基于用戶評論下的生鮮農(nóng)產(chǎn)品優(yōu)選排序
2020-04-10 06:57:04王梓萌周亦鵬蘇兵杰
江蘇農(nóng)業(yè)科學(xué) 2020年3期
王梓萌 周亦鵬 蘇兵杰

摘要:現(xiàn)如今電商市場競爭激烈,眾多小型垂直類生鮮電商緊緊圍繞在京東商城和天貓超市這兩大平臺上。用戶評論鋪天蓋地,如何減少消費者搜索和篩選的時間成本顯得尤為重要。對于生鮮農(nóng)產(chǎn)品來說,物流服務(wù)滿意度是關(guān)鍵因素。以京東商城和天貓超市兩大綜合類電商平臺的生鮮商品為例,采集大量的用戶評論,從數(shù)據(jù)中獲取物流服務(wù)滿意度影響因素進行相關(guān)度分析并最終得出6個因素,采用機器學(xué)習(xí)的方法對大量標注文本進行模型訓(xùn)練,通過訓(xùn)練的模型識別待分類文本的情感傾向,建立基于物流服務(wù)滿意度的商品排序方法,進一步提出威爾遜置信區(qū)間的方法修正物流服務(wù)滿意度用于評論數(shù)量分布不均的情形,最后對這2種算法的應(yīng)用場景作出分析介紹和對比,使商品排序過程中不僅考慮到商品的物流服務(wù)滿意度,同時也引入評論數(shù)量,通過不同的需求和數(shù)據(jù)情況生成最符合用戶期待的排序結(jié)果。
關(guān)鍵詞:電子商務(wù);生鮮農(nóng)產(chǎn)品;服務(wù)滿意度;用戶評論;情感分析;排序算法
中圖分類號: F323.7;F713.36 ?文獻標志碼: A ?文章編號:1002-1302(2020)03-0305-06
隨著時代的發(fā)展,網(wǎng)購平臺成為了生鮮購買方式之一,據(jù)中國電子商務(wù)研究中心發(fā)布的《2017(上)中國網(wǎng)絡(luò)零售市場數(shù)據(jù)檢測報告》顯示,我國生鮮電子商務(wù)交易規(guī)模在2017年上半年達到851.4億元,預(yù)測到2017年底該數(shù)據(jù)或?qū)⑦_到1 650億元,相比2016年的913.9億元,同比增長80.5%。至2017年底,生鮮電商基本形成“阿里系”和“京東系”兩大陣營。傳統(tǒng)的消費者數(shù)據(jù)調(diào)查來源大多是調(diào)查問卷,被忽略的商品評論總是更具實時性和真實性。如今的消費者主要是根據(jù)以往的購物經(jīng)驗和商品用戶評論數(shù)據(jù)形成心理預(yù)期。但是商品評論數(shù)據(jù)量大,依次瀏覽所有評論信息不現(xiàn)實,且未必能獲得滿意的結(jié)果。而生鮮農(nóng)產(chǎn)品保鮮時間不長,物流速度是影響生鮮電商發(fā)展的一項重要因素。因此,應(yīng)該重點關(guān)注物流方向評論對消費者購買選擇的問題。本研究采集大量的網(wǎng)購生鮮農(nóng)產(chǎn)品消費者評論數(shù)據(jù),并基于物流服務(wù)滿意度的生鮮商品優(yōu)選排序方法,從消費者的角度選擇商品,也便于商家針對不同情況作出調(diào)整。
