基于YOLO_v3的車輛和行人檢測方法
2020-05-13 14:15:23洪松高定國三排才讓
電腦知識與技術 2020年8期
洪松 高定國 三排才讓

摘要:在新時代背景下,智慧交通的概念已經出現在人們的生活中。檢測車輛和行人已經成為目標檢測領域比較熱門的應用研究方向。該文將YOLO_v3目標檢測算法應用于車輛和行人的檢測。針對行人和車輛檢測問題,將分類器的輸出張量維度設置為21維。實驗結果表明,訓練出的模型在測試集上的平均檢測精度約為89%。其中,車輛的檢測精度約為95.64%.行人的檢測精度約為82.55%。
關鍵詞:智慧交通;目標檢測;車輛;行人
中圖分類號:TP391 文獻標識碼:A
文章編號:1009-3044(2020)08-0192-02
開放科學(資源服務)標識碼(OSID):
1 概述
隨著城市的發展,城市交通流和人流密度成為城市道路交通擁擠的重要原因。針對這一問題,智慧交通的概念出現在人們的認知中,也因此提出了新時代智慧交通的發展應強化前沿科技應用與研發的觀點[1]。在此背景下,車輛和行人檢測成為當下的研究熱門。近年來計算機視覺領域發展迅猛,基于深度學習的目標檢測技術層出不窮。當前的目標檢測技術主要分為兩大類,一是以Fast R-CNN和Faster R-CNN為代表的基于區域生成的兩階段檢測算法;二是以YOLO和SSD為代表的基于回歸的單階段檢測算法[2]。兩階段的檢測算法通常具有較高的檢測精度,但檢測速度較慢,而單階段檢測算法在犧牲了一定檢測精度的基礎上提高了檢測速度。
目前YOLO系列檢測算法已經在工程中的各個領域中都有廣泛的應用。其中,在航空航天領域,鈕賽賽[3]等人將YOLO智能網絡算法用于紅外弱小多目標的檢測,將其與傳統的模板匹配方法相比,在檢測概率和檢測精度上YOLO具有明顯的優勢。在交通領域,周慧娟[4]等人提出了基于改進Tiny YOL02的地鐵進站客流人臉檢測方法,測試結果表明基于改進的TinyYOL02的人臉檢測算法相比于原始的檢測算法在召回率和檢測速度上都有提升且有較好的泛化性。在農業領域,燕紅文[5]等人提出了基于改進Tiny-YOLO模型的群養生豬臉部姿態檢測算法,實驗表明該模型可以有效地對群養生豬不同類別臉部姿態進行檢測。在教育領域,黃偉鎧[6]等人設計了一種基于YOLO算法的學生課堂關注度分析系統,該系統能有效檢測課堂中學生的行為,為分析學生的課堂關注度提供了一種有利的手段。由此可見,YOLO系列檢測算法已經應用于各行各業.并取得了不錯的檢測效果,具有一定的實際應用價值。
單階段檢測算法YOLO_v3因其良好的檢測精度和速度,已經在工程應用中成為主流檢測算法。本文在KITTI數據集的基礎上,利用YOLO_v3算法對該數據集進行特征訓練學習,進一步對網絡模型的參數進行調整,最終得到本文的車輛和行人檢測模型。
2 YOLO v3算法理論
2.1 特征提取網絡Darknet-53
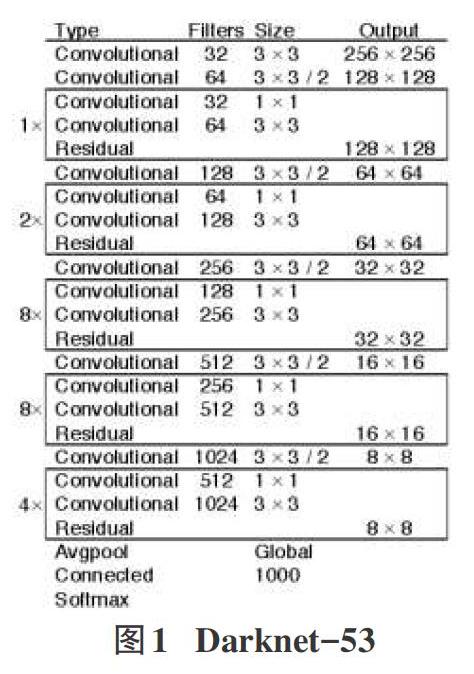
