真實軌跡相似且包含暴露位置的假軌跡來隱匿真實軌跡。值得一提的是,軌跡隱私保護既意味著整個軌跡不被識別,也意味著軌跡中的敏感位置(除暴露位置外的其他位置)不被識別。圖1(c)為添加假軌跡后的軌跡集。每條假軌跡都包含暴露位置l2。實驗結果表明,本文算法可以有效保護用戶的真實軌跡。

圖1 真實軌跡tr、隨機法生成的tr的假軌跡和tr的匿名軌跡集Fig.1 Real trajectory tr,dummy trajectories of tr generated by random algorithm and the anonymized trajectory set TRS of tr
1 相關工作
軌跡k-匿名是軌跡隱私保護方法之一,其主要思想是由匿名服務器挑選k-1 條其他用戶的軌跡與該用戶軌跡組成軌跡集,且這k 條軌跡無法區分。Monreale 等[4]提出了一種基于空間泛化和k-匿名的方法對原始GPS 軌跡進行轉換,在已有的軌跡數據集中實現真正的匿名;Xu 等[5]使用不同移動用戶的歷史足跡來形成匿名區域,并構建k-1 條歷史軌跡;Abul等[6]提出NWA(Never Walk Alone)方法,并通過軌跡聚類和空間轉移實現(k,δ)-anonymity;Huo 等[7]提出YCWA(You Can Walk Alone)方法,通過對軌跡上停留點泛化來保護軌跡隱私。
軌跡抑制法是指選擇性地發布軌跡數據,將敏感或頻繁訪問的位置去除。Gruteser 等[8]根據某個區域的用戶訪問量將地圖劃分為敏感區域和非敏感區域,當用戶進入到敏感區域時,抑制或推遲更新其位置,非敏感區域不受控制;Terrovitis 等[9]提出通過抑制處于敏感區域的位置來使軌跡泄露的風險低于用戶設定的隱私保護閾值;趙婧等[10]提出基于軌跡頻率處理軌跡數據來保護軌跡隱私。
假軌跡隱私保護的主要思想是由用戶自己生成k-1 條假軌跡,與真實軌跡組成軌跡集進行發布,其基本思想最早是由Kido 等[3,11]提出;Lei 等[12]通過隨機模式和旋轉模式來生成假軌跡;Wang 等[13]通過算法求出最佳旋轉角度來生成假軌跡,并將部分數據信息存儲在霧結構中進行物理控制,保證用戶的隱私;雷凱躍等[14]生成假軌跡時考慮了軌跡中相鄰位置的時間可達性和時空關聯性;Wu 等[15]考慮了用戶的移動模式,基于重力模型定義了連續位置熵和軌跡熵來度量軌跡保護程度,并基于此提出了假軌跡隱私保護方法。
然而現有的假軌跡隱私保護算法在生成假軌跡時沒有考慮用戶的暴露位置,使得攻擊值很容易利用暴露位置識別出某些假軌跡,甚至真實軌跡。本文以此為出發點,設計假軌跡隱私保護方案。
2 預備知識
本文涉及的變量說明如下:位置是地圖上的一個興趣點(醫院、餐廳、商店、銀行等),表示為l=(x,y),其中:x為經度,y為緯度。直接使用l代表位置。一條軌跡是由n個具有時空特性的位置組成的序列,可以將真實軌跡表示為tr={(l1,t1),(l2,t2),…,(ln,tn)},假軌跡表示為d={(l'1,t1),(l'2,t2),…,(l'n,tn)},其 中(li,ti)表 示 用 戶ti時 在 位 置li簽 到,且1 ≤i ≤n。| tr |表示軌跡的長度。由tr和k-1 條假軌跡組成的軌跡集為TRS={tr,d1,d2,…,dk-1}。
定義1暴露位置。 給定一條真實軌跡tr={(l1,t1),(λ,tλ),…,(ln,tn)},λ 為用戶在tλ時通過移動設備發布至社交網絡且所有人可知的位置,此時稱λ 為tr 在tλ時的暴露位置。該條軌跡中可以有多個暴露位置,用EL={(λ1,tλ1),(λ2,tλ2),...(λm,tλm)}(m <n)表示tr 的 暴 露位置集。軌跡中除暴露位置外的其他位置為敏感位置。
如圖1(a)所示,l2為暴露位置,軌跡中的其他位置{l1,l3,l4,l5}為敏感位置。
定義2暴露位置攻擊。假設攻擊者知道用戶軌跡中的某些位置,當其利用這些位置進行隱私攻擊時,稱為暴露位置攻擊。
例如用戶針對tr發布的軌跡集為TRS,tr的暴露位置集為EL,攻擊者利用暴露位置(λi,tλi)∈EL 作為先驗知識對軌跡集TRS 進行攻擊,當TRS 中某條軌跡在tλi時刻未經過暴露位置λi時,可識別出其為假軌跡,從而導致用戶軌跡隱私泄露。如圖1(b)所示,攻擊者利用l2攻擊,軌跡d2在t2時未經過位置l2可識別出其為假軌跡。
定義3軌跡泄露率TE。假設用戶發布的軌跡集為TRS,攻擊者利用其背景知識對TRS 進行識別,推測出用戶真實軌跡的概率。

