基于典型樣本的卷積神經網絡技術
2020-04-24 08:55:14李曉莉李曉光
計算機工程與設計 2020年4期
關鍵詞:特征
李曉莉,韓 鵬,李曉光
(遼寧大學 信息學院,遼寧 沈陽 110036)
0 引 言
卷積神經網絡(convolutional neural networks,CNN),是當前圖像分類的主流技術之一。目前,基于CNN的圖像分類常采用多尺寸Pooling提取不同級別特征,或將底層特征和高層特征結合方式,提高分類質量。然而,訓練樣本中包含大量非關鍵區分特征,甚至噪音。現有的CNN訓練方法并未對關鍵特征和非關鍵特征加以區分。如果把含有這些部分的特征向量直接交由分類器,就需要大量訓練樣本才能將這些不重要部分的權重降低,網絡泛化能力才會提高,分類準確率才會達到預期值。
本文提出一種利用典型樣本指導修正CNN訓練的卷積神經網絡模型TSBCNN。同傳統的CNN不同,TSBCNN不再直接采用所有訓練樣本,而是利用典型樣本選取算法從訓練集中選擇一部分有“代表性”的樣本,其包含了類別下的典型特征。TSBCNN利用典型樣本訓練“經驗修正網絡”(HNN)。HNN的作用類似于大腦皮層中上層反饋神經對前饋神經進行關聯、比較的過程。當采用普通樣本進行訓練時,TSBCNN利用HNN強化和修正CNN特征向量,其修正過程可以理解為對原特征向量進行局部強化操作,將具有更高區分能力的特征強化保留,弱化區分能力差的特征,進而達到利用少量訓練獲得關鍵特征,加快模型訓練收斂的同時防止模型過擬合。CNN和TSBCNN的訓練過程如圖1所示。

圖1 CNN和TSBCNN訓練過程
本文主要貢獻在于:①提出一種典型樣本指導修正下的卷積神經網絡模型。給出了神經網絡模型結構以及訓練方法;②提出一種典型樣本選取算法,用以獲得HNN訓練集;③在MNIST數據集上的實驗結果表明TSBCNN具有更好的訓練效果。
1 相關工作
特征在機器學習中起到至關重要的作用,僅僅單純依靠增加特征數量未必會帶來網絡性能的提升。一旦網絡參數龐大,數據量未能達到足夠規模,就會導致學習不充分,無法確保對關鍵特征有效選擇,并且無關冗余特征還會產生過擬合等問題。為了減少這種不利影響,需要進行有效特征選擇,以往研究普遍關注網絡最后的分類性能,對特征篩選這一重要環節的控制往往相對較少。Lu HY等[1]提出了卷積神經網絡增強特征選擇模型,利用一些特征評價方法來確定哪些特征更為重要,有效增強了神經網絡的特征選擇能力并驗證了該模型的有效性。Li H等[2]通過在圖像的顯著度探測問題中,將底層特征作為全連接層后高層特征的補充一起合并到神經網絡中,有效地提高了網絡對圖像中顯著物探測的準確率。高低層特征融合可以在一定程度上增強特征的代表性,但融合特征中仍然涵蓋了大量無用、冗余特征部分。Alexey Dosovitskiy等[4]提出學習通用特征,對隨機采樣的“種子”圖像塊的各種變換形成每個代理類來得到通用特征。通用特征不等于關鍵特征,對網絡訓練速度并未起到提升效果。在監督學習中,Cross-entropy loss和Softmax并沒有促進網絡學習類內更具有辨識性的特征的功能,Weiyang Liu等[7]提出了一個廣義的L-Softmax loss,促進了對類內緊湊、類間可分離性特征的學習,實驗結果表明通過L-Softmax深度學習的特征更具辨識力,同時對4個基準數據集有很好的實驗效果。可見,關鍵重要特征對圖像分類效果有非常重要的作用,因此合理利用這點是有效提升網絡性能的一種重要途徑。
樣本在特征提取階段中占有非常重要地位,訓練樣本是否具有代表性,決定了網絡的學習效果。Huang等[10]提出了一種選取典型樣本與新增樣本結合學習的增量方法,利用初始訓練樣本集訓練得到一個初始模型,然后根據后驗概率對樣本排序,再利用不同規則在各類中選取少量典型樣本。Duan等[11]針對包含少量樣本數據集情況,采用數據增強變換來擴充樣本范圍以提高網絡識別準確率和魯棒性。可見,對樣本的合理有效利用可以在訓練少量樣本的基礎上最大程度地學習到關鍵區分特征。
2 TSBCNN卷積神經網絡
我們認為,CNN訓練中的過擬合、訓練收斂慢等問題的主要原因之一是在每次權值調整中,調整量只與網絡輸出誤差有關。大量的神經科學研究結果表明,大腦皮層存在大量的前饋連接和反饋連接,大腦皮層中每個區域都在不斷在上層的反饋信號和下層的前饋信號間進行比較,也就是說大腦皮層不斷進行歷史經驗信息(反饋)與當前感知信息(前饋)的對比,兩者的交集就是我們所感知的事物。
在人工神經網絡在訓練過程中,如果能夠利用歷史經驗來指導修正訓練過程,根據數據特征區分能力大小,有選擇的訓練,將能夠降低模型過擬性,并提高訓練效率。如圖2所示,MNIST數據集同類數據具有共同重要特征,如圖中圈中區域對于數據區分起到主要作用,而非圈中區域作用較低。目前研究工作中的訓練方法,視數據每個部分同等重要,僅通過誤差傳導來調整權值。如果在訓練時更關注主要特征的學習,則可以大幅降低網絡的過擬,并提高訓練效率。

