基于深度卷積生成對抗網絡的圖像識別算法
2020-05-11 12:00:20劉戀秋
液晶與顯示 2020年4期
關鍵詞:模型
劉戀秋
(重慶財經職業學院,重慶 402160)
1 引 言
生成對抗網絡(GAN)是近年來最受關注的無監督式神經網絡之一,該模型功能強大且應用場景廣泛,最常見的應用是圖像生成。在GAN的框架中[1],結果的生成是通過對抗過程不斷進化,在GAN中同時有兩個模型訓練:捕獲數據分布的生成模型G以及估計數據分布的判別模型D。生成器G的訓練目標是騙過判別器D,換言之最大化D犯錯誤的概率;D的目標則是最大化自己的正確率。該框架本質上是一個博弈過程,最終收斂于納什均衡。在空間上,對于生成器G和判別器D,如果使用零和博弈的loss函數,當D訓練完美達到1/2時,D就無法再分辨出真實數據和生成數據,也就無法再給G提供梯度。
為了進一步提升GAN的穩定性和識別效率,有很多學者都提出了自己的優化方案,提出了虛擬批量標準化的算法,利用批量訓練數據的方式顯著改善網絡性能。Radford提出了深度卷積生成對抗網絡(DCGAN)的算法[2],該算法將GAN的概念擴展到卷積神經網絡中,可以生成更高質量的圖片。在此基礎上,Sailimans等在近紅外光譜(NIR)圖像的場景下提出了著色 DCGAN模型[3],該方案的核心是針對NIR圖像將其劃分為RGB 3個通道,再利用DCGAN的模型分別進行訓練,進一步提升了識別的準確率。但是針對大部分的圖像處理而言,基于深度卷積生成對抗網絡的圖形識別算法仍存在收斂速度慢、訓練過程不夠穩定的缺點。本文提出了融合加權Canny算子和Prewitt算子的深度卷積生成對抗網絡算法[4],該加權算子對多個方向進行卷積,從而初始化輸入圖片參數,有效減少了噪聲的干擾。
2 深度卷積神經網絡算法
卷積神經網絡又簡稱卷積網絡(CNN),該模型主要用于處理網格狀結構數據的特殊網絡結構[5-8]。該模型是受到貓的視覺皮層細胞研究的啟發,模仿其神經結構然后提出了感受野(Receptive Field)的概念。卷積神經網絡將時序信息等單一變量的信息作為一維的數據格式,而圖片、位置等信息則被認為是二維的數據格式。卷積神經網絡在推出后,取得了巨大的成功。呂永標基于深度學習理論,將圖像去噪過程看成神經網絡的擬合過程,構造簡潔高效的復合卷積神經網絡,提出基于復合卷積神經網絡的圖像去噪算法,該算法由2個2層的卷積網絡構成,分別訓練3層卷積網絡中的部分初始卷積核,縮短階段網絡的訓練時間和增強算法的魯棒性,最后運用卷積網絡對新的噪聲圖像進行有效去噪。實驗表明,文中算法在峰值信噪比、結構相識度及均方根誤差指數上與當前較好的圖像去噪算法相當,尤其當噪聲加強時效果更佳且訓練時間較短[9]。王秀席等針對現有車型識別算法耗時長、特征提取復雜、識別率低等問題,引入了基于深度學習的卷積神經網絡方法。此方法具有魯棒性好、泛化能力強、識別度高等優點,因而被廣泛使用于圖像識別領域。