其中|TRS'|表示被攻擊者識別為假軌跡的數量。
定義4平均位置泄露率ALE。假設用戶針對tr 發布的軌跡集為TRS,tr 的長度為n,暴露位置集為EL,個數為m(m<n),除暴露位置外的其他時刻ti對應的位置集為Li,在這個時刻泄露真實位置的概率為1/Li,那么對于整個軌跡而言,平均位置的泄露率為:

定義5(p,k)-anonymity。給定tr 的軌跡集TRS,軌跡匿名閾值p、k(p≤k),如果TRS 中任一敏感位置的位置泄露率不大于,軌跡泄露率不大于,則認為軌跡集TRS 滿足(p,k)-anonymity。
如圖1(c)所示的軌跡集滿足(2,3)-anonymity。
定義6位置距離。給定兩個位置li和lj,位置距離定義為位置間的歐氏距離。

定義7軌跡距離。給定兩條軌跡tr1={l1,l2,…,ln},,軌跡距離定義如下:

定義8軌跡距離閾值。給定兩條軌跡tr1和tr2,若α ≤TDist(tr1,tr2)≤β,則認為tr1和tr2之間的軌跡距離滿足軌跡距離閾值(α,β)。
問題1 給定用戶真實軌跡tr,暴露位置集EL,軌跡距離閾值(α,β),軌跡隱私要求閾值(p,k),采用假軌跡隱私保護方法使得生成的軌跡集滿足(p,k)-anonymity。
3 基于假軌跡的隱私保護算法
本文提出的基于假軌跡的軌跡隱私保護(Dummy-based Trajectory Privacy Protection,DTPP)算法的主要思想是生成k-1 條假軌跡與真實軌跡組成可供發布的軌跡集,代碼如算法1 所示。該算法既要求保護軌跡,又要求保護位置,所以每一條假軌跡既要盡可能地在形狀上與真實軌跡相似,又要增加軌跡集中敏感位置處的假位置數。DTPP 首先通過候選假軌跡生成算法DTC(Dummy Trajectory Candidate)得到Score 值降序排列的假軌跡候選集第2)行)。Score是一個啟發式函數,其值度量了假軌跡在軌跡相似性和位置多樣性兩方面的影響。Score 值越大表明該假軌跡與真實軌跡越相似,且能提供更多的假位置。然后循環選擇Score 值最大(即在Candtr頂端)的假軌跡加入到軌跡集中,直到生成k-1條假軌跡(第3)~5)行)。DTPP 生成軌跡集后,依次判斷每個敏感位置處的位置數是否滿足位置匿名閾值p,若不滿足,說明用戶該敏感位置處的假位置無法使軌跡集滿足(p,k)-anonymity(第7)~9)行),需要將其抑制,才能保證用戶的隱私安全。最后DTPP返回軌跡集合(第10)行)。
算法1 假軌跡隱私保護算法DTPP。
輸入 真實軌跡tr,暴露位置集EL,軌跡匿名閾值(p,k),軌跡距離閾值(α,β);
輸出 包含k條軌跡的軌跡集。

