基于GPU的軟件雷達信號處理
2020-04-27 10:10:34田乾元徐朝陽
艦船電子對抗 2020年1期
田乾元,徐朝陽,趙 泉
(中國船舶重工集團公司第七二三研究所,江蘇 揚州 225101)
0 引 言
雷達終端接收待處理的回波數據,通過信號處理系統這一重要環節,將龐大數量的回波數據進行脈沖壓縮、雜波抑制、動目標顯示(MTI)、動目標檢測(MTD)、恒虛警率(CFAR)檢測等處理,然后輸出有用的數據或圖像。最近幾年,通信技術、存儲技術的大力發展,使得回波數據量大大增加,數據傳輸速度加快,對數據處理的實時性提出了新的要求。單就MTD的仿真過程,數據吞吐量就達到了GB量級。為了滿足信號處理的實時性要求,雷達信號處理的軟件化十分重要,之前的主流方案一般都采用軟件和硬件耦合緊密的多數字信號處理(DSP)+現場可編程門陣列(FPGA)板實現[1-3]。最近幾年,基于通用計算機平臺的計算機圖形處理器(GPU) 運算能力的提升逐漸可為軟件雷達的實現提供硬件支持[4-6]。GPU具有高并行度、多線程、高存儲器帶寬和強大的算術計算能力,而愈發成熟的統一計算設備架構(CUDA)將GPU傳統的圖形處理能力與應用廣泛的C語言編程相結合,充分發掘了其強大的通用并行計算能力,非常適用于雷達信號處理過程。
1 軟件雷達信號處理系統
如圖1所示,基于GPU的軟件雷達信號處理系統由三大模塊組成:數據讀取模塊,是將接收機處理的基帶數據讀入,讀取報文各標志、讀取回波數據并重組,得到預處理后的回波數據;信號處理模塊是信號處理系統的核心,經過預處理之后的回波數據先經過脈沖壓縮(PC),得到PC數據,然后按照需要進行MTI處理或者MTD處理,在MTD結果的基礎上進行CFAR處理;信號輸出模塊不只是CFAR結果的輸出,還包括信號處理模塊中間過程(類如PC結果),產生的數據可以按照實際需求進行輸出并存儲。

圖1 基于GPU的軟件雷達信號處理系統
2 基于 GPU 的雷達信號處理算法實現
對于信號處理模塊,又包括脈沖壓縮、MTI、MTD和CFAR幾個大致處理環節。以下來說明基于GPU的各個環節的算法實現。
2.1 基于 CUDA 的GPU內存分配方法