1 相關(guān)研究評述
在生鮮電商方面,國內(nèi)外學(xué)者從消費者角度出發(fā)展開研究,在評價物流服務(wù)模型方面,利用突變級數(shù)方法構(gòu)建生鮮電商冷鏈物流服務(wù)評價模型[1],同時結(jié)合生鮮電商冷鏈物流質(zhì)量、成本和安全性等問題[2]。利用層次分析法和供應(yīng)鏈理論評估生鮮供應(yīng)商的績效水平[3],影響這些的主要原因是物流因素,但是還須更深一步地將評論和服務(wù)滿意度結(jié)合在一起。
在商品排序方面,大部分電子商務(wù)平臺都按照某種排序(默認是綜合排序)將商品列表返回給消費者,但網(wǎng)站只通過對用戶評論的等級(好評、中評、差評)劃分進行好評率計算,消費者在評論時習(xí)慣性地點擊好評,造成許多負面評價隱藏在好評之下,并不能作為很客觀的參考依據(jù)。目前有學(xué)者通過商品權(quán)重與用戶相似度之間的關(guān)系,分析考慮商品排序和用戶偏好的推薦算法[4],在原始排序的基礎(chǔ)上提出一種基于威爾遜區(qū)間的商品好評率排名算法,是一種比較適用于不同屬性下的商品評論數(shù)量分布不均衡下的模型[5]。
本研究通過獲取的評論數(shù)據(jù),運用數(shù)理統(tǒng)計的方法分析各個因素之間的關(guān)系,得到商品物流服務(wù)質(zhì)量各個影響因素的重要度,通過情感分析計算滿意度并建立2種排序方法,修正評論數(shù)量分布不均衡的情形,最后對這2種算法的應(yīng)用場景作出分析介紹和對比,計算店鋪綜合物流服務(wù)滿意度,為不同的角度和需求提供優(yōu)選排序的參考。
2 數(shù)據(jù)來源及方法
2.1 數(shù)據(jù)來源選取
本研究數(shù)據(jù)為京東商城和天貓超市生鮮區(qū)新鮮水果(橙子)、海鮮水產(chǎn)(帶魚)和精選肉類(牛排)的用戶評論數(shù)據(jù)。通過網(wǎng)絡(luò)爬蟲工具獲取生鮮商品的用戶評論作為本研究的原始數(shù)據(jù),京東商城抓取橙子、帶魚、牛排3類商品共56 040條評論,天貓超市生鮮商品共抓取25 783條用戶評論數(shù)據(jù)。
2.2 研究方法
本研究的主要內(nèi)容包括建立響應(yīng)指標計算其重要度、構(gòu)建滿意度模型、構(gòu)建排序模型、劃分模型適用場景等4 個階段:(1) 通過詞頻統(tǒng)計提取出9個物流服務(wù)滿意因素,再由SPSS相關(guān)性分析度判斷各因素之間的是否具有顯著性,最終得到6個影響因素,并計算每個因素的重要度。(2)通過XGBoost算法情感分析模型計算物流服務(wù)滿意度。(3)分別構(gòu)建基于物流服務(wù)滿意度的商品排序模型,引入威爾遜置信區(qū)間來進行修正模型。(4) 劃分2種排序算法適用場景,通過相同店鋪下同品類商品的物流服務(wù)滿意度進行綜合排名并得到最終排序。