3.1 軌跡度量
本文使用軌跡相似性(表示為Sim(d,tr))和位置多樣性(表示為Div(d,TRS))來度量假軌跡的影響,為了最大化假軌跡的作用效果,本文設計了如式(5)所示的啟發式來選擇假軌跡。

軌跡相似性Sim(d,tr)的定義如式(6)所示,它顯示了假軌跡與真實軌跡之間的形狀相似度,通過假軌跡與真實軌跡對應位置間的位置距離的方差來度量。為了與語義信息相匹配,通過對其取倒數即可達到“Sim(d,tr)越大,假軌跡與真實軌跡越相似”的效果。

位置多樣性Div(d,TRS)的定義如式(7)所示,它表示加入假軌跡后,軌跡集中有數量變化的位置集數占總位置集數的比例。其中div(l'i,Li)表示位置集Li在添加假位置l'i后的數量變化,有變化為1,無變化為0。


3.2 生成假軌跡候選集
在DTPP 算法中,通過候選假軌跡生成算法DTC(見算法2)生成候選假軌跡。本文通過連接假位置構造假軌跡,試想一條有s 個敏感位置的軌跡,每個敏感位置處產生m 個假位置,如果使用枚舉法來產生假軌跡,則有ms條軌跡,假軌跡數量隨著敏感位置數呈指數增長。考慮到真實軌跡具有時空特性,假軌跡相鄰位置間應滿足時空可達性,所以本文根據假軌跡相鄰位置間是否可達把假軌跡候選集建模為有向圖,正式化為 圖G={V,E}。V={(v10,v11,…,v1m),(v20,v21,…,v2m),…,(vn0,vn1,…,vnm)},其中:vi0為真實位置,vij為假位置;E 是邊的集合,表示軌跡中相鄰位置間可達。時空可達性由式(8)判斷,vmax是用戶在真實軌跡中的最大速度。很明顯,如果式(8)不成立,則說明用戶ti時從vij出發不能在ti+1之前到達位置vi+1,j。

如圖2 所示,為圖1(a)中的軌跡和其假位置候選集構成的軌跡有向圖,其中位置v20為暴露位置。如果兩個位置點可達,則兩個位置之間有一條邊。

圖2 軌跡有向圖Fig.2 Trajectory directed graph
為了便于計算假軌跡與真實軌跡的軌跡相似性和軌跡距離,同時實現有向圖的建立,采用如圖3 所示的鄰接表存儲結構。其中:id 為位置的邏輯地址;vij為位置;Dist=dist(vi.j+1,vi0)為假位置與對應真實位置之間的位置距離;Reach 為該位置在(ti+1-ti)內可以到達的位置集合,在這里不直接存儲位置,而是存儲位置的邏輯地址,節省存儲空間。

圖3 軌跡有向圖的存儲結構Fig.3 Storage structure of trajectory directed graph
算法2 候選假軌跡生成算法DTC。
輸入 真實軌跡tr,暴露位置集EL,位置匿名閾值p,軌跡距離閾值(α,β);
輸出 假軌跡候選集Candtr。

在算法2 中,由于每條假軌跡都是以真實軌跡中的第一個位置l0或Candl0中的假位置為起始位置,以真實軌跡的最后一個位置ln或Candln中的假位置為結束位置,因此,通過在圖G上以li∈{l0∪Candl0}為開始節點進行深度優先遍歷便可得到所有可能的假軌跡(第5)、6)行)。若假軌跡與真實軌跡之間的距離滿足軌跡距離閾值(α,β),計算該條軌跡的Score值,將其加入到假軌跡候選集Candtr中(第7)~10)行)。
接下來通過軌跡有向圖生成算法TDG(Trajectory Directed Graph,見算法3)介紹軌跡有向圖的建立,首先將li和Candli合并為Vi,得到有向圖中所有的點(第3)、4)行)。然后判斷相鄰位置vij和vi+1,j間的時空可達性,若可達,則存在邊最后得到有向圖G(第5)~14)行)。
算法3 軌跡有向圖生成算法TDG。
輸入 真實軌跡tr,假位置候選集Candl;
輸出 軌跡有向圖G。

