基于主題模型的胸部X光片診斷報告異常檢測方法*
2020-05-04 06:54:02尤誠誠馮旭鵬劉利軍黃青松
計算機工程與科學 2020年4期
尤誠誠,馮旭鵬,劉利軍,黃青松,3
(1.昆明理工大學信息工程與自動化學院,云南 昆明 650500;2.昆明理工大學信息化建設管理中心,云南 昆明 650500;3.云南省計算機技術應用重點實驗室,云南 昆明 650500)
1 引言
隨著醫院影像報告管理系統的廣泛應用,我國各級醫院產生并且保存著大量的胸部X光片及其對應的診斷報告。胸部X光片是常規體檢的檢查項目之一,已經成為胸部檢查的優先選擇,它能快捷、清晰地對胸部的大體情況包括肺、心臟等器官進行觀察。胸片診斷報告有著重要的應用價值,它不僅能對可能發生的疾病提前預警,還是臨床醫生制定治療方案的重要參考依據。診斷報告核心的內容是影像描述和診斷結論,這兩部分是輔助醫生診斷和患者治療的重要參考,也是用于診斷報告異常檢測的關鍵信息。醫生書寫診斷報告具有相當大的主觀性,有可能會因為經驗不足或疲勞而產生影像描述內容的解讀錯誤[1],使一些疾病被漏診、誤診。另外診斷報告中影像所見部分描述自由,多為醫療慣例描述語言,復雜的影像描述內容也可能影響醫生的鑒別診斷,得出錯誤的診斷結論。篩選出這些異常的診斷報告,首先可以減少疾病誤診率,為臨床醫生的診斷治療提供更準確有效的參考。其次,為建立規范化的醫療檢查體系和實現高效精準的醫療服務提供了基礎。最后,可增強醫院的管理水平,監督考察醫療工作者的技術素養。所以,對診斷報告進行異常檢測方法的研究意義重大。本文以胸部X光片診斷報告為研究對象進行診斷報告異常檢測的研究。
傳統的異常檢測方法都是為了找出不滿足規則和期望的樣本[2]。目前在醫療領域出現了大量的異常檢測方法用于檢測醫療保險記錄、醫療處方等醫療數據。有監督的異常檢測方法,首先通過大量高質量的人工標注數據,利用傳統的分類方法找出異常數據。Kumar等[3]用SVM的方法檢測醫療索賠數據的記錄錯誤。Rawte等[4]結合監督和無監督的方法來檢測醫保欺詐。無監督的異常檢測方法,通過計算離群點發現異常的數據樣本。崔書華等[5]通過離群點檢測方法對異常數據進行分析。高永昌[6]提出一種基于異構網絡社區離群點檢測的醫生欺詐發現方法。Segaert等[7]證明了穩健回歸和離群點檢測是處理高維臨床數據(如omics數據)的關鍵策略。丁可[8]提出一種基于狀態轉移矩陣的便攜式醫療設備通信異常數據檢測方法。Hawking等[9]基于k近鄰方法來找出醫療欺騙數據。張煥毫[10]提出了基于最近集孤立度的方法找出骨科處方數據的孤立點異常樣本。Yamanishi等[11]使用概率生成模型去檢測病理數據的異常。Johnson等[12]基于多階段方法檢測健康保險索賠中的欺騙。另外,還可以用上下文檢測的方法來檢測2類特征的匹配關系,找出匹配不成立的異常數據。該方法在醫療中也有應用,Hu等[13]使用該方法在醫療記錄中識別異常用藥案例。劉少欽等[14]提出了基于擴展主題模型的方法判斷診斷疾病與處方藥物間的異常,其提出的擴展主題模型具有很好的參考意義,在異常處方的檢測中取得了很好的效果。目前醫療領域的異常檢測方法,主要針對醫療處方等疾病名稱、藥物名稱固定的結構化數據,但是針對語言結構復雜、專業術語難以獲取的影像診斷報告的研究相對較少。
傳統的有監督檢測、異常點檢測、上下文異常檢測等方法檢測異常診斷報告效果不佳。由于缺乏有效的標注數據,有監督的檢測方法不適用于診斷報告。診斷報告文本描述自由,一些影像描述的癥狀或者疾病出現較少,但不能歸為異常,所以用于異常點檢測會出現偏差。診斷報告數據高維稀疏,因此通過傳統的映射函數進行上下文的特征匹配,效果不佳。
診斷報告中的診斷結論是根據影像描述得到的,影像描述中的癥狀實體與診斷中的結論實體存在特有的語義信息和對應關系。診斷報告中存在大量的專業術語,如果不進行實體的抽取,直接以字符或者詞語特征進行訓練,輸入特征就會失去原有的語義信息和對應關系。如:影像描述中的“雙側膈肌光滑,雙肋膈角銳利”對應結論中的“膈無異常”,分成字符或詞語就失去了原有的語義信息和對應關系。通過計算這2類實體之間的對應關系,就可以判斷該診斷報告影像描述與診斷結論是否匹配,即可以檢測該診斷報告是否異常。本文方法的主要改進有:(1)針對胸片診斷報告的特點,利用加入后綴特征的雙向LSTM-CRF(Long Short-Term Memory Neural Network-Conditional Random Fields)模型,對描述癥狀實體和診斷結論實體進行提取,提高了實體提取的效果。(2)利用領域知識和模板,對胸片診斷報告進行特征的擴展和補充,一定程度上緩解了特征稀疏的問題。(3)將胸片診斷報告的異常檢測,轉換為影像癥狀實體特征與診斷結論實體特征判斷能否匹配的問題,利用LDA主題模型[15]來進行異常檢測,取得了很好的識別效果。
2 基于主題模型的診斷報告異常檢測方法
2.1 整體框架
基于主題模型的診斷報告異常檢測方法整體框架如圖1所示,胸片診斷報告的異常檢測主要分為實體特征提取和實體特征匹配2部分。首先,利用雙向LSTM-CRF模型結合診斷報告文本數據自身的字符級特點(后綴特征),對診斷報告影像描述與診斷結論中的實體進行準確提取,解決診斷報告中未登錄詞過多和專業術語提取困難的問題。然后,依據診斷報告自身數據的特點及領域專家知識對診斷報告中的各類特征進行擴展和補充,緩解數據的高維稀疏問題。最后利用LDA模型對診斷報告中癥狀實體與結論實體進行特征匹配,確定區分正常診斷報告與異常診斷報告的閾值,對診斷報告進行異常檢測。