YOLO_v3其主干特征提取網絡由連續的3x3和IXI卷積層組合而成,因為一共有53個卷積層,又被稱為Darknet_53[7]。YOLO_v3的特征提取網絡Darknet-53如圖1所示,在整個特征提取網絡的結構里沒有池化層和全連接層,張量的尺寸變換是通過改變卷積核的步長來實現的,在此結構中不考慮全局平均池化,張量維度的變化一共有5次。
2.2 基于車輛和行人檢測的YOLO_v3算法分析
YOLO_v3網絡將輸入的行人和車輛圖片進行預處理,然后將其送入CNN網絡,CNN網絡將輸入的圖片分割成SXS的網格,每個單元格被用于檢測那些中心點落在該單元格內的目標。每個單元格會預測檢測物體邊界框的4個偏移坐標和置信度得分。最后YOLO_v3會在三個等級上進行預測,每個等級負責不同規模大小的物體的預測,每種規模預測三個邊界框。在本實驗數據集中類別為行人和車輛,共兩類。所以得到的張量是SxSx[3x(4+1+2)],其中包含4個邊界框的坐標、1個目標預測以及兩種分類預測。
3 基于YOLO_v3的車輛和行人檢測實驗
3.1 實驗數據
本文是在KITTI數據集的基礎上訓練行人和車輛檢測模型,官方提供的數據集中只有訓練集圖片給出了標簽,一共有7481張圖片。將這7481張圖片按照9:1的比例劃分為訓練集和測試集。該數據集中共有八個類別,分別是Car、Van、Truck、Tram、Pedestrian等,將這八個類合并為Car、Pedestrian這兩個大類。最后通過格式轉換腳本程序將KITTI數據集格式轉化為YOLO網絡所需要的標簽格式。
3.2 實驗平臺
本實驗平臺的配置為:顯卡為2080Ti,顯存IIG,CPU為In-ter Core i7 9700,內存64G,操作系統為ubuntu18.04,CUDA版本為10.1,CUDNN版本為7.6.3。
3.3 實驗參數設定
本實驗初始學習率設置為0.001,權重衰減設置為0.0005,最大迭代次數設置為50000次,動量參數設置為0.9。在模型訓練過程中,按照設定的訓練節點調整學習率的大小,減少模型訓練過程中的損失,該訓練節點分別為最大迭代次數的80%和90%[8]。本實驗數據集中的大部分車輛和行人在圖片中所占比例較小,較難分辨,為了提高檢測精度,將送入網絡的圖片分辨率設置為608x608。同時為了提高模型的魯棒性,在訓練過程中隨機使用不同尺寸的圖片進行訓練。
4 實驗分析
4.1 實驗過程及分析
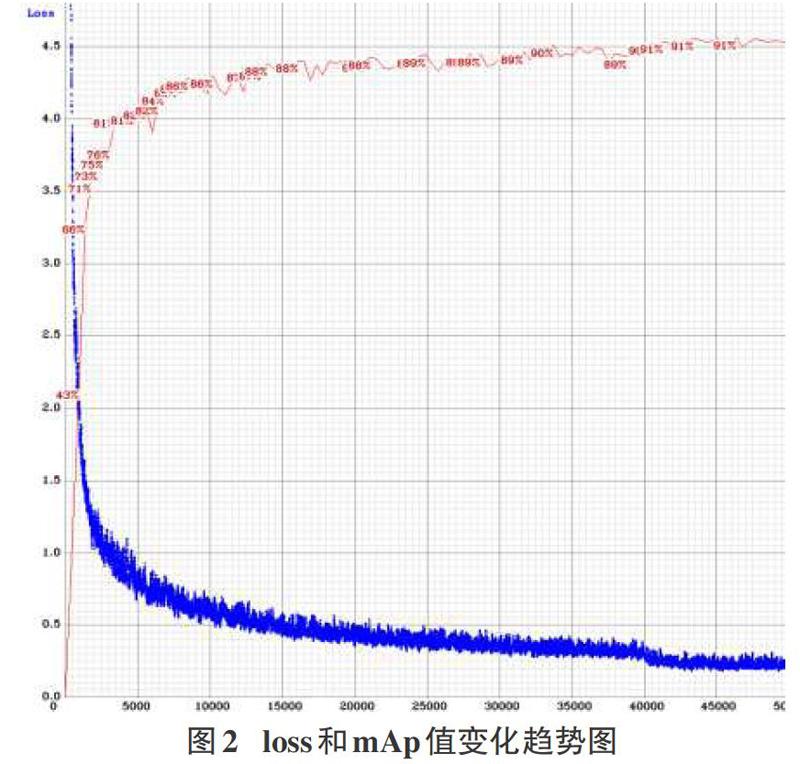
實驗過程中的loss和mAp值的變化趨勢如圖2所示,在前5000次迭代中loss急劇下降,mAp值逐步上升。隨著迭代次數的增加loss和mAp的變化趨于平緩,mAp的值在89%至91%范圍內波動。在40000次迭代訓練后loss值趨于穩定不再下降,當迭代訓練結束時,loss的值約為0.22左右。
4.2 實驗評價指標
