基于回歸分析的HIFU 治療子宮肌瘤的消融率預測研究
2020-04-16 11:02:54高立文銀剛張勤黃國華葉方偉
世界最新醫學信息文摘 2020年26期
高立,文銀剛,張勤,黃國華,葉方偉★
(1.超聲醫學工程國家重點實驗室,重慶醫科大學生物醫學工程學院,重慶;2.重慶市生物醫學工程學重點實驗室,重慶;3.超聲醫療國家工程研究中心,重慶;4.遂寧市中心醫院,四川 遂寧)
0 引言
子宮肌瘤是育齡期女性最常見疾病,大約在婦科良性腫瘤中占52%[1]。其臨床表現與肌瘤類型、肌瘤數目、肌瘤大小等相關,常見癥狀為經量增多、經期延長、尿頻尿急、貧血等,但大多數患者沒有癥狀,通常經由體檢發現。目前治療子宮肌瘤的方法主要包括藥物治療、手術治療、其他治療,如子宮動脈栓塞術,超聲消融治療[2,3]。近年來超聲消融治療作為一種非侵入性、保守性治療子宮肌瘤的方法已取得較為滿意的臨床療效[4]。現階段對其術后治療效果的評價一般是通過觀察造影后病灶區體積的變化,但此方法有一定的局限性。而數據挖掘以融合多個學科、匯總多種方法、處理海量數據、挖掘重要信息等特點越來越廣泛地引起了計算機、統計學等領域專家和學者的注意。回歸分析作為數據挖掘技術領域的一種重要算法,從其最初的算法到后來的算法改進以及它在醫學中的應用,都被進行了廣泛深入地研究。將回歸分析應用于HIFU 消融子宮肌瘤病人術后消融率的預測有著速度快,效率高,所建模型穩健性好等特點。通過數據挖掘回歸分析方法可為臨床判斷、選擇合適的治療方案提供決策依據[5]。
1 資料和方法
1.1 資料來源
資料來源于遂寧市中心醫院2014 年到2016 年的單發子宮肌瘤患者的臨床資料。涉及患者的基本信息、MRI 檢查、治療信息三個方面,共計11 項指標。
1.2 臨床數據預處理
首先,對原始數據進行初步篩選,剔除部分有缺失和不完整的臨床記錄,通過篩選剩余907 例。資料中的類型變量采用啞變量賦值,如肌瘤位置(前壁/后壁/側壁/宮底/宮頸)這是一個類型變量,類型變量需要納入計算必須將其轉化為數值。因此,我們為前壁創建一列數據,為后壁創建一列數據,以此類推。然后將每一列分別以0/1 填充(1=yes,0=no)。這表明如果原始列為前壁,那么就會在壁/側壁/宮底/宮頸四列得到0,在前壁這列得到1。本數據中由于宮頸數量很少,因此我們把宮頸這一屬性進行了剔除。
接著,對預處理后的數據進行特征縮放,如本文中年齡范圍在20-50,其對應的肌瘤體積范圍在500-300000 的數據。肌瘤體積一列的數據遠遠大于年齡,而且有更廣的數據范圍。這表明,歐氏距離將完全由肌瘤體積這一特征所主導,而忽視年齡數據的主導效果。縮放特征仍能加速模型收斂。因此,可以在數據預處理中加入。特征縮放不影響最終結果,且包含了標準歸一化等方法。
最后,我們進行了自變量的篩選,由于肌瘤位置在宮頸位置的只有一例,所以把宮頸位置予以刪除。最后一共產生了19 個自變量:對應x1,x2,x3......x19 年齡、身高、體重、粘膜下、漿膜下、肌壁間、前壁、后壁、側壁、宮底、肌瘤體積、高信號、等信號、低信號、混雜信號、治療時間、輻照時間、治療強度、治療劑量,1 個因變量:消融率y。最終數據情況如表1 所示。

表1 數據情況分布表
1.3 研究方法
采用數據挖掘技術中的回歸分析方法在Python 軟件上構建回歸預測模型,對2014 到2016 年907 例的單發子宮肌瘤患者的臨床資料進行回歸分析,并檢測其對子宮肌瘤患者術后消融率的預測準確性。
1.4 回歸分析
回歸分析指的是確定兩種或兩種以上變量間相互依賴的定量關系的一種統計分析方法。其按照涉及的變量的多少,分為一元回歸和多元回歸分析;按照因變量的多少,可分為簡單回歸分析和多重回歸分析;按照自變量和因變量之間的關系類型,可分為線性回歸分析和非線性回歸分析。