在對公路中的4種主要車型(大巴車、面包車、轎車、卡車)的分類實驗中,改進后的卷積神經網絡LeNet-5使車型訓練、測試結果均達到了98%以上,優于傳統的SIFT+SVM算法,其算法在減少檢測時間和提高識別率等方面都有了顯著提高,在車型識別上具有明顯優勢[10]。隨著大數據時代來臨以及GPU并行計算速度的飛速發展,卷積神經網絡本身不斷優化(ReLU激活函數取代Sigmoid函數,Dropout思想的提出),其計算效率得到了大幅度提升。許赟杰等針對常用的激活函數在反向傳播神經網絡中具有收斂速度較慢、存在局部極小或梯度消失的問題,將Sigmoid系和ReLU系激活函數進行了對比,分別討論了其性能,詳細分析了幾類常用激活函數的優點及不足,并通過研究Arctan函數在神經網絡中應用的可能性,結合ReLU函數,提出了一種新型的激活函數ArcReLU,既能顯著加快反向傳播神經網絡的訓練速度,又能有效降低訓練誤差并避免梯度消失的問題[11]。
深度卷積神經網絡包含以下幾個核心部分:
(1)局部感知。圖像的空間聯系中局部的像素聯系比較緊密,而距離較遠的像素相關性則較弱。因此,每個神經元其實只需對局部區域進行感知,而不需要對全局圖像進行感知。
(2)權值共享。在上述的局部連接中,每個神經元都有對應的參數,再進行卷積完成特征提取。例如,假設神經元都對應50個參數,共2 000 個神經元,如果這10 000個神經元的25個參數都是相等的,則參數量就變為25個。把這25個參數對應卷積操作,完成了特征提取。在卷積神經網絡中相同的卷積核的權值和偏置值是一樣的。同一種卷積核按照固定對圖像進行卷積操作,卷積后得到的所有神經元都使用同一個卷積核區卷積圖像,都是共享連接參數。因此,權值共享減少了卷積神經網絡的參數數量。
(3)卷積。該步驟利用卷積核對圖像進行特征提取。卷積過程本質上是一個去除無關信息,留下有用信息的過程。其核心就是卷積核的大小步長設計和數量的選取。個數越多提取的特征越多,但網絡的復雜度也在增加,如果特征數量太少又不足以描述特征。在該步驟中的卷積核的大小影響網絡結構的識別能力,步長決定了采取圖像的大小和特征個數。
(4)池化。在卷積神經網絡中,池化層一般在卷積層后,通過池化來降低卷積層輸出的特征向量維數。池化過程最大程度地降低了圖像的分辨率,同時降低了圖像的處理維度,但又保留了圖像的有效信息,降低了后面卷積層處理復雜度,大大降低了網絡對圖像旋轉和平移的敏感性。一般采用的池化方法有兩種:平均池化(Mean pooling)和最大池化(Max pooling)。平均池化是指對圖像目標局部區域的平均值進行計算,將其作為池化后該區域的值;最大池化則是選取圖像目標區域的最大值作為池化后的值。
3 基于深度卷積生成對抗網絡的圖像識別
3.1 圖像預處理
為了能夠提升圖像訓練效率,對圖像進行預處理,流程如下:
(1)假設給出圖像I,首先對其進行歸一化處理,假設有像素為128×128的圖像I,將其歸一化為In∈[0,1]128,128,3;
