預訓練模型下融合注意力機制的多語言文本情感分析方法
2020-05-09 02:59:46胡德敏褚成偉胡鈺媛
小型微型計算機系統 2020年2期
胡德敏,褚成偉,胡 晨,胡鈺媛
(上海理工大學 光電信息與計算機工程學院,上海200093)
1 引 言
互聯網的快速發展以及移動設備的迅速普及使得用戶可以方便地通過網絡社交平臺發表自己的觀點評論.日常生活中,人們習慣于:在社交平臺分享個人觀點、在電商平臺發表商品評論、在影評網站上發表觀后感等等.這些文本大都反應用戶的真實情感,通過分析評論中的情感取向可以有效把握社會輿論的趨勢,為政府和決策機構提供支持,成為學術研究的熱點[1,2].
傳統情感分析方法主要分為三類:1)基于詞典的方法;2)基于機器學習的方法;3)基于深度學習的方法.基于詞典的方法以情感詞典為主要依據并結合句法規則判斷文本的情感傾向[3],這類方法的優劣性很大程度上取決于人工設計和先驗知識,推廣能力較差,通常會與其他文本特征相結合作為情感分類依據.Pang等人[4]首次提出通過標準機器學習的方法解決情感分類問題,特征工程是這類方法的核心,常用的特征有n-gram特征(unigrams,bigrams,trigrams)、Part-of-Speech(POS)特征、句法特征、TF-IDF特征等.2006年Hinton[5]等提出深度學習后,深度學習方法被引入自然語言處理領域,解決傳統機器學習方法無法挖掘深層語義的問題[6],深度學習方法是目前情感分析領域的主流方法.
相比于傳統的單語言情感分析任務,多語言情感分析相關研究較少[7].但在如今的社交平臺上(微博、Facebook等),多語言混合的表達形式使用廣泛,多語社區環境下的用戶更傾向于發表多語言混合的評論.E1-E5展示了微博上包含中英雙語的評論.
E1.“真hold不住我的快樂.So happy!”
E2.“這首歌真的太有feel 了”
E3.”用了爵士的腔調,加了一點 free style,so nice !”
E4.”難受 聽了一下午 cry cry…”
E5.”John is an aggressive guy! 工作也很努力!”
可以看出,評論文本中同時存在兩種語言,兩者交替使用,類似這類同一文本中同時出現兩種甚至更多語言或語言變體的現象稱為編碼轉換(code-switching),針對該類文本的情感分類問題稱為編碼轉換情感分類問題,本文研究的多語言情感分類問題即編碼轉換情感分類問題.上述評論大多以中文為主體,英文文本相對較少.在這類混合文本中,整體的情感極性不僅取決于中文詞語,還包括一些關鍵的英文詞(happy,nice,cry等).因此,準確地提取出不同語言的情感詞對多語言文本情感分類來說十分重要.
在不同語境下,同一個單詞可能有著不同的含義和情感傾向,例如E5中aggressive 有兩種含義,可以表示為有侵略性的,攻擊性的,也可以表示為有上進心的,積極的,兩者有這截然不同的情感傾向,通過結合下文可知aggressive在這里具有正向的情感傾向,可以看出,錯誤的詞義將對整體的情感極性產生嚴重的影響.因此,解決一詞多義問題對文本情感分析任務來說同樣十分重要.
針對上述問題,本文以中英文混合文本為對象,提出了一種基于預訓練語言模型并融合注意力機制的細粒度情感分類模型,通過預訓練語言模型生成上下文語義相關的詞向量,避免文本中可能出現的一詞多義性問題.考慮到文本的語序和上下文信息,使用BiLSTM模型挖掘文本情感表征,分別對中文、英文以及雙語情感表征使用注意力機制提取關鍵情感表征,最終將融合后的情感表征輸入到分類模型中得到結果.實驗表明該方法在多語言情感分類任務上取得了較好的效果.
本文將在第一節介紹多語言文本情感分析的相關工作,在第二節介紹本文提出的情感分析模型結構及原理,第三節介紹試驗數據及評估標準,并在同一個數據集上對不同的多語言情感分析模型對比分析實驗結果,最后對本論文的工作進行總結并提出展望.
