
大數據采集與存儲技術生態及方案選型的探討
2020-04-12 08:32:22吳超
江蘇通信 2020年1期
關鍵詞:生態
吳 超
江蘇省通信管理局
0 引言
大數據時代,如何才能從豐富的數據礦藏中開采出更多價值?以石油開采來類比大數據分析,首先考慮的不是如何煉油(分析數據),而是如何獲取優質原油(高效地采集與存儲數據)。
本文圍繞三個問題展開:在大數據環境下,傳統的數據采集、存儲方式還適用嗎?現有哪些優質高效有前途的技術方案?我們該如何選擇?
1 大數據的挑戰
數據采集方面,傳統工具有ftp、scp、rsync、wget、curl等,它們通常源于少量主機之間的文件傳輸或同步的業務需求,雖然在斷點續傳、壓縮傳輸或者自動同步等方面有一定造詣,但這些基于抽樣分析的方法采集海量數據時如同“在汽車時代騎馬一樣”,效率、性能低下,不能滿足業務需求。
數據存儲方面,傳統文件系統適應不了紛繁的數據類型,同時關系型數據庫執迷于精確的ACID屬性,導致大量非結構化、混雜的數據被丟棄,無法利用。
綜上,傳統的以技術為中心的數據處理方式已不能滿足業務需求。為了實現對海量數據的分布采集、高效存儲、交互查詢、實時分析、深度挖掘等功能,需要采取以數據為中心的新方案。
2 新技術的應用
根據信息通信行業咨詢翹楚Gartner公司近年來發布的新興技術成熟度曲線,業界對大數據概念的炒作已進入尾聲,大數據技術正在走向“成熟”階段。
開源社區、商業公司、學術界、極客們圍繞著數據處理提出了種類繁多的解決方案,并站在自己立場上,對技術方案發表了各種聲音的爭論。基于軟硬件投資、學習成本的考量,我們希望采用“廉價的”“有前途”的技術方案;根據開源“圣經”《大教堂與集市》中經典理論,“如果有足夠多的beta測試者和合作開發者,幾乎所有問題都會很快顯現,然后自然有人會把它解決”;參考業界實踐派專家的觀點,新技術興衰是社區、企業、用戶之間“戰略、利益、技術、實踐”綜合較量的結果。