3 因素識別、重要度計算及滿意度模型構(gòu)建
3.1 生鮮農(nóng)產(chǎn)品的物流服務(wù)滿意度影響因素識別
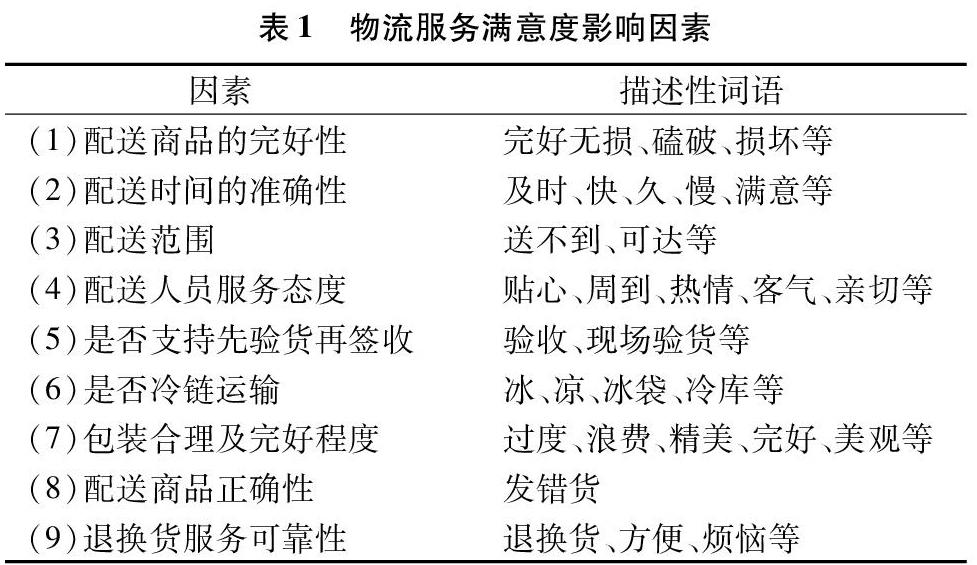
本研究從原始數(shù)據(jù)中集中抽取出有關(guān)物流的相關(guān)評論3 318條,對此樣本數(shù)據(jù)經(jīng)過中文分詞和停用詞處理之后,對其進行詞頻統(tǒng)計,再結(jié)合商品和物流服務(wù)的特征并根據(jù)對以往的文獻資料的總結(jié)整理[6-7],提取出9類影響物流服務(wù)滿意度的因素(表1)。
采用SPSS軟件對9個因素進行相關(guān)分析,觀察各因素之間以及每個因素與整體評價之間關(guān)系的顯著程度。數(shù)字1、0、-1分別表示正向情感、中性情感、負向情感(表2)。
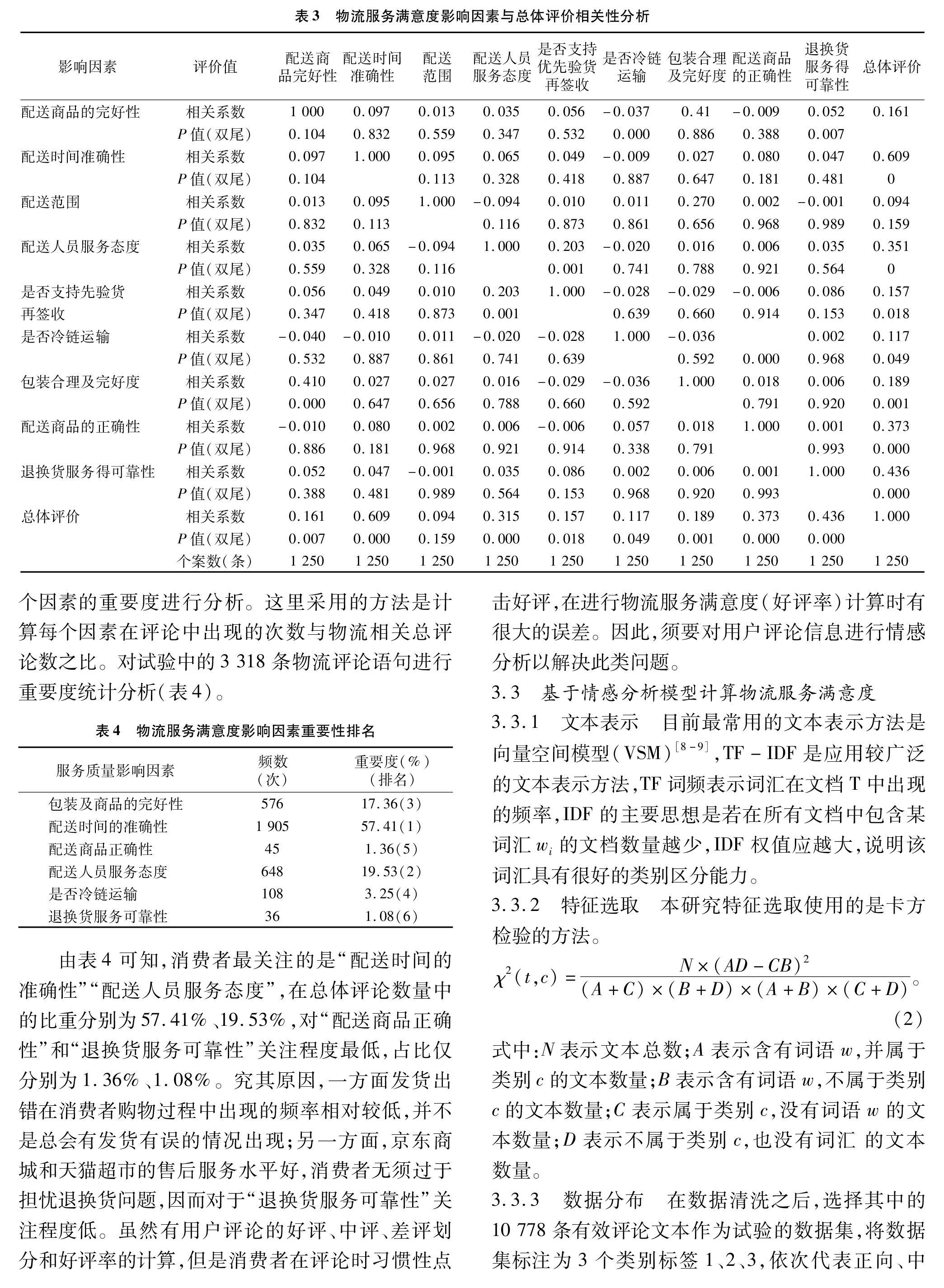
由于數(shù)據(jù)量大,本研究采用隨機抽樣的方式進行因素間的相關(guān)分析。最終選取1 000條好評、200條中評、50條差評共1 250條評論來構(gòu)建“因素-評論”矩陣(表3)。
由表3可知,配送范圍與總體評價的相關(guān)性不顯著,其余8個因素與總體評價的相關(guān)性均顯著,所以剔除“配送范圍”。配送商品的完好性、是否支持先驗貨后簽收與配送人員服務(wù)態(tài)度之間具有相關(guān)性,包裝程度對于商品送達時完好性是具有影響的;消費者在簽收商品時是否可以現(xiàn)場驗貨,消費者較易將其與配送人員的態(tài)度聯(lián)系起來,在作出評價時兩者同時出現(xiàn)的頻率較高。因此,將原有的“包裝合理及完好度”與“配送商品的完好性”合并為“包裝及商品完好性”,“是否支持先驗貨再簽收”與“配送人員服務(wù)態(tài)度”合并為“配送人員服務(wù)態(tài)度”。最終得到的服務(wù)滿意度影響因素共有包裝及商品完好性、配送時間的準確性、配送人員服務(wù)態(tài)度、是否冷鏈運輸、配送商品正確性、退換貨服務(wù)可靠性等6個維度。
3.2 物流服務(wù)滿意度影響因素重要度分析與計算
消費者在購買商品時對每一類物流服務(wù)質(zhì)量影響因素的關(guān)注程度是有區(qū)別的。因此,須要對每個因素的重要度進行分析。這里采用的方法是計算每個因素在評論中出現(xiàn)的次數(shù)與物流相關(guān)總評論數(shù)之比。對試驗中的3 318條物流評論語句進行重要度統(tǒng)計分析(表4)。
由表4可知,消費者最關(guān)注的是“配送時間的準確性”“配送人員服務(wù)態(tài)度”,在總體評論數(shù)量中的比重分別為57.41%、19.53%,對“配送商品正確性”和“退換貨服務(wù)可靠性”關(guān)注程度最低,占比僅分別為1.36%、1.08%。究其原因,一方面發(fā)貨出錯在消費者購物過程中出現(xiàn)的頻率相對較低,并不是總會有發(fā)貨有誤的情況出現(xiàn);另一方面,京東商城和天貓超市的售后服務(wù)水平好,消費者無須過于擔(dān)憂退換貨問題,因而對于“退換貨服務(wù)可靠性”關(guān)注程度低。雖然有用戶評論的好評、中評、差評劃分和好評率的計算,但是消費者在評論時習(xí)慣性點擊好評,在進行物流服務(wù)滿意度(好評率)計算時有很大的誤差。因此,須要對用戶評論信息進行情感分析以解決此類問題。