2 相關工作
如何準確地挖掘出多語言文本中各個語言的情感表征并提取出其中的關鍵信息是多語言情感分類研究的難點[7].一種方法是直接將源語言翻譯為指定的目標語言,然后針對目標語言提取情感表征,進行情感分類任務.這類方法的困難在于如何彌補語言差距對分類效果的影響[8].Ethem等人[9]首先針對英文語料訓練英文情感分類模型,對于多語言語料,將其他語言通過現有的機器翻譯方法翻譯為英文,輸入英文情感分類模型預測情感極性.Wang等[10]針對中英文混合文本,通過機器翻譯方法將英文文本翻譯為中文,結合雙語情感特征構建二分圖,最后通過半監督的標簽傳播算法實現文本的情感分類,對比只考慮單語文本的方法,該方法在每個情感類別上F1值均有提升.
另一種方式是使用字符級的編碼代替詞級別編碼,不同于詞級別的編碼方式(2013,Mikolov等[11,12]),字符級編碼可以挖掘出更豐富的情感表征,并且,對于多語言混合文本能夠更準確地挖掘出潛在的情感信息.Kim等人[13]首次提出基于字符卷積的詞嵌入方法Char-CNN,在英文數據集PennTreebank上模型困惑度(perplexity)與其他模型持平,在阿拉伯語、俄語等語言上模型困惑度均低于其他模型,取得較好結果.Prabhu[14]使用Char-CNN方法對印度語-英語混合文本進行字符編碼,將編碼結果輸入多層LSTM網絡訓練,最終得到情感分類結果,結果較傳統的詞級別編碼方法F1值有較大提升.Jhanwar等人[15]首先使用字符級的Trigram特征結合多層LSTM實現神經網絡分類器,接著通過詞級別的unigram、bigram特征構建多項樸素貝葉斯分類器,最終通過集成學習方式綜合上述分類器得到分類結果,模型在印度語-英語混合文本數據集上得到較高的F1值.
還有許多學者提出其他針對多語言文本的情感分類方法.徐源音等[16]提出混合文本情感分析模型MF-CSEL,使用CBOW訓練詞向量,分別針對中英文文本提取情感特征,融合情感特征、詞序特征以及TF-IDF權重矩陣后,通過集成學習的方式進行細粒度的情感分析.Wang等[7]針對中英文混合文本提出一種基于多注意力機制的情感分類模型,分別對中文、英文以及中英文混合文本使用注意力機制提取關鍵詞信息并融合,最后輸入分類器中實現細粒度情感分類,模型對比傳統單語言情感分析模型F1值有較大提升.
本文首先在大規模的語料上使用深度語言模型框架ELMo訓練得到語言模型,將原始文本輸入模型后得到上下文語義相關的詞向量,接著將詞向量輸入BiLSTM網絡學習文本情感表征,考慮到文本中的每個詞對整體情感極性影響不同,分別對中文、英文以及中英混合的情感表征使用注意力機制學出習每個詞對于情感傾向的權重分布,從而準確有效地挖掘出文本中的關鍵情感信息,最終通過并行融合的方式提升情感分類效果.
3 多語言文本情感分類模型
本文采用細粒度情感分類方式,將情感分為5類,分別為happiness、sadness、anger、fear、surprise,對于不含任何情感極性的文本標注為none.模型整體結構如圖1所示.模型結合了預訓練語言模型,BiLSTM網絡以及多語言注意力機制,通過預訓練語言模型得到上下文相關的詞向量,使用BiLSTM學習文本情感表征,使用多語言注意力機制分別對單語文本和混合文本提取關鍵情感表征.