基于以上三點,為了全面、發展地看待各方案,首先站在用戶、開發者、外圍支持者的視角,從用戶規模、技術水平、兼容性三個維度,對備選技術進行生態評估;然后篩選出使用廣泛、開發活躍、兼容性好的方案進行技術介紹;最后在方案對比的基礎上,結合應用場景提出相關建議。
2.1 分布采集方案
目前常見的大數據采集技術包括Flume、Kafka、Splunk Forwarder、Logstash、Fluentd、Chukwa、Scribe等,我們該如何取舍?
(1)生態評估
對上述技術生態進行評估如表1所示。
(2)技術對比
根據上述評估,我們選取Flume、Kafka兩種優秀的方案,在技術分析的基礎上,對適用場景及優缺點進行深入分析。
Flume是Apache社區中一款可高效收集、聚合、移動海量日志數據的工具。不同數據源的數據“原油”流經Flume這個“水槽”(Flume單詞的原義),最后匯入數據存儲系統中。Flume工具部署、維護簡單,可根據業務需求進行靈活擴展。
Kafka是一個分布式的消息“發布—訂閱”系統,它作為消息生產者與消費者之間的代理人(broker)解耦了這兩個角色,實現了消息的高效“按需供給”。Kafka 被廣泛用于采集網頁訪問量、網頁內容等活動數據以及服務器CPU 使用率、服務日志等運營數據。
功能方面,上述兩種方案都比較成熟,詳細比較見表2。

表2 備選采集方案功能對比
性能方面,數據采集屬于“I/O密集型”業務,即相比與CPU、內存、網絡流量等因素,系統I/O受限于低效的磁盤隨機讀寫物理性能,更易成為整個采集系統吞吐率的性能瓶頸。Kafka、Flume均支持在內存中進行數據傳輸,此時兩者性能都極高。下面僅討論當數據規模超過集群內存容量,需要進行大量磁盤讀寫操作時的場景:(A)Kafka精妙的設計保證其進行高效的順序讀寫操作,在到達磁盤物理性能瓶頸之前,寫磁盤平均速率隨著輸入數據吞吐率的增加線性增長;(B)Flume在實時性、吞吐率上比Kafka遜色不少,但可通過調整批量處理參數(Batch Size),以增加時延的代價,一定程度上提高吞吐率;(C)兩者都支持通過增加硬件數量的橫向擴展方式,提高系統吞吐率。