(2)利用Canny算子和Prewitt算子的加權綜合,對圖像進行進一步的卷積預處理,提取核心特征。
3.2 訓練流程
采用DCGAN的(G,D)架構,生成器G是一個編碼解碼的CNN結構,判別器D是一個步長卷積方案,不斷重復進行下采樣來完成二分分類[12]。在每次訓練的地帶中,我們都隨機采樣一批訓練數據,對每個訓練圖像I我們運行生成器,接著用判別器來進行分類,然后計算損失和更新的參數。
為了減少訓練過程,本文將訓練過程分為3個階段,每個階段定義一個損失函數:
LMSE(I)=‖MΘG(I)‖,
(1)
LD(I)=-[lnD(I)+ln(1-D(G(I)))] ,
(2)
LG(I)=LMSE(I)-αlnD(G(I)),
(3)
第一個訓練階段通過損失函數LMSE(I)不斷升級調整生成器的權重,第二階段則使用LD(I)來調整生成器的權重,第三階段過程類似,但是α是作為經驗值,根據不同的場景而變化。
3.3 網絡結構
在生成器G的網絡結構中,我們采用傳統的編碼器-解碼器結構,以及擴張的卷積來增加神經元的感受野。對于判別器D,我們將圖像沿垂直方向分為左右兩部分,分別為Il、Ir,為了產生出預測結果Id,判別器需要分別計算Dg(Id)、Dl(Il)、Dl(Ir),最后生成判別器的概率p,生成器和判別器的網絡參數如表1~5所示。
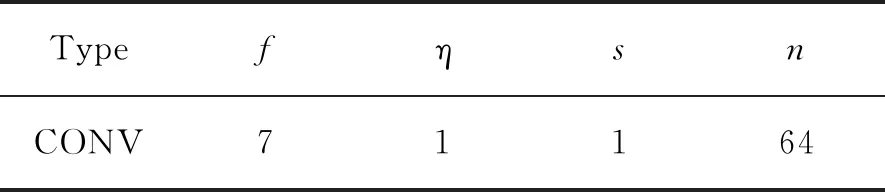
表1 卷積層1Tab.1 Convolution layer 1

表2 卷積層2Tab.2 Convolution layer 2
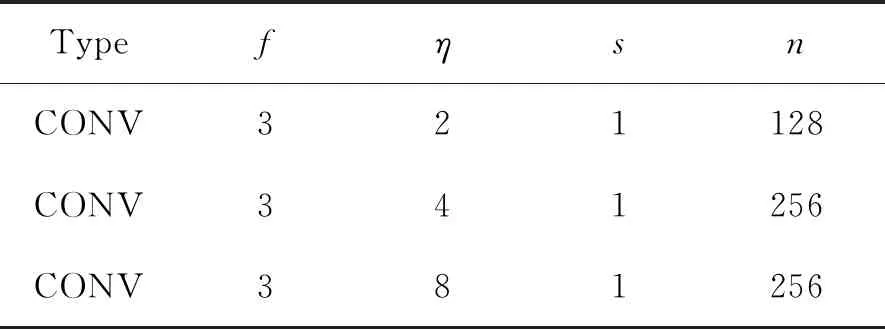
表3 卷積層3Tab.3 Convolution layer 3

表4 輸出Tab.4 Output

表5 判別器參數表Tab.5 Discriminator parameter table
4 結果與討論
考慮到深度卷積網絡的計算成本,本文主要利用GPU的并行計算能力,采用5臺Inter(R)I7-8700K,64 G內存,NVIDIA RTX 24 G GPU計算機,利用TensorFlow[13]平臺實現本文提出的算法并運行。
4.1 CIFAR-100數據集
本文采用的CIFAR-100數據集包含大量的測試圖片[14]。與CIFAR-10不同的是,CIFAR-100有100個分類,其中每個類都包含500個訓練圖像和100個測試圖像,每個圖像都帶有兩個標簽。使用本文2.3節提出的模型實現生成器和
判別器,首先對數據集中的圖像進行預處理,將圖片進行歸一化,再利用Canny算子和Prewitt算子的加權,最后作為訓練模型的輸入。在生成器的全連接層中加入Dropout,在預處理的3個階段,由于CIFAR-100的前景背景相對復雜多變,因此T1設置為20 000,T2為3 000,T3為10 000,α為0.006,實驗總共運行了25 h,進行了50個epoch。在訓練過程中,判別器的損失函數逐漸下降,而生成器的損失函數逐漸上升,最終判別器以微弱優勢戰勝了生成器。最終檢測效果如圖1所示。在與其他經典方法的對比中,其收斂的速度更快,檢測率也更優,如表6所示。