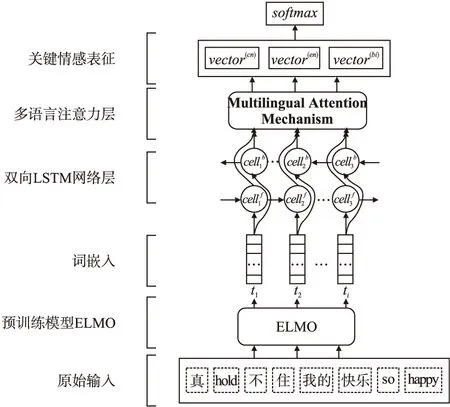
圖1 模型整體結構Fig.1 Model structure
3.1 預訓練語言模型
傳統淺層機器學習模型(SVM、LR等)依賴于人工提取特征,而人類的情感表達方式是復雜的,常常包含否定、雙重否定以及其他的語言模式,因此通過淺層機器學習模型無法有效地挖掘文本中的深層次的語義信息.相比于淺層模型,深度學習模型可以自動從原始文本中學習出層次化的特征[6],準確挖掘出文本中深層語義信息.另外,在獲取詞嵌入向量時考慮文本的上下文信息,針對不同的上下文得到不同的詞嵌入向量可以有效解決文本中的一詞多義問題.針對上述特點,本文使用深度學習框架ELMo訓練語言模型.
Matthew等[17]提出了上下文相關的深層詞表征模型ELMo,模型結構如圖2所示.模型包含兩個部分:Char-CNN嵌入層以及BiLSTM網絡層.
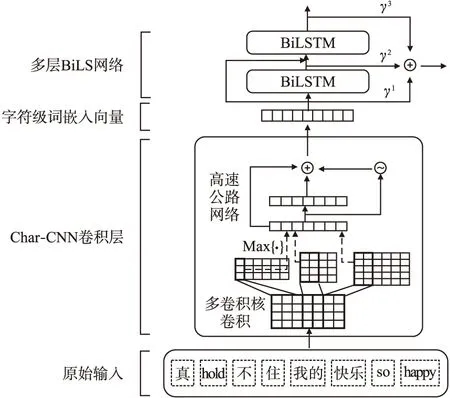
圖2 ELMo結構Fig.2 Structure of ELMo
Char-CNN卷積層用于實現字符級別的詞嵌入,對于給定詞Wk=[C1,C2,…,Cl],ci表示字符,l為詞長,d表示嵌入字符的維度,則Wk可以表示為矩陣Ck∈Rd×l.使用寬度為w的卷積核H∈Rw×d對矩陣Ck進行卷積,并添加非線性激活函數后得到特征矩陣fk∈Rl-w+1,fk中的每一個元素可以表示為:
fk[i]=tanh(
(1)
Ck[*,i:i+w-1]表示第i個字符到第i+w-1個字符組成的嵌入矩陣,
(2)
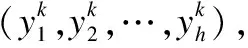
zk=t⊙g(WHek+bH)+(1-t)⊙ek
(3)
其中,g表示非線性激活函數,類似LSTM網絡中的記憶單元,t=σ(WTek+bT)表示轉換門限(transform gate),(1-t)表示傳送門限(carrygate),在多層神經網絡中,高速公路網絡允許低層輸入直接傳送至高層,并與輸出結合,有效解決梯度信息回流受阻所造成的網絡訓練困難問題.
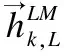
(4)
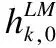
(5)
3.2 BiLSTM學習情感表征
在文本情感分類中,由于單詞之間存在時序關系,且上下文之間存在語義依賴關系,因此,本文采用BiLSTM模型對句子進行編碼,學習句子的情感表征.雙向長短記憶網絡(Bidirectional Long Short-Term Memory,BiLSTM)是對單向長短記憶網絡(Long Short-Term Memory,LSTM)[18]的擴展,同時對輸入序列進行正向和反向計算,最終將正向結果和反向結果拼接后輸出.
圖3展示了LSTM的基本單元結構.xt表示t時刻的輸入數據,ht表示該時刻LSTM單元的輸出,ct表示該時刻更新后的細胞狀態.LSTM結構的關鍵是細胞狀態c,狀態信息在LSTM單元中傳輸,其中線性操作用以控制狀態信息的保留,更新和輸出,分別對應遺忘門、輸入門和輸出門.

