Python在校園大數據中的應用研究
2020-05-12 06:06:26朱正國
商丘師范學院學報 2020年6期
朱正國
(安徽城市管理職業學院,安徽 合肥 230011)
伴隨著信息技術的發展和學校信息化建設的加強,每天都會產生大量信息化數據,如何有效利用好這些數據資源是目前很多學校面臨的問題.
當今社會已經進入大數據時代,各種數據正在迅速膨脹變大,人們將越來越依賴大數據[1].大數據具備海量、多樣、高速、易變四大特點和數據類型繁多、價值密度相對較低、處理速度快時效性要求高三大特征[2].當今高校也進入了大數據時代,各種關聯性數據正在呈幾何級的增加,Python在大數據時代越來越凸顯出它的優勢.Python豐富的工具包讓它在數據搜集、科學計算、文件處理、數據處理、數據可視化、人工智能、自動化控制等方面具備很大的優勢.我們使用Python進行校園大數據的數據采集、分析、匯總,給學校的教學改進和學生管理提供決策支持.
1 Python在數據處理上的優勢分析
Python是一種計算機程序設計語言.它是面向對象的動態腳本語言,起初主要用于自動化腳本的編寫,后期版本的更新和新增的語言功能使得Python語言現在可以用來進行大型項目和獨立項目的開發[3].
Python在處理數據上具備以下優勢:(1)代碼量少,開發速度快;(2)豐富的數據處理包,對于正則表達式、html解析、xml解析等處理起來非常方便;(3)使用成本低,且不要額外操作;(4)語法簡單,學習快、維護成本低;(5)Python是免費開源的、且兼容眾多平臺.正是由于Python不需要考慮諸如如何管理程序使用的內存之類的底層細節、可移植性、可擴展性良好等優點,非常適合高校做大數據分析.
2 Python在數據處理上的應用
2.1 數據搜集
學校每天的數據資源非常多,既有傳統的關系型數據庫,又有包含視頻、音頻、文本以及其他形式的非結構化數據.數據收集就是要對這些碎片化的數據進行收集的同時進行清洗來保證數據質量,同時還要更新數據模式來確定數據實體之間的關系,統一格式存儲,以便給后期數據分析階段提供有效的優質數據資源[4].
本文研究的Python工具版本是Python3,開發工具使用的是Eclipse,具體開發環境搭建過程在此不做詳細闡述,網上案例很多.Python抓取的系統包括:網頁形式各種校方教務、學工系統、門戶網站、包含人臉識別的視頻采集分析系統的智慧教室、校園一卡通系統、相關的各種交流論壇、實訓室管理系統、以及在線學習平臺網站等.設計思路是首先進入校園門戶網站,根據該網絡爬出所有相關連的網站和系統url,包括校內和校外的,部分實現代碼如下:
def crawl(pages,depth=2):
for i in range(depth):
newpages = set()
for page in pages:
try:
c = urllib.request.urlopen(page)
except:
print(’Invaild page:’,page)
continue
soup = bs4.BeautifulSoup(c.read())
links = soup(’a’)
for link in links……
通過一個循環抓取當前頁面上所有的鏈接,我們盡可能多地去抓取鏈接,之所以選擇set而不使用list是防止重復的現象,我們可以將爬取的網站存放到文件或者MySQL或者是MongoDB里.
output = sys.stdout
outputfile = open(’chengguan.txt’,’w’)
sys.stdout = outputfile
list = GetFileList(chengguan,[])
這一步的目的是做數據資源的來源分析.接下來,需要做的是“關鍵詞”搜索,如:“學生成績”“某某班級”“某某人”“某某實訓室”等,部分實現代碼如下:
import jiban
import jiban.analyse
text = “關鍵詞”
fenci_text = jiban.cut(text)……
通過Python編寫的網絡爬蟲程序,只需要設計好規則,程序就會自動的、不間斷的按照既定規則去抓取你所需要的數據.同時對抓取的數據進行存儲、分析、過濾、建立索引,方便后期查詢與檢索,通過這一系列過程所得到的分析結果還會對以后的抓取過程給出反饋和指導[5].
2.2 數據清洗
通過Python爬蟲抓取的數據是臃腫的、散亂的、未校驗、不規則的,在提交給“數據分析”之前,還需要進行“數據清理”工作.因為Python是不間斷地進行數據搜集工作,如果不進行數據清洗,那么爬蟲庫也將越來越龐大、對其進行的分析時間也將越來越長,逐漸的就會失去其意義.
我們利用數據挖掘、數理統計、預定義清理的規則等對數據進行審查和校驗,剔除重復、錯誤的信息,保證數據的準確、一致、有用[6].本研究部分Python編寫的數據清洗代碼如下:
import pandas as pd
import numpy as np
from collections import Counter
from sklearn import preprocessing
from matplotlib import pyplot as plt
matplotlib inline
import seaborn as sns
plt.rcParams[’font.sans-serif’]= [’SimHei’]
plt.rcParams[’axes.unicode_minus’]= False
sns.set(font=’SimHei’)
data=pd.read_excel(’...’)