(3)應用建議
方案選型時,需綜合考慮業務需求、預算經費、自身技術等因素:(A)當僅需要對服務器訪問記錄、網絡設備告警等運維數據進行采集、分析時,預算充裕的用戶推薦Splunk、Datadog等一站式商業解決方案;有一定技術基礎、想節約預算的用戶可考慮Flume、Logstash;(B)當數據源既有日志數據又有流數據,從方便運維、擴容的角度,建議使用Flume;(C)如果采集數據將被多個業務系統使用、業務實時性要求很高或者需要錯峰、流控時,建議使用Kafka;(D)Kafka與Flume也常常“強強聯合”:一種典型應用將Kafka作為數據源,Flume作為采集代理;此外也可以先部署Flume1.6.0版本采集數據,今后業務有實時性要求時,將Kafka作為一種傳輸渠道(channel),把采集后數據匯入下游存儲系統;此外還可以將Flume采集的數據存入Kafka主題中供業務程序拉取。
具體部署時,需要權衡高吞吐與低時延、容錯性與冗余性這兩對矛盾。例如,通過數據壓縮傳輸、分批次傳輸的方法,以增加時延的代價,降低對系統網絡、I/O等資源的消耗。此外,數據采集過程中也可以嘗試發揮人的作用,例如為準確、及時地采集宏觀經濟數據,Premise公司采用線上線下相結合的方式。其中線下部分鼓勵大眾貢獻各種價格數據,這種眾包方式受到資本青睞。
2.2 高效存儲方案
對海量數據采集、清洗后,我們既要確定采用什么方式將數據長期保存起來,又要考慮以哪種方案組織管理數據以及供業務查詢使用,還得權衡是否需要以內存存儲、管理來提高性能。下文將分別對大數據存儲系統、數據庫技術方案進行評估比較。
(1)生態評估