3.3 基于情感分析模型計算物流服務(wù)滿意度
3.3.1 文本表示 目前最常用的文本表示方法是向量空間模型(VSM)[8-9],TF-IDF是應(yīng)用較廣泛的文本表示方法,TF詞頻表示詞匯在文檔T中出現(xiàn)的頻率,IDF的主要思想是若在所有文檔中包含某詞匯wi的文檔數(shù)量越少,IDF權(quán)值應(yīng)越大,說明該詞匯具有很好的類別區(qū)分能力。
3.3.3 數(shù)據(jù)分布 在數(shù)據(jù)清洗之后,選擇其中的10 778條有效評論文本作為試驗的數(shù)據(jù)集,將數(shù)據(jù)集標注為3個類別標簽1、2、3,依次代表正向、中性、負向的情感傾向,為避免數(shù)據(jù)不平衡造成模型訓(xùn)練的不足,數(shù)據(jù)抽樣選取時每類數(shù)據(jù)保持均衡狀態(tài),并不存在較大差別(表5)。
本研究將商品評論文本情感識別抽象為一個分類問題,采用XGBoost算法[8]進行分類,利用機器學(xué)習(xí)的方法對人工標注的文本數(shù)據(jù)及其特征進行學(xué)習(xí),得出預(yù)測模型,從而能夠在輸入評論文本數(shù)據(jù)之后,即可自動預(yù)測該文本數(shù)據(jù)的情感傾向。
4 生鮮農(nóng)產(chǎn)品排序模型構(gòu)建及劃分
4.1 基于物流服務(wù)滿意度的商品排序模型
以各因素好評率的均值作為排序準則,根據(jù)重要程度對每個因素進行加權(quán)綜合。綜上分析可計算得到商品的物流服務(wù)質(zhì)量、各影響因素重要度和物流服務(wù)滿意度(表6)。
本研究邀請100位消費者對這2種方法的排序結(jié)果進行評價,每位參與的用戶根據(jù)自己的實際意愿選擇自己更加支持的一種排序方式,如果認為2種排序結(jié)果都不滿意,則選擇其他。最后匯總統(tǒng)計算出每種排序方法的支持率(支持率=試驗中支持該排序方法的人數(shù)/試驗總?cè)藬?shù)),得到2種排序結(jié)果的支持率(表9)。
該試驗結(jié)果(表9)說明基于威爾遜置信區(qū)間的方法對評論數(shù)量極不均衡的20個商品進行修正后,能使商品排序更加合理。另外有研究表明,商品評論對商品銷量發(fā)揮著重要的影響作用[11-12]。因此,利用統(tǒng)計軟件分析本研究所提商品排序結(jié)果與商品銷量之間的關(guān)系是否顯著。試驗數(shù)據(jù)依然使用上述選取的20種橙子,采用Spearman等級相關(guān)系數(shù)判斷銷量排序和商品排序的相關(guān)性,得到2種方法的商品排序與銷量排序的相關(guān)系數(shù)(表10)。