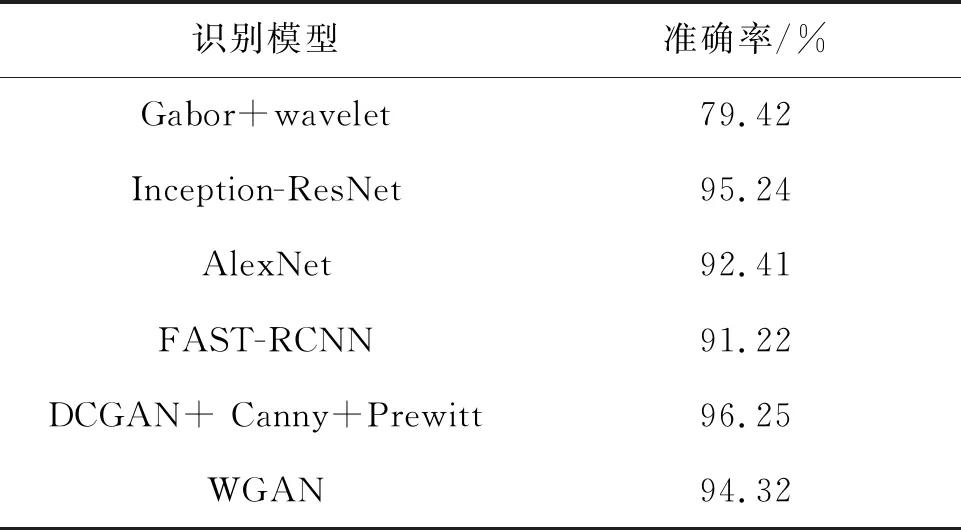
表6 CIFAR-100圖像集實驗準確率Tab.6 Experimental accuracy of CIFAR-100 image set

圖1 CIFAR-100生成器迭代結果Fig.1 Iterative results of CIFAR-100 generator
4.2 LFW實驗
LFW是一個人臉識別專用的圖像訓練集[15],有2 845張圖片,每張圖片中包含多個人臉,共有5 171個人臉作為測試集。測試集范圍包括不同姿勢、不同分辨率、旋轉和遮擋等圖片,基本能呈現人臉表情的各種狀態,同時包括灰度圖和彩色圖。本文采用灰度圖進行實驗。由于整個數據集相對較小,同時前景相對簡單,因此預處理時間消耗較小,T1設置為1 000,T2為2 000,T3為10 000,α為0.005,實驗共運行4 h,進行了50個epoch。在迭代過程中隨著epoch的增大,生成器產生的圖片越加清晰精準,質量不斷提升,結果如圖2所示。
從表7中可以看到,本文采用的DCGAN+softmax+centermax的模型優于傳統的DCGAN模型,在相對較小的數據集中,具備更強的特征提取能力;本文提出的模型的檢測率優于其他有監督和無監督算法,證明了本文方法的可行性。

圖2 LFW生成器頭像迭代結果Fig.2 Iterative results of LFW generator
表7 LFW圖像集實驗識別準確率
Tab.7 Experimental recognition accuracy of LFW image set
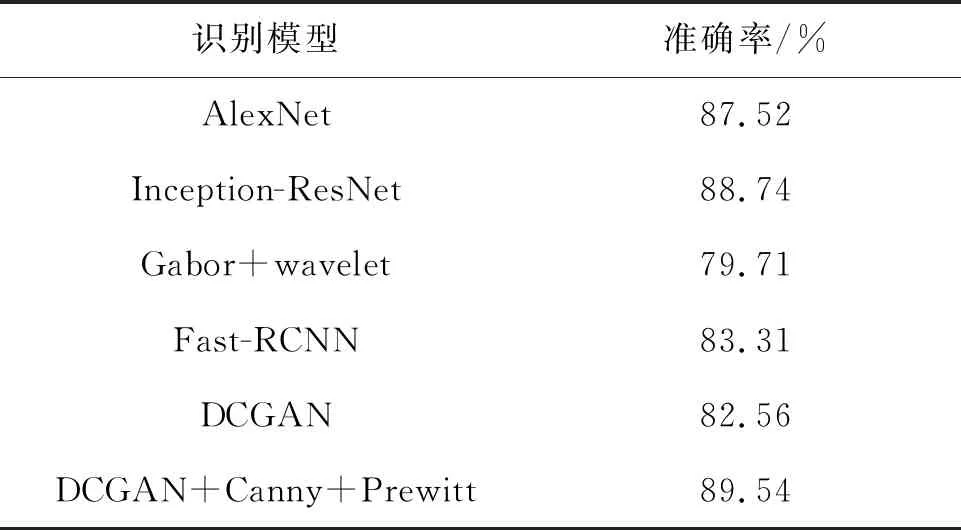
識別模型準確率/%AlexNet87.52Inception-ResNet88.74Gabor+wavelet79.71Fast-RCNN83.31DCGAN82.56DCGAN+Canny+Prewitt89.54
5 結 論
提出了一個基于深度卷積對抗網絡的模型,利用該模型對訓練完成后的判別器進行特征提取并用于圖像識別。利用Canny算子和Prewitt算子進行圖像預處理,同時將訓練劃分為3個階段設置不同的訓練參數,提高了分類算法的內聚性。在WILDERFACE和LFW數據集上進行實驗,結果表明相對于其他傳統檢測算法,本文提出的模型在LFW識別準確率達到89.54%,CIFAR-100上達到96.25%,證明了本文提出的模型在圖像檢測領域的可行性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