大數據存儲系統多得令人眼花繚亂,既有云服務商Amazon的 S3、老牌存儲服務商EMC的系列產品和解決方案,又含開源社區的HDFS、Swift、Ceph,還包括高校孵化出的Alluxio。對這些技術生態進行評估如表3所示。
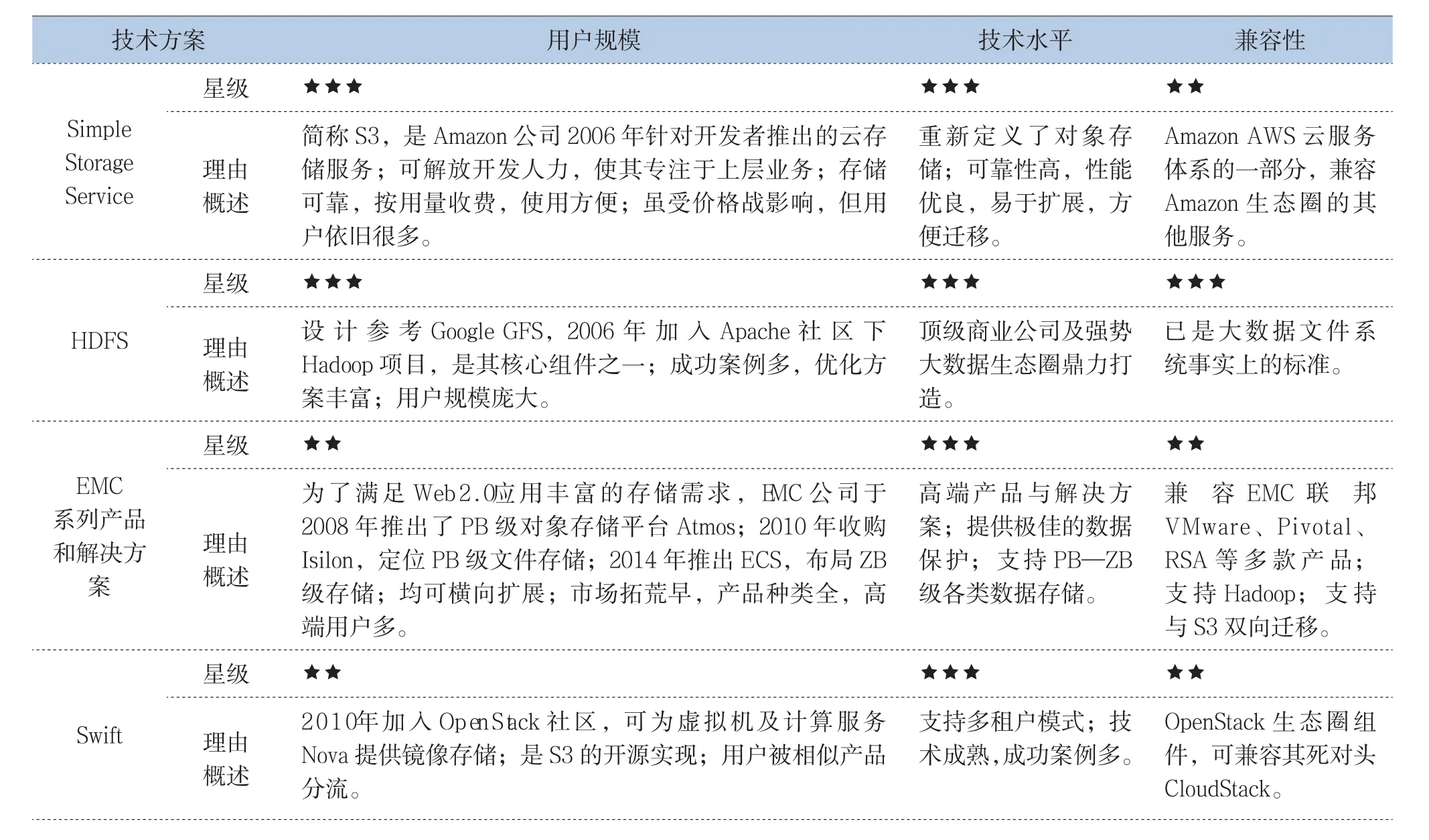
表3 大數據存儲系統生態評估

技術方案 用戶規模 技術水平 兼容性星級 ★★★★★C e p h 理由概述項目開源早(2006年),但穩定較慢(2012年才發布第一個穩定大版本),現由R e d H a t主推;架構有特色,獨一無二地同時支持文件、對象、塊存儲;使用靈活,易于擴展;項目長期不夠穩定,缺少大規模應用案例,用戶觀望多使用少。社區被紅帽公司把持;代碼難懂、耦合過高,質量廣受爭議;成功案例少,待實踐驗證完善。可 兼 容A W S、O p e n S t a c k生態組件;合入L i n u x 2.6.34內核;站在“軟件定義存儲”、“超融合”概念風口。星級 ★★★★ ★★★A l l u x i o 理由概述2013年誕生于A M P L a b(原名T a c h y o n),是S p a r k同門師弟,基因優秀;定位明確,就是為了將海量數據從計算模型中抽象獨立出來;得益于S p a r k生態圈壯大、內存和S S D變得便宜,正迅速崛起。性能優秀;有經典案例參考;比較年輕,部分輔助功能待改進。完善兼 容 H D F S、S 3、S w i f t等底層存儲系統, 及 M R、S p a r k等上層計算框架。
大數據數據庫技術外延更廣。按適用業務場景分為事務型(追求高效讀寫的事務處理能力)、分析型(追求高吞吐、高擴展能力)、兼顧型;按數據存儲模型主要包含關系型、鍵值對型、面向列的、面向文檔、圖形數據庫;按設計原則又分為ACID、C/A/P三選二、兼顧型。典型的大數據數據庫演進及分類如表4所示。
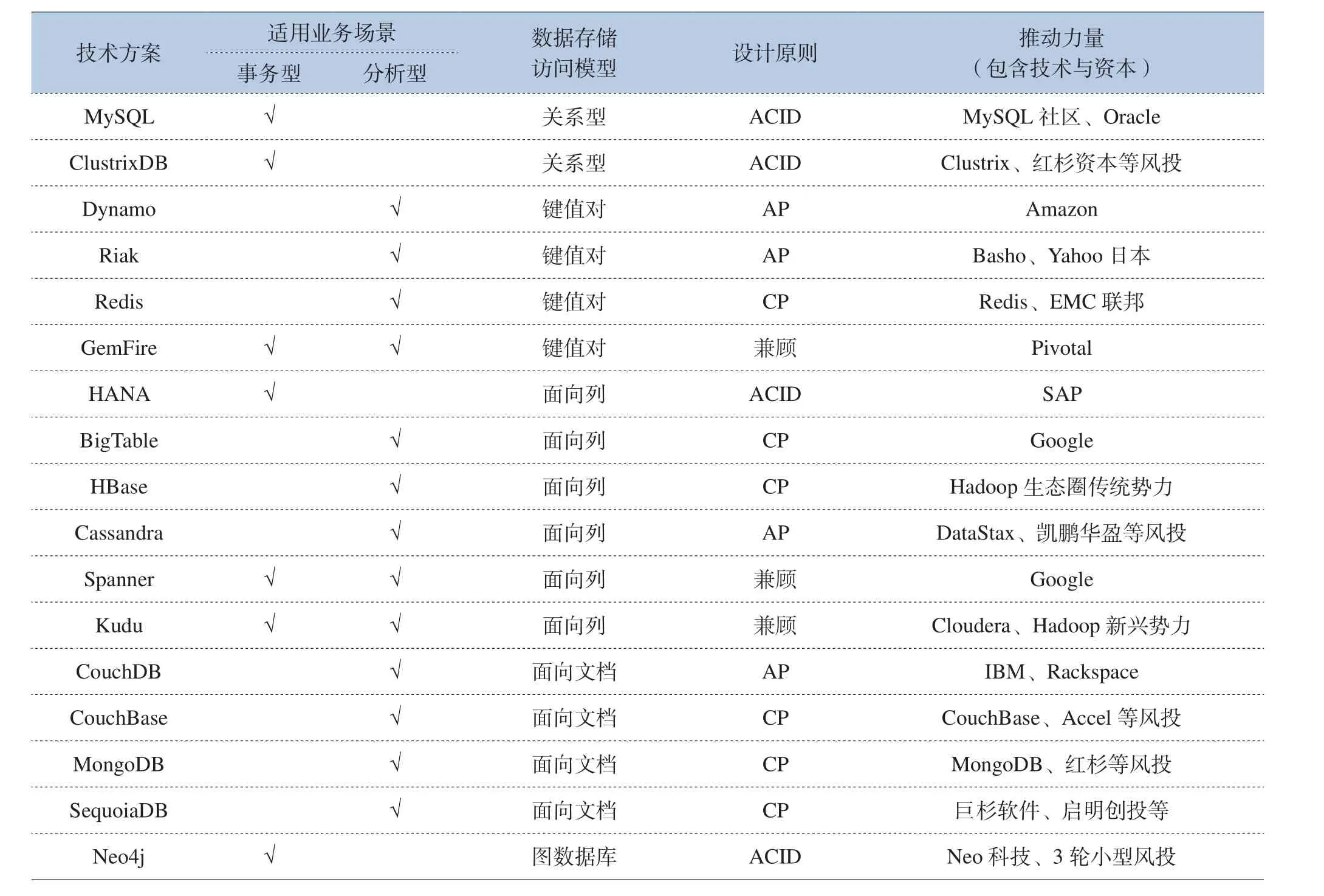