由表10可知,在α的情況下都具有顯著的相關(guān)性,且后者與商品銷量的相關(guān)程度更高,相關(guān)系數(shù)為 0.825,更能進一步說明在評論數(shù)量分布不均衡的條件下,威爾遜置信區(qū)間排序方法的優(yōu)越性及合理性。
4.2.2 不同場景下排序算法的選擇 綜上可以得出不同算法的具體適用場景(表11)。在商品評論數(shù)量分布不均衡的狀態(tài)下,無論物流服務(wù)滿意度是否相同,均引入威爾遜置信區(qū)間作滿意度修正;反之,在商品評論數(shù)量分布均衡的狀態(tài)下,當(dāng)物流服務(wù)滿意度不相同時,主要根據(jù)物流服務(wù)滿意度作商品的排序決策;商品評論數(shù)量分布均衡,物流服務(wù)滿意度相同時,可以劃分為2種情況:一種情況是商品評論數(shù)量相同,這時無論使用何種方法計算得到的排序分值均相同,此時對這些商品可以任意排序;另一種情況是商品評論數(shù)量不同,這時同樣須要引入威爾遜區(qū)間。
4.3 店鋪綜合物流服務(wù)滿意度計算
上述2種排序方法都是針對單個商品計算得到的綜合物流服務(wù)滿意度,而物流服務(wù)滿意度水平和商品提供者(店鋪)具有極大的關(guān)聯(lián)性,相同店鋪下同品類不同商品的物流服務(wù)滿意度是相同的,因此在商品排序時僅依據(jù)單一商品的物流服務(wù)滿意度水平對商品進行排序缺乏可信度。因此,在完成商品的物流服務(wù)滿意度計算后,對相同店鋪下同品類商品的物流服務(wù)滿意度進行綜合分析,得到該店鋪在該品類下的物流服務(wù)滿意度水平,并依據(jù)此物流服務(wù)滿意度對商品作最終排序(表12)。
由表12可知,上述加權(quán)綜合和引入威爾遜置信區(qū)間可得店鋪內(nèi)都是單個商品的物流服務(wù)滿意度水平,綜合物流服務(wù)滿意度并根據(jù)品類分別計算,通過對店鋪內(nèi)同品類商品的物流服務(wù)滿意度水平進行加權(quán)求和,計算得到該品類商品該店鋪提供的物流服務(wù)滿意度水平。
5 結(jié)語
在不同需求下作不同的排序,并考慮到爬取的數(shù)據(jù)總是存在不均衡,才能更好地為廣大消費者提供生鮮農(nóng)產(chǎn)品的優(yōu)選項,并為農(nóng)產(chǎn)品企業(yè)提供參考。本研究通過爬取大量用戶的評論數(shù)據(jù),構(gòu)建物流服務(wù)滿意度影響因素,分析在評論分布不均下的商品排序,考慮到評論數(shù)量對滿意度的可靠性影響,在商品排序過程中不僅考慮到商品的物流服務(wù)滿意度,同時也引入評論數(shù)量,對相同店鋪下同品類商品的物流服務(wù)滿意度進行綜合分析,得到該店鋪在該品類下的物流服務(wù)滿意度水平,最后對這2種算法的應(yīng)用場景作出分析介紹并得出最終排序。但本研究也存在不足之處,因為網(wǎng)絡(luò)用語具有很大的不規(guī)范性,新詞層出不窮。因此,所構(gòu)建的本體模型和語言詞庫須要經(jīng)常迭代更新。