3.3 生成假位置候選集
本節介紹候選假位置生成算法DLC(Dummy Location Candidate)生成假位置候選集。考慮到真實生活中,攻擊者很容易從網上獲取到地圖信息,所以他可以根據軌跡中位置所處的地理環境特征來識別假位置,從而排除假軌跡。例如,如果攻擊者捕獲到軌跡集中的某條軌跡的某個位置是湖泊,則可以推斷出該條軌跡為假軌跡。因此,本文使用地圖中真實且有意義的位置點作為假位置來保護軌跡隱私。
為了提高程序的運行效率,本文通過網格劃分地圖。根據軌跡距離閾值(α,β)將網格單元大小設置為2β。如圖4(a)所示,如果敏感位置正好在網格中心,則只需要查找一個網格;如圖4(b)所示,若敏感位置不在網格中心,也只需要查找4個網格,大大縮短了查詢時間。
在算法DLC 中,首先根據軌跡距離閾值上限β 將地圖劃分為網格單元大小為2β×2β 的網格(第2)行)。對于軌跡中的位置,若為暴露位置,則其假位置候選集為?(第4)、5)行);若為敏感位置,根據位置坐標查找網格并遍歷其中的位置l'i,若,則將l'i加入到候選集Candli中(第6)~10)行)。記|Candli|為位置候選集中位置的個數,若|Candli|<p,則將真實軌跡中該位置刪除(第11)、12)行)。因為當|Candli|<p 時,說明li處于地理位置密度稀疏區域,無法生成足夠多的假位置來隱匿用戶的真實位置,只能將其抑制。

圖4 不同敏感位置的查詢網格Fig.4 Query girds of different sensitive locations
算法4 候選假位置生成算法DLC。
輸入 真實軌跡tr,暴露位置集EL,位置匿名閾值p,軌跡距離閾值上限β;
輸出 假位置候選集Candl。

3.4 算法的安全性、復雜度理論分析
假設用戶軌跡的長度為n,有m 個暴露位置,s 個敏感位置,那么n=s+m。
定理1采用基于假軌跡的軌跡隱私保護算法(算法1)對用戶軌跡進行保護后,得到的軌跡集滿足(p,k)-anonymity。
證明 軌跡中有s 個敏感位置,軌跡匿名閾值為(p,k)。算法4 為每個敏感位置生成假位置候選集,若其候選集中的位置數小于位置匿名閾值p,則將該位置刪除,所以軌跡中剩余的敏感位置處的位置數至少為p。算法2 生成假軌跡候選集,假設每個敏感位置處有p 個位置,理論上有ps條軌跡,而實際中,由于不只有p個位置,軌跡數會更多,足夠產生k條軌跡。算法1 通過調用算法2,啟發式地選擇假軌跡,直到軌跡集中有k 條軌跡,并且判斷軌跡集中敏感位置處的位置匿名程度,若不滿足p,將該敏感位置刪除,從而保證軌跡集中的敏感位置都滿足p 匿名。綜上,通過算法1 生成的軌跡集滿足(p,k)-anonymity。
算法復雜度分析:在算法DLC 中,敏感位置通過查詢網格獲取假位置候選集,假設|Dl|為查詢網格中的假位置數量,因為算法的時間復雜度為s ?|Dl|+m,s ?|Dl|?m,所以復雜度為O(s ?|Dl|)。在算法TDG 中,需要n ?(|Candli|+1)2時間生成有向圖,其中|Candli|為每個敏感位置的候選位置數,時間復雜度為O(n ?(|Candli|+1)2)。在算法DTC 中,首先調用算法DLC,然后調用TDG,最后執行深度優先遍歷獲取假軌跡候選集,最多耗時(|Candli|+1)s,即任意相鄰位置間都滿足時空可達性,當假位置數量過多時,可能導致有向圖很龐大,但是其執行時間最多與前人算法中的枚舉方式時間相同。實際上,通過實驗可以發現,此種情況發生的概率很小,所以算法DTC的 時 間 復 雜 度 為O(Max(n ?(|Candli|+1)2,(|Candli|+1)s))。DTPP 算法通過調用算法DTC 獲取k-1條假軌跡,DTPP 執行一次DTC,之后更新Candtr中的Score 值,耗時為n ?(|Candli|+1)2+(|Candli|+1)s+(k-2)|Candtr|,所 以DTPP 算 法 的 時 間復雜度為O(Max(n ?(|Candli|+1)2,(|Candli|+1)s))。
4 實驗評估與分析
本章對提出的假軌跡隱私保護算法進行性能分析和評價。實驗中用戶的軌跡數據來自斯坦福大學復雜網絡分析平臺公開的兩個真實數據集Brightkite和Gowalla,同時也得到了這兩個數據集所在州California 的地圖數據,包括21 047 個節點和21 692 條邊。本文從兩個軌跡數據集中分別選取了5 000個用戶的5 000條軌跡數據進行實驗,表1顯示了實驗數據的其他相關信息。