CUDA通過核函數利用GPU資源進行計算,而核函數只能讀取GPU內存中的數據,因此對于待處理數據,必須先將其讀取到GPU內存中。GPU有3種常用的不同類型的內存儲器:全局內存(global memory)、本地內存(local memory)、共享內存(shared menory)。shared memory位于片內,讀取速度較快,另外2個為板載顯存。
這里一般使用cudaMallocHost和cudaMalloc語句分別在CPU和GPU的global memory中分配內存,用cudaMemcpy語句進行CPU與GPU的數據傳遞,比如:
float *h_data;
cudaMallocHost((void**)&h_data,1024* sizeof(float));
float *d_data;
cudaMalloc((void**)&d_data,1024*sizeof(float));
cudaMemcpy(d_data,h_data,1024*sizeof(float),cudaMemcpyHostToDevice);
除此之外,還可用cudaMallocPitch語句以二維對齊方式分配二維內存。下文各個處理環節,包括建立窗函數等過程都要用到這里的內存分配方法。在CFAR處理中,還要用到shared memory加快處理速度。
2.2 基于GPU的脈沖壓縮算法實現
脈沖壓縮有時域和頻域2類實現方式。時域上利用有限脈沖響應(FIR)濾波器實現時域脈沖壓縮,處理方法比較直觀。當距離單元數較小時,相對運算量不大,采用時域脈壓處理可以滿足實時性要求[7]。但是當距離單元數很大,時域卷積的運算量很大,這時宜采用頻域脈沖壓縮方法[8]。
本文采用頻域脈壓處理方法,其算法實現如圖2所示。
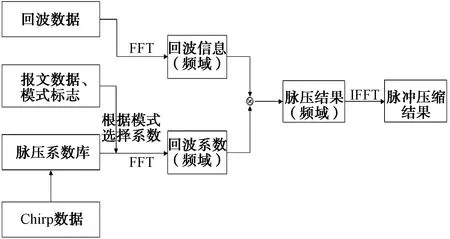
圖2 基于GPU的脈沖壓縮算法
由于發射機的發射波數據和模式可以提前得到,所以提前計算出所有的脈壓系數(可以在計算時進行加窗處理),組成脈壓系數庫(存放于dat文件中)。進行脈沖壓縮時,讀取預處理過的報文數據和模式標志,從脈壓數據庫中選擇對應的系數數據,傳送到GPU內存中,通過建立快速傅里葉變換(FFT) plan進行頻域脈壓系數計算。讀取預處理過的回波數據,同樣做FFT計算。然后將2個頻域數據相乘,得到脈壓的頻域結果,之后進行快速傅里葉逆變換(IFFT)計算,得到脈沖壓縮結果。一維FFT plan建立方法如下:
cufftHandle plan;
cufftPlan1d(&plan,FFT_number1,CUFFT_C2C,1);
除了一維FFT之外還可以創建二維按行或者按列FFT(2種方法計算耗時不同)的plan,調用plan時通過CUFFT_FORWARD或者CUFFT_INVERSE來確定進行FFT還是IFFT,需要注意的是,經過2次N點變換之后的數據比原數據擴大了N倍,如需輸出脈壓數據,需乘以1/N。
2.3 基于 GPU 的 MTI 算法實現
本文采用非遞歸型對消器實現MTI過程,其中,一次對消器的一般結構見圖3,其差分方程為:
yn=xn-xn-1
(1)
二次對消器的一般結構見圖4,其差分方程為:
yn=xn-2xn-1+xn-2
(2)
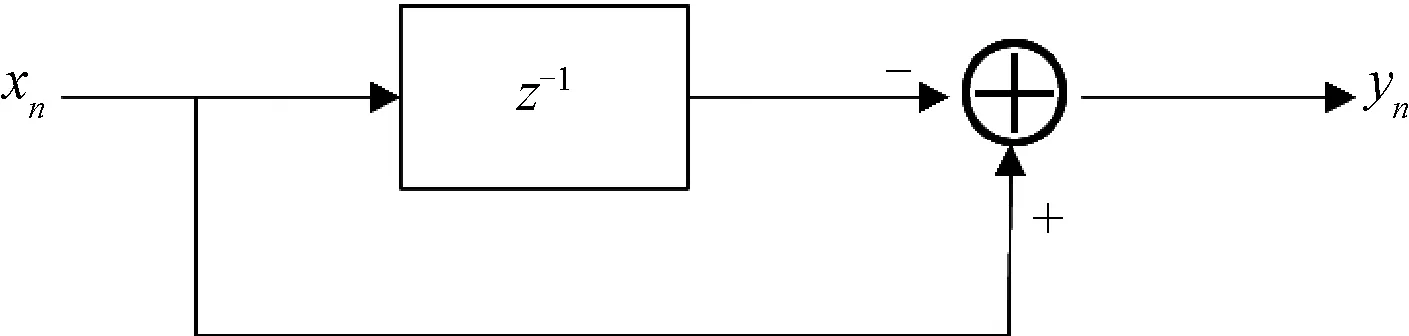
圖3 一次對消器的一般結構
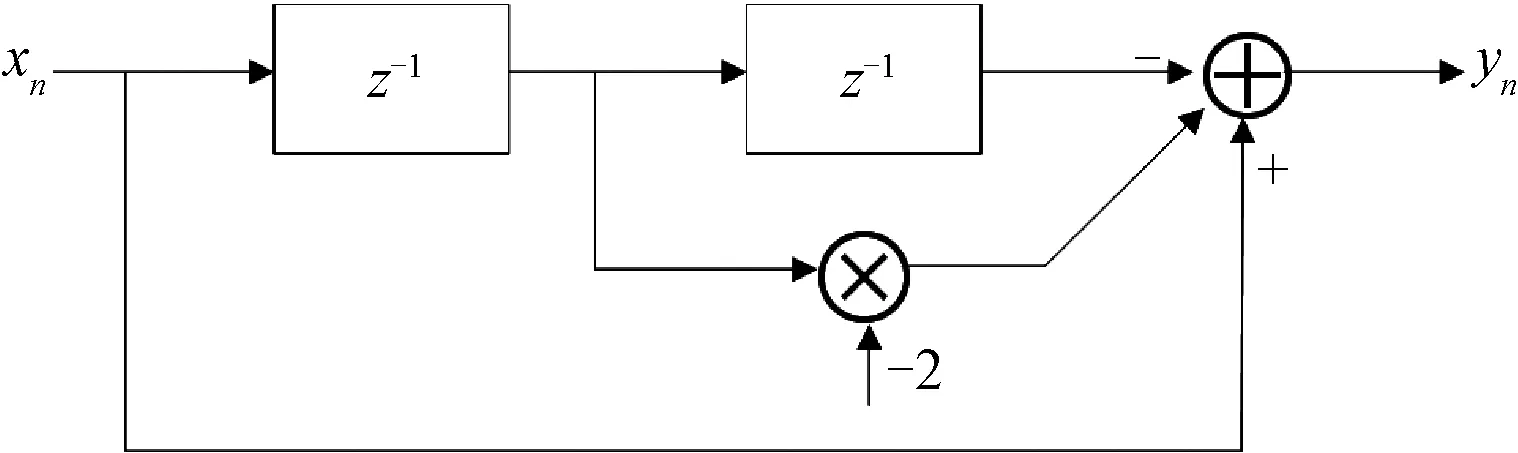
圖4 二次對消器的一般結構
而基于CUDA的算法實現過程為:將脈壓結果存儲為二維形式(可以使用cudaMallocPitch語句),設計核函數構造一次、二次對消器等濾波器,調用核函數處理脈壓數據得到MTI結果并輸出。其算法過程如圖5所示。

圖5 基于 GPU 的 MTI 算法
2.4 基于 GPU 的 MTD 算法實現
為了提高MTD的方位精度,本文采用滑動MTD(SMTD)方法。在方位上每滑過一個脈沖,做一次M點(如16點)的MTD,新進入一個信號,丟掉一個老信號,又進行一次M點的老信號,因此每次MTD處理中均只有1個新信息,M-1個老信息。若一共有N個回波信息(脈沖壓縮之后),每M個信息做一次MTD,那么SMTD之后就剩下了N-M+1個信息。對于每次MTD過程,M個脈壓數據在相同距離門上(多普勒維度)進行M點的加窗FFT,得到M個通道的MTD結果。得到結果后可以對這M個通道的數據取模并取大,為CFAR提供源數據。