圖2 數字5及對應強化部分
基于該思想,本文提出一種基于典型樣本的卷積神經網絡TSBCNN。在CNN的基礎上,TSBCNN平行增加了一個前饋輸出修正網絡,這里稱為經驗修正網絡HNN,經驗網絡的輸出為“強化因子”。通過選取少量的典型樣本訓練經驗網絡,以獲得訓練數據的典型先驗特征。在CNN訓練中,利用強化因子,對前饋輸出進行局部強化處理,并根據強化后的CNN輸出誤差來調整CNN前饋層。TSBCNN的網絡結構如圖3所示,包括兩個部分:卷積神經網絡CNN以及經驗修正網絡HNN。HNN輸出Ya對CNN輸出Y0進行強化,強化函數為按位乘積,即Y*=Y0⊙Ya; 對強化輸出Y*利用Softmax進行分類,分類向量為Yout。

圖3 TSBCNN結構
TSBCNN所涉及的公式如下,公式符號描述見表1
Y0=CNN(X)
(1)
Ya=HNN(Xa)
(2)
Y*=Y0⊙Ya
(3)
(4)
(5)

表1 符號描述
3 TSBCNN訓練
TSBCNN訓練分為兩個部分:①選取典型訓練樣本TS,利用梯度下降法訓練HNN;②對全體訓練樣本,固定HNN,訓練CNN。在選取典型訓練樣本時,TSBCNN采用了像素頻度分布直方圖來刻畫數據特征分布,并設計了一個樣本相似度函數用以度量樣本與典型樣本基于特征分布的相似程度。TSBCNN典型樣本選取過程如下:
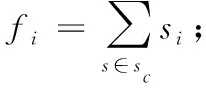
(2)令Hist’為Hist中頻度最大的n′像素位置頻度集合,其中n′=θ*n,θ為自定義截斷閾值參數。這里將Hist’作為典型樣本的特征表達;
(3)對類c中訓練樣本s∈sc, 計算s與Hist’的相似度Sim公式定義如下
(6)
對于給定的相似度閾值參數η, 當Sim(s,Hist’)>η時,將樣本s歸為類c的典型樣本TS。
(4)選取典型樣本數量過少不利于HNN學習關鍵特征,影響后續強化因子的準確性;選取過多會增加網絡訓練總時長。從實驗角度建議典型樣本數不要超過全量樣本的35%左右。
4 實驗與分析
4.1 選取數據集與實驗過程參數設置
本文采用MNIST數據集和HWDB1.1數據集作為實驗數據集。MNIST訓練集共60 000個樣本,其中包含55 000行的訓練集和5000行的驗證集。測試集共10 000個樣本。HWDB1.1中文手寫數據集,包括漢字分類3755種,實驗選用其中最常用的50個漢字作為實驗對象。數據集概況見表2。在MNIST數據集上選取典型樣本過程中,“0”標簽像素頻度直方圖Hist如圖4所示,橫軸表示部分像素位置,縱軸表示圖像二值化累計頻度值。通過兩個閾值參數:截斷閾值參數θ、相似度閾值參數η,并根據式(6)得到該類下所有典型樣本。
實驗分析了TSBCNN在MNIST數據集和HWDB數據集上運行效果,比對TSBCNN與常規CNN準確率以及損失函數的效果差異。