表1 實驗數據統計信息Tab.1 Statistics of datasets
首先通過實驗獲得本文DTPP 算法中最優軌跡距離閾值;然后通過與基于重力模型的假軌跡隱私保護方法(記為GM)[15]和基于隨機法的假軌跡隱私保護方法(記為SM)[10]進行比較來分析本文算法的性能;最后評估本文算法涉及的參數對算法的影響。在測試中:匿名閾值k和p的取值范圍分別是[6,27](默認為15)、[3,9](默認為3),暴露位置集|EL|取值范圍為[1,4](默認為1)。
本實驗的軟硬件環境如下:1)硬件環境:Intel Core i5 2.33 GHz,4 GB DRAM。2)操作系統平臺:Microsoft Windows 7。3)編程環境:Java,IDEA。
4.1 最優軌跡距離閾值
本節通過測試DTPP 算法在不同軌跡距離下的軌跡相似性、平均位置泄露率和運行時間來獲得最優軌跡距離閾值(α,β)。
由圖5 可知:1)隨著軌跡距離的增大,軌跡相似性逐漸降低,平均位置泄露率逐漸降低,運行時間逐漸增加。這是因為隨著軌跡距離的增加,更多的假位置加入到軌跡集中,而所有的假軌跡都要經過暴露位置,導致軌跡相似性降低;相應地,平均位置泄漏率減小,運行時間增加。2)當軌跡距離為2 km時,雖然軌跡相似性很高,但平均位置泄漏率卻很大,Gowalla數據集甚至達到了60%;當軌跡距離大于6 km 時,軌跡相似性在減小,但平均位置泄露率基本穩定于20%。3)當軌跡距離小于6 km 時,本文DTPP 算法的運行時間在4 s 以內,所以本文把軌跡距離閾值設為(α,β)=(3,6)。4)從兩個數據集比較上來看,Gowalla 數據集在軌跡相似性和平均位置泄露率方面比Brightkite 略好,但運行時間比Brightkite 稍長,這是因為Gowalla 數據集中的位置分布密度要略高于Brightkite 數據集。

圖5 軌跡相似性、平均位置泄漏率和運行時間隨軌跡距離的變化Fig.5 Trajectory similarity,average location disclosure rate and running time varying with trajectory distance
4.2 性能分析
本節通過軌跡泄露率、軌跡相似性和算法運行時間來比較DTPP 算法、GM 和SM 的性能。由圖6~8 可知:1)軌跡相似性隨著軌跡數量的增多而減小。DTPP 算法的軌跡相似性比GM 算法低約5%,這是因為DTPP 算法考慮了暴露位置,導致假軌跡與真實軌跡對應位置之間的位置距離差異性較GM 算法要大一些,而GM 算法考慮了用戶的移動模式,產生的假軌跡與真實軌跡更為相似,但算法DTPP 的軌跡相似性卻遠高于SM 算法,是SM 算法的4 倍左右。2)當軌跡中存在暴露位置時,由于DTPP 算法考慮了暴露位置,攻擊者無法利用此信息識別假軌跡;而GM 算法在生成假軌跡時,與真實軌跡沒有交點,導致攻擊者可以利用暴露位置100%識別出真實軌跡;SM 隨機生成假軌跡,所以可能經過暴露位置,但平均軌跡泄露率卻高達約50%。3)三個算法的運行時間隨著軌跡數的增多而增加。DTPP 算法的運行時間與RM 算法相差不大,都低于5 s,但遠低于GM 算法。這是因為GM 算法在生成假軌跡時,應用枚舉法列舉所有可能的假軌跡,其運行時間隨著位置數呈指數增長,而DTPP 算法通過構建合理的數據結構縮減了假軌跡候選集,節省了運行時間。
綜上所述,可以得出DTPP 算法在考慮暴露位置的同時,能保持較高的軌跡相似性且花費很少的運行時間,所以DTPP算法能有效保護用戶的真實軌跡。
4.3 參數評估
本節通過實驗評估DTPP 算法涉及的參數對算法性能的影響。

