基于詞向量的SVM集成學(xué)習(xí)社交網(wǎng)絡(luò)抑郁傾向檢測方法
2020-04-09 04:42:13王垚賈寶龍杜依寧張晗陳響
無線互聯(lián)科技 2020年3期
王垚 賈寶龍 杜依寧 張晗 陳響


摘? ?要:目前抑郁癥的診斷手段單一、診斷率低,為此,文章提出一種基于詞向量的SVM集成學(xué)習(xí)社交網(wǎng)絡(luò)抑郁傾向檢測方法。人工標(biāo)注和專家校驗獲得訓(xùn)練數(shù)據(jù),使用詞向量進(jìn)行文本向量化。以SVM為基分類器進(jìn)行Boosting集成學(xué)習(xí)。實驗結(jié)果表明,文章提出的模型可以用于抑郁傾向的檢測。
關(guān)鍵詞:抑郁檢測;微博;支持向量機;詞向量;集成學(xué)習(xí)
目前,國內(nèi)外基于社交媒體文本內(nèi)容的抑郁傾向檢測主要分成兩類,一類是基于統(tǒng)計的數(shù)據(jù)挖掘方法,另一類是基于機器學(xué)習(xí)模型的檢測方法。
(1)基于統(tǒng)計的數(shù)據(jù)挖掘方法,主要是通過統(tǒng)計微博文本內(nèi)容的高頻詞、構(gòu)建情感詞典等方式來評價用戶的抑郁傾向。高一虹等[1]利用統(tǒng)計的方法對比了微博中抑郁傾向用戶和現(xiàn)實中抑郁癥患者,發(fā)現(xiàn)抑郁癥在現(xiàn)實生活和社交媒體上的表現(xiàn)有重合也有偏差。
(2)基于機器學(xué)習(xí)模型的檢測方法,主要是將微博文本或用戶屬性向量化,進(jìn)而構(gòu)建分類器進(jìn)行分類。施志偉等[2-3]通過問卷調(diào)查得到有抑郁傾向的用戶,并爬取其微博,使用支持向量機(Support Vector Machine,SVM)模型進(jìn)行監(jiān)督學(xué)習(xí),得到了具有82.35%準(zhǔn)確率的模型。
本研究提出了一種基于詞向量的SVM集成學(xué)習(xí)社交網(wǎng)絡(luò)抑郁傾向檢測方法,通過多組對比實驗驗證了其有效性。
1? ? 相關(guān)工作
1.1? 數(shù)據(jù)的收集
使用的數(shù)據(jù)來自新浪微博,選擇352位有明顯抑郁傾向的博主的微博作為正數(shù)據(jù),共有35 962條微博文本,323位非抑郁癥患者博主的7 297條微博文本作為負(fù)數(shù)據(jù)。篩選后得到28 654條微博文本的正數(shù)據(jù),58 569條微博文本的負(fù)數(shù)據(jù),如表1所示。經(jīng)過3位心理學(xué)系的碩士研究生進(jìn)行交叉檢驗,僅有10位用戶存在爭議,數(shù)據(jù)的可信度達(dá)到了97.5%。
1.2? 數(shù)據(jù)的清洗
為了保證數(shù)據(jù)的高可用性,對得到的數(shù)據(jù)進(jìn)行了過濾,具體過濾方法如下:
(1)過濾掉不可用的信息,如圖片、視頻以及微博中有跳轉(zhuǎn)鏈接。(2)過濾掉廣告數(shù)據(jù)以及非原創(chuàng)數(shù)據(jù),如文本中的投票、打榜、影響力、人氣演員等。(3)正則匹配過濾部分干擾字符,如@xxx,#xxx超話#等。(4)過濾掉長度小于7個字的微博文本。
2? ? 抑郁傾向檢測方法
本文提出的抑郁傾向檢測方法主要包括兩部分:構(gòu)建用戶向量、SVM集成學(xué)習(xí),如圖1所示。
首先,文本的向量化主要包含4部分:對微博文本的分詞、獲取每個詞語的百度詞向量、將詞向量進(jìn)行特征加權(quán)計算句向量、根據(jù)句向量構(gòu)建用戶向量;其次,進(jìn)行SVM有監(jiān)督學(xué)習(xí);最后,以其為基分類器進(jìn)行Boosting集成學(xué)習(xí)。
2.1? 構(gòu)建用戶向量
2.1.1? 分詞與詞向量
由于微博文本包含大量網(wǎng)絡(luò)用語,而百度分詞比較善于針對網(wǎng)絡(luò)文本進(jìn)行分詞,同時也能通過構(gòu)建自定義詞典提高特殊詞匯的分詞效果,所以先利用百度分詞API進(jìn)行分詞,然后獲得對應(yīng)的百度詞向量。對于百度詞向量庫中不存在的抑郁詞,則選擇詞向量庫中與其最相近的詞作為替代。對于不在抑郁詞典中且詞向量未收錄的詞語,直接賦0,便于之后的計算。