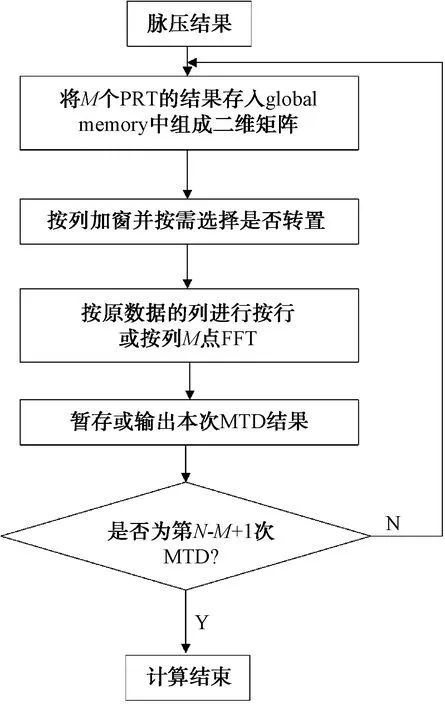
圖6 基于GPU 的 SMTD 算法
圖6為基于GPU的SMTD算法實現示意圖,其中按行或按列進行FFT可以按照如下語句建立plan:
cufftHandle plan;
int rank=1;
int n[rank]={SampleNumber};
int inembed[1]={0};
int onembed[1]={0};
int istride=1;
int idist=SampleNumberF;
int ostride=1;
int odist=SampleNumber;
int batch=PulseNumber;
cufftPlan(&plan,rank,n,inembed,istride,idist,onembed,ostride,odist,CUFFT_C2C,batch);
理國要道,在于公平正直。從黨的十八大提出“進一步深化司法體制改革”,到黨的十九大要求“深化司法體制綜合配套改革”,以習近平同志為核心的黨中央從全面推進依法治國,實現國家治理體系和治理能力現代化的高度,擘畫司法體制改革宏偉藍圖,加快建設公正高效權威的社會主義司法制度。
2.5 基于 GPU 的 CFAR 算法實現
CFAR檢測器有單元平均CFAR(CA-CFAR)、單元平均取大CFAR(GO-CFAR)、單元平均取小CFAR(SO-CFAR)等類型,本文采用的是較為常見的CA-CFAR檢測器。
CA-CFAR 的自適應門限值取決于雜波和目標距離門附近的噪聲。待檢單元(CUT)兩邊的N個單元組成參考窗(CFAR window cells),對其回波信號進行采樣,將待檢單元的輸出與由參考單元輸出總和所得到的自適應門限相比較并進行判決。一般將緊臨 CUT 的單元設為保護單元(Guard Cells),在計算門限值時不將其列入計算之中來減小誤差。CA-CFAR算法如圖7所示。
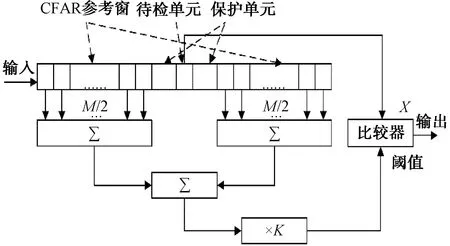
圖7 CA-CFAR算法
基于GPU實現CFAR過程,在代碼上是緊接著SMTD過程的。SMTD每得到1次MTD結果,取MTD結果的模值,將數據在距離門維度上取M個模的最大值,這樣每M組數據結果就得到了1組數據,以此作為CFAR的源數據。