圖3 LSTM基本結構Fig.3 Structure of LSTM
狀態信息首先經過遺忘門ft,該門限決定上一時刻細胞狀態ct-1保留多少信息,丟棄多少信息.ft計算方式如下:
ft=σ(Wf[ht-1,xt]+bf)
(6)
將ht-1和xt拼接后進行線性變換,傳遞給sigmoid激活函數,輸出0到1之間的值表示信息的保留量,Wf表示遺忘門權重,bf表示遺忘門偏置.
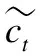
(7)
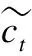
it=σ(Wi[ht-1,xt]+bi)
(8)
Wi表示輸入門權重,bi表示輸入門偏置.接著更新細胞狀態得到ct,計算公式如下:
(9)
輸出門Ot的計算方式同遺忘門、輸入門類似,如下所示:
Ot=σ(Wo[ht-1,xt]+bo)
(10)
Wo表示輸出門權重,bo表示輸出門偏置.得到輸出門Ot之后,便可以計算最終輸出ht:
ht=Ot*tanh(ct)
(11)
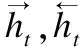
(12)
(13)
(14)
3.3 注意力機制提取關鍵情感表征
句子中的不同詞對整體的情感極性影響不同,通過分析語料發現,句子中的一些情感詞往往更能體現用戶的情感傾向,而在中英文混合的文本中,這些關鍵的情感詞可能是中文詞,也可能是英文詞,見表1.為了增強關鍵情感詞在情感分類中的作用,本文采用注意力機制(Bahdanau等[19])學習不同詞匯的權重分布.
表1 情感詞分布
Table 1 Affective word distribution

評論關鍵詞E6.前天各種玩各種happy,昨天五星級晚宴感覺很high!Happy、highE7. 一點都不開心,一個個都幸福的回家過年了.微博刷下來全是各種party holiday 啊! 苦逼的還在辦公室,傷心!!!不開心、傷心E8.一覺到現在能分得清夢境和現實么?我不能,大多數時候都不能,非常不好,so bad and so sad.不好、bad、sadE9.感冒發燒,喉嚨還難受,誒,心累…還有做不完的功課,多么happy 的holiday…難受、誒、心累、happy
對于表1中的E6和E7而言,整體的情感極性只由單語詞決定.而E8和E9的整體情感極性由中文關鍵詞和英文關鍵詞同時決定,對于E9,如果只考慮英文詞happy,則整體的情感極性完全相反.因此,構建模型時應該同時考慮中文、英文情感詞以及上下文信息.
本文注意力結構如圖4所示,vector(cn)、vector(en)、vector(bi)分別表示對中文、英文以及雙語文本應用注意力機制得到的情感表征向量.
1)雙語注意力機制 針對雙語文本,模型會為文本中的每一個詞學習出一個自適應權重,接著將詞的情感表征向量乘以權重后累加求和得到雙語文本情感表征向量vector(bi),如式(15)-式(17)所示:
(15)
(16)
(17)
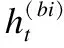
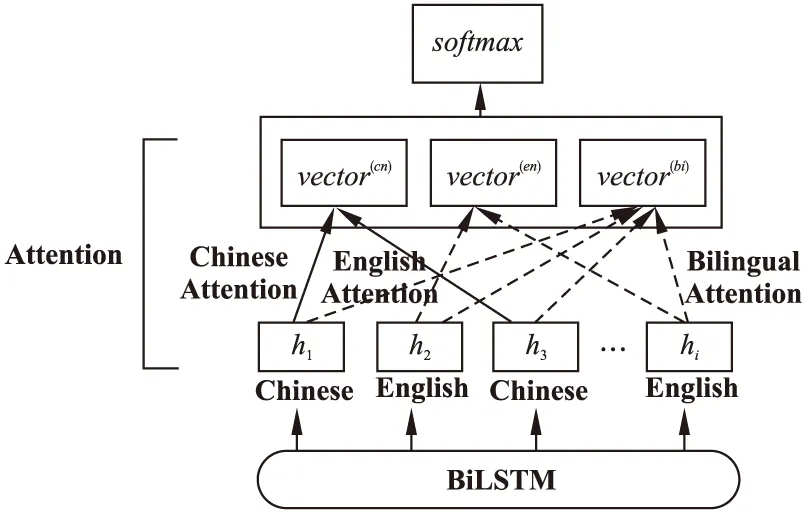
圖4 多語言注意力機制Fig.4 Multilingual attention mechanism
2)單語注意力機制 類似雙語文本,模型會分別針對中文詞和英文詞學習自適應權重,將詞的情感表征向量乘以權重后累加求和得到單語文本情感表征向量vector(mo),如式(18)-式(20)所示:
(18)
(19)
(20)

3.4 分類器
模型的最后一層為分類層,分類層將上一層得到的單語情感表征向量(vector(cn)、vector(en))和雙語情感表征向量(vector(bi))拼接后作為分類器輸入Finput=[vector(bi),vector(cn),vector(en)]輸出類別概率Pc:
Pc=softmax(W(s)Finput+b(s))
(21)
最終類別:
(22)
W(S)為n×c的權重矩陣,n為輸入向量Finput的維度,c為類別數,b(s)為分類層的偏置向量,在得到預測類別的概率分布后,本文使用交叉熵損失函數(cross entropy)衡量預測值與真實值之間的差距,利用反向傳播更新模型中的參數.