2.1.2? 詞向量加權(quán)
首先,使用TF-IDF進(jìn)行特征加權(quán),特征權(quán)重的計算如式(1):
2.1.3? 構(gòu)建用戶向量
2.2? SVM集成學(xué)習(xí)
集成學(xué)習(xí)是機器學(xué)習(xí)中一種通過多個算法或者模型來執(zhí)行單個任務(wù)的技術(shù),可以在一定程度上提升模型的性能。主要的集成學(xué)習(xí)方法包括堆疊[4](Stacking)、提升[5](Boosting)和裝袋[6](Bagging)3類。為了進(jìn)一步提升模型在判錯樣本上的分類能力,選擇使用Boosting的提升方法。Boosting方法通過不斷改變訓(xùn)練樣本的權(quán)重,得到多個分類器,并將其進(jìn)行線性組合,提高分類的性能。本文選擇使用Boosting方法中最經(jīng)典、最常用的是AdaBoost算法。
3? ? 實驗結(jié)果及分析
3.1? 實驗設(shè)計
實驗分為4部分:(1)用原始百度詞向量進(jìn)行訓(xùn)練,用SVM表示。(2)用TF-IDF加權(quán)詞向量進(jìn)行訓(xùn)練,用SVM-T表示。(3)用TF-IDF和抑郁詞加權(quán)的詞向量進(jìn)行訓(xùn)練,用SVM-TW表示。(4)用TF-IDF和抑郁詞加權(quán)的詞向量進(jìn)行AdaBoost集成學(xué)習(xí)訓(xùn)練,用SVM-TW-AdaBoost表示。
3.2? 評價標(biāo)準(zhǔn)
3.3? 實驗結(jié)果與分析
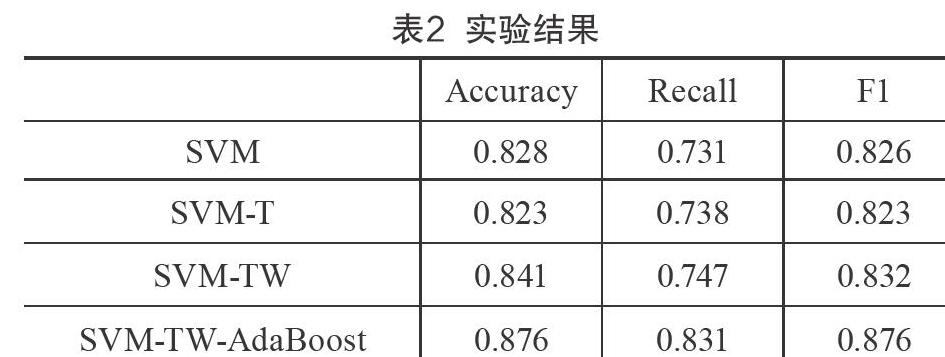
實驗結(jié)果如表2所示,可以看出,SVM-T相比SVM僅召回率略有提升,而準(zhǔn)確率和F1有所降低,說明TF-IDF加權(quán)不能較好地改善微博文本的向量表示。SVM-TW相比SVM-T有明顯提升,說明抑郁詞權(quán)重能夠有效增強微博文本抑郁傾向的表示。SVM-TW-AdaBoost相比SVM-TW有較大提升,說明集成學(xué)習(xí)能夠明顯地提升微博文本的情感表示。
4? ? 結(jié)語
本研究提出的基于詞向量的SVM集成學(xué)習(xí)方法,由于將傳統(tǒng)SVM進(jìn)行集成學(xué)習(xí),使得學(xué)習(xí)到的分類器更加準(zhǔn)確,泛化能力更強。下一步將考慮用戶其他有效特征,進(jìn)一步增強模型性能。
[參考文獻(xiàn)]
[1]高一虹,孟玲.自殺傾向的話語表述—大學(xué)生“走飯”微博分析[J].外語與外語教學(xué),2019(1):43-55,145-146.
[2]PANG B,LEE L,VAITHYANATHAN S.Thumbs up?Sentiment classification using machine learning techniques[C].Stroudsburg:Processing.of the ACL-02 Conference on Empirical Methods In Natural Language Processing,2002.
[3]YOUN SJ,TRINH NH,SHYU I,et al.Using online social media Facebook in screening for major depressive disorder among college students[J].International Journal of Clinical and Health Psychology,2013(1):74-80.
[4]李壽山,黃居仁.基于Stacking組合分類方法的中文情感分類研究[J].中文信息學(xué)報,2010(5):56-62.
[5]黃彬.基于Boosting算法的中文情感分類研究[J].電子技術(shù)與軟件工程,2017(12):190-191.
[6]FENGGANG L,JI L F,LI W,et al.A method based on manifold learning and bagging for text classification[C].Beijing:Management Science and Electronic Commerce,2011.