本實驗采用目標檢測領域公認的平均檢測精度mAP以及Precision、Recall、Fl值來衡量模型的性能。Precision、Recall、F1值、AP及mAP定義如式(1)一(5)所示。
其中TP表示正確檢測到是行人或車輛;FP表示誤檢測為是行人或車輛;FN表示漏檢測行人或車輛;P,R分別表示精確率與召回率;C表示數據集中的類別總數,本實驗取2,C.表示當前第i個類別,i的取值為0和1。
4.3 實驗結果
實驗結果表明,訓練出的模型在748張圖片的測試集上的平均檢測精度約為89%。其中,車輛的檢測精度約為95.64%,行人的檢測精度約為82.55%。詳細的實驗結果如表1到3所示,在測試集上的部分檢測效果如圖3和4所示。
5 結束語
本文闡述了基于YOLO_v3的車輛和行人檢測方法,包括修改分類器維度、模型訓練及網絡參數調整。實驗結果表明基于YOLO_v3的車輛和行人檢測方法取得了不錯的檢測效果,具有一定的實用價值。但是基于YOLO_v3的車輛和行人檢測方法對于弱小車輛和行人目標檢測效果不好,下一步可針對特定場景下的弱小車輛和行人目標進行網絡改進以進一步提升網絡檢測精度。
參考文獻:
[1]伍朝輝,武曉博,王亮.交通強國背景下智慧交通發展趨勢展望[Jl.交通運輸研究,2019,47(4):26-36.
[2]周曉彥,王珂,李凌燕.基于深度學習的目標檢測算法綜述[J].電子測量技術,2017,40(11):89-93.
[3]鈕賽賽,周華偉,朱婧文,等.基于YOLO智能網絡的紅外弱小 多目標檢測技術[Jl.上海航天,2019,36(5):28-34.
[4]周慧娟,張強,劉羽,等.基于YOLO:的地鐵進站客流人臉檢測方法[J].計算機與現代化,2019(10):76-82.
[5]燕紅文,劉振宇,崔清亮,等,基于改進Tiny-YOLO模型的群養生豬臉部姿態檢測[Jl.農業工程學報,2019,35(18):169-179.
[6]黃偉鎧,張登輝.基于YOLO算法的學生課堂關注度分析系統[J].浙江樹人大學學報:自然科學版,2019,19(3):1-4,17.
[7]
Redmonj, Farhadi A.YOL09000: better, faster, stronger[C]//2017lEEE Conference on Computer Vision and Pattem Recognition(CVPR),July 21-26, 2017. Honolulu, Hl. lEEE, 2017.
[8]游忍,周春燕,劉明華,等.基于TINY-YOLO的嵌入式人臉檢測系統設計[Jl.工業控制計算機,2019,32(3):47-48.
【通聯編輯:梁書】
收稿日期:2019-12-21
作者簡介:洪松(1994-),男,碩士生,主要研究圖像處理;高定國(1972-),藏族,碩士,教授,主要研究藏文信息處理、算法設計;三排才讓(1994-),男,藏族,碩士生,主要研究藏文信息處理。
