輔助車道線檢測的端到端自動駕駛
2020-05-03 13:54:12閆春香陳林昱王玉龍劉文如
汽車實用技術 2020年7期
閆春香 陳林昱 王玉龍 劉文如


摘 要:基于深度學習的端到端自動駕駛有著簡潔高效的優勢,尤其在車道保持上有著良好表現,但是面臨路況復雜時存在極大的不穩定性,表現為車輛偏離車道現象。針對此問題,文章首先在虛擬環境下利用神經網絡可視化方法分析了車道偏離的原因,然后在方法上將方向盤轉角序列作為神經網絡輸入,同時根據車道線檢測的方法求出車輛所在車道的面積作為輔助任務。文末分析對比了文章方法和遞歸神經網絡(RNN,LSTM)方法在平穩性上的差異,最后通過虛擬實驗和實車實驗驗證文章中的方法的有效性。結果表明,本文中的方法能有效改善車輛行駛平穩性問題,和LSTM方法相比穩定性效果相近,但本方法操作應用簡單,節省計算資源。
關鍵詞:端到端;神經網絡;自動駕駛;序列;車道線檢測
Abstract: End to end self-driving has drawn increasing attention due to its simplicity and efficiency. Especially, this approach has achieved good performance in lane following. But its safety is still a concern with existing problem like sudden lane departure under complex road conditions. In view of this problem, firstly, we analyze the example accounted for such decision making problem by visualizing attention. Secondly, advocate sequences of steering angles as the input to Convolutional Neural Network(CNN), then, calculate the road area of the car in its lanes using lane detection as auxiliary task.Meanwhile,the contrast difference of stability is analyzed compared to the recurrent neural network in deep learning(RNN,LSTM). Finally, the results show that this method enhances the stability closed to LSTM and computation -ally efficient verified by virtual and real vehicle test.
1 背景
車輛在行駛中面臨的環境場景非常龐大且復雜,自動駕駛算法通常根據人為編寫規則,建立一套復雜規則系統來應對多變復雜的環境。相對于此,端到端自動駕駛算法有著結構簡單、成本低廉的優勢,用深度學習網絡[1]模仿人類駕駛行為來替代復雜的規則系統,是近幾年的新興技術。
英偉達在2016年提出應用CNN網絡,由車輛實時拍攝的圖片輸入直接映射到方向盤轉角輸出[2],利用端到端的方式實現了車道保持任務。端到端的技術實際上在數十年前已經有所應用[11],但是可以實現的功能較為單一,對于復雜場景難以處理。長短時記憶網絡LSTM[3,4,5]可以存儲過去的部分記憶,改善CNN在時序問題上的表現,在自動駕駛上也開始廣泛應用。論文[3](BDD)建立一個300小時的視頻數據集,提出了FCN+LSTM[4]方法,該網絡先通過全卷積網絡提取圖像的特征,然后通過長短時記憶網絡(LSTM)將當期的特征和之前的特征融合,共同預測車輛下一個行為動作,比如左轉右轉直行等等,但是網絡輸出只包含車輛的方向盤控制,沒有對于車輛速度的控制。論文[6]把車輛周邊360度的信息進行融合,該方法的缺點是需要同步多個傳感器間的信息,并且整個網絡計算耗時較長。論文[7]用CNN和LSTM并行處理圖像輸入,兩個網絡分別負責獨立的任務,CNN負責預測方向盤轉角,LSTM負責預測速度,實現了對車輛的橫縱向控制。