由于CFAR過程會頻繁訪問同一回波數據,2.1中提到的global memory訪問速度較慢,計算效率較低,因此將待用數據寫入到shared memory中,減小不必要的時間開銷,從而提高計算效率。在計算閾值時,由于窗長取值一般為 2 的冪次,故采用歸約求和算法,將求和過程變為多層多線程并行求和[9]。CFAR過程可以從GPU的內存特點和計算特性進行優化,此處不再展開。本文的基于GPU的CFAR算法過程如圖8所示。
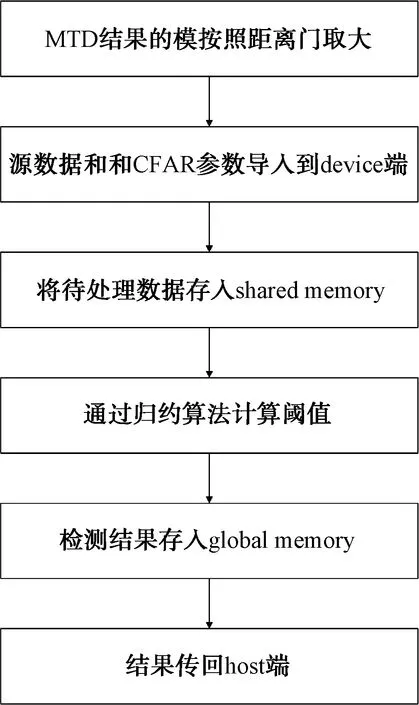
圖8 基于GPU的CFAR算法
3 基于GPU與基于CPU的雷達信號處理仿真實驗及結果對比分析
某警戒雷達基于傳統CPU平臺,其信號處理過程采用C++編程,通過調用Intel Math Kernel Library加快計算效率。本文對其與本文采用的基于GPU平臺的雷達信號處理進行性能比較。
在 GPU 與 CPU 上分別實現雷達信號處理的脈沖壓縮、MTI、MTD和CFAR處理過程,源數據相同,計算兩者處理結果的誤差,同時對比兩者的計算時間,以分析 GPU 算法實現的準確度和計算效率。CPU端使用Intel(R) Math Kernel Library(Version 2017.0.31)進行計算。開發計算機采用的顯卡 GPU 為 NVIDIA GeForce GTX1060,CPU 為Intel Core(TM)i5-8300H 2.30 GHz,操作系統為Deepin 15.11。

圖9 基于GPU的雷達信號處理仿真實驗結果
圖9為同一仿真源數據GPU平臺的處理結果。
分析圖9可以得出結論,基于GPU的軟件雷達信號處理系統在仿真實驗中完成了脈沖壓縮、MTI、MTD任務。實驗數據也表明CFAR檢測結果正確。之后將基于GPU的檢測結果與基于CPU的雷達信號處理計算結果進行比較,以CPU計算結果為基準(認為是絕對真實值),繪制GPU平臺下脈沖壓縮、MTI、MTD的絕對誤差圖。
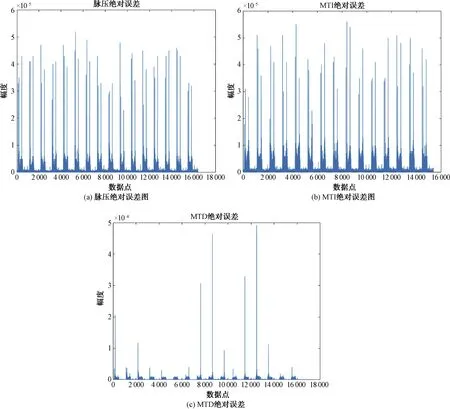
圖10 基于GPU與CPU的雷達信號處理仿真實驗結果誤差