在數據分析中,回歸分析是一種預測性的建模技術,它研究的是因變量(目標)和自變量(預測)之間的關系。這種技術通常用于預測分析,時間序列模型以及發現變量之間的因果關系。
回歸分析的主要應用場景是進行預測和控制,例如計劃制定、KPI 制定、目標制定等方面;也可以基于預測的數據與實際數據進行比對和分析,確定事件發展程度并給未來行動提供方向性指導[6]。
1.5 Python 代碼實現
本文將通過Python 機器學習相關工具包實現模型構建和預測,分別是用到:BayesianRidge( 貝葉斯嶺回歸)、LinearRegression( 普通線性回歸)、ElasticNet( 彈性網絡回歸)、SVR(支持向量機回歸)、GradientBoostingRegression(梯度增強回歸)等機器學習模型。
2 結果
2.1 回歸分析預測結果
回歸分析的評估指標采用以下4 個指標來衡量:(1)方差得分(explainedvariancescore),其值取值范圍是[0, 1],越接近于1 說明自變量越能解釋因變量的方差變化,值越小則說明效果越差;(2)平均絕對誤差(Mean Absolute Error, MAE),用于評估預測結果和真實數據集的接近程度的程度,其值越小說明擬合效果越好;(3)均方誤差(Mean squared error, MSE),該指標計算的是擬合數據和原始數據對應樣本點的誤差的平方和的均值,其值越小說明擬合效果越好;(4)判定系數(r2score),其含義也是解釋回歸模型的方差得分,其值取值范圍是[0, 1],越接近于1 說明自變量越能解釋因變量的方差變化,值越小則說明效果越差。本研究建立了5 種回歸模型,各個模型的評估指標得分如表2 所示。
2.2 實驗結果分析
本次實驗使用的數據集屬于小規模、多屬性,單從這一點分析,5 種回歸算法都易于實現、且性能表現良好。綜合表2 的數據中可以看出,SVR 的模型評估得分要明顯優于其他4 種算法,這可能由于:(1)只考慮了每個自變量和因變量之間的關系,而沒有考慮到各個自變量之間的關系;(2)樣本數據分布不均勻,這都是能直接影響預測準確率的原因。而且,根據表2 可以看到,5 種算法的均方誤差也是有差異的,SVR 算法的均方誤差顯然比另外4種算法小。綜上所述,在HIFU 消融子宮肌瘤的消融率預測實驗中SVR 算法效果更好。
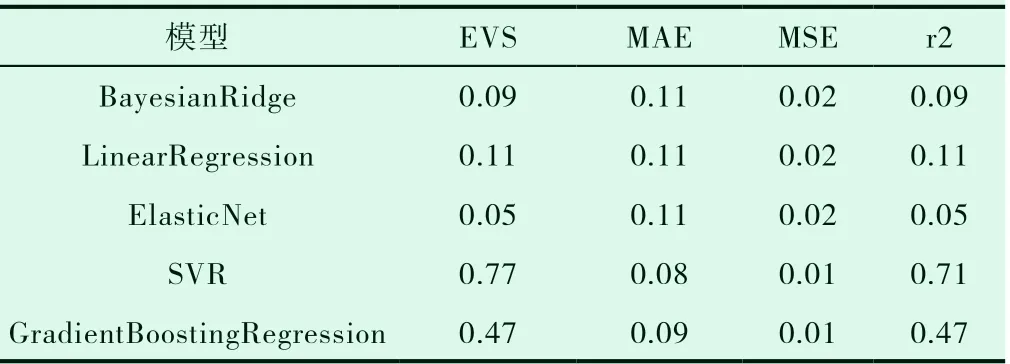
表2 5 種回歸模型評估指標得分表
3 結束語
子宮肌瘤是婦科中最常見的一種良性腫瘤,已經對廣大女性的日常生活造成了很多負面影響。文章利用數據挖掘中的回歸分析算法在海扶醫療股份有限公司醫學服務部提供的子宮肌瘤患者數據進行實驗,從而實現對HIFU 消融子宮肌瘤的消融率進行預測。此次實驗不僅實現了對HIFU 消融子宮肌瘤消融率的預測,還可以對比5 種回歸分析算法,選出最合適的一種。SVR 算法擬合度較高,且均方誤差明顯比另外4 種算法小,因此,在此次實驗中使用SVR 算法效果更佳。
今后主要研究的問題就是在提高SVR 算法效率的同時,尋找更優的算法。如今,HIFU 消融子宮肌瘤的有效性預測是廣受關注的一個問題,未來會有越來越多的研究學者提出更好的算法和方案來解決這個問題,并為醫學中的子宮肌瘤治療提供幫助。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
電力與能源(2017年6期)2017-05-14 06:19:37
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
信息通信技術(2015年6期)2015-12-26 01:16:46