除了上述加入LSTM的方法外,許多論文提出了不同的CNN網絡結構創新,比如引進輔助任務。輔助任務是為了使網絡模型可以關注車輛行駛過程中人為認為需要額外關注的要素,以此來改善自動駕駛表現。通過在訓練方法上做改變,例如把語義分割[3],物體檢測[8]等作為輔助任務,這樣的多任務學習方式可以提升神經網絡的學習能力[9,10]。輔助任務的引入,使得模型強化了對于指定交通場景特征的關注,其缺點是需要大量的人工來標注場景元素。
經過上述分析,在提高自動駕駛技能方面,在CNN架構及CNN+LSTM架構上都有各種不同架構及應用,由于LSTM比CNN可解釋性差,且其網絡結構復雜,數據處理繁瑣。對此,本文提出輔助車道線檢測的端到端自動駕駛,最后實車上進行了測試。
2 方法介紹
2.1 卷積神經網絡結構
端到端自動駕駛模型訓練的數據集只需要采集人類駕駛行為的數據,將原始數據輸入神經網絡直接映射輸出駕駛控制指令數據(目標方向盤轉角、油門、剎車)。本文首先采用CNN架構測試了車道保持的情況。
本文利用resnet50作為基模型,通過回歸計算方式輸出預測方向盤轉角值及速度值。在行駛時預測僅使用中間攝像頭作為輸入。
在測試中發現,車輛在行駛過程有預測方向盤轉角值的突變導致駛離正常車道后現象,在GTAV模擬環境下重現該現象,并進行分析,見2.2。
2.2 可視化
在GTAV的虛擬環境下,采用resnet50模型重現了車輛突然駛出路面現象,得出車輛沖出路面時的方向盤預測轉角和上一幀相比,出現較大的突變。本文對該時刻神經網絡模型的關注點進行了可視化分析[5,12],具體方法如下圖2。輸入圖像3通道大小為224*224,經過卷積層CONV1的處理后輸出64通道大小為112*112 map圖,CONV2_x到CONV5_x是帶有殘差結構的卷積block。從最后一層逆向計算,使用平均池化的方法對輸出特征圖每個通道進行加權并反卷積點乘上一層的map值,最后獲取到的結果轉化為熱力圖的形式疊加到原始圖像上。
圖3是可視化結果,a(1)是正常行駛場景圖,a(2)是其對應的神經網絡關注點熱力圖,可以看出a(2)能正確的關注到車道線;b(1)是車輛沖出正常車道的場景圖,b(2)是對應的關注點熱力圖,從可視化效果的熱力圖看,神經網絡把紅框內的木頭錯認為車道線。
2.3 網絡架構
網絡設計基于數據輸入及損失函數兩個方面,將歷史數據作為輸入解決序列問題,在損失函數上將車輛駛出車道線的情況給以懲罰。
2.3.1 方向盤轉角序列
駕駛行為是一個時間上連續的序列行為,下一時刻的車輛駕駛控制通常是基于上一次的狀態結果微調。神經網絡在處理時間序列問題上,目前多是采用CNN+LSTM的方法,但是該方法的訓練和預測均比單獨的CNN網絡復雜,同時在預測時LSTM網絡的運算資源消耗也較大,在序列長的情況下,預測耗時較長,而在序列短時雖然計算耗時較短,又難以保證效果。本文在序列行為問題上采用歷史序列幀的狀態作為模型輸入來解決。
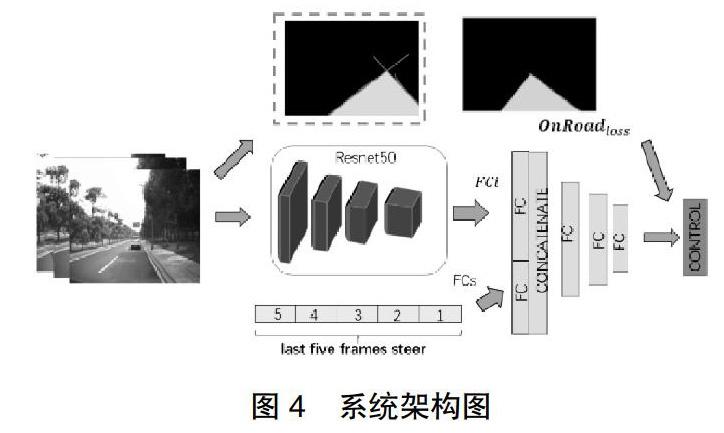
本文所述模型架構如圖4所示,輸入為攝像頭拍攝的圖像,經過CNN(Resnet50)網絡提取圖像特征,輸出全連接層FCi,FCi層輸出為1024個神經元。前5幀的歷史方向盤轉角值首先轉換為one-hot形式,然后與FCi連接起來構成一維數組,經過一次全連接變換FCs輸出的大小為256,將FCi和FCs連接,共1280個神經元,并在后方增加三層全連接層,全連接層輸出的神經元個數分別設定為512、256、50。根據實驗結果,作為輸入的歷史幀數設置5幀是比較合適的選擇。