由圖10分析可知:基于GPU的處理結果與CPU相比誤差極小,脈壓絕對誤差小于5.5×10-5,MTI絕對誤差小于6×10-5,MTD絕對誤差小于5×10-4,而對于這3個過程來說,目標或者說是有用數據一般大于1,因此相對誤差最大不超過上述對應數值。因此,基于GPU的軟件雷達信號處理系統計算結果具有較高的準確度。
分別進行100次仿真實驗,記錄GPU和CPU處理實現各個功能的平均時間,得到結果如表1所示。
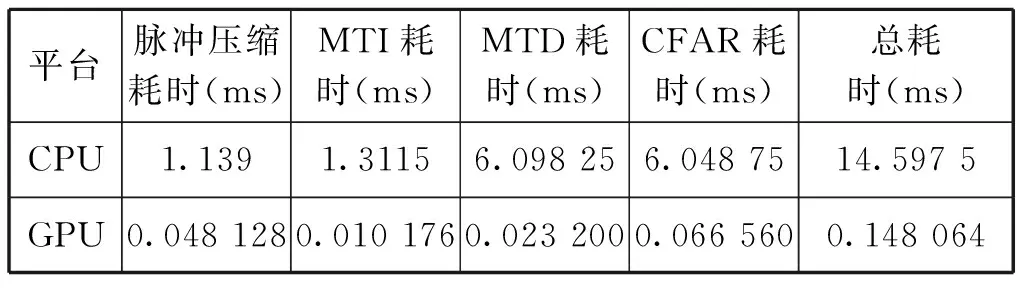
表1 基于GPU與CPU的信號處理仿真實驗計算耗時
表1為2種平臺下實現信號處理的計算耗時,顯然基于GPU的方法計算耗時要少得多,將CPU耗時除以GPU耗時,繪制GPU算法相較于CPU算法的效率提升折線圖,如圖11所示。
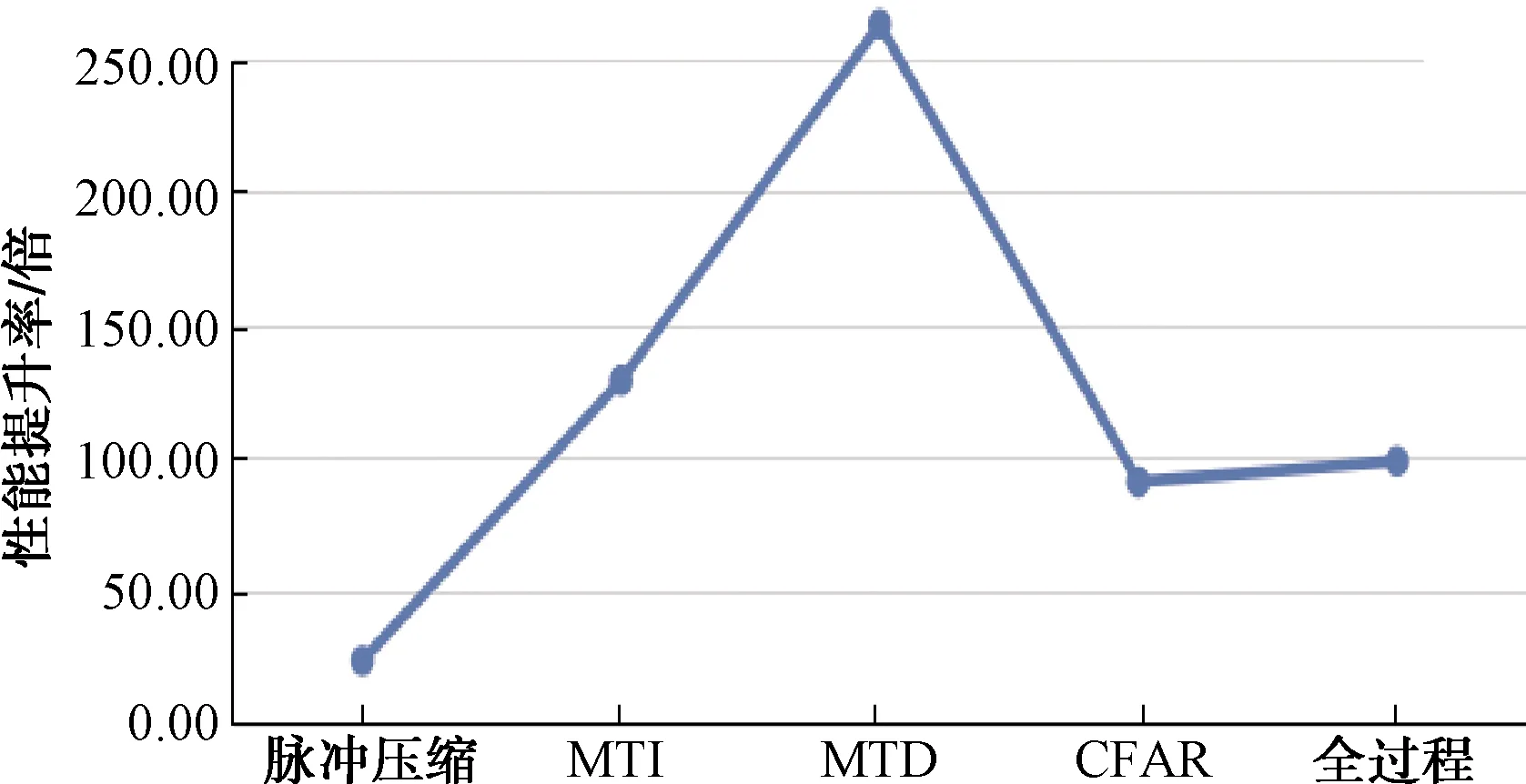
圖11 基于GPU的算法對比CPU算法的計算性能提升率
圖11表明基于GPU的軟件雷達信號處理系統相較傳統CPU平臺的處理方式在計算性能上有巨大的提升,尤其是MTD模塊更是達到了262倍的效率提升,總體的平均提升率也在100倍左右。而且因為本文做的是仿真實驗,數據量受限,實際應用過程中的回波數量遠遠大于本次仿真的數據量,對于GPU的計算能力來說,仍有較大的提升空間。
4 結束語
本文闡述了基于GPU的軟件雷達信號處理系統的結構以及各個信號處理模塊的實現原理,通過仿真實驗,對比了GPU平臺(CUDA架構)和CPU平臺(調用MKL庫)下雷達信號處理的結果正確性、結果準確度和計算性能。結果表明:GPU平臺下的雷達信號處理結果與CPU下的結果在數值上幾乎完全相同;而在計算耗時方面,GPU平臺下算法的計算效率是CPU平臺下的100倍左右,在某些信號處理環節上計算效率更高。由于仿真實驗的條件受限,數據量較小,并沒有發揮出GPU的全部性能。實際應用中待處理數據(如回波采樣點數、PRT數量)會更加龐大,利用GPU實現雷達信號處理將獲得更大的吞吐量。因此,GPU平臺下的雷達信號處理與傳統雷達采用的CPU相比,計算結果準確,計算效率更高,更能滿足現代雷達信號處理的大吞吐量和高實時性要求。