參考文獻:
[1]邱 斌. 基于突變級數(shù)法的生鮮電商冷鏈物流服務(wù)質(zhì)量評價研究[D]. 北京:北京交通大學(xué),2017.
[2]金芯名. 生鮮農(nóng)產(chǎn)品電商冷鏈物流研究——以易果生鮮為例[D]. 武漢:華中師范大學(xué),2017.
[3]Guritno A D,F(xiàn)ujianti R,Kusumasari D.Assessment of the supply Chain factors and classification of inventory management in suppliers level of fresh vegetables[J]. Agriculture and Agricultural Science Procedia,2015(3):51-55.
[4]張云飛. 基于深度學(xué)習(xí)的短文本情感分析[D]. 北京:北京郵電大學(xué),2016.
[5]徐林龍,付劍生,蔣春恒,等. 一種基于威爾遜區(qū)間的商品好評率排名算法[J]. 計算機技術(shù)與發(fā)展,2015,25(5):168-171.
[6]尹 欣. 基于網(wǎng)絡(luò)評價的電商物流服務(wù)滿意度影響因素分析[D]. 深圳:深圳大學(xué),2016.
[7]周 雪. 基于客戶滿意度的第三方物流配送服務(wù)質(zhì)量評價指標體系研究[J]. 物流技術(shù),2013,32(15):60-62.
[8]郭 慧,柳 林,劉 曉,等. 深度學(xué)習(xí)下的情感分析與推薦算法[J]. 測繪通報,2018(9):55-58.
[9]Liu B. Sentiment analysis and opinion mining[J]. Synthesis Lectures on Human Language Technologies,2012,5(1):1-167.
[10]張學(xué)新. 一種簡單有效的二項分布比例參數(shù)似然比置信區(qū)間的求法[J]. 統(tǒng)計與信息論壇,2017,32(6):38-41.
[11]Chen Y,Xie J.Online consumer reviews:word-of-mouth as a new element of marketing communication mix[J]. Management Science,2008,54(3):477-491.
[12]Ghose A,Ipeirotis G.Deriving the pricing power of product features by mining consumer review[J]. Management Science,2011,57(8):1485-1509.