Figure 1 Overall framework of the proposed method圖1 本文方法總體框架
2.2 基于雙向LSTM-CRF的診斷報告實體抽取
對胸部X光片診斷報告中的癥狀實體和疾病實體進行實體抽取時,具有以下挑戰:數據量巨大、未登錄詞過多、沒有相應的術語詞典、癥狀實體較長。診斷報告中的專業術語本身還具有很多的明顯字符級特征,如表1所示。本文根據診斷報告自身特征提出了基于LSTM-CRF模型進行診斷報告的實體抽取。
模型中雙向LSTM[16]神經網絡層可以整合上下文信息,得到序列中字符標簽的分布矩陣。CRF[17]廣泛用于序列標注的問題,模型中CRF層根據雙向LSTM層輸出的標簽概率分布,預測出最優的序列組合。
本文以字符基本特征結合診斷報告特有的實體后綴特征,生成表示其類型的字嵌入向量,輸入雙向LSTM-CRF序列標注模型,對序列標簽進行預測,最后完成對診斷報告實體的抽取。以字嵌入向量作為模型的輸入,解決了未登錄詞過多的問題,減少分詞帶來的負面影響,并且結合癥狀實體和疾病實體的字符級特征,對診斷報告中較長實體進行識別,取得了很好的效果。

Table 1 Classification of character-level features表1 字符級特征分類
2.3 基于主題模型的診斷報告異常檢測
2.3.1 主題模型