data.head()
data.shape
data.describe()
data.isnull().any()
total = data.isnull().sum().sort_values(ascending=False)
print(total)
data.duplicated().sum()
data.drop_duplicates()
for i in cat_col:
print(pd.Series(data[i]).value_counts())
plt.plot(data[i])
dummies=pd.get_dummies(data[cat_col])
dummies
數據清洗路徑如圖:
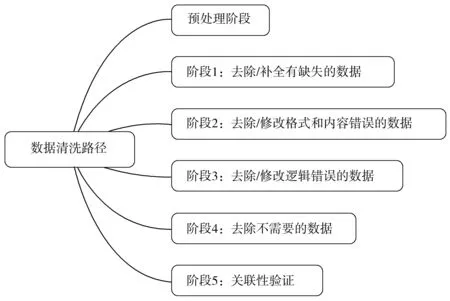
圖2 數據清洗路徑
2.3 數據分析
爬取后的數據經過數據清洗后還需要經過數據分析這個過程來挖掘其潛在的價值,我們可以用傳統的方法來對數據進行分析諸如數據挖掘、機器學習、統計分析等[7].只是需要按照大數據的特點來進行調整:首先對于處理海量信息化數據的分析,我們需要借助Map/ Reduce模型經過數據拆分處理和結果匯總二個過程,一次完整的分析可能需要多次類似的處理過程;其次,正如前面所說的大數據的應用有很強的時效性,數據的價值會隨著時間的推移而不斷降低,因此我們在進行數據分析時需要處理和平衡好效率和準確率之間的關系[7].
高校大數據分析需要從多維度進行:例如課堂教學質量分析,通過清洗后的課堂視頻數據,我們可以得到課堂的出勤、教師提問、學生舉手抬頭鼓掌包括學生上課睡覺等情況;例如學校科目分析,通過清洗后的相關教學數據,可以得到不同學年、不同教師對同一科目的教學成果,可以得到同一教師在不同學期、不同專業的同一科目教學成果;例如具體學生學習分析,可以通過清洗后的教學數據、學工數據、一卡通數據,獲得該學生不同學科的 成績、進出宿舍打卡時間統計信息、進出教室打卡時間統計信息、進出實訓室打卡時間統計信息、科目教師對其評價匯總信息、該學生在學校推薦在線學習平臺學習情況匯總信息;例如學生消費分析,可以通過該學生的一卡通在校園內食堂刷卡消費記錄、零食品店鋪刷卡消費記錄,獲得該學生不同時間段消費記錄匯總信息、不同類型消費對比信息.
本研究,部分Python編寫的數據分析代碼如下:
from collections import defaultdict
def group_data(data,key_name):
grouped_data=defaultdict(list)
for data_point in data:
grouped_data[data_point[key_name]].append(data_point)
return grouped_data……
數據分析的結果,很容易了解哪些課是受歡迎的;哪些教師是學生喜歡的,哪些院系重視教學工作;哪些課程需要改進,如何改進;哪些教師應該獲得幫助,需要哪些幫助;哪些課程應該獲得更多的投入;哪些教師應該獲得獎勵;哪些教室應該進行改造,如何改造;哪些院系應該淘汰哪些課程等.
數據分析的結果,能夠幫助學校健全學生信息,例如生源、家庭條件、專業背景、學習習慣、學習成績、消費習慣、網絡瀏覽習慣、上課狀態、對某些科目的喜好程度、校內社交情況、主動上網在線學習情況、主動預約實訓室學習情況等;這些信息具有很高的價值,角度全面、且信息處于不斷變化之中.
按照一定規則分析出的數據,就可以進行下一步環節:數據匯總.
2.4 數據匯總與反饋
通過Python進行數據搜集和分析,我們可以匯總出在校學生的各科學習情況、學生成績階段性對比情況、同級學生對比情況、同科學生對比情況、不同教師上同一科目的教學效果對比情況、同一教師上不同班級教學效果對比情況等;同時還匯總出學生在校消費行為報告、不同學生消費行為對比分析報告、不同時間段學生消費行為分析報告、學生在考試前和考試后消費行為分析報告等;以及學生消費行為和當天上課效果關聯性分析、學生在節假日前后消費和學習效果關聯性分析等.
這些分析匯總數據,對學校進行教學診改、學生個性化優勢教學、學生消費行為指導等,提供了決策數據支持.
3 總結及后續工作
本文運用Python對安徽城市管理職業學院的校園大數據進行挖掘分析,旨在為校園大數據的充分利用探索可行路線.現在很多高校都在探索校園大數據問題,大部分是從發展規劃的角度去探索數據分析問題,包括挖掘關乎學校發展的各類數據指標,然后從幾個維度進行縱、橫向比較分析,從而分析學校發展存在的問題[2].本研究以學生為中心,進行數據搜集、挖掘、清洗、分析、匯總,通過對學生的多維度分析,從而更好地培養人才.
當然,在研究的過程中,也遇到了一些問題:比如信息不全面,為此學校在智慧校園的改造過程中,把以前那些互聯性較差的、數據統一標準較差的系統進行了逐步改造,現在學校的各種系統基本都是web方式部署,且建立了統一的數據標準;比如缺乏數據分析的模式和方法,用戶需求零散瑣碎,數據價值難以真實體現等等[9].為了解決諸如此類問題,我們參考了多所其他院校分析模式結合網上專家的一些指導方向,通過摸索實驗,建立了適合本校的研究模式.利用Python對校園信息化大數據的分析應用,只是起點,后續還有很多需要完善的地方.如何利用好這些數據,讓其價值得到充分的體現,是我們每個教育工作者都應該盡力去做的事情.
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
琴童(2017年3期)2017-04-05 14:49:04
小天使·二年級語數英綜合(2017年3期)2017-04-01 17:17:48
山東工業技術(2016年15期)2016-12-01 05:31:22
留學生(2016年6期)2016-07-25 17:55:29
中學生天地(A版)(2015年5期)2015-06-01 02:46:03
小朋友·聰明學堂(2014年7期)2015-01-15 12:07:06
下一代英才(2014年10期)2014-10-27 02:33:47
中學生英語·外語教學與研究(2008年2期)2008-02-18 01:52:44