3.5 情感分類流程
模型的情感分類流程如圖5所示.
a)輸入中英混合文本.
b)預處理:為混合文本分詞,分詞后為每個詞標記語言屬性(中文或英文).
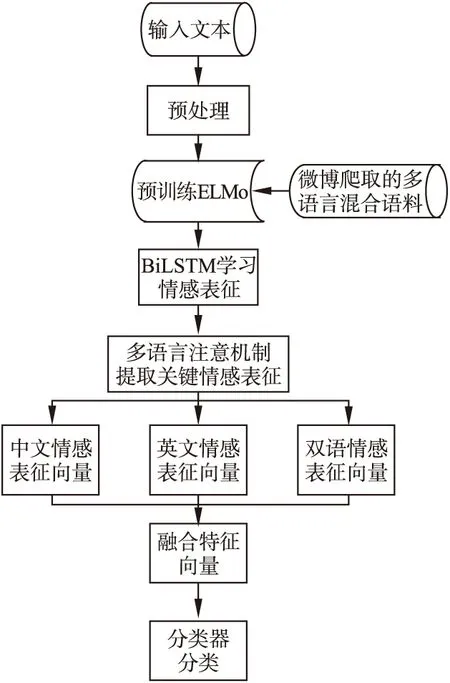
圖5 情感分類流程Fig.5 Affective classification process
c)將預處理的文本輸入預訓練模型ELMo得到上下文相關詞向量(t1,t2,…,tn).
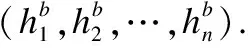
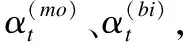
f)將上一步得到的情感表征拼接后輸入分類器中得到情感分類結果.
4 實驗和分析
4.1 實驗數據
本文預訓練模型ELMo使用的訓練數據集包括三部分:中文數據集、英文數據集以及中英文混合數據集.中文數據集使用維基百科開放中文語料集以及Github開源中文自然語言處理數據集ChineseNlpCorpus,其中ChineseNlpCorpus包括了來自微博、外賣、電影以及酒店平臺的30萬條中文評論數據.英文數據集使用維基百科開放英文語料集以及斯坦福大學開放的亞馬遜評論集,從亞馬遜評論集中抽取出30萬條英文評論數據.中英文混合數據集爬取自新浪微博,共計2萬條數據.
對于上述數據,本文統一進行預處理(去除特殊字符、停用詞、詞形還原),中文文本采用Jieba分詞器分詞.過濾詞量小于5以及詞量大于300的文本后得到500萬條訓練數據.