2.3.2 懲罰函數
為了降低神經網絡預測難度,在訓練回歸預測中引入車輛偏離車道的懲罰損失函數。
首先利用已知的車道線檢測模型識別出當前車輛所在車道線,車身左右兩邊的車道線在遠方形成交叉點,構成圖4中OnRoad所示的黃色區域。若無形成交叉點,則取車道線的線端兩個坐標點,根據直接方程式y=kx+b構成直線,如此,和圖像底部構成封閉區域。在直行路面,當前車道線所構成的區域通常呈銳角三角形,若在道路彎曲路面,則通常呈現圖4虛線框內效果圖。
其次求出黃色封閉區域在整個圖像面積中占比,見公式(1),w×h表示圖像寬和高,σ (i,j)表示在二值圖中非0的值。由此,當車輛沖出正常車道時,車道面積和背景圖的重疊率幾乎為0。
最后偏離車道時的損失函數定義為lOnRoad=1-lRoad,當lRoad值越小時說明車輛已偏離當前車道,反正lRoad值較大是說明車輛在正常車道行駛。
大多的車道線輔助任務的方法是在訓練時使得訓練模型同時關注車道線信息,需要大量人工標注車道線的信息。本文所述的輔助車道線檢測的方法,將車道線檢測任務和模型預測任務分開進行,車道線的識別方法可以使用機器視覺的方法或深度學習的方法,不需要對所有參與預測模型訓練的大規模數據集標注車道線,從而避免了大量人工標注。
2.3.3 損失函數
本文的損失函數由方向盤轉角損失函數、速度損失函數和2.3.3章節所述的懲罰函數三部分構成,見公式2,其中給以方向盤轉角損失函數系數配比為2。
θt表示當前t時刻預測的方向盤角度,θlt表示t時刻的方向盤轉角真值。St表示當前t時刻預測的速度,和方向盤轉角不同的是,速度的label是取5幀后的值,即Sl(t+5)表示t時刻向后5幀圖像對應的速度真值,具體設定需根據本車的整體系統響應周期進行設定。
方向盤轉角和速度的預測采用均方誤差MSE損失函數作為回歸預測,見公式3,MSE越小表示預測值和真值越接近。
yi為訓練時batch中第i個數據真值,yi'為神經網絡預測的值,在本案例中,y對應為方向盤轉角θ和速度s。
2.3.4 模型輸入輸出
圖像輸入處理:模型輸入的圖像數據為前向3個攝像頭所采集的數據,每個攝像頭的圖像數據都是單獨作為神經網絡的輸入。將它們都縮放到同樣的尺寸224x224,并按照image/127.5-1的方法歸一化預處理。
Label處理:方向盤轉角label按照steer/steermax的方式歸一為(-1,1)之間的浮點數,速度label按照speed/speedmax的方式處理為(0-1)之間浮點數。
方向盤轉角序列輸入處理:FCs處輸入的方向盤轉角值用one-hot編碼形式輸入,one-hot編碼分類設定為200,將5個編碼值形成數組大小為1000(200*5)的一維數組。
輸出:采用均方誤差回歸預測輸出方向盤轉角值和速度值。
3 實驗驗證
使用廣汽GE3車型進行實車改造,在廣州生物島進行實車測試,多次測試結果表現,繞行一周(7KM),人工干預次數一般在2次以內甚至無需人工干預,干預次數表現基本上和CNN+LSTM方案相當,而僅僅采用resnet50基礎模型測試時,很難做到無人工干預。
圖5是完全沒有參與訓練的廣州大學城部分路段的離線測試結果,測試對象為方向盤轉角,其中藍色線是模型預測的方向盤轉角值,橙色線是測試車輛行駛實際轉角值。
圖5(a)是2.1所述的CNN結構離線測試結果,圖中紅圈2之前的路段存在大量連環彎道,全路段有路邊停車,及來往車輛數量高于5。紅圈1、2、4、5為三岔口,由于CNN預測為離散信息,所以在三岔口有不同的表現,紅圈3是提前轉彎,轉彎半徑較小。圖5中(b)是cnn+SeqRoad的方法離線測試圖,整個趨勢吻合。圖5中(c)是CNN+LSTM離線測試圖,趨勢和(b)接近,但是在轉彎半徑較大的大彎處表現的力度有所不足,如圖(c)中所圈出的1、2、3處。
(a) cnn結構離線圖 (b) cnn +SeqRoad結構離線圖 (c)cnn+lstm結構離線圖 (d)實車測試車外視角 (e)實車測試車內視角