與傳統的LDA模型類似,改進后的LDA模型參數求解依然使用吉布斯采樣[18]方法,對同一個實例分為2個部分進行采樣,兩者有著相同的求解過程。以A類特征為例,計算實例d中A類特征w屬于主題t的概率如式(1)所示:
(1)
標記為主題t的所有A類特征中,特征w的比重如式(2)所示:
(2)
實例d標記為主題t的特征在所有特征中的比重如式(3)所示:
(3)

將診斷報告分為影像描述(A)和診斷結論(B)單獨出發進行推斷,得到2個診斷報告的實例主題分布。用MA表示A類特征實例的數目,MB表示B類特征實例的數目,K表示主題數目。
影像描述類實體特征x在該模型上的實例主題分布,推斷公式如式(4)所示:
(4)
診斷結論類實體特征x在該模型上的實例主題分布,推斷公式如式(5)所示:
(5)
診斷報告中的影像描述、診斷結論2類實體特征由共同的參數θ得到,因此改進主題模型抽取到的2類特征語義相似,并且2類主題分布可以進行關聯分析,最后得到影像描述和診斷結論之間的對應關系。通過計算比較影像描述實體和診斷結論實體得到的實例主題分布是否匹配,就可以檢測異常診斷報告。
2.3.2 特征擴展補充
胸部X光片診斷報告影像描述中的內容較長,實體特征豐富,利用LDA模型可以很好地進行主題提取。但是,一些診斷結論中的實體特征較少且稀疏,進行主題提取面臨挑戰。針對診斷報告的特點,通過以下方式緩解上述問題。診斷報告樣本實例如表2所示。
(1)特征擴展:診斷報告中存在較多并列描述,將這些并列實體分開描述如“雙肺紋理增強,紊亂”改為“雙肺紋理增強”和“雙肺紋理紊亂”。“心臟大小形態無異常”改為“心臟大小無異常”和“心臟形態無異常”。通過特征擴展可以大大豐富特征信息。
(2)特征補充:診斷結論主要突出表征的是影像描述中的異常,主要給出異常結論,很多正常的影像描述沒有給出相應的結論。這是造成診斷結論簡短的一個主要原因。對于胸部X光片,醫院和在線醫療網站都有對應的參考模板,診斷報告中的結論都有著與之相對應的規范描述。本文依據這些模板對診斷報告中的正常結論進行補充,大大緩解了診斷結論特征稀疏、主題提取困難的問題。
(3)將診斷的性質即陰性、陽性加入結論部分,并與影像描述中的癥狀實體進行匹配。

Table 2 Samples of diagnostic reports表2 診斷報告樣本實例
2.3.3 閾值計算
通過計算診斷報告中影像描述和診斷結論對應的主題分布的相似度,按照相似度排序,進而檢測本文方法在進行異常檢測時的效果。本文利用不同的相似度計算方法計算主題分布相似度,θA表示影像描述的主題分布,θB表示診斷結論的主題分布。
用歐幾里得距離(EUC)計算空間中2個點之間的距離,如式(6)所示。
EUC(θA,θB)=|θA-θB|
(6)
用余弦公式(COS)根據2個向量的夾角來確定相似度,如式(7)所示:
(7)
皮爾遜相關性(PS):由于θA和θB各個維度上分量之和為1,可以用相關性計算相似度,如式(8)所示:
(8)
其中,μ表示主題向量各個維度的均值,σ表示方差。
因為缺乏高質量標注的異常數據,所以不能依據相似度確定檢測異常診斷報告的閾值。本文利用診斷報告實體相對較少的優勢,對評價策略做出改進來確定檢測異常診斷報告的閾值。首先得到診斷報告中每個影像描述實體概率最大的2個主題并進行標記,然后得到每個診斷結論實體概率最大的主題,最后將診斷實體依次與每個描述實體標記的主題做匹配。如果能找到對應的主題,則證明該診斷結論有來自影像描述的依據,視為正常結論,否則視為異常結論。本文根據診斷結論與影像描述中不匹配實體的數量確定檢測異常診斷報告的閾值。
3 實驗
3.1 實驗數據及預處理
本文研究對象為胸部X光片,是最普遍的一種影像檢查,作為入院或門診的常規檢查進行疾病篩選。對大量診斷報告進行分析并與有關專家進行討論了解到,影像描述中出現的醫療癥狀實體與診斷中的結論實體有著明顯的對應關系,這些醫療實體大多是專有醫療用語和醫療共識用語。實驗數據來自某三級甲等醫院,為了保證診斷報告的普遍性,選取的診斷報告考慮到了患者性別、年齡以及檢查的時間。
胸片診斷報告的實體抽取,首先需要進行序列標注。本文在有關專家的耐心指導和監督下,對胸片診斷報告進行標注。由于診斷報告中的未登錄詞較多,以現有的分詞工具進行分詞后輸入模型會產生很大的負面影響。本文以字符特征按照BIO標準進行標注,實體起始字標簽為“B”,實體非起始字為“I”,非實體字為“O”。
診斷報告數據中缺乏標注數據,因此本文使用人工擾動的方式模擬出異常的診斷報告數據。本文將一部分的診斷報告數據中的確定疾病的診斷結論,全部換為正常的結論。如“肺氣腫”,改為“肺部無異常”。通過所提的方法檢測出這些人工擾動。數據集共有5 000份正常診斷報告和標注人工擾動的200份異常診斷報告。
3.2 評價標準及部分參數設置
本文對不同實驗效果的評價,采用準確率P、召回率R、以及兩者的綜合考量F-measure值(F)。公式如下所示:

Table 3 Training corpus annotation表3 訓練語料標注
(9)
(10)
(11)
其中,TP為準確識別出的標注實體;FP為錯誤識別出的非標注實體;FN為未識別出的標注實體。對于異常檢測:TP為準確識別出的異常報告;FP為錯誤識別出的非異常報告;FN為未識別出的異常報告。
本文在實體抽取部分使用雙向LSTM模型,隱藏層單元數量為64,句子長度不超過100。為防止過擬合,輸入層和隱藏層進行dropout,值設為0.6。在主題模型部分,設置的先驗超參數α=5.55,β=0.01。由于診斷報告屬于短文本,實體特征數量較少,本文以10為步長逐漸增加進行主題數對比實驗。
3.3 實驗設計及分析
實驗1 在本文提出的異常檢測方法中,實體提取的效果對異常檢測影響巨大。實驗1驗證在雙向LSTM-CRF中加入診斷報告字符級特征的實體識別方法的效果。將傳統的CRF模型、雙向LSTM模型、雙向LSTM-CRF模型與本文方法做對比,結果如表4所示,交叉驗證實驗表明,本文方法在進行診斷報告的實體抽取時取得了更好的效果。

Table 4 Entity extraction results of diagnostic report表4 診斷報告實體抽取結果 %
由表4可知,本文方法在進行診斷報告的實體提取時取得了最高的準確率和召回率。本文方法充分考慮了診斷報告的特殊性,結合字符級特征,針對診斷報告中較長專業術語的提取表現出優越的性能。
實驗2 將所有5 000份正常的診斷報告分成10份,采用10-fold交叉驗證的方式對數據集進行劃分,測試集采用其中500份正常的診斷報告和標注的200份異常診斷報告。實驗分別采用了詞語特征、實體特征和實體特征擴展3種輸入方式,驗證不同輸入方式進行診斷報告異常檢測的效果。同時驗證不同主題數K和相似度計算方法對異常檢測實驗效果的影響。首先將不同類型的特征在K=10,15,20下訓練模型;然后進行測試實驗,根據相似度由低到高進行排序,抽取相似度較低的200份診斷報告;最后通過其中標注出的異常診斷報告的數量進行對比實驗。交叉驗證實驗結果如表5所示。