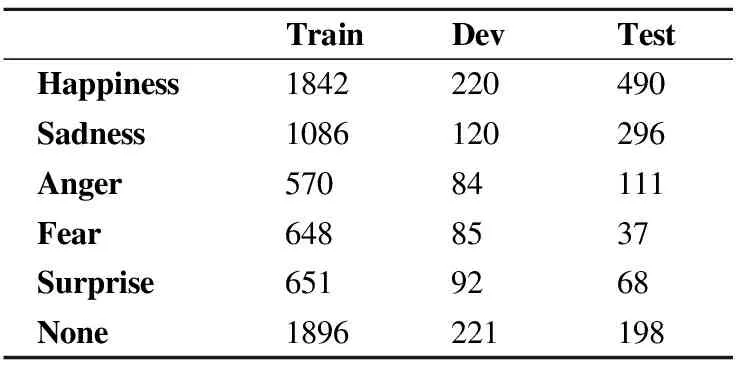
本文使用的試驗數據為NLPCC2018多語言情感分類評測任務數據集(中英文).數據分為訓練集(6000條數據)、驗證集(728條數據)、測試集(1200條數據).包含5個情感極性(happiness、sadness、anger、fear、surprise).數據分布如表2所示,其中,None表示不包含任何情感極性.
表2 情感類別分布
Table 2 Distribution of emotion
TrainDevTestHappiness1842220490Sadness1086120296Anger57084111Fear6488537Surprise6519268None1896221198
4.2 評價指標
本文選用與NLPCC2018多語言情感分類評測任務相同的評價標準,使用精確度(Precision)、召回率(Recall)、F1值(F1-score)以及宏平均F1值(Macro-F1)評估本文方法.精確度和召回率計算方式如式(23)-式(24)所示:
(23)
(24)
其中,TPi、FPi和FNi分別表示第i個類別的真正例(truepositive)、假正例(falsepositive)和假反例(falsenegative)個數.
宏平均F1值計算方式如式(25)-式(27)所示:
(25)
(26)
(27)
Pma表示準確率均值,Rma表示召回率均值.
4.3 實驗對比模型
為了驗證模型的有效性,本文設計了對比實驗,將本文模型分別和不使用注意力機制、不采用預訓練方式的情感分類模型以及已有的多語言情感分類模型對比.如下所示:
Baseline:NLPCC2018多語言情感分析評測任務提出的基線模型,模型使用unigram特征,SVM作為分類器.
w2v+BiLSTM:使用word2vec訓練詞向量,使用雙向LSTM模型學習文本情感表征.
w2v+BiLSTM+Attention:使用word2vec訓練詞向量,使用雙向LSTM模型學習文本情感表征,使用注意力機制提取關鍵情感表征.
DeepIntell:NLPCC2018多語言情感分析評測任務中的最高成績,作者將多標簽分類轉化為二分類,采用集成學習的方式利用文本中的情感詞匯進行情感分類任務.
MF-CSEL:徐源音等人提出的多特征融合的集成學習情感分析模型,使用CBOW訓練詞向量,分別針對中英文文本提取情感特征,融合情感特征、詞序特征以及TF-IDF權重矩陣后,通過集成學習的方式進行細粒度的情感分析.
ELMo+BiLSTM+Attention:本文提出的模型,使用ELMo預訓練語言模型輸出詞向量,使用雙向LSTM模型學習文本情感表征,使用注意力機制提取關鍵情感表征.
4.4 實驗環境及參數設置
本文使用Tensorflow1.13框架搭建模型,詞向量長度定義為200,除詞向量長度外,ELMo模型超參數均使用默認參數,如表3所示.
表3 ELMo參數
Table 3 Parameters of ELMo

參數名參數值BiLSTM隱層單元個數4096BiLSTM輸出維度512Char-CNN卷積核個數2048
限定句子長度為100,超出100的句子只截取前100個詞,不足的部分使用
表4 模型參數
Table 4 Parameters of Model

參數名參數值BiLSTM隱層單元個數300詞向量維度200學習率0.001批處理大小64句長100
4.5 實驗結果及分析
本實驗在服務器上進行,CPU為雙核Intel至強處理器,GPU為NVIDIA Tesla P4.實驗結果如圖6所示.