表4 常見大數據數據庫分類
根據上表分類,將選擇具有代表性的擴展MySQL、HBase、Cassandra、MongoDB、Redis、Kudu進行生態進行評估,詳見表5。
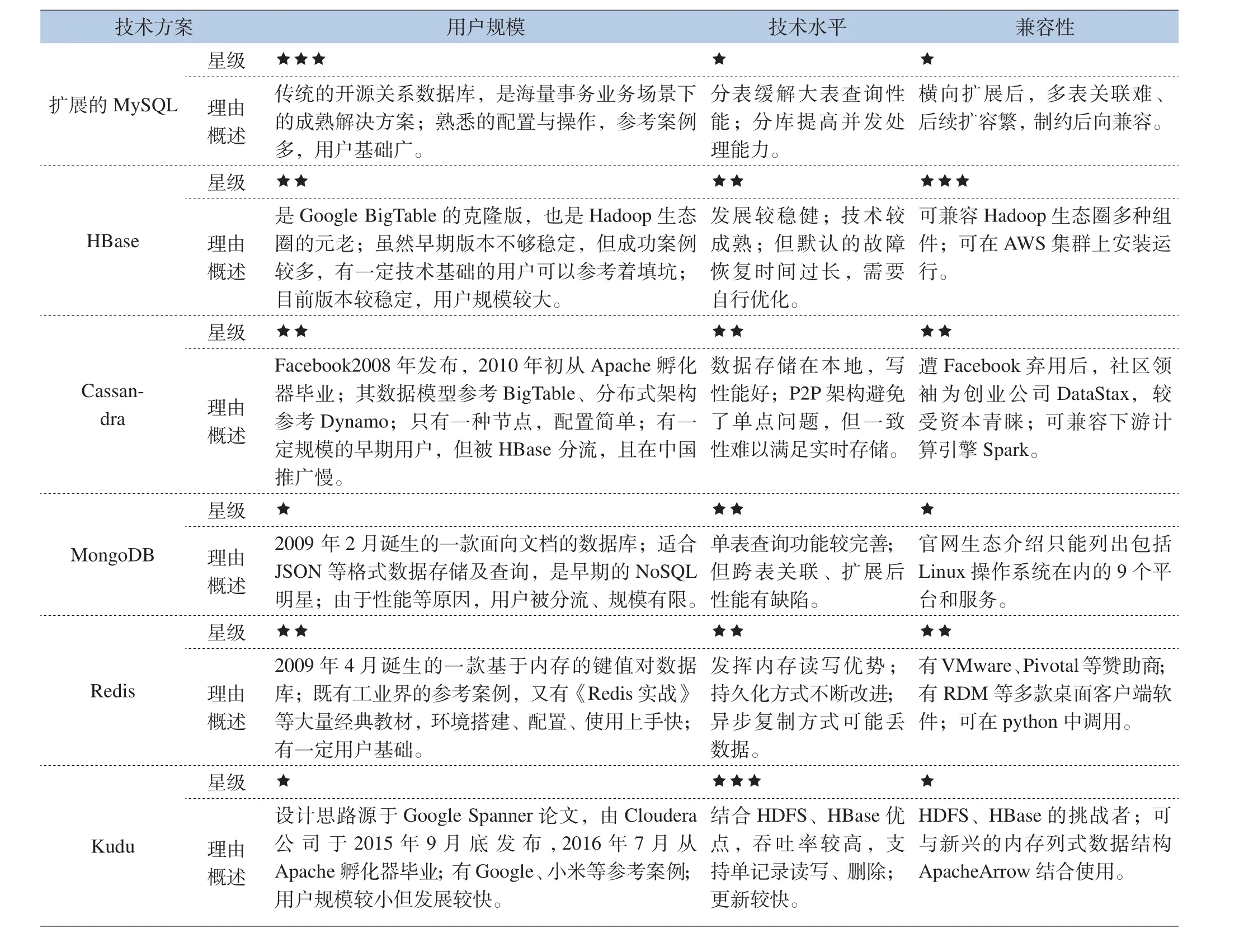
表5 大數據數據庫技術生態評估
(2)技術對比
根據上述評估,將選取S3、HDFS、Alluxio、HBase幾種優秀的方案進行詳述。
S3是Amazon公司AWS云存儲服務的重要組成部分,是對象存儲的典型代表。S3采用扁平的數據組織結構,將對象數據保存在“存儲桶”(Bucket)中,并給用戶提供基于HTTP的REST風格數據訪問、操作接口。該存儲形態能夠方便地進行橫向擴展,以適應大量用戶高并發訪問的場景;但是不支持隨機位置讀寫操作,只能讀取、寫入或覆蓋整個文件。
HDFS起源于Google的GFS論文,是一種易于擴展的分布式文件系統。HDFS基于“移動計算比移動數據更經濟”的設計理念,可構建在大量廉價機器上,節約大量建設擴容投資;另一方面,其具備可靠數據容錯能力,有效減少運營維護成本。HDFS伴隨著Hadoop生態圈的壯大不斷完善,目前已支持Parquet存儲格式,可對嵌套數據進行高效列式存儲,即將合入ErasureCoding糾錯編碼使冷數據冗余成本大幅減少。
HBase起源于Google的BigTable論文,是構建在HDFS之上高性能、高可靠、易擴展的大數據列族式存儲數據庫。其適合存儲海量稀疏數據,可以通過版本檢索到歷史數據,解決了HDFS不支持數據隨機查找、不適合增量數據處理、不支持數據更新等問題。常用于存儲超大規模的實時隨機讀寫數據,如存儲互聯網搜索引擎數據。
Alluxio原名Tachyon,是以內存為中心的虛擬分布式存儲系統。其核心思想是將存儲與計算分離。Alluxio介于底層存儲系統(如HDFS、Amazon S3、OpenStackSwift)與上層計算框架(如Spark、MapReduce、Apache Flink)分離,使Spark等框架更專注于計算,從而達到更高的執行效率。