Table 5 Experiment results with different input features and number of topics表5 不同輸入特征和主題數實驗結果
由表5可知,(1)以實體特征擴展后數據作為輸入,保持了診斷報告的語義特征和對應關系,同時一定程度上緩解了診斷報告實體特征稀疏的問題,取得了較好的實驗效果。(2)在主題數K=10時,不同輸入特征在各組排序數據中都取得了較好的效果。(3)利用皮爾遜相關性作為相似度計算的方法,實驗效果較好。因此,后續的對比實驗均以實體特征擴展作為輸入,主題數K選擇10,相似度計算采用皮爾遜相關性。
實驗3 為了驗證本文方法的性能,將本文方法與傳統的異常檢測的方法做比較。將上下文檢測方法、異常點檢測方法與本文方法進行了對比實驗。實驗根據相似度排序抽取出的50,100,150,200份診斷報告,根據異常診斷報告的數量,對比不同方法的性能。本文方法:計算實驗數據中所有實例主題分布相似度,并根據所有診斷報告實例相似度由低到高進行排序。上下文檢測方法:根據診斷報告數據偏離映射函數的程度進行排序。異常點檢測:根據與實驗數據集合的距離,將遠離集合的診斷報告數據進行排序。本實驗采用10-fold交叉驗證的方式,實驗結果如圖2所示。

Figure 2 Experimental results comparison of different methods圖2 不同方法實驗結果對比
由圖2可知,本文方法進行診斷報告的異常檢測,在不同的抽取數量中的檢測準確率提高顯著,檢測效果明顯優于傳統的異常點檢測、上下文檢測方法。因此,本文方法更適合缺乏高質量標注,數據特征稀疏的胸部X光片診斷報告。
實驗4 由于根據實例主題分布的相似度無法準確確定檢測異常診斷報告的閾值,所以本文將每一個診斷結論與影像描述中癥狀進行關系匹配,根據不匹配的數量來確定檢測異常診斷報告的閾值。實驗結果如表6所示。
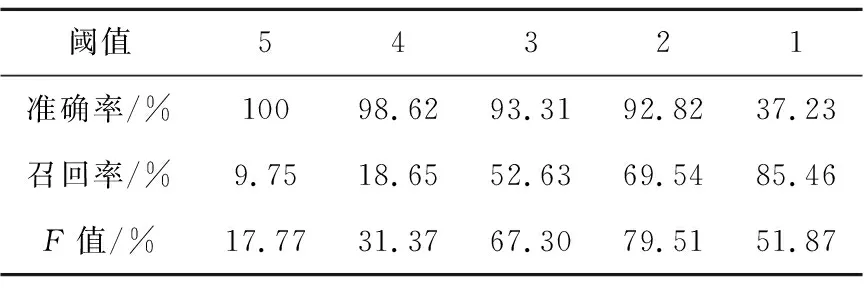
Table 6 Experimental results on different thresholds表6 不同閾值的實驗結果
由表6可知,當閾值設定為2以上的時候,雖然準確率有著很高的水平,但是召回率卻急劇下降。當閾值設定在2以下時,雖然召回率有所提高,但是準確率出現了明顯的下降。最終將檢測診斷報告的閾值設置為2,取得了較好的實驗效果。
4 結束語
本文提出了一種基于主題模型的胸部X光片診斷報告異常檢測方法,適用于缺乏有效標注,數據高維稀疏,未登錄詞較多的胸部X片診斷報告異常檢測。首先,利用雙向LSTM-CRF模型結合該診斷報告文本數據自身的字符級特點(后綴特征),對診斷報告影像描述與診斷結論中的實體進行準確提取。然后,依據診斷報告自身數據的特點及領域專家知識對診斷報告中的各類特征進行有效擴展和補充。最后,利用LDA模型對診斷報告中癥狀實體與結論實體進行特征匹配,對診斷報告進行異常檢測。本文方法對胸部X光片診斷報告進行異常檢測取得了很好的效果,但是對于其他診斷結論較短、實體較少或者缺乏領域知識進行特征擴展的、高維稀疏的診斷報告異常檢測的準確率仍有待提升。后續將圍繞存在以上問題的診斷報告開展進一步的研究工作。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
南方人物周刊(2017年32期)2017-10-28 22:48:36
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
南風窗(2016年26期)2016-12-24 21:48:09
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
南風窗(2015年22期)2015-09-10 07:22:44