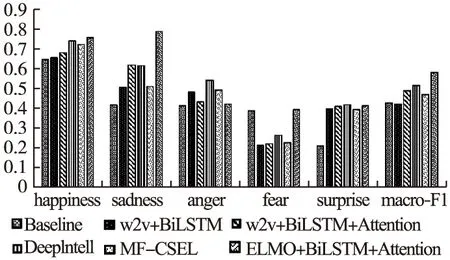
圖6 模型實驗結果對比Fig.6 Comparison of model experiment results
從圖6中可以看出,僅使用word2vec和BiLSTM網絡時,模型在除Fear外所有情感類別上的F1值就已經超越基線模型,加入了注意力機制后,模型在除Anger外的各類別上的F1值均有提升.而在使用了ELMo預訓練模型后,模型在除anger、surprise類別外均取得最高分數,宏平均F1值提高至0.581,表明了本文多語言情感分析模型的有效性.
模型在不同情感類別上的準確率(Precision)、召回率(Recall)以及F1值如表5所示.可以看出,模型在Anger、Fear以及Surprise情感類別上的準確率遠遠大于召回率,造成這一問題的主要原因是數據類別的不平衡,通過分析語料發現,訓練集中無情緒句子數量最多(1896),其次是Happiness(1842)和Sadness(1086),而其余類別數量較少,數據的不平衡將導致分類器偏向于占比較高的類別,對于Anger、Fear以及Surprise而言,由于本身類別較少,分類器則會傾向于將類別分類為無情緒(none),故式(24)中FNi較大,從而降低召回率.
表5 本文模型實驗結果
Table 5 Results of model experiment in this paper
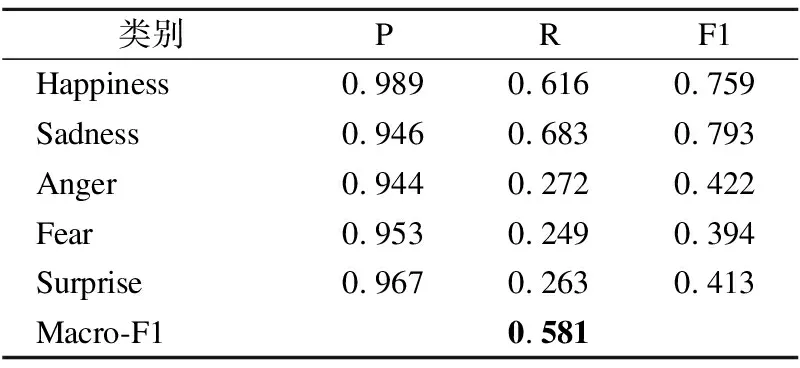
類別PRF1Happiness0.9890.6160.759Sadness0.9460.6830.793Anger0.9440.2720.422Fear0.9530.2490.394Surprise0.9670.2630.413Macro-F10.581
為了觀察句子中的注意力分布,本文將單語和雙語注意力權重輸出,如圖7所示.其中,CN、EN、Bi分別表示對中文、英文、中英混合文本使用注意力機制.可以看到,通過多語言注意力機制可以有效提取出中文和英文的關鍵情感詞匯,對于情感詞前的否定詞匯(不、開心),模型也可以有效識別,這也驗證了加入多語言注意力機制有助于模型效果的提升.
5 總結與展望
本文針對中英文混合文本提出了一種在預訓練語言模型基礎上結合多語言注意力機制的情感分析模型.模型將預訓練學習到的語義信息應用在詞向量上,根據具體的上下文生成含有不同語義信息的詞向量,通過BiLSTM網絡學習文本情感表征.不同于傳統的單語言文本注意力機制,本文分別針對中文、英文以及中英文混合文本使用注意力機制提取關鍵情感信息,融合后進行情感分類.實驗表明,本文提出的模型在宏平均F1值上超越現有的情感分類模型.
本文在多語言情感分析上的研究任然存在不足之處,可以看到,由于類別數據不平衡,本文模型在Anger、Fear以及Surprise類別上的F1值較低,在后續的研究中將考慮通過樣本空間重構的方式調整樣本分布,降低數據不平衡問題對模型分類結果的影響.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
鄱陽湖學刊(2016年6期)2017-01-16 13:05:41
中國遠程教育(2016年6期)2016-12-07 10:07:02
財經(2016年19期)2016-08-11 08:17:03
中國遠程教育(2016年5期)2016-06-29 10:13:42