上述四種大數據存儲方案詳細比較如表6所示。
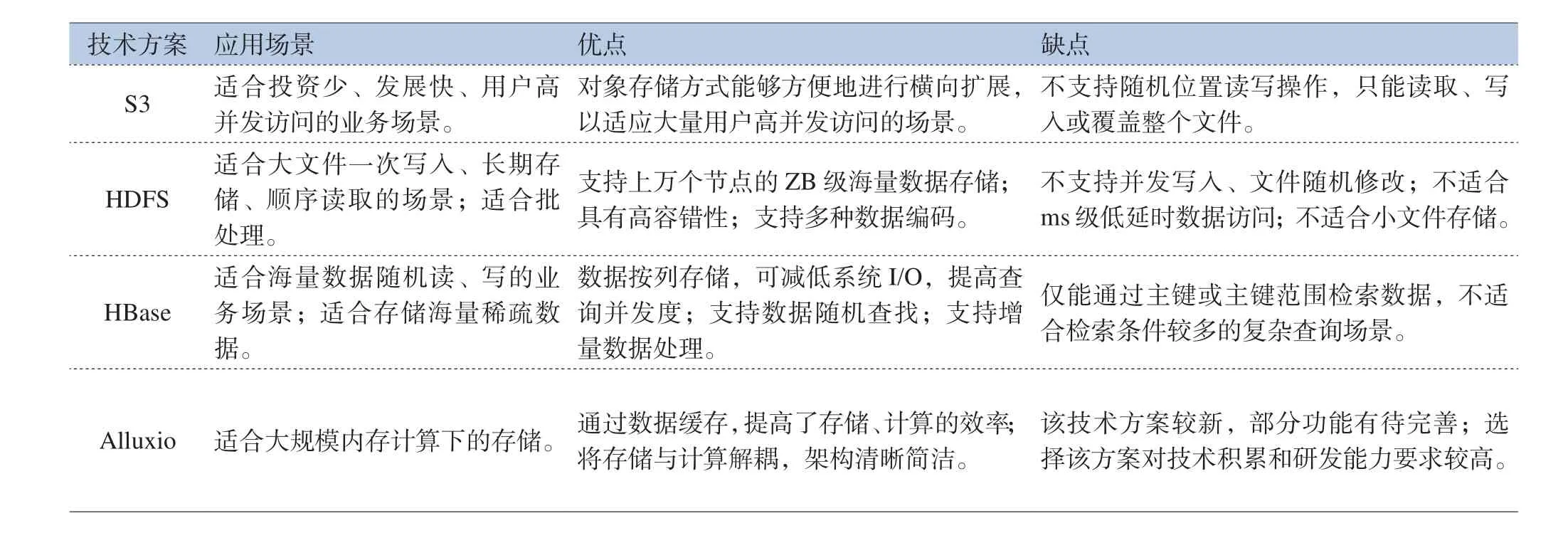
表6 數據存儲方案比較
(3)應用建議
方案選型時,首先需要綜合考慮業務需求變化、原始數據規模、實時分析需求、存儲周期、軟硬件開發及運維成本等因素,再進一步明確存儲方案:(A)對業務中斷時間、業務恢復時長、數據一致性要求都極高的金融等行業,可根據業務量考慮購買EMC、IBM等廠商的存儲軟硬件產品,在此基礎上選擇Teradata、IBM的方案做進一步數據挖掘;(B)對于啟動資金有限、需求靈活多變、規模可能激增的創業公司,建議以“輕資產”的方式運營。可購買Amazon、微軟、阿里等的云服務,集中精力進行業務開發和市場推廣;(C)對于TB數據級別數據,一致性要求不高并且需要進行實時查詢的場景可考慮Redis,一致性高且追求高吞吐量的場景可考慮GemFire。不建議用低性能的CouchBase、Memcached;(D)對于PB數量級存儲、計算、虛擬化服務提供商,建議搭建自己的OpenStack環境,采用Swift、Cinder等存儲方案,以快速滿足定制化需求;(E)對于PB—ZB級別歷史數據、需要進行關聯查詢、批量計算的業務場景,建議搭建Hadoop環境,采用HDFS存儲方案;(F)對于PB級別數據、追求低延遲隨機讀寫的場景,例如對海量網頁數據做進一步提取、修改的,建議采用HBase數據庫。非專家級用戶不推薦在生產環境使用Kudu、Kylin等新興方案。
在此基礎上,根據業務場景進一步選擇合適的存儲模式:(A)如果業務首要考慮數據完整性與可靠性,行存儲具備了天然的優勢,列存儲只有增加磁盤并改進軟件后才能接近該目標;(B)以長期保存數據為主的應用,可考慮寫入性能較高的行存儲模式;(C)需要對大數據做深入挖掘分析的場景,特別是數據源為扁平的關系型數據或者復雜的嵌套數據時,建議使用讀取性能優秀的列式存儲。