表2為對應的均方根誤差對比表,同一批數據集下RMSE值越小其效果越為理想,本文方法明顯優于單純的CNN的表現,而LSTM在大彎道處理表現轉彎力度不足。
4 結論
針對端到端自動駕駛中可能出現的車輛突然偏離正常車道這種極其危險的行為,本文提出了輔助車道線檢測的端到端自動駕駛,能夠較為有效的解決上述問題。車道線檢測輔助任務不是在訓練中同步完成,而是作為獨立任務,避免了大量的人工標注,省時節力。和CNN+LSTM方法相比,本方法結構簡單,訓練和測試迭代速度快,且測試效果較優。目前本方法能在開放道路的車道保持上有著較好的效果,但仍存在部分問題需要進一步研究,比如動態繞障、換道并線表現不佳等問題。
參考文獻
[1] Deep learning. Y.LeCun, Y.Bengio, and G.Hinton, 2015.
[2] End to end learning for self-driving cars. M.Bojarski, D.D.Testa,D. Dworakow ski,B.Flepp,P.Goysl,etc,2016.
[3] End-to-end learning of Driving Models from Large-scale Video Datasets.H.Xu,Y.Gao,F.Yu,and T.Darrell,2017.
[4] Long short-term memory recurrent neural network architectures for large scale acoustic modeling. H.Sak, A.Senior, and F.Beaufays, 2014.
[5] Deep steering:Learning end-to-end driving model from spatial and temporal visual cues. L.Chi, Y.Mu,etc. 2017.
[6] End-to-End Learning of Driving Models with Surround-view Camers and Route Planners. S.Hecher, D.Dai, L.VanGool,etc. 2018.
[7] End-to-end Multi-modal multi-task Vehicle Control for self-Driving Cars with Visual Perceptions. Z.Yang, Y.Zhang, J.Yu, J.Cai, J.Luo, 2018.
[8] Object detection networks on convolutional feature maps. S.Ren, K.He, R.B.Girshick,X.Zhang,and J.Sun, 2017.
[9] Learning affordance for direct perception in autonomous driving. C.Chen, A.Seff, A.Kornhauser, and J.Xiao, 2015.
[10] Learning End-to-end Autonomous Driving using Guided Auxiliary Supervision. A. Mehta, A. Subramanian, 2018.
[11] Off-road obstacle avoidance through end-to-end learning. U.Muller, J.Ben, E.Cosatto, B.Flepp, and Y.LeCun,2006.
[12] VisualBackProp:visualizing CNNs for autonomous driving. M. Bojarski, A.Choromanska, K.Choromanski,B.Firner,etc, 2016.