圖6 軌跡相似性隨k的變化Fig.6 Trajectory similarity varying with k

圖7 軌跡泄漏率隨k的變化Fig.7 Trajectory disclosure rate varying with k

圖8 運行時間隨k的變化Fig.8 Running time varying with k
首先評估暴露位置數|EL|對軌跡相似性和運行時間的影響。由圖9可知:1)當暴露位置數|EL|在(1,3)區間時,軌跡相似性隨著暴露位置數的增加而減小;當|EL|>3 時,軌跡相似性隨著暴露位置數的增加而增大。這是因為開始時暴露位置數的增加導致軌跡之間的位置距離差異增大,當暴露位置數增加到一定程度后,軌跡之間重合的部分變多,軌跡相似性相應提高。2)DTPP 算法的運行時間隨著暴露位置數的增加較大幅度地降低,當暴露位置數大于2時,運行時間均低于1 s。這是由于暴露位置數的增多導致生成候選假位置集和假軌跡集時間大幅減少。
接下來通過位置抑制比來衡量軌跡匿名閾值中的p 對算法的影響。將位置抑制比定義為軌跡中被抑制位置數占總位置數的比例。由圖10 可知:位置抑制比隨著位置匿名閾值p的增大而增大,但位置抑制比沒有超過10%,說明DTPP 算法在滿足位置匿名要求的前提下,不需要抑制太多的位置。
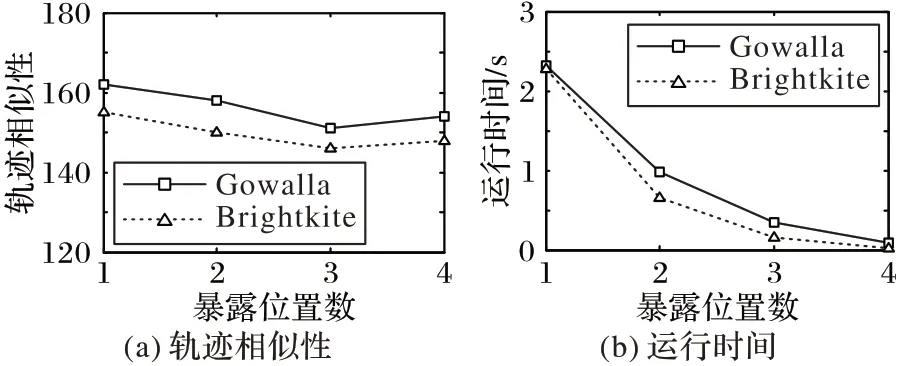
圖9 暴露位置數|EL|對DTPP的影響Fig.9 Effect of|EL|on DTPP

圖10 位置匿名閾值p對DTPP的影響Fig.10 Effect of p on DTPP
5 結語
本文首次提出應用假軌跡保護軌跡隱私時考慮用戶的暴露位置,并基于此研究了一種軌跡隱私保護算法DTPP。該算法基于網格查找假位置候選集,并利用軌跡相鄰位置間的時空可達性構建軌跡有向圖存儲假軌跡候選集,建立了啟發式規則選擇假軌跡,使得假軌跡在保護真實軌跡時具有更好的軌跡相似性。基于真實軌跡數據集進行實驗,結果表明DTPP算法能夠有效保護軌跡隱私免受暴露位置攻擊。由于本文采用真實地圖上的位置點作為假位置,因而適合保護分布在地理位置密度較密集區域中的軌跡。對于分布于地理位置密度稀疏的軌跡,需要抑制敏感位置,導致信息損失較大。針對此問題的解決方式,還需要進一步研究。
猜你喜歡
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
山東青年(2016年1期)2016-02-28 14:25:25
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
當代修辭學(2014年3期)2014-01-21 02:30:44