具體部署時,可根據自身預算水平、技術能力,選擇服務商一攬子解決方案,集成商負責建設維保,利用開源框架自建自維,在開源代碼基礎上自主開發等建設與維護模式。
3 小結與展望
本文回顧了主流的大數據采集與存儲技術誕生、發展、對抗、衰落的歷史,梳理了其中老牌的商業公司、初創的明星企業、大小的開源社區、學術界、極客之間的糾葛與合作,從生態角度進行了宏觀對比與評估;同時本文選取優秀、通用的方案進行了較詳盡的介紹,并結合具體應用場景給出了技術選型及應用部署的相關建議。
展望未來,物聯網、智能制造等新興產業的崛起,將提供更大規模、更多類型的海量數據源,大數據采集方案將結合更廉價的采集設備、更靈活的組網部署、更有效的數據清洗;同時隨著內存、SSD等高效存儲介質的性能提升,內存存儲技術將進一步發展與普及;業務形態方面,大數據技術將與商業智能、機器學習等新興技術更緊密地結合,采集、存儲等底層技術將隨之進一步演進。
猜你喜歡
保健醫苑(2021年7期)2021-08-13 08:48:02
學生天地(2020年36期)2020-06-09 03:12:30
小學科學(學生版)(2020年5期)2020-05-25 07:11:32
小學科學(學生版)(2020年4期)2020-05-21 07:30:46
小學科學(學生版)(2020年3期)2020-03-25 13:31:22
貴茶(2019年3期)2019-12-02 01:46:32
鄉村地理(2018年3期)2018-11-06 06:51:02
茶葉通訊(2017年2期)2017-07-18 11:38:40
河北城市研究(2015年4期)2015-08-23 11:53:06
浙江工商大學學報(2015年6期)2015-03-01 02:56:40