表2 數據集概況
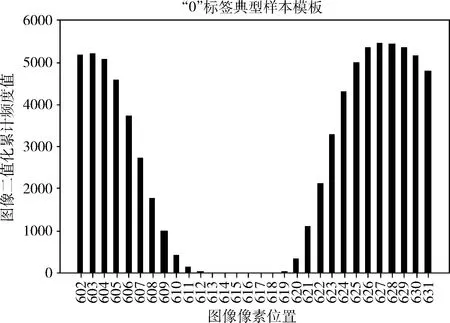
圖4 “0”標簽樣本部分像素頻度分布直方圖
4.2 實驗結果與分析
4.2.1 MNIST實驗結果與分析
TSBCNN與CNN準確率對比如圖5所示,典型樣本數過少會造成HNN經驗網絡對關鍵特征學習不足,影響強化因子準確性,導致收斂過程波動較為明顯,后續 TSBCNN 準確率也不會太高。隨著典型樣本數增加,可以更好地學習關鍵特征,網絡收斂速度明顯加快并且波動很小,準確率不斷提高。當典型樣本數達到2000時,網絡在訓練18次左右時,TSBCNN準確率已達到預期值,網絡收斂速度遠高于傳統CNN。TSBCNN與CNN損失函數對比如圖6所示,最終損失函數收斂速度也明顯高于CNN。MNIST數據集的特點是分類少(10類),樣本多(每類約6000左右),同標簽下樣本區別性不大,樣本關聯性較強,因此隨著典型樣本數的增加,可以更好捕獲樣本的“典型性”。

圖5 MNIST上準確率對比

圖6 MNIST上損失函數對比
4.2.2 HWDB實驗結果與分析
TSBCNN與CNN準確率對比如圖7所示,隨著典型樣本數增加,網絡收斂速度加快并且準確率不斷提高。與此同時,TSBCNN與CNN損失函數對比如圖8所示,隨著典型樣本數增加,損失函數值不斷降低。HWDB數據集的特點是分類多(50類),樣本少(每類約240左右),恰巧與MNIST截然相反。由圖7、圖8可以看出,隨著典型樣本數的增加,雖然網絡準確率得以提高,損失函數值呈下降趨勢,但是二者卻未能達到預期值。原因在于漢字手寫數據集HWDB分類多,樣本少,區別性很大且關聯性不強的數據集,TSBCNN的效果不會高出傳統CNN太多。因此,針對這種類型的數據集可以考慮是否采用TSBCNN 網絡。

圖7 HWDB上準確率對比

圖8 HWDB上損失函數對比
5 結束語
本文主要針對傳統CNN提取樣本特征時會包含大量非關鍵區分特征使得訓練存在模型過擬合、訓練收斂慢等問題,提出利用少量典型樣本來指導修正CNN訓練的卷積網絡TSBCNN,目的是讓CNN在訓練過程中主要學習關鍵特征,進而提高網絡訓練收斂速度并在一定程度上起到減少過擬合作用。在MNIST數據集和HWDB數據集上的對比實驗結果表明,對于數據集中同一類別下樣本較多且樣本之間差異性不大的數據集,TSBCNN網絡有很好的提升效果。對樣本相對較少且樣本個體差異比較大的數據,提升效果并不明顯。未來將進一步研究如何在樣本關聯性不強、樣本差異性大情況下,提高網絡訓練效率以及準確率。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
